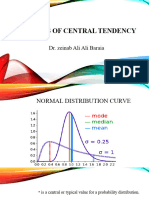
Вам также может понравиться
- Lesson 5 Model SelectionДокумент41 страницаLesson 5 Model SelectionmaartenwildersОценок пока нет
- Multiple Linear Regression 13112023 063212pmДокумент49 страницMultiple Linear Regression 13112023 063212pmAHSAN HAMEEDОценок пока нет
- Lecture 4 Intro To ML 27 03 2023 27032023 041559pmДокумент50 страницLecture 4 Intro To ML 27 03 2023 27032023 041559pmGaylethunder007Оценок пока нет
- Class 13 Optimizing The Training ProcessДокумент20 страницClass 13 Optimizing The Training ProcessSumana BasuОценок пока нет
- Ensemble Learning MethodsДокумент24 страницыEnsemble Learning Methodskhatri81100% (1)
- Mathematical ModellingДокумент29 страницMathematical ModellingSujith DeepakОценок пока нет
- C4.5 and CHAID Algorithm: Pavan J Joshi 2010MCS2095 Special Topics in Database SystemsДокумент30 страницC4.5 and CHAID Algorithm: Pavan J Joshi 2010MCS2095 Special Topics in Database SystemsFidia DtaОценок пока нет
- Sampling Fundamentals for Statistical AnalysisДокумент64 страницыSampling Fundamentals for Statistical AnalysisPrakshal GangwalОценок пока нет
- Central Tendency & Measures of SpreadДокумент20 страницCentral Tendency & Measures of SpreadPragya RoyОценок пока нет
- Statistics Interview 02Документ30 страницStatistics Interview 02Sudharshan Venkatesh100% (1)
- Missing Data Analysis: University College London, 2015Документ37 страницMissing Data Analysis: University College London, 2015charudattasonawane55Оценок пока нет
- Path AnalysisДокумент25 страницPath AnalysisMiraОценок пока нет
- Teknik Komputasi (TEI 116) : 3 Sks Oleh: Husni Rois Ali, S.T., M.Eng. Noor Akhmad Setiawan, S.T., M.T., PH.DДокумент44 страницыTeknik Komputasi (TEI 116) : 3 Sks Oleh: Husni Rois Ali, S.T., M.Eng. Noor Akhmad Setiawan, S.T., M.T., PH.DblackzenyОценок пока нет
- ESE306-lecture 1Документ34 страницыESE306-lecture 1masamba10Оценок пока нет
- Comp 3111Документ83 страницыComp 3111Kamau GabrielОценок пока нет
- COMP2230 Introduction To Algorithmics: Lecture OverviewДокумент35 страницCOMP2230 Introduction To Algorithmics: Lecture OverviewMrZaggyОценок пока нет
- 3 Measures of Central Tendency (Mean, Median)Документ32 страницы3 Measures of Central Tendency (Mean, Median)Mohamed FathyОценок пока нет
- Measures of Central Tendency: The Mean, Median, and ModeДокумент6 страницMeasures of Central Tendency: The Mean, Median, and ModeMd. Abdulla-Al-SabbyОценок пока нет
- 2) Business Analytics. PreprocessingДокумент19 страниц2) Business Analytics. PreprocessingAni KhachatryanОценок пока нет
- Operations Research Lecture Notes by Tanmoy DasДокумент11 страницOperations Research Lecture Notes by Tanmoy Dasrafsan rahatОценок пока нет
- ML Module 5 2022 PDFДокумент31 страницаML Module 5 2022 PDFjanuary100% (1)
- Classification Models: An Overview of Ensemble Learning TechniquesДокумент40 страницClassification Models: An Overview of Ensemble Learning TechniquesFriday Jones100% (1)
- Measures of Location - MIДокумент12 страницMeasures of Location - MISaudulla Jameel JameelОценок пока нет
- Model Selection StrategiesДокумент20 страницModel Selection StrategiesIlinca MariaОценок пока нет
- Theory in Machine LearningДокумент47 страницTheory in Machine LearningSreetam Ganguly100% (2)
- Measures of Central TendencyДокумент85 страницMeasures of Central TendencyAngelica TalastasinОценок пока нет
- Machine Learning Interview Questions.Документ43 страницыMachine Learning Interview Questions.hari krishna reddy100% (1)
- Module02 LogisticRegressionДокумент29 страницModule02 LogisticRegressionrohan kalidindiОценок пока нет
- MB0032 Operations Research AssignmentsДокумент12 страницMB0032 Operations Research Assignmentspranay srivastavaОценок пока нет
- Clustering (Unit 3)Документ71 страницаClustering (Unit 3)vedang maheshwari100% (1)
- ESO 208A: Introduction to Computational MethodsДокумент26 страницESO 208A: Introduction to Computational MethodsAswerОценок пока нет
- Hypothesis Testing Slide 14Документ45 страницHypothesis Testing Slide 14Mario BrossОценок пока нет
- CSO504 Machine Learning: Evaluation and Error Analysis Regularization Koustav Rudra 24/08/2022Документ36 страницCSO504 Machine Learning: Evaluation and Error Analysis Regularization Koustav Rudra 24/08/2022Being IITianОценок пока нет
- Measures of Variance ExplainedДокумент5 страницMeasures of Variance ExplainedsimonОценок пока нет
- Lecture1 - Introduction To Algorithmics and Maths RevisionДокумент87 страницLecture1 - Introduction To Algorithmics and Maths RevisionMrZaggyОценок пока нет
- ds module 4Документ73 страницыds module 4Prathik SrinivasОценок пока нет
- Unit VДокумент27 страницUnit V05Bala SaatvikОценок пока нет
- Simulation and Modelling: Chapter FourДокумент19 страницSimulation and Modelling: Chapter FourLet’s Talk TechОценок пока нет
- Chapter3 - Measures of Central Tendency Ungrouped DataДокумент25 страницChapter3 - Measures of Central Tendency Ungrouped DataDionne Rei BontiaОценок пока нет
- Maths For DAДокумент38 страницMaths For DApallav adhikariОценок пока нет
- Artificial Intelligence Chapter 18 (Updated)Документ19 страницArtificial Intelligence Chapter 18 (Updated)Rahul SrinivasОценок пока нет
- Image Restoration Is The Process of Removal of Noise in An IMAGEДокумент7 страницImage Restoration Is The Process of Removal of Noise in An IMAGERishita jainОценок пока нет
- DOEpptДокумент16 страницDOEpptJeevanantham KannanОценок пока нет
- Mathematical ModelingДокумент33 страницыMathematical ModelingIsma OllshopОценок пока нет
- Computational Statistics: Unit - 5Документ24 страницыComputational Statistics: Unit - 5yenopОценок пока нет
- CS103 Chapter6Документ46 страницCS103 Chapter6Mem MemОценок пока нет
- Measures of Central TendencyДокумент58 страницMeasures of Central TendencyAlyanna CrisologoОценок пока нет
- Reviewer CHAPTER 12Документ8 страницReviewer CHAPTER 12Krisha AvorqueОценок пока нет
- Measures of Central Tendency Ungrouped DataДокумент28 страницMeasures of Central Tendency Ungrouped DataDionne Rei BontiaОценок пока нет
- Checking Model AssumptionsДокумент4 страницыChecking Model AssumptionssmyczОценок пока нет
- Methods of Data SummarizationДокумент50 страницMethods of Data SummarizationEngdaw Asmare GeramiОценок пока нет
- Advanced Statistics Manual PDFДокумент258 страницAdvanced Statistics Manual PDFhamartinez100% (3)
- Error Propagation 1Документ11 страницError Propagation 1Seeron SivashankarОценок пока нет
- Specification Bias: Dr. Seema Gupta Department of Statistics Ram Lal Anand CollegeДокумент22 страницыSpecification Bias: Dr. Seema Gupta Department of Statistics Ram Lal Anand Collegeshivani singhОценок пока нет
- OutliersДокумент7 страницOutliersRavikanth ReddyОценок пока нет
- Theory of RegressionДокумент843 страницыTheory of RegressionvdhienОценок пока нет
- Practical Design of Experiments: DoE Made EasyОт EverandPractical Design of Experiments: DoE Made EasyРейтинг: 4.5 из 5 звезд4.5/5 (7)
- Revenue Sharing ContractДокумент3 страницыRevenue Sharing ContractSamantha YuОценок пока нет
- Lee's Framework - Efficient Vs Responsive Supply ChainsДокумент1 страницаLee's Framework - Efficient Vs Responsive Supply ChainsSamantha YuОценок пока нет
- 80827v00 Machine Learning Section4 Ebook v03 PDFДокумент20 страниц80827v00 Machine Learning Section4 Ebook v03 PDFviejopiscoleroОценок пока нет
- Lecture 5 PostДокумент26 страницLecture 5 PostSamantha YuОценок пока нет
- Fisher's Framework - Demand Vs Supply UncertaintiesДокумент1 страницаFisher's Framework - Demand Vs Supply UncertaintiesSamantha YuОценок пока нет
- Chapter 5 and 6 Bond Characteristics and PricingДокумент29 страницChapter 5 and 6 Bond Characteristics and PricingSamantha YuОценок пока нет
- Assign1 - SolДокумент9 страницAssign1 - SolSamantha YuОценок пока нет
- Coordination and Collaboration (4th C)Документ1 страницаCoordination and Collaboration (4th C)Samantha YuОценок пока нет
- Supply Chain Management (SCM) - DefinitionДокумент1 страницаSupply Chain Management (SCM) - DefinitionSamantha YuОценок пока нет
- 80827v00 Machine Learning Section4 Ebook v03Документ10 страниц80827v00 Machine Learning Section4 Ebook v03Samantha YuОценок пока нет
- Mod1 SummaryДокумент3 страницыMod1 SummarySamantha YuОценок пока нет
- Costs and Benefits Through Bureaucratic Lenses - Example of A Highway ProjectДокумент25 страницCosts and Benefits Through Bureaucratic Lenses - Example of A Highway ProjectSamantha YuОценок пока нет
- Lecture 2Документ21 страницаLecture 2Samantha YuОценок пока нет
- Lecture 3Документ23 страницыLecture 3Samantha YuОценок пока нет
- Hku Msba BrochureДокумент10 страницHku Msba Brochurelovingbooks1Оценок пока нет
- Chapter 5 Valuing BondsДокумент34 страницыChapter 5 Valuing BondsSamantha YuОценок пока нет
- Econ 371 Business Finance 1: Pirapa TharmalingamДокумент26 страницEcon 371 Business Finance 1: Pirapa TharmalingamSamantha YuОценок пока нет
- PS3 L22 L31Документ2 страницыPS3 L22 L31Samantha YuОценок пока нет
- Actsc371f15outline Section 1Документ3 страницыActsc371f15outline Section 1Samantha YuОценок пока нет
- CAPM Chapter 09 Multiple ChoiceДокумент65 страницCAPM Chapter 09 Multiple ChoicePRAKОценок пока нет
- FM #1 (LV 3.66)Документ59 страницFM #1 (LV 3.66)Samantha YuОценок пока нет
- Review of BA II PLUS Calculator FunctionsДокумент31 страницаReview of BA II PLUS Calculator FunctionsbookosmailОценок пока нет
- How Gourmet Foods Hired a Trainer to Boost Morale and ProfitsДокумент2 страницыHow Gourmet Foods Hired a Trainer to Boost Morale and ProfitsSamantha Yu67% (9)
- Formulas For SOA/CAS Exam FM/2Документ15 страницFormulas For SOA/CAS Exam FM/2jeff_cunningham_11100% (3)
- CAPM NotesДокумент8 страницCAPM NotesSamantha YuОценок пока нет
- Stat 330Документ134 страницыStat 330Samantha YuОценок пока нет
- FM 09 05quesДокумент61 страницаFM 09 05queserg534Оценок пока нет
- Stat331-Multiple Linear RegressionДокумент13 страницStat331-Multiple Linear RegressionSamantha YuОценок пока нет
- AWGN MatlabДокумент4 страницыAWGN MatlabKhaidir YazidОценок пока нет
- Ngailo EdwardДокумент83 страницыNgailo Edwardsharktale2828Оценок пока нет
- Community Project: Friedman TestДокумент3 страницыCommunity Project: Friedman TestLeah Mae AgustinОценок пока нет
- WORKSHEET 1, Module 4, Nguyen Thi Xoan, Bspsy 1Документ2 страницыWORKSHEET 1, Module 4, Nguyen Thi Xoan, Bspsy 1Nguyen Xoan100% (1)
- Popcorn DOE ProjectДокумент10 страницPopcorn DOE Projectalliosagie100% (2)
- Casio Calc RegressionДокумент2 страницыCasio Calc Regression'Tahir AnsariОценок пока нет
- ForecastingДокумент20 страницForecastingAndrewVazОценок пока нет
- Chapter 3 Sample Size Calculation and SamplingДокумент60 страницChapter 3 Sample Size Calculation and Samplingestela aberaОценок пока нет
- RENR 690 – Geostatistics Lab in RДокумент6 страницRENR 690 – Geostatistics Lab in RWladimir Gonzalo RondanОценок пока нет
- Normal Curve and Standard Score-1 2Документ31 страницаNormal Curve and Standard Score-1 2Angela Grace CatralОценок пока нет
- What Is A General Linear ModelДокумент70 страницWhat Is A General Linear ModelAshish PandeyОценок пока нет
- Roberson Et Al. (2007) Does The Measure of Dispersion Matter in Multilevel ResearchДокумент25 страницRoberson Et Al. (2007) Does The Measure of Dispersion Matter in Multilevel ResearchCrónicasОценок пока нет
- How Coffee Affects HeightДокумент10 страницHow Coffee Affects Heightapi-356553666Оценок пока нет
- Six Sigma Black Belt Project On: Reduction in Breakage in BiscuitsДокумент42 страницыSix Sigma Black Belt Project On: Reduction in Breakage in BiscuitsHombing Haryanto100% (1)
- Sampling Two Stage SamplingДокумент21 страницаSampling Two Stage SamplingFitri JuandaОценок пока нет
- IGNOU Statistics Guide Explains Hypothesis TestingДокумент16 страницIGNOU Statistics Guide Explains Hypothesis TestingKingKaliaОценок пока нет
- 1) Statement: Descriptive Analytics, Is The Conventional Form of Business Intelligence and Data Analysis. B. FalseДокумент21 страница1) Statement: Descriptive Analytics, Is The Conventional Form of Business Intelligence and Data Analysis. B. False21P410 - VARUN M100% (1)
- 06 Augste Lames 2011Документ6 страниц06 Augste Lames 2011cbales99Оценок пока нет
- POLC 6314 - Homework 4 - DELAOДокумент16 страницPOLC 6314 - Homework 4 - DELAOKaty DОценок пока нет
- Week 11 Lecture 20Документ16 страницWeek 11 Lecture 20Muhammad FaisalОценок пока нет
- Chapter 9Документ14 страницChapter 9Khay OngОценок пока нет
- Multilevel Linear Modeling: Heather Kennedy CURR 7004 Dr. BistaДокумент19 страницMultilevel Linear Modeling: Heather Kennedy CURR 7004 Dr. BistaSTAR ScholarsОценок пока нет
- Voluntary Sampling Design: February 2015Документ17 страницVoluntary Sampling Design: February 2015may ann capileОценок пока нет
- Two Sample Hotelling's T SquareДокумент30 страницTwo Sample Hotelling's T SquareJoselene MarquesОценок пока нет
- DSCI 6003 Class NotesДокумент7 страницDSCI 6003 Class NotesDesire MatoubaОценок пока нет
- MSA 4th EditionДокумент54 страницыMSA 4th EditionMarcos ROSSIОценок пока нет
- Lec 12 - Regresi Multi-LinierДокумент22 страницыLec 12 - Regresi Multi-LinierAsal ReviewОценок пока нет
- 8 - Analyze - Hypothesis Testing Non Normal Data - P2Документ37 страниц8 - Analyze - Hypothesis Testing Non Normal Data - P2Paraschivescu CristinaОценок пока нет
- 1516 QS025 - 2 SolutionДокумент21 страница1516 QS025 - 2 SolutionFira dinaОценок пока нет
- III B.Tech I Semester Probability and Statistics Exam QuestionsДокумент8 страницIII B.Tech I Semester Probability and Statistics Exam Questionsgeddam06108825Оценок пока нет