Вам также может понравиться
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (400)
- Art ChinoДокумент7 страницArt ChinodanielОценок пока нет
- Lógica Difusa y ProbabilidadДокумент4 страницыLógica Difusa y ProbabilidaddanielОценок пока нет
- 2017 Estadística y Clasificación de Abortos Según SeguridadДокумент10 страниц2017 Estadística y Clasificación de Abortos Según SeguridaddanielОценок пока нет
- Mimics Student Edition Course BookДокумент83 страницыMimics Student Edition Course Bookleobia100% (1)
- Modelo en Lógica Difusa de PercepciónДокумент13 страницModelo en Lógica Difusa de PercepcióndanielОценок пока нет
- Lógica DIfusa Salud Enfermedad y MalestarДокумент34 страницыLógica DIfusa Salud Enfermedad y MalestardanielОценок пока нет
- Neural Fuzzy Systems LectureДокумент315 страницNeural Fuzzy Systems LecturedanielОценок пока нет
- Patients' Reports or Clinicians' Assessments - Wich Are Better For PrognosticatingДокумент6 страницPatients' Reports or Clinicians' Assessments - Wich Are Better For PrognosticatingdanielОценок пока нет
- Self-Rated Health and Long-Term Prognosis of DepressionДокумент9 страницSelf-Rated Health and Long-Term Prognosis of DepressiondanielОценок пока нет
- Transparent Reporting of A Multivariable Prediction Model For Individual Prognosis or Diagnosis (TRIPOD) The TRIPOD StatementДокумент10 страницTransparent Reporting of A Multivariable Prediction Model For Individual Prognosis or Diagnosis (TRIPOD) The TRIPOD StatementdanielОценок пока нет
- The Knowledge System Underpinning Healthcare Is Not Fit For Purpose and Must ChangeДокумент3 страницыThe Knowledge System Underpinning Healthcare Is Not Fit For Purpose and Must ChangedanielОценок пока нет
- Assessing Prognosis From Nonrandomized Studies - An Example From Brain Arteriovenous MalformationsДокумент4 страницыAssessing Prognosis From Nonrandomized Studies - An Example From Brain Arteriovenous MalformationsdanielОценок пока нет
- Comparing Risk Prediction ModelsДокумент2 страницыComparing Risk Prediction ModelsdanielОценок пока нет
- Changing Clinical Behaviour by Making Guidelines SpecificДокумент3 страницыChanging Clinical Behaviour by Making Guidelines SpecificdanielОценок пока нет
- Information in PracticeДокумент8 страницInformation in PracticecherioОценок пока нет
- Changing Clinical Behaviour by Making Guidelines SpecificДокумент3 страницыChanging Clinical Behaviour by Making Guidelines SpecificdanielОценок пока нет
- Assessing Prognosis From Nonrandomized Studies - An Example From Brain Arteriovenous MalformationsДокумент4 страницыAssessing Prognosis From Nonrandomized Studies - An Example From Brain Arteriovenous MalformationsdanielОценок пока нет
- Unexpected Predictor-Outcome Associations in Clinical Prediction Research - Auses and SolutionsДокумент7 страницUnexpected Predictor-Outcome Associations in Clinical Prediction Research - Auses and SolutionsdanielОценок пока нет
- Prognostic Modeling With Logistic Regression Analysis - in Search of A Sensible Strategy in Small Data SetsДокумент12 страницPrognostic Modeling With Logistic Regression Analysis - in Search of A Sensible Strategy in Small Data SetsdanielОценок пока нет
- Application of Bayesian Classifier For The Diagnosis of Dental PainДокумент15 страницApplication of Bayesian Classifier For The Diagnosis of Dental PaindanielОценок пока нет
- The Cost of Dichotomising Continuous VariablesДокумент1 страницаThe Cost of Dichotomising Continuous VariablesLakshmi SethОценок пока нет
- An Address On PrognosisДокумент2 страницыAn Address On PrognosisdanielОценок пока нет
- Computational Intelligence in Medical Decision Support - A Comparison of Two Neuro-Fuzzy SystemsДокумент8 страницComputational Intelligence in Medical Decision Support - A Comparison of Two Neuro-Fuzzy SystemsdanielОценок пока нет
- Basic EpidemiologyДокумент226 страницBasic EpidemiologyvladimirjazzОценок пока нет
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (344)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (121)
- Superelevation Calculator: Superelevation Data Dialog BoxДокумент2 страницыSuperelevation Calculator: Superelevation Data Dialog Boxhussnainali aliОценок пока нет
- HAL MPD GBA CustomerGuideДокумент24 страницыHAL MPD GBA CustomerGuidetxcrudeОценок пока нет
- Grade 2 DLL MATH 2 Q4 Week 8Документ12 страницGrade 2 DLL MATH 2 Q4 Week 8Chad Dela CruzОценок пока нет
- 500 IBPS Clerk Quantitative Aptitude Questions and AnswersДокумент115 страниц500 IBPS Clerk Quantitative Aptitude Questions and AnswerssatyaОценок пока нет
- Hecke's L-FunctionsДокумент102 страницыHecke's L-FunctionsluisufspaiandreОценок пока нет
- DSP SamplingДокумент36 страницDSP Samplingin_visible100% (1)
- Programs For C Building Blocks:: 1. WAP in C To Print "HELLO WORLD"Документ86 страницPrograms For C Building Blocks:: 1. WAP in C To Print "HELLO WORLD"Gautam VermaОценок пока нет
- Data Structures Through C 1Документ209 страницData Structures Through C 1Abhay DabhadeОценок пока нет
- Control of A DC Motor DriveДокумент25 страницControl of A DC Motor DrivePoliConDrive0% (1)
- Rational Numbers: Class VIII. Maths WorksheetДокумент3 страницыRational Numbers: Class VIII. Maths WorksheetThe world Of HarshОценок пока нет
- Fick's Laws of DiffusionДокумент5 страницFick's Laws of Diffusionvijay kumar honnaliОценок пока нет
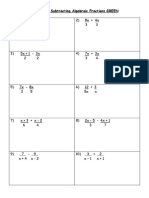
- Algebraic FractionДокумент4 страницыAlgebraic FractionBaiquinda ElzulfaОценок пока нет
- 6 Differential CalculusДокумент35 страниц6 Differential CalculusPankaj SahuОценок пока нет
- PERT HO 19 - RlNav30RMXДокумент2 страницыPERT HO 19 - RlNav30RMXSHIKHAR ARORAОценок пока нет
- Microeconomics Cha 4Документ8 страницMicroeconomics Cha 4haile GetachewuОценок пока нет
- Compressibility Modelling in PetrelДокумент10 страницCompressibility Modelling in PetrelMuhamad Afiq RosnanОценок пока нет
- Differential Calculus 1Документ12 страницDifferential Calculus 1Jeffcaster ComelОценок пока нет
- Eulerian Graph FinalДокумент11 страницEulerian Graph FinalBishal PatangiaОценок пока нет
- (Bart M. Ter Haar Romeny) Front-End Vision and Multi-Scale Image Analysis - Multi-Scale Computer Vision Theory and Applications (2003)Документ470 страниц(Bart M. Ter Haar Romeny) Front-End Vision and Multi-Scale Image Analysis - Multi-Scale Computer Vision Theory and Applications (2003)mvannierОценок пока нет
- Introduction To PLSQLДокумент19 страницIntroduction To PLSQLSpartanz RuleОценок пока нет
- Tugas1 - IDPS6602 - 06398 - ADENTA VALENTHARIQ ASWANДокумент6 страницTugas1 - IDPS6602 - 06398 - ADENTA VALENTHARIQ ASWANValen ThariqОценок пока нет
- Silabus Manajemen StrategikДокумент11 страницSilabus Manajemen StrategikKarina AprilliaОценок пока нет
- Soal UAS Ekonometrika 2018Документ8 страницSoal UAS Ekonometrika 2018Ayu YapriyantiОценок пока нет
- Hardy Cross Continuous Frames of Reinforced ConcreteДокумент361 страницаHardy Cross Continuous Frames of Reinforced ConcreteCarson BakerОценок пока нет
- D.A.V. Public School, Berhampur, Odisha: ND TH THДокумент3 страницыD.A.V. Public School, Berhampur, Odisha: ND TH THSimanchal SadangiОценок пока нет
- The Role of The Ramanujan Conjecture in Analytic Number TheoryДокумент54 страницыThe Role of The Ramanujan Conjecture in Analytic Number TheoryLuis Alberto FuentesОценок пока нет
- CRIMTCS1 FingerprintДокумент31 страницаCRIMTCS1 Fingerprintcamille capalacОценок пока нет
- Data Structure Using C++ - Elective IIIДокумент2 страницыData Structure Using C++ - Elective IIIsneha_eceОценок пока нет
- Forecasting With Artificial Intelligence: Theory and ApplicationsДокумент441 страницаForecasting With Artificial Intelligence: Theory and ApplicationsLong Tran KimОценок пока нет
- EbnfДокумент21 страницаEbnfIan ChuahОценок пока нет