Вам также может понравиться
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (121)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (400)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5795)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (345)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- Payment SystemДокумент24 страницыPayment SystemTooba HashmiОценок пока нет
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- How The American Dream Has Changed Over TimeДокумент3 страницыHow The American Dream Has Changed Over TimeKellie ClarkОценок пока нет
- About Me-1Документ2 страницыAbout Me-1Don't Talking100% (1)
- Entrepreneurship and The EconomyДокумент15 страницEntrepreneurship and The EconomyDennis ValdezОценок пока нет
- CPP Form (New License)Документ4 страницыCPP Form (New License)Kopil uddin NishanОценок пока нет
- Air Passenger Service Quality in Bangladesh: An Analysis On Biman Bangladesh Airlines LimitedДокумент55 страницAir Passenger Service Quality in Bangladesh: An Analysis On Biman Bangladesh Airlines LimitedRupa Banik100% (1)
- 6-Directory Officers EmployeesДокумент771 страница6-Directory Officers EmployeesBikki KumarОценок пока нет
- Mining IndustryДокумент115 страницMining Industrykanchanthebest100% (1)
- Exercise 1.1: Obs ID SBP DBP SEX AGE WT 1 2 3 4 5Документ2 страницыExercise 1.1: Obs ID SBP DBP SEX AGE WT 1 2 3 4 5askazy007Оценок пока нет
- Concave Functions of Two Variables: X XX XДокумент4 страницыConcave Functions of Two Variables: X XX Xaskazy007Оценок пока нет
- The Annals of Statistics 10.1214/12-AOS1003 Institute of Mathematical StatisticsДокумент36 страницThe Annals of Statistics 10.1214/12-AOS1003 Institute of Mathematical Statisticsaskazy007Оценок пока нет
- The LOGISTIC Procedure The LOGISTIC ProcedureДокумент10 страницThe LOGISTIC Procedure The LOGISTIC Procedureaskazy007Оценок пока нет
- Water Study Model SelectionДокумент8 страницWater Study Model Selectionaskazy007Оценок пока нет
- Chapter 5 Discrete Choice ModelsДокумент19 страницChapter 5 Discrete Choice Modelsaskazy007100% (1)
- P Values Are Random VariablesДокумент5 страницP Values Are Random Variablesaskazy007Оценок пока нет
- Stat ComputingДокумент329 страницStat Computingaskazy007Оценок пока нет
- 206 Hwk3 SolutionsДокумент3 страницы206 Hwk3 Solutionsaskazy007Оценок пока нет
- Contol of QuairyststaeДокумент2 страницыContol of Quairyststaeaskazy007Оценок пока нет
- Essentials of Stochastic Processes: Hello Word!Документ1 страницаEssentials of Stochastic Processes: Hello Word!askazy007Оценок пока нет
- Learning With Hidden Variables - EM AlgorithmДокумент31 страницаLearning With Hidden Variables - EM AlgorithmMary JansiОценок пока нет
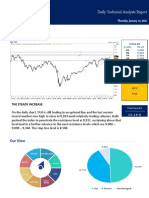
- Daily Technical Analysis Report: Main IndexДокумент3 страницыDaily Technical Analysis Report: Main IndexAbdullah MantawyОценок пока нет
- NTSE MAT Solved Sample Paper 1 PDFДокумент17 страницNTSE MAT Solved Sample Paper 1 PDFAlmelu AvinashОценок пока нет
- Ecl Annual Report 2018-19Документ208 страницEcl Annual Report 2018-19Rohit VishwasОценок пока нет
- Depreciation Solution PDFДокумент10 страницDepreciation Solution PDFDivya PunjabiОценок пока нет
- Strategic Human Resource Management-A FrameworkДокумент21 страницаStrategic Human Resource Management-A FrameworkkinjalОценок пока нет
- NDT and Tpi Control1Документ87 страницNDT and Tpi Control1KyОценок пока нет
- BASFINE - Banks HomeworkДокумент5 страницBASFINE - Banks HomeworkDanaОценок пока нет
- Andy Bushak InterviewДокумент7 страницAndy Bushak InterviewLucky ChopraОценок пока нет
- Imp WebsitesДокумент21 страницаImp WebsitesMeenakshi S. RajpurohitОценок пока нет
- Research Paper Electric Vehicles (Autorecovered)Документ3 страницыResearch Paper Electric Vehicles (Autorecovered)AryanОценок пока нет
- ROSALINDAДокумент10 страницROSALINDAIan PaduaОценок пока нет
- Mindquest Rules 2024Документ6 страницMindquest Rules 2024carrybabaahmmmОценок пока нет
- Personnel Planning and Recruiting: Chapter-5Документ15 страницPersonnel Planning and Recruiting: Chapter-5Dayittohin JahidОценок пока нет
- Full Download Solution Manual For Global Investments 6 e 6th Edition Bruno Solnik Dennis Mcleavey PDF Full ChapterДокумент36 страницFull Download Solution Manual For Global Investments 6 e 6th Edition Bruno Solnik Dennis Mcleavey PDF Full Chapterwaycotgareb5ewy100% (18)
- Weber - S Least Cost TheoryДокумент12 страницWeber - S Least Cost TheoryadityaОценок пока нет
- Channel ManagementДокумент8 страницChannel Managementsajid bhattiОценок пока нет
- CSZ Sfi Standard v4Документ7 страницCSZ Sfi Standard v4Shingirai PfumayarambaОценок пока нет
- Summer ASQ 2010Документ6 страницSummer ASQ 2010autonomyallianceОценок пока нет
- Business Chapter 1 - 24 4 2018Документ14 страницBusiness Chapter 1 - 24 4 2018Aishani ToolseeОценок пока нет
- Mint E-Paper 2Документ23 страницыMint E-Paper 2Parthasarathi MishraОценок пока нет
- The Lawton Instrumental Activities of Daily Living ScaleДокумент2 страницыThe Lawton Instrumental Activities of Daily Living ScaleGEN ERIGBUAGASОценок пока нет