Вам также может понравиться
- A705F Schematic Circuit Diagram HALABTECHДокумент11 страницA705F Schematic Circuit Diagram HALABTECHbcscneg0% (1)
- Final Exam DiassДокумент9 страницFinal Exam Diassbaby rafa100% (3)
- Aljotronic Control 2Документ30 страницAljotronic Control 2Fuzzbuddy100% (1)
- Sipij040309 PDFДокумент18 страницSipij040309 PDFsipijОценок пока нет
- Ma 2012Документ16 страницMa 2012Zahir MahroukОценок пока нет
- Liu Robust Video Super-Resolution ICCV 2017 PaperДокумент9 страницLiu Robust Video Super-Resolution ICCV 2017 PaperEkoОценок пока нет
- Adding Amount of Motion As A Psqa Parameter: Irisa/Inria Campus Universitaire de Beaulieu, 35042 Rennes Cedex, FranceДокумент13 страницAdding Amount of Motion As A Psqa Parameter: Irisa/Inria Campus Universitaire de Beaulieu, 35042 Rennes Cedex, FranceHenry Moreno DíazОценок пока нет
- NR Va RRДокумент2 страницыNR Va RRHoàng Mạnh QuangОценок пока нет
- An Image-Based Approach To Video Copy Detection With Spatio-Temporal Post-FilteringДокумент27 страницAn Image-Based Approach To Video Copy Detection With Spatio-Temporal Post-FilteringAchuth VishnuОценок пока нет
- 2011 - IEEE - Image Quality Assessment by Separately Evaluating Detail Losses and Additive ImpairmentsДокумент15 страниц2011 - IEEE - Image Quality Assessment by Separately Evaluating Detail Losses and Additive Impairmentsarg.xuxuОценок пока нет
- Activity-Based Motion Estimation Scheme ForДокумент11 страницActivity-Based Motion Estimation Scheme ForYogananda PatnaikОценок пока нет
- Research PaperДокумент9 страницResearch Papersharmaharsh506325Оценок пока нет
- Content-Based Adaptation of Streamed MultimediaДокумент12 страницContent-Based Adaptation of Streamed MultimediaKHAOULA WISSALE HARIKIОценок пока нет
- A User-Friendly SSVEP-based Brain-Computer Interface Using A Time-Domain ClassifierДокумент11 страницA User-Friendly SSVEP-based Brain-Computer Interface Using A Time-Domain ClassifierAndrei Damian da SilvaОценок пока нет
- Offset Trace-Based Video Quality Evaluation After Network TransportДокумент13 страницOffset Trace-Based Video Quality Evaluation After Network TransportRavneet SohiОценок пока нет
- Final - Video - Based11903-Article Text-15431-1-2-20201228Документ8 страницFinal - Video - Based11903-Article Text-15431-1-2-20201228Khushal DasОценок пока нет
- Real-Time Analysis of AthletesДокумент11 страницReal-Time Analysis of AthletesMaxwell Nunes do CarmoОценок пока нет
- Info Com 2010Документ9 страницInfo Com 2010Hoang TranОценок пока нет
- Building A Reduced Reference Video Quality Metric With Very Low Overhead Using Multivariate Data AnalysisДокумент6 страницBuilding A Reduced Reference Video Quality Metric With Very Low Overhead Using Multivariate Data AnalysisAzmi AbdulbaqiОценок пока нет
- Icann 2010Документ6 страницIcann 2010Cecil ChiuОценок пока нет
- Temporal Motion Prediction For Fast Motion Estimation in Multiple Reference FramesДокумент4 страницыTemporal Motion Prediction For Fast Motion Estimation in Multiple Reference FramesNj NjОценок пока нет
- A Fast Image Coding Algorithm Based On Lifting Wavelet TransformДокумент4 страницыA Fast Image Coding Algorithm Based On Lifting Wavelet TransformRoshan JayswalОценок пока нет
- Sensors: Objective Video Quality Assessment Based On Machine Learning For Underwater Scientific ApplicationsДокумент15 страницSensors: Objective Video Quality Assessment Based On Machine Learning For Underwater Scientific ApplicationshoainamcomitОценок пока нет
- A New Approach For Video Denoising and Enhancement Using Optical Flow EstimationДокумент4 страницыA New Approach For Video Denoising and Enhancement Using Optical Flow EstimationAnonymous kw8Yrp0R5rОценок пока нет
- Estimating Velocity of Nailfold Vessels Flow Using Improvised Deconvolution AlgorithmДокумент6 страницEstimating Velocity of Nailfold Vessels Flow Using Improvised Deconvolution AlgorithmIJERDОценок пока нет
- Auro 2017Документ16 страницAuro 2017chowkamlee81Оценок пока нет
- Contrast Sensitivity For Human Eye SystemДокумент10 страницContrast Sensitivity For Human Eye SystemNandagopal SivakumarОценок пока нет
- Trajectons: Action Recognition Through The Motion Analysis of Tracked FeaturesДокумент8 страницTrajectons: Action Recognition Through The Motion Analysis of Tracked FeaturesyunciОценок пока нет
- View Synthesis Motion Estimation For Multiview Distributed Video CodingДокумент5 страницView Synthesis Motion Estimation For Multiview Distributed Video CodingKrishna Reddy KondaОценок пока нет
- Video Quality Assessment For Concurrent Multipath TransferДокумент3 страницыVideo Quality Assessment For Concurrent Multipath TransferBONFRINGОценок пока нет
- Object TrackingДокумент23 страницыObject TrackingRahul PaulОценок пока нет
- Pedestrian Detection - Research PaperДокумент9 страницPedestrian Detection - Research PaperAnshumanОценок пока нет
- Conversion of Sign Language Video To Text andДокумент8 страницConversion of Sign Language Video To Text andIJRASETPublicationsОценок пока нет
- Accepted Manuscript: J. Vis. Commun. Image RДокумент47 страницAccepted Manuscript: J. Vis. Commun. Image RANSHY SINGHОценок пока нет
- Wavelet Related TopicДокумент12 страницWavelet Related TopicThumma NeeliОценок пока нет
- Objective Video Quality Assessment Methods: A Classification, Review, and Performance ComparisonДокумент18 страницObjective Video Quality Assessment Methods: A Classification, Review, and Performance ComparisonThu TrangОценок пока нет
- Video Based CNN LSTMДокумент6 страницVideo Based CNN LSTMJ SANDHYAОценок пока нет
- Fast Human Pose Estimation in Compressed VideosДокумент12 страницFast Human Pose Estimation in Compressed VideosNikitaОценок пока нет
- A Unified Scheme For Super-Resolution and Depth Estimation From Asymmetric Stereoscopic VideoДокумент14 страницA Unified Scheme For Super-Resolution and Depth Estimation From Asymmetric Stereoscopic VideoSanjay ShelarОценок пока нет
- Video Coding and Routing in Wireless Video Sensor NetworksДокумент6 страницVideo Coding and Routing in Wireless Video Sensor Networkseily0Оценок пока нет
- VLC Using Mobile-Phone Camera With Data Rate Higher Than Frame RateДокумент6 страницVLC Using Mobile-Phone Camera With Data Rate Higher Than Frame RateKhoa LêОценок пока нет
- Frame-Skip Convolutional Neural Networks For Action RecognitionДокумент6 страницFrame-Skip Convolutional Neural Networks For Action RecognitionMitchell Angel Gomez OrtegaОценок пока нет
- VSQuAD ICIP 2022 Paper Camera Ready - 1 CompressedДокумент5 страницVSQuAD ICIP 2022 Paper Camera Ready - 1 CompressedAissa BOUKHARIОценок пока нет
- Moving Object Detection and Tracking in VideosДокумент25 страницMoving Object Detection and Tracking in VideosTomislav LivnjakОценок пока нет
- A66 BergmanДокумент8 страницA66 Bergmanisrael_l13Оценок пока нет
- 2011 - APSIPA - Recent Developments and Future Trends in Visual Quality AssessmentДокумент10 страниц2011 - APSIPA - Recent Developments and Future Trends in Visual Quality Assessmentarg.xuxuОценок пока нет
- Mpeg4 Animation Clustering For Networked Virtual EnvironmentsДокумент4 страницыMpeg4 Animation Clustering For Networked Virtual EnvironmentsVictoria WareОценок пока нет
- Ibook - Pub Crowd Aware Summarization of Surveillance Videos by Deep Reinforcement LearningДокумент21 страницаIbook - Pub Crowd Aware Summarization of Surveillance Videos by Deep Reinforcement LearningANSHY SINGHОценок пока нет
- Video Saliency-Recognition by Applying Custom Spatio Temporal Fusion TechniqueДокумент10 страницVideo Saliency-Recognition by Applying Custom Spatio Temporal Fusion TechniqueIAES IJAIОценок пока нет
- Full-Reference Metric For Image Quality Assessment: Abstract-The Quality of Image Is Most Important Factor inДокумент5 страницFull-Reference Metric For Image Quality Assessment: Abstract-The Quality of Image Is Most Important Factor inIjarcsee JournalОценок пока нет
- (IJETA-V8I2P7) :MD - Noman Habib KhanДокумент8 страниц(IJETA-V8I2P7) :MD - Noman Habib KhanIJETA - EighthSenseGroupОценок пока нет
- Automated Video Summarization Using Speech TranscriptsДокумент12 страницAutomated Video Summarization Using Speech TranscriptsBryanОценок пока нет
- Human Fall Detection Using Optical Flow Farne BackДокумент15 страницHuman Fall Detection Using Optical Flow Farne Backkandulaanusha20Оценок пока нет
- S Q E/Q S C M M S: Urvey On O O Orrelation Odels FOR Ultimedia ErvicesДокумент20 страницS Q E/Q S C M M S: Urvey On O O Orrelation Odels FOR Ultimedia ErvicesijdpsОценок пока нет
- Tobias Hoßfeld, Michael Seufert, Christian Sieber, Thomas ZinnerДокумент6 страницTobias Hoßfeld, Michael Seufert, Christian Sieber, Thomas ZinnerHallel13Оценок пока нет
- Full Body Motion Capture: A Flexible Marker-Based SolutionДокумент8 страницFull Body Motion Capture: A Flexible Marker-Based Solutionfallenangel006Оценок пока нет
- Gap Model QOEДокумент12 страницGap Model QOEzahoorelahiОценок пока нет
- Is Attention To Bounding Boxes All You Need For Pedestrian ActionДокумент7 страницIs Attention To Bounding Boxes All You Need For Pedestrian ActionSoulayma GazzehОценок пока нет
- Coding of Video Sequences Using Three Step Search AlgorithmДокумент8 страницCoding of Video Sequences Using Three Step Search AlgorithmprobleОценок пока нет
- Engineering Journal A Fire Fly Optimization Based Video Object Co-SegmentationДокумент7 страницEngineering Journal A Fire Fly Optimization Based Video Object Co-SegmentationEngineering JournalОценок пока нет
- Dynamic Swarm Particle For Fast Motion Vehicle TrackingДокумент13 страницDynamic Swarm Particle For Fast Motion Vehicle Trackingrushendra.umbОценок пока нет
- Video Summarization and Retrieval Using Singular Value DecompositionДокумент12 страницVideo Summarization and Retrieval Using Singular Value DecompositionIAGPLSОценок пока нет
- Intelligent Image and Video Compression: Communicating PicturesОт EverandIntelligent Image and Video Compression: Communicating PicturesРейтинг: 5 из 5 звезд5/5 (1)
- Guidelines and Standards For External Evaluation Organisations 5th Edition v1.1Документ74 страницыGuidelines and Standards For External Evaluation Organisations 5th Edition v1.1Entrepre NurseОценок пока нет
- Project Initiation and Planning (Schwalbe, 2019) : Student - Feedback@sti - EduДокумент3 страницыProject Initiation and Planning (Schwalbe, 2019) : Student - Feedback@sti - EduRhea Anne N. OcceñaОценок пока нет
- 3949-Article Text-8633-1-10-20180712Документ10 страниц3949-Article Text-8633-1-10-20180712Volodymyr TarnavskyyОценок пока нет
- D4530Документ5 страницD4530rimi7al100% (1)
- Pism Pub Line Up - Jul-Dec - 2022Документ1 страницаPism Pub Line Up - Jul-Dec - 2022Yus CeballosОценок пока нет
- KIT REQUEST FORM - GradДокумент2 страницыKIT REQUEST FORM - Graddamie aadamsОценок пока нет
- Self Awareness and Self Management: NSTP 1Документ7 страницSelf Awareness and Self Management: NSTP 1Fritzgerald LanguidoОценок пока нет
- Lifestyle Mentor. Sally & SusieДокумент2 страницыLifestyle Mentor. Sally & SusieLIYAN SHENОценок пока нет
- CHEM 111 Assignment 2024Документ3 страницыCHEM 111 Assignment 2024Ben Noah EuroОценок пока нет
- Coding Prony 'S Method in MATLAB and Applying It To Biomedical Signal FilteringДокумент14 страницCoding Prony 'S Method in MATLAB and Applying It To Biomedical Signal FilteringBahar UğurdoğanОценок пока нет
- SkepticismДокумент5 страницSkepticismstevenspillkumarОценок пока нет
- English Action Plan 2023-2024Документ5 страницEnglish Action Plan 2023-2024Gina DaligdigОценок пока нет
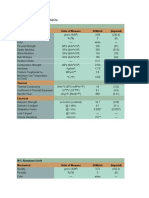
- Engineering Properties (Al O) : 94% Aluminum Oxide Mechanical Units of Measure SI/Metric (Imperial)Документ7 страницEngineering Properties (Al O) : 94% Aluminum Oxide Mechanical Units of Measure SI/Metric (Imperial)Hendy SetiawanОценок пока нет
- Leap Motion PDFДокумент18 страницLeap Motion PDFAnkiTwilightedОценок пока нет
- Catholic Social TeachingsДокумент21 страницаCatholic Social TeachingsMark de GuzmanОценок пока нет
- Absolute Containers Brochure 2019 2 27 PDFДокумент19 страницAbsolute Containers Brochure 2019 2 27 PDFEduardo SolanoОценок пока нет
- Seventh Pay Commission ArrearsДокумент11 страницSeventh Pay Commission Arrearssantosh bharathyОценок пока нет
- Vernacular in Andhra PradeshДокумент1 страницаVernacular in Andhra PradeshNandyala Rajarajeswari DeviОценок пока нет
- Imarest 2021 Warship Development 1997Документ43 страницыImarest 2021 Warship Development 1997nugrohoОценок пока нет
- CV LeTranNguyen enДокумент4 страницыCV LeTranNguyen enLe Tran NguyenОценок пока нет
- NAAC 10.12.1888888 NewДокумент48 страницNAAC 10.12.1888888 Newచిమ్ముల సందీప్ రెడ్డిОценок пока нет
- JMPGuitars 18 Watt Tremolo TMB Reverb LayoutДокумент1 страницаJMPGuitars 18 Watt Tremolo TMB Reverb LayoutRenan Franzon GoettenОценок пока нет
- Floor DiaphragmДокумент24 страницыFloor DiaphragmChristian LeobreraОценок пока нет
- Disconnect Cause CodesДокумент2 страницыDisconnect Cause Codesdungnt84Оценок пока нет
- Quotation Request Form: Customer DetailsДокумент1 страницаQuotation Request Form: Customer DetailsAmanda RezendeОценок пока нет
- Ficha Tecnica Castrol Hyspin AWS RangeДокумент2 страницыFicha Tecnica Castrol Hyspin AWS Rangeel pro jajaja GonzalezОценок пока нет
- Lesson 2 - Reflection PaperДокумент2 страницыLesson 2 - Reflection PaperkristhelynОценок пока нет