Вам также может понравиться
- High Availability and Load Balancing For Postgresql Databases: Designing and Implementing.Документ8 страницHigh Availability and Load Balancing For Postgresql Databases: Designing and Implementing.Maurice Lee100% (1)
- ACFS 12C - Automatic Storage Management Cluster File SystemДокумент8 страницACFS 12C - Automatic Storage Management Cluster File SystemduraianbuОценок пока нет
- Using Oracle Sharding PDFДокумент177 страницUsing Oracle Sharding PDFHarish NaikОценок пока нет
- An Introduction To Software Architecture - SummaryДокумент15 страницAn Introduction To Software Architecture - SummaryJohn Ortiz100% (1)
- IBM - Introduction To Spectrum ScaleДокумент30 страницIBM - Introduction To Spectrum Scalefrsantos123Оценок пока нет
- Sharding 19c New FeaturesДокумент7 страницSharding 19c New FeaturesjayОценок пока нет
- Making Sense of NoSQLДокумент1 страницаMaking Sense of NoSQLDreamtech Press0% (1)
- Coq 8.10.2 Reference Manual PDFДокумент643 страницыCoq 8.10.2 Reference Manual PDFJohn BardakosОценок пока нет
- CSCI 5828 - Spring 2010 Foundations of Software EngineeringДокумент28 страницCSCI 5828 - Spring 2010 Foundations of Software EngineeringKunjal Patel BathaniОценок пока нет
- Everything You Need to Know About Containerization with dotCMS: 101Документ23 страницыEverything You Need to Know About Containerization with dotCMS: 101Pedro GrОценок пока нет
- Introduction To Oracle ShardingДокумент13 страницIntroduction To Oracle Shardingscolomaay100% (1)
- Oracle Database Structures and ComponentsДокумент18 страницOracle Database Structures and ComponentsSwapnil Yeole100% (1)
- Datapower Overview: Brief DescriptionДокумент6 страницDatapower Overview: Brief Descriptionpardhunani143Оценок пока нет
- Performance Tuning With InfoSphere CDCДокумент37 страницPerformance Tuning With InfoSphere CDCkarthikt27100% (1)
- Database Migration From Oracle To DB2-20120314pdf PDFДокумент15 страницDatabase Migration From Oracle To DB2-20120314pdf PDFaamir_malikОценок пока нет
- NetApp Data Fabric Architecture FundamentalsДокумент35 страницNetApp Data Fabric Architecture FundamentalsDavid ChungОценок пока нет
- Unit No: 02 Architecture/Infrastructure & Data Representation of DWHДокумент166 страницUnit No: 02 Architecture/Infrastructure & Data Representation of DWHRavi SistaОценок пока нет
- 1 Data Vault TDWI SouthFL 20110311 by Raphael KlebanovДокумент30 страниц1 Data Vault TDWI SouthFL 20110311 by Raphael KlebanovJonJonОценок пока нет
- Informatica Configuration of CDC Option For Oracle Through LogMinerДокумент5 страницInformatica Configuration of CDC Option For Oracle Through LogMinerIvan PavlovОценок пока нет
- MongoDB Architecture GuideДокумент19 страницMongoDB Architecture GuideKiệtОценок пока нет
- Talend ESB Container AG 50b enДокумент63 страницыTalend ESB Container AG 50b enslimanihaythemОценок пока нет
- Python Project Data Analysis-1Документ27 страницPython Project Data Analysis-1ripunjay080808Оценок пока нет
- 2019 Strategic Roadmap For Storage: Key FindingsДокумент20 страниц2019 Strategic Roadmap For Storage: Key FindingsLeoОценок пока нет
- DataStage Migration Webinar - v3FINALДокумент28 страницDataStage Migration Webinar - v3FINALHulya SahipОценок пока нет
- Battle of The Giants - Comparing Kimball and InmonДокумент15 страницBattle of The Giants - Comparing Kimball and InmonFelipe Oliveira GutierrezОценок пока нет
- Teradata Is An Enterprise Software Company That Develops and Sells Database Analytics Software SubscriptionsДокумент4 страницыTeradata Is An Enterprise Software Company That Develops and Sells Database Analytics Software SubscriptionsEIE VNRVJIETОценок пока нет
- Oracle 12c Partitioned and Subpartitioned TablesДокумент24 страницыOracle 12c Partitioned and Subpartitioned Tableslz7r6cОценок пока нет
- IBM PowerHA CookbookДокумент486 страницIBM PowerHA CookbookLeonardo M MichelОценок пока нет
- Revolutionizing Data Warehousing in Telecom With The Vertica Analytic DatabaseДокумент11 страницRevolutionizing Data Warehousing in Telecom With The Vertica Analytic DatabasegrandelindoОценок пока нет
- DWH Informatica Session PDFДокумент32 страницыDWH Informatica Session PDFSwaroop VanteruОценок пока нет
- Director IT Infrastructure Operations in Colorado Springs CO Resume William SchmidtДокумент3 страницыDirector IT Infrastructure Operations in Colorado Springs CO Resume William SchmidtWilliamSchmidtОценок пока нет
- Oracle GoldenGate Best Practices - Configuring Oracle GoldenGate For Teradata Databases V5a ID1323119.1-1Документ43 страницыOracle GoldenGate Best Practices - Configuring Oracle GoldenGate For Teradata Databases V5a ID1323119.1-1upenderОценок пока нет
- Software Architecture and DesignДокумент95 страницSoftware Architecture and DesignLevi CorveraОценок пока нет
- 07 - FastConnect Day 3 - v1Документ19 страниц07 - FastConnect Day 3 - v1jay karandikarОценок пока нет
- ETL Processing: High Performance Data Warehouse Design and ConstructionДокумент39 страницETL Processing: High Performance Data Warehouse Design and ConstructionFilmy StudioОценок пока нет
- Loading and Transformation OverviewДокумент24 страницыLoading and Transformation OverviewexbisОценок пока нет
- How To Synchronize Standby When Logs LostДокумент25 страницHow To Synchronize Standby When Logs LostSanjay GunduОценок пока нет
- Blockchain For IBMers - DifferentiatorsДокумент18 страницBlockchain For IBMers - Differentiatorsayanmukherjee1Оценок пока нет
- Dataguard QuestionsДокумент5 страницDataguard QuestionssuhaasОценок пока нет
- IBM Cognos TM1 WhitepaperДокумент7 страницIBM Cognos TM1 Whitepaperprabu2125Оценок пока нет
- A Complete Guide To Docker For Operations and Development Test-Prep For The Docker Certified Associate (DCA) Exam (Engy Fouda) (Z-Library)Документ197 страницA Complete Guide To Docker For Operations and Development Test-Prep For The Docker Certified Associate (DCA) Exam (Engy Fouda) (Z-Library)Les Marchés TauОценок пока нет
- Oracle Fact Sheet 079219 PDFДокумент2 страницыOracle Fact Sheet 079219 PDFGiovanni Serauto100% (1)
- Mastering Dynamodb: Chapter No. 1 "Getting Started"Документ26 страницMastering Dynamodb: Chapter No. 1 "Getting Started"Packt PublishingОценок пока нет
- UNIX Knowledge DocumentДокумент43 страницыUNIX Knowledge DocumentSwapnil SaketОценок пока нет
- The Future of The Mainframe: Gary BarnettДокумент19 страницThe Future of The Mainframe: Gary BarnettSantosh ReddyОценок пока нет
- Dbms NotesДокумент84 страницыDbms NotesJugal K Sewag100% (1)
- Documentation: Community Resources Blog EnglishДокумент11 страницDocumentation: Community Resources Blog EnglishAbhishekОценок пока нет
- Baseline The Baseline On MDMДокумент24 страницыBaseline The Baseline On MDMAmgad AlsisiОценок пока нет
- Developing WebLogic Server ApplicationsДокумент125 страницDeveloping WebLogic Server Applicationsintrepid1122Оценок пока нет
- Data Subsetting and MaskingДокумент32 страницыData Subsetting and MaskinggaiauserОценок пока нет
- Data Hub Guide For ArchitectsДокумент83 страницыData Hub Guide For ArchitectsfptstopОценок пока нет
- How the World Bank Built an Enterprise TaxonomyДокумент28 страницHow the World Bank Built an Enterprise TaxonomyChiKita Tinitana100% (1)
- Migrating and Upgrading To Oracle Database 12c Quickly With Near-Zero DowntimeДокумент31 страницаMigrating and Upgrading To Oracle Database 12c Quickly With Near-Zero DowntimesellenduОценок пока нет
- XQuery and XPath ExamplesДокумент25 страницXQuery and XPath ExamplesKirti ShekharОценок пока нет
- Druid PDFДокумент12 страницDruid PDFs.zeraoui1595Оценок пока нет
- Backend Developer RoadmapДокумент3 страницыBackend Developer RoadmapRahulОценок пока нет
- Chapter 1. Networking and Storage ConceptsДокумент31 страницаChapter 1. Networking and Storage ConceptsBhaskar ChowdaryОценок пока нет
- 3.1 Lesson 1.2 Hints PDFДокумент7 страниц3.1 Lesson 1.2 Hints PDFIliass Aklilah0% (1)
- Database Sharding White Paper V1Документ17 страницDatabase Sharding White Paper V1Jason ProbertОценок пока нет
- How To Obtain Flexible, Cost-Effective Scalability and Performance Through Pushdown ProcessingДокумент16 страницHow To Obtain Flexible, Cost-Effective Scalability and Performance Through Pushdown ProcessingAlok TiwaryОценок пока нет
- 2014 Ieee Computer NosqlДокумент4 страницы2014 Ieee Computer NosqlSagar PhullОценок пока нет
- Cloud Database Database As A ServiceДокумент12 страницCloud Database Database As A ServiceMaurice LeeОценок пока нет
- 10 Value - Engg & AnalysisДокумент46 страниц10 Value - Engg & AnalysisSagar PhullОценок пока нет
- 10 Value - Engg & AnalysisДокумент46 страниц10 Value - Engg & AnalysisSagar PhullОценок пока нет
- Operations Management Plant LocationДокумент36 страницOperations Management Plant LocationSagar PhullОценок пока нет
- Operations Management: Topic: Scheduling. DR - Nitin KubdeДокумент31 страницаOperations Management: Topic: Scheduling. DR - Nitin KubdeSagar PhullОценок пока нет
- 2.prod Design AnalisiS DevLOP.Документ39 страниц2.prod Design AnalisiS DevLOP.Sagar PhullОценок пока нет
- Hershey ERP Case StudyДокумент3 страницыHershey ERP Case StudySagar PhullОценок пока нет
- 5b.aggregate PlanningДокумент27 страниц5b.aggregate PlanningSagar PhullОценок пока нет
- 3.process Seln A FinalДокумент14 страниц3.process Seln A FinalSagar PhullОценок пока нет
- 2.prod Design AnalisiS DevLOP.Документ39 страниц2.prod Design AnalisiS DevLOP.Sagar PhullОценок пока нет
- Plant Layout Decision GuideДокумент31 страницаPlant Layout Decision GuideSagar PhullОценок пока нет
- Project Management HomeworkДокумент2 страницыProject Management HomeworkSagar PhullОценок пока нет
- Operations ManagementДокумент44 страницыOperations ManagementSagar PhullОценок пока нет
- IT Fundamentals & Computing-ObjДокумент6 страницIT Fundamentals & Computing-ObjSagar PhullОценок пока нет
- Finance BrochureДокумент2 страницыFinance BrochureSagar PhullОценок пока нет
- Project Report FINALДокумент38 страницProject Report FINALSagar PhullОценок пока нет
- Project ExelДокумент18 страницProject ExelSagar PhullОценок пока нет
- Us 3625836Документ3 страницыUs 3625836Sagar PhullОценок пока нет
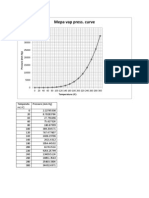
- Vapor pressure curves of MEA, Toluene, and WaterДокумент5 страницVapor pressure curves of MEA, Toluene, and WaterSagar PhullОценок пока нет
- Imanager U2000-Cme Northbound Interface Scenario Description (GSM)Документ33 страницыImanager U2000-Cme Northbound Interface Scenario Description (GSM)ramos_lisandroОценок пока нет
- Introduction To Image Processing Using MatlabДокумент85 страницIntroduction To Image Processing Using MatlabAkankhya BeheraОценок пока нет
- PowerPoint TemplateДокумент20 страницPowerPoint Templatehuynhducquoc0122100% (3)
- Load Economic Dispatch IEEE-9 Bus MATPOWERДокумент26 страницLoad Economic Dispatch IEEE-9 Bus MATPOWERMuhammet AlkaşОценок пока нет
- E17040 ZenWiFi AX XT8 UM PDFДокумент151 страницаE17040 ZenWiFi AX XT8 UM PDFEP TANОценок пока нет
- HTML Cheatsheet GuideДокумент6 страницHTML Cheatsheet Guidearronstack100% (1)
- Technical Support International: Module 8: Software UpdateДокумент10 страницTechnical Support International: Module 8: Software UpdateBrayan RamírezОценок пока нет
- Que 1:-Using The Following Database:: Colleges (Cname, City, Address, Phone, Afdate)Документ26 страницQue 1:-Using The Following Database:: Colleges (Cname, City, Address, Phone, Afdate)jassi7nishadОценок пока нет
- Class 12 CSC Practical File MysqlДокумент21 страницаClass 12 CSC Practical File MysqlS JAY ADHITYAA100% (1)
- 11.2.3.11 Packet TR Logging From Multiple Sources InstructionsДокумент4 страницы11.2.3.11 Packet TR Logging From Multiple Sources InstructionsNОценок пока нет
- Word Processing Fundamentals ExplainedДокумент12 страницWord Processing Fundamentals ExplainedQueven James EleminoОценок пока нет
- G8052 CR 8-3Документ684 страницыG8052 CR 8-3Gino AnticonaОценок пока нет
- Automotive Functional Safety WPДокумент14 страницAutomotive Functional Safety WPAvinash ChiguluriОценок пока нет
- ThesisДокумент34 страницыThesisFacts fidaОценок пока нет
- P3 Score Improvement Through Parameter OptimizationДокумент25 страницP3 Score Improvement Through Parameter Optimizationmohamed fadlОценок пока нет
- AirScale RNC Product DescriptionДокумент46 страницAirScale RNC Product Descriptionsamir YOUSIF100% (1)
- Software ProcessДокумент25 страницSoftware ProcessHarsha VardhanОценок пока нет
- Millipak 4QДокумент4 страницыMillipak 4QAb MoОценок пока нет
- MESDДокумент311 страницMESDsarath rocksОценок пока нет
- 27.tacacs Configuration in Aci - Learn Work ItДокумент8 страниц27.tacacs Configuration in Aci - Learn Work Itravi kantОценок пока нет
- MacPorts GuideДокумент77 страницMacPorts GuideNestor MorenoОценок пока нет
- Vita Template PDFДокумент2 страницыVita Template PDFMoath AlhajiriОценок пока нет
- IFP-2100/ECS RFP-2100: Installation and Operation GuideДокумент264 страницыIFP-2100/ECS RFP-2100: Installation and Operation GuideMurali DaranОценок пока нет
- Build an Automated Airsoft Gun TurretДокумент19 страницBuild an Automated Airsoft Gun TurretWeb devОценок пока нет
- DAD 3 Hour Tutorial PDFДокумент52 страницыDAD 3 Hour Tutorial PDFSiddharth Kumar KatiyarОценок пока нет
- Understanding Basic ICT ConceptsДокумент7 страницUnderstanding Basic ICT ConceptsGhayle de AsisОценок пока нет
- Microsoft Official Course: Identity With Windows Server 2016Документ21 страницаMicrosoft Official Course: Identity With Windows Server 2016Ziad AbdoОценок пока нет
- Learning Material - VLSI DesignДокумент172 страницыLearning Material - VLSI DesignVeena Divya KrishnappaОценок пока нет
- Security Best Practices in AOS v1.7 PDFДокумент70 страницSecurity Best Practices in AOS v1.7 PDFAmerica CorreaОценок пока нет
- RH124 RHEL6 en 1 20101029 SlidesДокумент45 страницRH124 RHEL6 en 1 20101029 SlidesShekhar Kumar100% (1)