Вам также может понравиться
- Managing Sino American Crises: Case Studies and AnalysisДокумент535 страницManaging Sino American Crises: Case Studies and AnalysisCarnegie Endowment for International Peace100% (3)
- A Conceptual History of Civil Society from Ancient Greece to MarxДокумент40 страницA Conceptual History of Civil Society from Ancient Greece to MarxaliamriОценок пока нет
- Foucault On The Social Contract PDFДокумент37 страницFoucault On The Social Contract PDFKeabetswe CossaОценок пока нет
- 2015, HOLMES WhatIsNationalSecurityДокумент10 страниц2015, HOLMES WhatIsNationalSecurityRodrigo LentzОценок пока нет
- Divided Dynamism: The Diplomacy of Separated Nations: Germany, Korea, ChinaОт EverandDivided Dynamism: The Diplomacy of Separated Nations: Germany, Korea, ChinaОценок пока нет
- The Dilemma of Collective SecurityДокумент11 страницThe Dilemma of Collective SecurityDimitris KantemnidisОценок пока нет
- Rational Model of Foreign Policy DecisionДокумент10 страницRational Model of Foreign Policy DecisionSiân Caitlin BurkittОценок пока нет
- China's New Diplomacy Concept: Building a Community of Shared Future for MankindОт EverandChina's New Diplomacy Concept: Building a Community of Shared Future for MankindОценок пока нет
- Networks and States The Global Politics of Internet GovernanceДокумент306 страницNetworks and States The Global Politics of Internet GovernanceAndra DimiОценок пока нет
- Legislating Privacy: Technology, Social Values, and Public PolicyОт EverandLegislating Privacy: Technology, Social Values, and Public PolicyОценок пока нет
- Foreign Affairs.2019 6Документ228 страницForeign Affairs.2019 6WaltОценок пока нет
- America's Strategic Blunders: Intelligence Analysis and National Security Policy, 1936–1991От EverandAmerica's Strategic Blunders: Intelligence Analysis and National Security Policy, 1936–1991Оценок пока нет
- Digital China Big Data and Government Managerial Decision (Qing Jiang) (Z-Library)Документ150 страницDigital China Big Data and Government Managerial Decision (Qing Jiang) (Z-Library)lqq250700Оценок пока нет
- Cyber Challenges and National Security ThreatsДокумент257 страницCyber Challenges and National Security ThreatsToufik AbdelhayОценок пока нет
- Legislative Oversight of Intelligence Activities: The U.S. ExperienceДокумент162 страницыLegislative Oversight of Intelligence Activities: The U.S. ExperiencetrevorgriffeyОценок пока нет
- The Taylor Commission ReportДокумент312 страницThe Taylor Commission ReportPraiseSundoОценок пока нет
- Geopolitics and SecurityДокумент24 страницыGeopolitics and SecurityJaved ZafarОценок пока нет
- HIGLEY, John BURTON, Michael FIELD, G. in Defense of Elite Theory PDFДокумент7 страницHIGLEY, John BURTON, Michael FIELD, G. in Defense of Elite Theory PDFJonas BritoОценок пока нет
- Hobbes and The Legitimacy of LawДокумент39 страницHobbes and The Legitimacy of LawKabita SharmaОценок пока нет
- Liu, I. Y. (2017) - State Responsibility and Cyberattacks Defining Due Diligence Obligations.Документ70 страницLiu, I. Y. (2017) - State Responsibility and Cyberattacks Defining Due Diligence Obligations.s.ullah janОценок пока нет
- Environment Chapter of Secret Trans-Pacific Partnership DraftДокумент29 страницEnvironment Chapter of Secret Trans-Pacific Partnership DraftLeakSourceInfoОценок пока нет
- Civil Military Fusion in Intelligence in India The Way Forward by Col Vijay Narayan ShuklaДокумент17 страницCivil Military Fusion in Intelligence in India The Way Forward by Col Vijay Narayan ShuklaVikas TyagiОценок пока нет
- The Revival of GeopoliticsДокумент16 страницThe Revival of GeopoliticsAbraham PaulsenОценок пока нет
- Fukuyama. 2019. Against Identity PoliticsДокумент24 страницыFukuyama. 2019. Against Identity PoliticsCelestina Brenes Porras100% (1)
- Handbook of Revolutions in The 21st Century - The New Waves of RevolutionsДокумент1 048 страницHandbook of Revolutions in The 21st Century - The New Waves of RevolutionsSavas AkturОценок пока нет
- Return of Geopolitics and Revisionist Powers Shake Global OrderДокумент7 страницReturn of Geopolitics and Revisionist Powers Shake Global OrderESMERALDA GORDILLO ARELLANO100% (1)
- Psychologists, The U.S. Military Establishment and Human RightsДокумент11 страницPsychologists, The U.S. Military Establishment and Human RightssbondiolihpОценок пока нет
- Notes - Schweller (2011) Emerging Powers in An Age of DisorderДокумент4 страницыNotes - Schweller (2011) Emerging Powers in An Age of DisorderSimon FialaОценок пока нет
- Big Data, Political Campaigning and The Law - NORMANN WITZLEB - Routledge - 2020Документ259 страницBig Data, Political Campaigning and The Law - NORMANN WITZLEB - Routledge - 2020Gabriel AguiarОценок пока нет
- Soviet Theory of Reflexive Control PDFДокумент126 страницSoviet Theory of Reflexive Control PDFSandro AlmeidaОценок пока нет
- Walzer's Theory of Morality in International RelationsДокумент25 страницWalzer's Theory of Morality in International RelationsNikeBОценок пока нет
- Rand - Future of WarefareДокумент20 страницRand - Future of WarefaredanielОценок пока нет
- A Brief History of Jews in BelarusДокумент3 страницыA Brief History of Jews in BelarusBrian Tice100% (1)
- Jervis (1978) - Cooperation Under The Security DilemmaДокумент49 страницJervis (1978) - Cooperation Under The Security DilemmaThainá PenhaОценок пока нет
- The Case For State-Based Work Visas by Chaston PfingstonДокумент8 страницThe Case For State-Based Work Visas by Chaston PfingstonHoover InstitutionОценок пока нет
- Cold War Summative Essay Copy1 Copy2Документ8 страницCold War Summative Essay Copy1 Copy2David HygateОценок пока нет
- Coping With Crisis: Nuclear Weapons: The Challenges AheadДокумент23 страницыCoping With Crisis: Nuclear Weapons: The Challenges AheadLaurentiu PavelescuОценок пока нет
- Unsalvageable Phenomena: A Doubter's Guide To Middle Eastern Oil and US Foreign PolicyДокумент16 страницUnsalvageable Phenomena: A Doubter's Guide To Middle Eastern Oil and US Foreign PolicyHoover InstitutionОценок пока нет
- World PolicyJournal Winter 2016 2017Документ124 страницыWorld PolicyJournal Winter 2016 2017Arun KapoorОценок пока нет
- Putin Vladimir 10 Feb 2007. President of Russian Federation in Munich at The 43rd Conference On Security PolicyДокумент19 страницPutin Vladimir 10 Feb 2007. President of Russian Federation in Munich at The 43rd Conference On Security PolicyThomas ClothierОценок пока нет
- Review of Au Cameroun de Paul BiyaДокумент3 страницыReview of Au Cameroun de Paul BiyaAdebang AngwafoОценок пока нет
- Intelligence and International Security Fall 2019 HARVARD UNIVERSITYДокумент7 страницIntelligence and International Security Fall 2019 HARVARD UNIVERSITYstudent1Оценок пока нет
- The Political Origins of Global Justice PhilosophyДокумент28 страницThe Political Origins of Global Justice PhilosophyRodrigo ChaconОценок пока нет
- National Counterintelligence and Security Center (NCSC) China Genomics Fact Sheet 2021Документ5 страницNational Counterintelligence and Security Center (NCSC) China Genomics Fact Sheet 2021lawofseaОценок пока нет
- The Democracy of Knowledge-Bloomsbury Academic (2013)Документ220 страницThe Democracy of Knowledge-Bloomsbury Academic (2013)Sandra MalagónОценок пока нет
- Strategic Culture A.I. JohnstonДокумент34 страницыStrategic Culture A.I. JohnstonIulia PopoviciОценок пока нет
- China Spy 20091022Документ88 страницChina Spy 20091022debgage100% (1)
- David Wen-Wei Chang (Auth.) - China Under Deng Xiaoping - Political and Economic Reform-Palgrave Macmillan UK (1988)Документ324 страницыDavid Wen-Wei Chang (Auth.) - China Under Deng Xiaoping - Political and Economic Reform-Palgrave Macmillan UK (1988)Alex SalaОценок пока нет
- Cybersecurity Policy and The Trump AdministrationДокумент18 страницCybersecurity Policy and The Trump AdministrationEricОценок пока нет
- Psychological OperationsДокумент2 страницыPsychological OperationsMotuzОценок пока нет
- Why Realist Theory Remains Relevant After the Cold WarДокумент4 страницыWhy Realist Theory Remains Relevant After the Cold WarElaineMarçalОценок пока нет
- Analyzing Political Discourse On RedditДокумент20 страницAnalyzing Political Discourse On RedditmscandociaОценок пока нет
- Vimal Chand - Australian Intelligence Failures in The 2006 Fiji Coup - Australian Institute of Professional Intelligence Officers Journal - Vol18 N1 2010Документ52 страницыVimal Chand - Australian Intelligence Failures in The 2006 Fiji Coup - Australian Institute of Professional Intelligence Officers Journal - Vol18 N1 2010Intelligentsiya HqОценок пока нет
- The Three WavesДокумент23 страницыThe Three WavesSalim Ullah100% (1)
- Fiona Hill TestimonyДокумент446 страницFiona Hill TestimonyWashington Examiner100% (1)
- IR Theory Toolbox: Realism Best Explains EmpiricsДокумент126 страницIR Theory Toolbox: Realism Best Explains EmpiricsHemant Sai100% (1)
- Democratic Deficits: Chapter 12Документ16 страницDemocratic Deficits: Chapter 12Renato RibeiroОценок пока нет
- Online Shop Setup Made Easy with ShopifyДокумент38 страницOnline Shop Setup Made Easy with ShopifySlaheddine DardouriОценок пока нет
- Three Maps and Three MisunderstandingsДокумент19 страницThree Maps and Three MisunderstandingsSlaheddine DardouriОценок пока нет
- Tunisian Arabic - Competency Based Language Education Curriculum GuideДокумент98 страницTunisian Arabic - Competency Based Language Education Curriculum GuideSlaheddine DardouriОценок пока нет
- IntroStatistics Obooko Ref0010Документ47 страницIntroStatistics Obooko Ref0010Slaheddine DardouriОценок пока нет
- The Sentient' City and What It MayДокумент21 страницаThe Sentient' City and What It MaySlaheddine DardouriОценок пока нет
- Digitization of Selling Activity and Sales Force Performance An Empirical InvestigationДокумент17 страницDigitization of Selling Activity and Sales Force Performance An Empirical InvestigationSlaheddine DardouriОценок пока нет
- The Social Media ImageДокумент15 страницThe Social Media ImageSlaheddine DardouriОценок пока нет
- An Exploration of Small Business Website Optimization Enablers, Influencers andДокумент29 страницAn Exploration of Small Business Website Optimization Enablers, Influencers andSlaheddine DardouriОценок пока нет
- Big Data, Data Integrity, and The FracturingДокумент11 страницBig Data, Data Integrity, and The FracturingSlaheddine DardouriОценок пока нет
- Emerging Practices and PerspectivesДокумент10 страницEmerging Practices and PerspectivesSlaheddine DardouriОценок пока нет
- Destination Management & Marketing Systems A Reality Check in The Greek Tourism Industry Net-Working or Not-WorkingДокумент31 страницаDestination Management & Marketing Systems A Reality Check in The Greek Tourism Industry Net-Working or Not-WorkingSlaheddine Dardouri100% (1)
- The Complete Outdoorsman's Handbook - A Guide To Outdoor Living and Wilderness SurvivalДокумент108 страницThe Complete Outdoorsman's Handbook - A Guide To Outdoor Living and Wilderness Survivalmtomm100% (2)
- Buzz and Recommendations On The Internet What Impacts On Box-Office SuccessДокумент21 страницаBuzz and Recommendations On The Internet What Impacts On Box-Office SuccessSlaheddine DardouriОценок пока нет
- Art For Art's Sake or Selling UpДокумент24 страницыArt For Art's Sake or Selling UpSlaheddine DardouriОценок пока нет
- Trans-Generational Equity The Transmission of Consumption Practices Between Mother and DaughteДокумент27 страницTrans-Generational Equity The Transmission of Consumption Practices Between Mother and DaughteSlaheddine DardouriОценок пока нет
- Ambush Marketing Disclosure Impact On Attitudes Toward The Ambusher's BrandДокумент18 страницAmbush Marketing Disclosure Impact On Attitudes Toward The Ambusher's BrandSlaheddine DardouriОценок пока нет
- Trust in B-to-BДокумент21 страницаTrust in B-to-BSlaheddine DardouriОценок пока нет
- Analyzing Mental Representations The Contribution of Cognitive MapsДокумент24 страницыAnalyzing Mental Representations The Contribution of Cognitive MapsSlaheddine DardouriОценок пока нет
- Special Issue On The Theme Alternative Forms of Communication in MarketingДокумент5 страницSpecial Issue On The Theme Alternative Forms of Communication in MarketingSlaheddine DardouriОценок пока нет
- Because You'Re Worth It A Study of The Consumer Status ConceptДокумент18 страницBecause You'Re Worth It A Study of The Consumer Status ConceptSlaheddine DardouriОценок пока нет
- An Exploratory Study of The Implications of Free Admission To Museums and MonumentsДокумент15 страницAn Exploratory Study of The Implications of Free Admission To Museums and MonumentsSlaheddine DardouriОценок пока нет
- The Impact of Telepresence in An Online Ad On TheДокумент22 страницыThe Impact of Telepresence in An Online Ad On TheSlaheddine DardouriОценок пока нет
- Influence Des Recommandations D'internautes Le Rôle de La Présence Sociale Et de L'expertiseДокумент26 страницInfluence Des Recommandations D'internautes Le Rôle de La Présence Sociale Et de L'expertiseSlaheddine DardouriОценок пока нет
- Taboo An Underexplored Concept in MarketingДокумент28 страницTaboo An Underexplored Concept in MarketingSlaheddine DardouriОценок пока нет
- Brand Equity Model Integrates Psycho-Cognitive PerspectiveДокумент14 страницBrand Equity Model Integrates Psycho-Cognitive PerspectiveSlaheddine DardouriОценок пока нет
- Analyzing Mental Representations The Contribution of Cognitive MapsДокумент24 страницыAnalyzing Mental Representations The Contribution of Cognitive MapsSlaheddine DardouriОценок пока нет
- Service Relation ShipДокумент28 страницService Relation ShipSlaheddine DardouriОценок пока нет
- Perceived Quality and Customer Satisfaction in B2B TelecommunicationsДокумент23 страницыPerceived Quality and Customer Satisfaction in B2B TelecommunicationsSlaheddine DardouriОценок пока нет
- À Quel Point La Publicité Est-Elle Efficace Généralisations À Partir D'une Méta-Analyse deДокумент29 страницÀ Quel Point La Publicité Est-Elle Efficace Généralisations À Partir D'une Méta-Analyse deSlaheddine DardouriОценок пока нет
- RC AmicusДокумент52 страницыRC AmicusrobertОценок пока нет
- NDA Agreement for ConsultantsДокумент2 страницыNDA Agreement for ConsultantsDaron MalakianoОценок пока нет
- N To Yyyyotification BSPHCL AEE AE IT Manager JR Accounts Clerk Other PostsДокумент7 страницN To Yyyyotification BSPHCL AEE AE IT Manager JR Accounts Clerk Other Postsdeepu kumarОценок пока нет
- HMO Enrolment Form for Pru Life Insurance CorpДокумент2 страницыHMO Enrolment Form for Pru Life Insurance CorpJoanne TadeoОценок пока нет
- 2017 Standards For Business ConductДокумент45 страниц2017 Standards For Business ConductDavid DiepОценок пока нет
- Security For The Digital World Within An Ethical FrameworkДокумент12 страницSecurity For The Digital World Within An Ethical Frameworkhoras siraitОценок пока нет
- Belo Henares Vs Atty GuevarraДокумент18 страницBelo Henares Vs Atty GuevarraJLОценок пока нет
- BiometricsДокумент10 страницBiometricsKrishna Murthy PОценок пока нет
- Information Warfare BookДокумент264 страницыInformation Warfare Bookjasonddennis100% (2)
- Media Society CultureДокумент22 страницыMedia Society CultureDr NoumanОценок пока нет
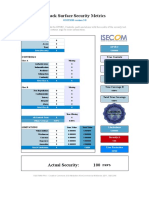
- Rav Calc OSSTMM3Документ2 страницыRav Calc OSSTMM3dion363Оценок пока нет
- Non-Personal Data Report on Governance FrameworkДокумент72 страницыNon-Personal Data Report on Governance FrameworkVivek BadkurОценок пока нет
- 2018.04.24 Edward Burlington - A Brief SynopsisДокумент2 страницы2018.04.24 Edward Burlington - A Brief SynopsisFaireSansDireОценок пока нет
- AI and Cyber SecurityДокумент56 страницAI and Cyber SecuritySumit ThatteОценок пока нет
- Why Supreme Court Under Art 32Документ9 страницWhy Supreme Court Under Art 32manoj ktmОценок пока нет
- Privacy Management Accountability Framework-GDPR EditionДокумент1 страницаPrivacy Management Accountability Framework-GDPR EditionrainbowmapОценок пока нет
- United States v. JonesДокумент34 страницыUnited States v. JonesDoug MataconisОценок пока нет
- Secret Law and The Snowden Revelations: A Response To The Future of Foreign Intelligence: Privacy and Surveillance in A Digital Age, by Laura K. Donohue by HEIDI KITROSSERДокумент10 страницSecret Law and The Snowden Revelations: A Response To The Future of Foreign Intelligence: Privacy and Surveillance in A Digital Age, by Laura K. Donohue by HEIDI KITROSSERNew England Law ReviewОценок пока нет
- Aadhaar Enrolment/ Correction/ Update FormДокумент2 страницыAadhaar Enrolment/ Correction/ Update FormasasasasasОценок пока нет
- AG Ruling On Governor's Office EmailsДокумент28 страницAG Ruling On Governor's Office EmailsNatasha KoreckiОценок пока нет
- Artificial Intelligence in E-Commerce: Legal AspectsДокумент7 страницArtificial Intelligence in E-Commerce: Legal Aspectsagha babarОценок пока нет
- No Generative Artificial IntelligenceДокумент3 страницыNo Generative Artificial IntelligencefundacionvalienteboliviaОценок пока нет
- Ethical Issues in Electronic Commerce: Bette Ann Stead Jackie GilbertДокумент19 страницEthical Issues in Electronic Commerce: Bette Ann Stead Jackie GilbertRizky Maharani R.Оценок пока нет
- Social MediaДокумент15 страницSocial MediaBhavika GholapОценок пока нет
- Informed Consent FormatДокумент3 страницыInformed Consent FormatCarlo Lopez CantadaОценок пока нет
- 2019 - en Digit Main Report With ForewordДокумент98 страниц2019 - en Digit Main Report With ForewordEd PraetorianОценок пока нет
- Psychotronic WeaponsДокумент5 страницPsychotronic WeaponsDOMINO66100% (1)
- 13 EncryptionДокумент15 страниц13 EncryptionArunОценок пока нет
- Quiz Isecurity Quiz - WBTДокумент6 страницQuiz Isecurity Quiz - WBTLuis Angel SantillanОценок пока нет
- Adult Clinical Interview Form PDFДокумент20 страницAdult Clinical Interview Form PDFO KiОценок пока нет
- Defensive Cyber Mastery: Expert Strategies for Unbeatable Personal and Business SecurityОт EverandDefensive Cyber Mastery: Expert Strategies for Unbeatable Personal and Business SecurityРейтинг: 5 из 5 звезд5/5 (1)
- Python for Beginners: The 1 Day Crash Course For Python Programming In The Real WorldОт EverandPython for Beginners: The 1 Day Crash Course For Python Programming In The Real WorldОценок пока нет
- Ultimate Guide to LinkedIn for Business: Access more than 500 million people in 10 minutesОт EverandUltimate Guide to LinkedIn for Business: Access more than 500 million people in 10 minutesРейтинг: 5 из 5 звезд5/5 (5)
- So You Want to Start a Podcast: Finding Your Voice, Telling Your Story, and Building a Community that Will ListenОт EverandSo You Want to Start a Podcast: Finding Your Voice, Telling Your Story, and Building a Community that Will ListenРейтинг: 4.5 из 5 звезд4.5/5 (35)
- The Digital Marketing Handbook: A Step-By-Step Guide to Creating Websites That SellОт EverandThe Digital Marketing Handbook: A Step-By-Step Guide to Creating Websites That SellРейтинг: 5 из 5 звезд5/5 (6)
- How to Be Fine: What We Learned by Living by the Rules of 50 Self-Help BooksОт EverandHow to Be Fine: What We Learned by Living by the Rules of 50 Self-Help BooksРейтинг: 4.5 из 5 звезд4.5/5 (48)
- How to Do Nothing: Resisting the Attention EconomyОт EverandHow to Do Nothing: Resisting the Attention EconomyРейтинг: 4 из 5 звезд4/5 (421)
- Content Rules: How to Create Killer Blogs, Podcasts, Videos, Ebooks, Webinars (and More) That Engage Customers and Ignite Your BusinessОт EverandContent Rules: How to Create Killer Blogs, Podcasts, Videos, Ebooks, Webinars (and More) That Engage Customers and Ignite Your BusinessРейтинг: 4.5 из 5 звезд4.5/5 (42)
- The Wires of War: Technology and the Global Struggle for PowerОт EverandThe Wires of War: Technology and the Global Struggle for PowerРейтинг: 4 из 5 звезд4/5 (34)
- Nine Algorithms That Changed the Future: The Ingenious Ideas That Drive Today's ComputersОт EverandNine Algorithms That Changed the Future: The Ingenious Ideas That Drive Today's ComputersРейтинг: 5 из 5 звезд5/5 (7)
- Ultimate Guide to YouTube for BusinessОт EverandUltimate Guide to YouTube for BusinessРейтинг: 5 из 5 звезд5/5 (1)
- SEO: The Ultimate Guide to Optimize Your Website. Learn Effective Techniques to Reach the First Page and Finally Improve Your Organic Traffic.От EverandSEO: The Ultimate Guide to Optimize Your Website. Learn Effective Techniques to Reach the First Page and Finally Improve Your Organic Traffic.Рейтинг: 5 из 5 звезд5/5 (5)
- Facing Cyber Threats Head On: Protecting Yourself and Your BusinessОт EverandFacing Cyber Threats Head On: Protecting Yourself and Your BusinessРейтинг: 4.5 из 5 звезд4.5/5 (27)
- The $1,000,000 Web Designer Guide: A Practical Guide for Wealth and Freedom as an Online FreelancerОт EverandThe $1,000,000 Web Designer Guide: A Practical Guide for Wealth and Freedom as an Online FreelancerРейтинг: 4.5 из 5 звезд4.5/5 (22)
- Monitored: Business and Surveillance in a Time of Big DataОт EverandMonitored: Business and Surveillance in a Time of Big DataРейтинг: 4 из 5 звезд4/5 (1)
- A Great Online Dating Profile: 30 Tips to Get Noticed and Get More ResponsesОт EverandA Great Online Dating Profile: 30 Tips to Get Noticed and Get More ResponsesРейтинг: 3.5 из 5 звезд3.5/5 (2)
- More Porn - Faster!: 50 Tips & Tools for Faster and More Efficient Porn BrowsingОт EverandMore Porn - Faster!: 50 Tips & Tools for Faster and More Efficient Porn BrowsingРейтинг: 3.5 из 5 звезд3.5/5 (23)
- Coding for Beginners and Kids Using Python: Python Basics for Beginners, High School Students and Teens Using Project Based LearningОт EverandCoding for Beginners and Kids Using Python: Python Basics for Beginners, High School Students and Teens Using Project Based LearningРейтинг: 3 из 5 звезд3/5 (1)
- SEO 2021: Learn search engine optimization with smart internet marketing strategiesОт EverandSEO 2021: Learn search engine optimization with smart internet marketing strategiesРейтинг: 5 из 5 звезд5/5 (6)
- The Ultimate LinkedIn Sales Guide: How to Use Digital and Social Selling to Turn LinkedIn into a Lead, Sales and Revenue Generating MachineОт EverandThe Ultimate LinkedIn Sales Guide: How to Use Digital and Social Selling to Turn LinkedIn into a Lead, Sales and Revenue Generating MachineОценок пока нет