Вам также может понравиться
- Abinitio Intvw QuestionsДокумент20 страницAbinitio Intvw Questionsayon hazra100% (1)
- Most Repeated Questions With AnswersДокумент8 страницMost Repeated Questions With AnswersDeepak Simhadri100% (1)
- Ab Initio Interview Questions - HTML PDFДокумент131 страницаAb Initio Interview Questions - HTML PDFdigvijay singhОценок пока нет
- Relation between EME, GDE and Co-operating systemДокумент6 страницRelation between EME, GDE and Co-operating systemkamnagarg87Оценок пока нет
- Ab Initio Interview Questions - 1Документ19 страницAb Initio Interview Questions - 1sudgay567780% (5)
- Abinitio Faq'sДокумент19 страницAbinitio Faq'sparvEenОценок пока нет
- Ab InitioFAQ2Документ14 страницAb InitioFAQ2Sravya ReddyОценок пока нет
- Abinitio InterviewДокумент70 страницAbinitio InterviewChandni Kumari100% (5)
- Abinitio-FaqsДокумент14 страницAbinitio-Faqsinderjeetkumar singh100% (1)
- Integrated Data Warehouse Repository For Business Intelligence And Decision MakingДокумент33 страницыIntegrated Data Warehouse Repository For Business Intelligence And Decision Makingudaykishorep100% (2)
- Ab Initio Interview QuestionsДокумент3 страницыAb Initio Interview QuestionsRatika Miglani MalhotraОценок пока нет
- Rollup Advanced Details Abinitio NotesДокумент2 страницыRollup Advanced Details Abinitio NotesVivek KaushikОценок пока нет
- Ab-Initio Interview QuesДокумент39 страницAb-Initio Interview Queshem77750% (2)
- 71 Ab Initio Etl Best PracticesДокумент3 страницы71 Ab Initio Etl Best Practicesraopd0% (1)
- Abinitio Scenarios QuestionДокумент33 страницыAbinitio Scenarios QuestionAashrita VermaОценок пока нет
- Ab-Initio Interview QuestionsДокумент26 страницAb-Initio Interview QuestionsMesha Malli100% (4)
- BT Project Team TCS, Kolkata: ConfidentialДокумент99 страницBT Project Team TCS, Kolkata: ConfidentialChandni KumariОценок пока нет
- Abinitio Practitioner V 1 0 Day1 PDFДокумент129 страницAbinitio Practitioner V 1 0 Day1 PDFVeerendra Boddu100% (1)
- Ab Initio Questionnaire FinalДокумент56 страницAb Initio Questionnaire FinalQtp SeleniumОценок пока нет
- Abinitio MaterialДокумент11 страницAbinitio MaterialAniket BhowmikОценок пока нет
- Ab Initio - Session3Документ90 страницAb Initio - Session3Pindiganti75% (4)
- Abinitio Ace: (A I Application Configuration Environment)Документ16 страницAbinitio Ace: (A I Application Configuration Environment)gade kotiОценок пока нет
- Abinitio Session 1Документ237 страницAbinitio Session 1Sreenivas Yadav100% (1)
- Interview AbinitioДокумент28 страницInterview AbinitioHirak100% (1)
- Cio Eu 12 Ab - Initio - Software One - System PDFДокумент64 страницыCio Eu 12 Ab - Initio - Software One - System PDFmarisha100% (1)
- Abinitio Interview QuesДокумент30 страницAbinitio Interview QuesVasu ManchikalapudiОценок пока нет
- Abinitio QuestionДокумент3 страницыAbinitio Questionabhishek palОценок пока нет
- Ab InitioДокумент183 страницыAb Initiojesus alamilla100% (3)
- AB Initio Related Components and ConceptsДокумент35 страницAB Initio Related Components and Conceptsamy_7Оценок пока нет
- Abinitio QuestionsДокумент33 страницыAbinitio Questionsadityak780% (1)
- Ab Initio EMEДокумент37 страницAb Initio EMEsuperstarraj100% (4)
- Ab InitioДокумент14 страницAb InitioManish ChoudharyОценок пока нет
- Ab Initio - Session6Документ110 страницAb Initio - Session6Pindiganti33% (3)
- Ab Initio - E0 - Case StudyДокумент8 страницAb Initio - E0 - Case StudyYashKumarОценок пока нет
- Abinitio Gde 3 0Документ60 страницAbinitio Gde 3 0Chandra Sekhar50% (2)
- Abinitio NotesДокумент26 страницAbinitio NotesSravya Reddy89% (9)
- Rollup Abinitio Run Time BehaviourДокумент2 страницыRollup Abinitio Run Time BehaviourVivek KaushikОценок пока нет
- Ab Initio ArchitectureДокумент33 страницыAb Initio Architectureaustinfru100% (2)
- Abinitio Components PDFДокумент36 страницAbinitio Components PDFanil krishna100% (2)
- Abinitio Latest QuestionsДокумент13 страницAbinitio Latest QuestionsPavan Reddy100% (1)
- Abinitio CookBookДокумент236 страницAbinitio CookBooksiva_mm100% (2)
- Introduction To EME - AB INITIOДокумент32 страницыIntroduction To EME - AB INITIONamrata Mukherjee0% (1)
- Introduction To Ab Initio: Prepared By: Ashok ChandaДокумент37 страницIntroduction To Ab Initio: Prepared By: Ashok ChandaUtkarsh Shrivatava50% (6)
- AbInitio High LevelДокумент16 страницAbInitio High LevelBibhu Prasad DasОценок пока нет
- Ab Initio QuestionsДокумент8 страницAb Initio Questionssnehajoshi_89Оценок пока нет
- 01 Ab Initio BasicsДокумент139 страниц01 Ab Initio BasicsSahil Ahamed75% (4)
- Part Two AnalysisДокумент45 страницPart Two Analysisposi babu100% (2)
- Introduction To Ab Initio: Prepared By: Ashok ChandaДокумент41 страницаIntroduction To Ab Initio: Prepared By: Ashok ChandaUtkarsh Shrivatava100% (1)
- How Ab-Initio Job Is Run What Happens When You Push The "Run" Button?Документ39 страницHow Ab-Initio Job Is Run What Happens When You Push The "Run" Button?praveen kumar100% (2)
- How To Use PDL (Parameter Definition Language) in AbinitioДокумент11 страницHow To Use PDL (Parameter Definition Language) in AbinitioAmjathck100% (4)
- Eme Admin KTДокумент8 страницEme Admin KTSUNETRO.TAX5816Оценок пока нет
- ABInitio FAQДокумент21 страницаABInitio FAQGanga VenkatОценок пока нет
- ILE concepts and AS/400 commandsДокумент54 страницыILE concepts and AS/400 commandser_tarun1Оценок пока нет
- Ab Initio Interview Question v1.0Документ7 страницAb Initio Interview Question v1.0Ravi ChythanyaОценок пока нет
- Can U Declare Multiple Heading Sections in One SQR Program?Документ5 страницCan U Declare Multiple Heading Sections in One SQR Program?Siji SurendranОценок пока нет
- Ab InitioДокумент4 страницыAb Initiokavitha221Оценок пока нет
- Structure and Table Both Are 2/2 Matrices But There Are Many Differences Between Table andДокумент35 страницStructure and Table Both Are 2/2 Matrices But There Are Many Differences Between Table andDittyAneeshОценок пока нет
- Ab Initio FAQ's Part1Документ61 страницаAb Initio FAQ's Part1Yogesh Singh83% (6)
- C Programming QnsДокумент8 страницC Programming QnsRitthy SОценок пока нет
- Android QuestionsДокумент1 страницаAndroid QuestionsVankayalapati SrikanthОценок пока нет
- GDC - WrapperДокумент53 страницыGDC - Wrapperapi-3754320Оценок пока нет
- And QstnsДокумент1 страницаAnd QstnsVankayalapati SrikanthОценок пока нет
- Android QuestionsДокумент1 страницаAndroid QuestionsVankayalapati SrikanthОценок пока нет
- Teradata - Architecture II - v1 1Документ44 страницыTeradata - Architecture II - v1 1Vankayalapati SrikanthОценок пока нет
- Data Warehouse Concepts: TCS InternalДокумент19 страницData Warehouse Concepts: TCS Internalapi-3716519Оценок пока нет
- Object Oriented Programming (OOP) : EncapsulationДокумент11 страницObject Oriented Programming (OOP) : EncapsulationVankayalapati SrikanthОценок пока нет
- Android QuestionsДокумент1 страницаAndroid QuestionsVankayalapati SrikanthОценок пока нет
- Object Oriented Programming (OOP) : EncapsulationДокумент11 страницObject Oriented Programming (OOP) : EncapsulationVankayalapati SrikanthОценок пока нет
- Ab Initio Functions GuideДокумент36 страницAb Initio Functions GuideVankayalapati SrikanthОценок пока нет
- Autosys Command List and Job Scheduling Every Half An Hour - Stack OverflowДокумент2 страницыAutosys Command List and Job Scheduling Every Half An Hour - Stack OverflowVankayalapati SrikanthОценок пока нет
- AbInitio FAQsДокумент14 страницAbInitio FAQssarvesh_mishraОценок пока нет
- Autosys Commands - Tutorials 4 All ..Документ11 страницAutosys Commands - Tutorials 4 All ..Vankayalapati SrikanthОценок пока нет
- What is Ab Initio and how does it workДокумент26 страницWhat is Ab Initio and how does it workVankayalapati SrikanthОценок пока нет
- Ab Initio ETL Tool OverviewДокумент24 страницыAb Initio ETL Tool OverviewVankayalapati SrikanthОценок пока нет
- MSWordShortcutsДокумент20 страницMSWordShortcutsVankayalapati SrikanthОценок пока нет
- CobolДокумент12 страницCobolVankayalapati SrikanthОценок пока нет
- AbInitio FAQsДокумент14 страницAbInitio FAQssarvesh_mishraОценок пока нет
- CobolДокумент12 страницCobolVankayalapati SrikanthОценок пока нет
- Application For Scholarship 2013-14Документ2 страницыApplication For Scholarship 2013-14Vankayalapati SrikanthОценок пока нет
- ITETL0001Документ23 страницыITETL0001api-37543200% (1)
- C Language TutorialДокумент19 страницC Language Tutorialapi-3781081Оценок пока нет
- ETL Testing TemplatesДокумент2 страницыETL Testing TemplatesVankayalapati SrikanthОценок пока нет
- ETL Test Plan Template With DescriptionsДокумент5 страницETL Test Plan Template With DescriptionsVankayalapati SrikanthОценок пока нет
- ETL Test Plan Template With DescriptionsДокумент5 страницETL Test Plan Template With DescriptionsVankayalapati SrikanthОценок пока нет
- ETL TestДокумент4 страницыETL Testmysharma888Оценок пока нет
- 9 I ETLДокумент20 страниц9 I ETLVankayalapati SrikanthОценок пока нет
- Orcl 6Документ6 страницOrcl 6Vankayalapati SrikanthОценок пока нет
- Learn Ab Initio ETL Tool in 32 HoursДокумент1 страницаLearn Ab Initio ETL Tool in 32 Hoursxiangxu77Оценок пока нет
- Mammo1012C enДокумент2 страницыMammo1012C enLizzy DuronОценок пока нет
- HWM Radwin Software for Data LoggersДокумент1 страницаHWM Radwin Software for Data LoggersMais OmarОценок пока нет
- Vivek - Win7Документ234 страницыVivek - Win7blunt2vitreОценок пока нет
- DNS SECURES THE ABC'SДокумент31 страницаDNS SECURES THE ABC'SMgciniNcubeОценок пока нет
- HP BIOS Configuration Utility: Technical White PaperДокумент12 страницHP BIOS Configuration Utility: Technical White Paperdaniel de los riosОценок пока нет
- BJT Small Signal Configurations Cheat SheetДокумент1 страницаBJT Small Signal Configurations Cheat SheetAdi SaggarОценок пока нет
- Micro Hi-Fi System: Service ManualДокумент63 страницыMicro Hi-Fi System: Service Manualboroda2410Оценок пока нет
- 20 Minerals Library Yard and Port ObjectsДокумент49 страниц20 Minerals Library Yard and Port ObjectsKhaled EbaidОценок пока нет
- Multiple Monitor Replacement GuideДокумент2 страницыMultiple Monitor Replacement GuideVikas KumarОценок пока нет
- Chapter 2: Configure A Network Operating System: CCNA Routing and Switching Introduction To Networks v6.0Документ47 страницChapter 2: Configure A Network Operating System: CCNA Routing and Switching Introduction To Networks v6.0de vОценок пока нет
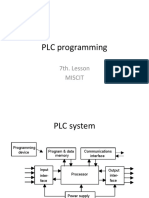
- PLC ProgrammingДокумент42 страницыPLC ProgrammingWily Ponce100% (1)
- Computrac MAX 5000XL Moisture Analyzer Seminar Hong Kong 2009Документ67 страницComputrac MAX 5000XL Moisture Analyzer Seminar Hong Kong 2009udiptya_papai2007Оценок пока нет
- Un Dipfree En64.exe 20100Документ6 страницUn Dipfree En64.exe 20100Jeremiash ForondaОценок пока нет
- COMP1829: Week 3Документ22 страницыCOMP1829: Week 3SujiKrishnanОценок пока нет
- TD Osb SincДокумент135 страницTD Osb SincGabriel Abelha Dos SantosОценок пока нет
- AC Servo Spindle System User ManualДокумент51 страницаAC Servo Spindle System User Manualamit sutarОценок пока нет
- VWorkspace 8.6.3 ReleaseNotesДокумент10 страницVWorkspace 8.6.3 ReleaseNotesRubén J. AguileraОценок пока нет
- PCS-9830B X Instruction Manual en Domestic General X R1.05Документ164 страницыPCS-9830B X Instruction Manual en Domestic General X R1.05Ricchie Gotama SihiteОценок пока нет
- Personal Digital Assistant Audit Checklist June 2009: Page 1 of 7Документ7 страницPersonal Digital Assistant Audit Checklist June 2009: Page 1 of 7T&J HR OFFICIALОценок пока нет
- Basic Computer Skills AECC-2 BA Bcom BSC BBA Combined PDFДокумент2 страницыBasic Computer Skills AECC-2 BA Bcom BSC BBA Combined PDFBalmur Saiteja100% (2)
- Allen Bradley Df1 ManualДокумент58 страницAllen Bradley Df1 ManualAlex CarmonaОценок пока нет
- Fdma, Tdma, Sdma, CdmaДокумент9 страницFdma, Tdma, Sdma, CdmaRajОценок пока нет
- Loytec: Standard IEC 62386 Edition 1.0 and of One of The Following Device Types or A CombinationДокумент4 страницыLoytec: Standard IEC 62386 Edition 1.0 and of One of The Following Device Types or A CombinationGuillermo Andres García MoraОценок пока нет
- A Multi-Hop Implementation in Wireless Sensor NetworksДокумент6 страницA Multi-Hop Implementation in Wireless Sensor Networkshj43us100% (1)
- System server process detailsДокумент261 страницаSystem server process detailsFahrudinОценок пока нет
- Common Mistakes Best Practices Coding StandardsДокумент21 страницаCommon Mistakes Best Practices Coding StandardsMadduri VenkateswarluОценок пока нет
- Stepper Motor Speed ProfileДокумент5 страницStepper Motor Speed ProfileCharoensak Charayaphan100% (1)
- VMDR Handout 2.2Документ150 страницVMDR Handout 2.2Javier Fernando Rojas FernándezОценок пока нет
- Etx-P3M: Embedded Technology ExtendedДокумент2 страницыEtx-P3M: Embedded Technology ExtendedkratmelОценок пока нет
- Prepp - In-Preparation Strategy For IAS UPSC CSE Electrical Engineering OptionalДокумент6 страницPrepp - In-Preparation Strategy For IAS UPSC CSE Electrical Engineering Optionalmojo xoxoОценок пока нет