Вам также может понравиться
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (894)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (344)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (119)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (399)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2219)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (265)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- Grade 7 Kitchen Layout SymbolsДокумент3 страницыGrade 7 Kitchen Layout SymbolsJoanna Mae David88% (112)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- Introduction To Mass Communication Media Literacy and Culture 10th Edition Ebook PDF VersionДокумент62 страницыIntroduction To Mass Communication Media Literacy and Culture 10th Edition Ebook PDF Versionjames.brooks131100% (49)
- Bharti AxaДокумент2 страницыBharti AxaViswanath KapavarapuОценок пока нет
- OWASP: Testing Guide v4 Checklist: Information Gathering Test NameДокумент26 страницOWASP: Testing Guide v4 Checklist: Information Gathering Test NameasasaОценок пока нет
- Operational Risk Questions AnsweredДокумент1 страницаOperational Risk Questions AnsweredViswanath KapavarapuОценок пока нет
- Mifare Card ICДокумент18 страницMifare Card ICDyt Kaito'KidОценок пока нет
- Introduction To Structure of Banking IndustryДокумент7 страницIntroduction To Structure of Banking IndustrygrunedaОценок пока нет
- Commit CoinДокумент8 страницCommit CoinViswanath KapavarapuОценок пока нет
- CCID Specification for Smart Card Interface DevicesДокумент123 страницыCCID Specification for Smart Card Interface DevicesViswanath KapavarapuОценок пока нет
- 11696166Документ51 страница11696166Viswanath KapavarapuОценок пока нет
- CryptographyДокумент503 страницыCryptographyViswanath KapavarapuОценок пока нет
- Placement Report IIMB 2016Документ20 страницPlacement Report IIMB 2016Viswanath KapavarapuОценок пока нет
- FDMcodeДокумент9 страницFDMcodeViswanath KapavarapuОценок пока нет
- RBI Officer Grade B Phase 1 Exam 03.08.2014 - Answer Key PDFДокумент2 страницыRBI Officer Grade B Phase 1 Exam 03.08.2014 - Answer Key PDFViswanath KapavarapuОценок пока нет
- Credit Risk Management and Business Loans ExplainedДокумент1 страницаCredit Risk Management and Business Loans ExplainedViswanath KapavarapuОценок пока нет
- Chapter 7: Net Present Value and Capital BudgetingДокумент6 страницChapter 7: Net Present Value and Capital BudgetingViswanath KapavarapuОценок пока нет
- Chapter 7: Net Present Value and Capital BudgetingДокумент6 страницChapter 7: Net Present Value and Capital BudgetingViswanath KapavarapuОценок пока нет
- Robust Bayesian Estimation of The Kinetics of The Polymorphic Crystallization of L-Glutamic Acid CrystalsДокумент12 страницRobust Bayesian Estimation of The Kinetics of The Polymorphic Crystallization of L-Glutamic Acid CrystalsViswanath KapavarapuОценок пока нет
- Terms GoogledДокумент2 страницыTerms GoogledViswanath KapavarapuОценок пока нет
- Indian Railways Coach Layout ChartДокумент1 страницаIndian Railways Coach Layout ChartPradebban RajaОценок пока нет
- dmcs0708 PDFДокумент327 страницdmcs0708 PDFarviandyОценок пока нет
- Age 3 LogДокумент1 страницаAge 3 LogViswanath KapavarapuОценок пока нет
- Design Control SystemДокумент32 страницыDesign Control SystemAslama IsnaeniОценок пока нет
- Cest La Guerre 2Документ7 страницCest La Guerre 2Viswanath KapavarapuОценок пока нет
- PSDДокумент69 страницPSDViswanath KapavarapuОценок пока нет
- IIT Kharagpur Process Dynamics and Control Mid-Sem ExamДокумент1 страницаIIT Kharagpur Process Dynamics and Control Mid-Sem ExamViswanath KapavarapuОценок пока нет
- IBPS Computer Knowledge Paper IV for PO ExamДокумент10 страницIBPS Computer Knowledge Paper IV for PO ExamViswanath KapavarapuОценок пока нет
- CD 8130Документ24 страницыCD 8130Roger FeraОценок пока нет
- Large Government Agency Converts and Archives Millions of Paper Documents To Electronic SystemДокумент2 страницыLarge Government Agency Converts and Archives Millions of Paper Documents To Electronic SystemViswanath KapavarapuОценок пока нет
- MMC 1Документ1 страницаMMC 1Viswanath KapavarapuОценок пока нет
- Trigonometric Ratios: Find The Value of Each Trigonometric RatioДокумент2 страницыTrigonometric Ratios: Find The Value of Each Trigonometric RatioRandom EmailОценок пока нет
- Q4 Report - OASSPEPДокумент61 страницаQ4 Report - OASSPEPkeziahОценок пока нет
- Abm-Amethyst Chapter 2Документ12 страницAbm-Amethyst Chapter 2ALLIYAH GRACE ADRIANOОценок пока нет
- CMS and CEMC present the 2007 Sun Life Financial Canadian Open Mathematics ChallengeДокумент4 страницыCMS and CEMC present the 2007 Sun Life Financial Canadian Open Mathematics ChallengeNicola EvripidouОценок пока нет
- Iii-Ii Final PDFДокумент44 страницыIii-Ii Final PDFChinsdazz KumarОценок пока нет
- Community Organizing Philosophies of Addams and AlinskyДокумент40 страницCommunity Organizing Philosophies of Addams and AlinskymaadamaОценок пока нет
- InTech-A Review of Childhood Abuse Questionnaires and Suggested Treatment ApproachesДокумент19 страницInTech-A Review of Childhood Abuse Questionnaires and Suggested Treatment ApproacheskiraburgoОценок пока нет
- Training Activity Matrix in Food ProcessingДокумент4 страницыTraining Activity Matrix in Food Processingian_herbasОценок пока нет
- Fasil Andargie Fenta: LecturerДокумент2 страницыFasil Andargie Fenta: Lecturerfasil AndargieОценок пока нет
- DepEd issues guidelines for ALS presentation portfolio assessmentДокумент27 страницDepEd issues guidelines for ALS presentation portfolio assessmentJessica MataОценок пока нет
- Weekly Report, Literature Meeting 2Документ2 страницыWeekly Report, Literature Meeting 2Suzy NadiaОценок пока нет
- Mother Tongue Lesson Week 7Документ7 страницMother Tongue Lesson Week 7ElsieJhadeWandasAmandoОценок пока нет
- Set in Our Ways: Why Change Is So HardДокумент5 страницSet in Our Ways: Why Change Is So HardMichael JohnsonОценок пока нет
- 7 HR Data Sets for People Analytics Under 40 CharactersДокумент14 страниц7 HR Data Sets for People Analytics Under 40 CharactersTaha Ahmed100% (1)
- Assignment 1, 2021-22 (1) DMU AssignmentДокумент2 страницыAssignment 1, 2021-22 (1) DMU Assignmenttest 74Оценок пока нет
- Chapter 1-5 Teacher-Attributes (Full Research)Документ26 страницChapter 1-5 Teacher-Attributes (Full Research)Honeyvel Marasigan BalmesОценок пока нет
- 02 eLMS Activity 1 (NSTP)Документ1 страница02 eLMS Activity 1 (NSTP)Yuki C. ArutaОценок пока нет
- Landscape Architect Nur Hepsanti Hasanah ResumeДокумент2 страницыLandscape Architect Nur Hepsanti Hasanah ResumeMuhammad Mizan AbhiyasaОценок пока нет
- Problem Solving Cases in Microsoft Access and Excel 13th Edition Monk Solutions ManualДокумент24 страницыProblem Solving Cases in Microsoft Access and Excel 13th Edition Monk Solutions ManualJosephWilliamssjgdxОценок пока нет
- PRACTICAL Biology 9th & 10thДокумент3 страницыPRACTICAL Biology 9th & 10thnbacademyОценок пока нет
- Motivation and EmotionДокумент4 страницыMotivation and EmotionReinaОценок пока нет
- Graphic Design - Brochure 2021Документ4 страницыGraphic Design - Brochure 2021Siddharth KhuranaОценок пока нет
- Iitm - MДокумент1 страницаIitm - Msachin pathakОценок пока нет
- Research 2: First Quarter - Week 5 and 6Документ20 страницResearch 2: First Quarter - Week 5 and 6Rutchel100% (2)
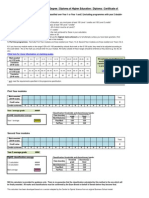
- Classification Calculator - Foundation Degree / Diploma of Higher Education / Diploma / Certificate of Higher Education / CertificateДокумент1 страницаClassification Calculator - Foundation Degree / Diploma of Higher Education / Diploma / Certificate of Higher Education / CertificateShammus SultanОценок пока нет
- RPP Struktur AtomДокумент4 страницыRPP Struktur AtomFawnia D'Genkbellzz Ezzar FluorinAnindyaОценок пока нет
- Project CloseoutДокумент9 страницProject Closeoutjansen_krystyn06100% (1)
- A Comparative Study of Volleyball Skill Between National and College Level Player Through Volleyball TestДокумент56 страницA Comparative Study of Volleyball Skill Between National and College Level Player Through Volleyball TestMullah 302Оценок пока нет