Вам также может понравиться
- 5 Ways To Delete Duplicate RecordsДокумент6 страниц5 Ways To Delete Duplicate RecordsdharmendardОценок пока нет
- Advance SQL Queries: Posted by Amar Alam at LabelsДокумент3 страницыAdvance SQL Queries: Posted by Amar Alam at Labelsprince2venkatОценок пока нет
- Delete From Emp Where Rowid ! (Select Max (Rowid) From Emp Group by Empno)Документ2 страницыDelete From Emp Where Rowid ! (Select Max (Rowid) From Emp Group by Empno)ger1974Оценок пока нет
- Good SQL qUERIESДокумент4 страницыGood SQL qUERIESSandeep DabralОценок пока нет
- EXISTS Conditions: An Condition Tests For Existence of Rows in A SubqueryДокумент5 страницEXISTS Conditions: An Condition Tests For Existence of Rows in A Subqueryyalamandu4358Оценок пока нет
- Interview Questions With Answers SQL - V1.0Документ5 страницInterview Questions With Answers SQL - V1.0Parampreet KaurОценок пока нет
- SQL Important Question AnswerДокумент47 страницSQL Important Question AnswerTaniya MajumdarОценок пока нет
- Oracle InterviewДокумент13 страницOracle Interviewsubash pradhanОценок пока нет
- Oracle NotesДокумент15 страницOracle NotesLoganathan Jayaraman JОценок пока нет
- Complex Queries in SQL (Oracle) : These Questions Are The Most Frequently Asked in InterviewsДокумент7 страницComplex Queries in SQL (Oracle) : These Questions Are The Most Frequently Asked in InterviewsAKASH LADОценок пока нет
- SQL HandbookДокумент127 страницSQL HandbooknishantОценок пока нет
- SQL Complex Query ExamplesДокумент3 страницыSQL Complex Query ExamplesSuman JyotiОценок пока нет
- SQL FundamentalsДокумент14 страницSQL FundamentalsmuralindlОценок пока нет
- Complex SQL QueriesДокумент127 страницComplex SQL Queriessahu.aashish03Оценок пока нет
- SELECT-NOTES MergedДокумент23 страницыSELECT-NOTES MergedSATYAОценок пока нет
- PLSQL SQL Interviews QuestionsДокумент89 страницPLSQL SQL Interviews QuestionsRadhaОценок пока нет
- Oracle NotesДокумент110 страницOracle Notesparvathi100% (1)
- SQL Complex Query TechniquesДокумент9 страницSQL Complex Query TechniquesAsutosh MohapatraОценок пока нет
- Sqlqueries IMP Interview Questions-2Документ39 страницSqlqueries IMP Interview Questions-2abhash royОценок пока нет
- SQL Queries 1688182703Документ127 страницSQL Queries 1688182703PadmaОценок пока нет
- SQL FaqsДокумент16 страницSQL Faqssriram kantipudiОценок пока нет
- SQL Query To Delete Duplicate RowsДокумент3 страницыSQL Query To Delete Duplicate RowsAnonymous xMYE0TiNBcОценок пока нет
- Retrieve 2nd Highest Salary in Each Department Using GROUP BYДокумент15 страницRetrieve 2nd Highest Salary in Each Department Using GROUP BYAlok KumarОценок пока нет
- Complex Queries in SQLДокумент3 страницыComplex Queries in SQLArun SamyОценок пока нет
- Complex Queries in SQLДокумент4 страницыComplex Queries in SQLvenkat manojОценок пока нет
- Complex SQLДокумент127 страницComplex SQLlokeshscribd186100% (6)
- Sub QueryДокумент12 страницSub QueryAvulaiah GОценок пока нет
- Oracle SQLДокумент110 страницOracle SQLbhanu_billa100% (1)
- Dbms Lab All TasksДокумент38 страницDbms Lab All TasksPrithvi Sriman Maddukuri MaddukuriОценок пока нет
- SQL Overview and Common QueriesДокумент8 страницSQL Overview and Common QuerieskarzthikОценок пока нет
- Oracle Interview Questions and AnswersДокумент23 страницыOracle Interview Questions and Answersjagadish_val100% (2)
- The 3rd MAX Salary in The Emp Table.: SQL Important Interview Queries by Prazval - Ks@OdigurusДокумент4 страницыThe 3rd MAX Salary in The Emp Table.: SQL Important Interview Queries by Prazval - Ks@OdigurusReza AhmadОценок пока нет
- Oracle SQL Fundamentals I Exam Sample QuestionsДокумент6 страницOracle SQL Fundamentals I Exam Sample QuestionsjoeyskiОценок пока нет
- Complex Queries in SQLДокумент15 страницComplex Queries in SQLVibhor JainОценок пока нет
- SQL MATERIALДокумент36 страницSQL MATERIALRaja KammaraОценок пока нет
- Implementation of DDL CommandsДокумент6 страницImplementation of DDL Commandslaalan jiОценок пока нет
- Delete:It's An DML Command Which Is Used For Deleting Particular Table in TheДокумент6 страницDelete:It's An DML Command Which Is Used For Deleting Particular Table in TheArya SumeetОценок пока нет
- Complex Queries in SQLДокумент14 страницComplex Queries in SQLultimatesolutionОценок пока нет
- SQLplus - The Complete GuideДокумент12 страницSQLplus - The Complete GuideAbhishek JaiswalОценок пока нет
- SQL Complex Queries (Oracle)/TITLEДокумент18 страницSQL Complex Queries (Oracle)/TITLEAvantika PadiyaОценок пока нет
- Oracle Interview Questions and Answers: SQLДокумент28 страницOracle Interview Questions and Answers: SQLThirupathi Reddy LingalaОценок пока нет
- Complex Queries in SQL (Oracle)Документ4 страницыComplex Queries in SQL (Oracle)santoshОценок пока нет
- Database Management System in Oracle 8.xДокумент44 страницыDatabase Management System in Oracle 8.xHarpreet MehtaОценок пока нет
- SQL Complex QueriesДокумент5 страницSQL Complex Queriesmr25000Оценок пока нет
- I. Page To Be Omitted: SQL QueriesДокумент14 страницI. Page To Be Omitted: SQL QueriesMohapatra SaradaОценок пока нет
- SQL Tuning#1Документ49 страницSQL Tuning#1rajadurai_aОценок пока нет
- Interview QuestionsДокумент12 страницInterview QuestionsAli NaveedОценок пока нет
- SQL QueriesДокумент194 страницыSQL Queriesaamer_shahbaaz100% (4)
- SQL PLUS File CommandsДокумент5 страницSQL PLUS File CommandsrutujasawaimoolОценок пока нет
- Syntax Rules of SQL Commands: - in One or More Lines - With Small or Capital LettersДокумент6 страницSyntax Rules of SQL Commands: - in One or More Lines - With Small or Capital LettersMatthew ReachОценок пока нет
- InterviewДокумент5 страницInterviewGali VenkiОценок пока нет
- Sub QueriesДокумент51 страницаSub QueriesSrinivas Mahanti100% (1)
- A Brief Introduction to MATLAB: Taken From the Book "MATLAB for Beginners: A Gentle Approach"От EverandA Brief Introduction to MATLAB: Taken From the Book "MATLAB for Beginners: A Gentle Approach"Рейтинг: 2.5 из 5 звезд2.5/5 (2)
- Graphs with MATLAB (Taken from "MATLAB for Beginners: A Gentle Approach")От EverandGraphs with MATLAB (Taken from "MATLAB for Beginners: A Gentle Approach")Рейтинг: 4 из 5 звезд4/5 (2)
- Matrices with MATLAB (Taken from "MATLAB for Beginners: A Gentle Approach")От EverandMatrices with MATLAB (Taken from "MATLAB for Beginners: A Gentle Approach")Рейтинг: 3 из 5 звезд3/5 (4)
- Advanced SAS Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesОт EverandAdvanced SAS Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesОценок пока нет
- Self Assessment FormДокумент4 страницыSelf Assessment FormRabindra P.SinghОценок пока нет
- Medical ReimbursementДокумент1 страницаMedical ReimbursementRabindra P.SinghОценок пока нет
- Vehicle Maintenance: Employee Name: Employee No: Date of Joining: DesignationДокумент1 страницаVehicle Maintenance: Employee Name: Employee No: Date of Joining: DesignationRabindra P.SinghОценок пока нет
- DWHДокумент5 страницDWHRabindra P.SinghОценок пока нет
- Banking Application for Customer Accounts and TransactionsДокумент3 страницыBanking Application for Customer Accounts and TransactionsRabindra P.SinghОценок пока нет
- Medical BillДокумент1 страницаMedical BillRabindra P.Singh50% (2)
- Medical ReimbursementДокумент1 страницаMedical ReimbursementRabindra P.SinghОценок пока нет
- Report 6iДокумент98 страницReport 6iShiva RamaОценок пока нет
- Read Excel (xlsx) Files and Extract Cell Data in Oracle PL/SQLДокумент9 страницRead Excel (xlsx) Files and Extract Cell Data in Oracle PL/SQLRabindra P.SinghОценок пока нет
- Oracle PLSQL CVДокумент4 страницыOracle PLSQL CVRabindra P.SinghОценок пока нет
- Datapump StepsДокумент2 страницыDatapump StepsRabindra P.SinghОценок пока нет
- PLSQL Tuning StepsДокумент8 страницPLSQL Tuning StepsRabindra P.SinghОценок пока нет
- Oracle Database Index ScanДокумент7 страницOracle Database Index ScanRabindra P.SinghОценок пока нет
- Cleartax Investment Handbook2019 20 PDFДокумент12 страницCleartax Investment Handbook2019 20 PDFYFAОценок пока нет
- The SQL INSERT INTO StatementДокумент11 страницThe SQL INSERT INTO StatementRabindra P.SinghОценок пока нет
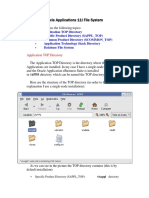
- Oracle Applications 11i File SystemДокумент7 страницOracle Applications 11i File SystemRabindra P.SinghОценок пока нет
- The SQL INSERT INTO StatementДокумент11 страницThe SQL INSERT INTO StatementRabindra P.SinghОценок пока нет
- PLSQL FAQsДокумент18 страницPLSQL FAQsRabindra P.SinghОценок пока нет
- Difference Between 11i and R12 Module WiseДокумент6 страницDifference Between 11i and R12 Module WiseRabindra P.SinghОценок пока нет
- Add GL Accounting Flexfield Range to R12 ReportДокумент2 страницыAdd GL Accounting Flexfield Range to R12 ReportRabindra P.SinghОценок пока нет
- Form Personalization in Oracle AppsДокумент14 страницForm Personalization in Oracle AppsRabindra P.SinghОценок пока нет
- Imp Interview QuestionsДокумент6 страницImp Interview QuestionsRabindra P.SinghОценок пока нет
- Oracle Implementation: Key Differences Between AIM and OUMДокумент8 страницOracle Implementation: Key Differences Between AIM and OUMRabindra P.SinghОценок пока нет
- Oracle Memory Architecture ExplainedДокумент5 страницOracle Memory Architecture ExplainedRabindra P.SinghОценок пока нет
- Period End Closing Process QueriesДокумент2 страницыPeriod End Closing Process QueriesRabindra P.SinghОценок пока нет
- SCM WRT Oracle AppsДокумент6 страницSCM WRT Oracle AppsRabindra P.SinghОценок пока нет
- HELP Menu in Oracle AppsДокумент2 страницыHELP Menu in Oracle AppsRabindra P.SinghОценок пока нет
- Several Ways To Delete Duplicate Rows in OracleДокумент3 страницыSeveral Ways To Delete Duplicate Rows in OracleRabindra P.SinghОценок пока нет
- Fundamentals of Flexfields: Key Flexfields: Most Organizations Use "Codes" Made Up of Meaningful SegmentsДокумент19 страницFundamentals of Flexfields: Key Flexfields: Most Organizations Use "Codes" Made Up of Meaningful SegmentsRabindra P.SinghОценок пока нет