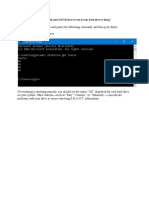
Вам также может понравиться
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- Iam UgДокумент860 страницIam UgThai PhuongОценок пока нет
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- Create The Network Security Group and An RDP RuleДокумент2 страницыCreate The Network Security Group and An RDP Rulemateigeorgescu80Оценок пока нет
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5794)
- Create A VM From A VHD by Using The Azure PortalДокумент2 страницыCreate A VM From A VHD by Using The Azure Portalmateigeorgescu80Оценок пока нет
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (399)
- Upload A Generalized VHD and Use It To Create New VMs in AzureДокумент3 страницыUpload A Generalized VHD and Use It To Create New VMs in Azuremateigeorgescu80Оценок пока нет
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- How It Works: Azure AD Multi-Factor AuthenticationДокумент4 страницыHow It Works: Azure AD Multi-Factor Authenticationmateigeorgescu80Оценок пока нет
- Manage Two-Step Verification For Your Atlassian AccountДокумент3 страницыManage Two-Step Verification For Your Atlassian Accountmateigeorgescu80Оценок пока нет
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- Create A VM From A VHD by Using The Azure PortalДокумент2 страницыCreate A VM From A VHD by Using The Azure Portalmateigeorgescu80Оценок пока нет
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- DHCP Server Migration, How It's DoneДокумент2 страницыDHCP Server Migration, How It's Donemateigeorgescu80Оценок пока нет
- Group PolicyДокумент3 страницыGroup Policymateigeorgescu80Оценок пока нет
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Remove Properties From The Computer IconДокумент1 страницаRemove Properties From The Computer Iconmateigeorgescu80Оценок пока нет
- Transfer FSMO Roles Using The GUI: Emulator, Follow The Steps BelowДокумент8 страницTransfer FSMO Roles Using The GUI: Emulator, Follow The Steps Belowmateigeorgescu80Оценок пока нет
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- Remove Properties From The Computer IconДокумент1 страницаRemove Properties From The Computer Iconmateigeorgescu80Оценок пока нет
- Fsmo PDFДокумент27 страницFsmo PDFmateigeorgescu80Оценок пока нет
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- Network PrinterДокумент3 страницыNetwork Printermateigeorgescu80Оценок пока нет
- R Sync Preserve Copy Hard LinksДокумент2 страницыR Sync Preserve Copy Hard Linksmateigeorgescu80Оценок пока нет
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (344)
- Install Windows From A USB Flash DriveДокумент2 страницыInstall Windows From A USB Flash Drivemateigeorgescu80Оценок пока нет
- PHP My AdminДокумент5 страницPHP My Adminmateigeorgescu80Оценок пока нет
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- Disk Drive Smart StatusДокумент1 страницаDisk Drive Smart Statusmateigeorgescu80Оценок пока нет
- SQL Create Index StatementДокумент2 страницыSQL Create Index Statementmateigeorgescu80Оценок пока нет
- SSL CertificateДокумент3 страницыSSL Certificatemateigeorgescu80Оценок пока нет
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- Tera Station R Sync Backup TargetДокумент3 страницыTera Station R Sync Backup Targetmateigeorgescu80Оценок пока нет
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- Rsync Link-Dest - Unsure If Its Creating Hard Links: FavoriteДокумент2 страницыRsync Link-Dest - Unsure If Its Creating Hard Links: Favoritemateigeorgescu80Оценок пока нет
- Tera Station R Sync Backup TargetДокумент3 страницыTera Station R Sync Backup Targetmateigeorgescu80Оценок пока нет
- Mozilla Public License: Author Latest Version Published CompatibleДокумент6 страницMozilla Public License: Author Latest Version Published Compatiblemateigeorgescu80Оценок пока нет
- NetTime - Network Time Synchronization ToolДокумент3 страницыNetTime - Network Time Synchronization Toolmateigeorgescu80Оценок пока нет
- Welcome To Open Upload Project Web SiteДокумент1 страницаWelcome To Open Upload Project Web Sitemateigeorgescu80Оценок пока нет
- GPING - Graphical Ping NotesДокумент1 страницаGPING - Graphical Ping Notesmateigeorgescu80Оценок пока нет
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (121)
- Disconnect A User From A SessionДокумент1 страницаDisconnect A User From A Sessionmateigeorgescu80Оценок пока нет
- G3335-90146 Qual Familiarization LCMSДокумент164 страницыG3335-90146 Qual Familiarization LCMSaxel2303Оценок пока нет
- Diskstation: Household Cloud Solution For Data Sharing and BackupДокумент7 страницDiskstation: Household Cloud Solution For Data Sharing and BackupJacquinotPungaОценок пока нет
- Task 2 Process EssayДокумент4 страницыTask 2 Process EssayChelsie AtkinsОценок пока нет
- Linux FinalДокумент46 страницLinux Finalryleb89_507192887Оценок пока нет
- Jeep Grand Cherokee Software Update Process Rs1Документ18 страницJeep Grand Cherokee Software Update Process Rs1Brayan Sanchez ZepedaОценок пока нет
- Syllabus Class 6 First TermДокумент3 страницыSyllabus Class 6 First TermMani SheikhОценок пока нет
- Galaad EngДокумент292 страницыGalaad EngovertopОценок пока нет
- "Shell - Application" "C:/foo": Dim As Variant Dim Set Dim Set Namespace For Each in NextДокумент4 страницы"Shell - Application" "C:/foo": Dim As Variant Dim Set Dim Set Namespace For Each in NextYamini ShindeОценок пока нет
- ReleaseNotesCTADE9 2Документ9 страницReleaseNotesCTADE9 2openid_JE0UyuG7Оценок пока нет
- MODFLOW 6 Release Notes: Version Mf6.1.0-December 12, 2019Документ26 страницMODFLOW 6 Release Notes: Version Mf6.1.0-December 12, 2019AkmalОценок пока нет
- EASE Focus 2 User S GuideДокумент59 страницEASE Focus 2 User S GuidepyloloОценок пока нет
- GG Flat File v3Документ37 страницGG Flat File v3Hasan BilalОценок пока нет
- WFM - Cloud.and - OnPrem Installation Smartsync GuideДокумент7 страницWFM - Cloud.and - OnPrem Installation Smartsync GuidemanishОценок пока нет
- PC LintДокумент367 страницPC LintMu-Tai Lin100% (1)
- Thanks For Purchasing: Project!Документ12 страницThanks For Purchasing: Project!sinouОценок пока нет
- Android NDKДокумент15 страницAndroid NDKRet SecОценок пока нет
- Pathloss Files Conversion Methods 0 PDFДокумент5 страницPathloss Files Conversion Methods 0 PDFKyle DiopОценок пока нет
- 0 - Glossary - VNX GlossaryДокумент108 страниц0 - Glossary - VNX GlossaryBelorgey NicolasОценок пока нет
- RPAx User Manual Rev 9.6 Update 27 - 5 - 2017Документ11 страницRPAx User Manual Rev 9.6 Update 27 - 5 - 2017Andres Libardo Botero BoteroОценок пока нет
- Serial / Ethernet Communications Guide: Azeotech DaqfactoryДокумент23 страницыSerial / Ethernet Communications Guide: Azeotech DaqfactoryOuadah MohamadОценок пока нет
- Mstower V6 User ManualДокумент272 страницыMstower V6 User Manualdinapangaribuan0% (1)
- DAT v1.00 DocumentationДокумент24 страницыDAT v1.00 DocumentationbrivetteОценок пока нет
- Tablet TP Operator Manual (B-84274EN 02)Документ110 страницTablet TP Operator Manual (B-84274EN 02)Mihail Avramov100% (3)
- RW Tools Help PDFДокумент87 страницRW Tools Help PDFMarkus Schwarz100% (1)
- Railway Reservation SystemДокумент15 страницRailway Reservation Systemchithambaramani0% (1)
- SMARTPLAY INFOTAINMENT System Software Update ManualДокумент2 страницыSMARTPLAY INFOTAINMENT System Software Update Manualabhijeet834u100% (3)
- ps2 Memory CardДокумент3 страницыps2 Memory Cardf1294563Оценок пока нет
- C5 User Manual - 20210401Документ68 страницC5 User Manual - 20210401Rudy Fernado Gonzalez EscobarОценок пока нет
- Epm AutomateДокумент130 страницEpm Automatemickey100% (1)
- Autocad Raster Design 2012 TutorialsДокумент240 страницAutocad Raster Design 2012 TutorialsTiberiu ScarlatОценок пока нет
- Azure DevOps Engineer: Exam AZ-400: Azure DevOps Engineer: Exam AZ-400 Designing and Implementing Microsoft DevOps SolutionsОт EverandAzure DevOps Engineer: Exam AZ-400: Azure DevOps Engineer: Exam AZ-400 Designing and Implementing Microsoft DevOps SolutionsОценок пока нет
- iPhone Unlocked for the Non-Tech Savvy: Color Images & Illustrated Instructions to Simplify the Smartphone Use for Beginners & Seniors [COLOR EDITION]От EverandiPhone Unlocked for the Non-Tech Savvy: Color Images & Illustrated Instructions to Simplify the Smartphone Use for Beginners & Seniors [COLOR EDITION]Рейтинг: 5 из 5 звезд5/5 (2)
- RHCSA Red Hat Enterprise Linux 9: Training and Exam Preparation Guide (EX200), Third EditionОт EverandRHCSA Red Hat Enterprise Linux 9: Training and Exam Preparation Guide (EX200), Third EditionОценок пока нет
- Kali Linux - An Ethical Hacker's Cookbook - Second Edition: Practical recipes that combine strategies, attacks, and tools for advanced penetration testing, 2nd EditionОт EverandKali Linux - An Ethical Hacker's Cookbook - Second Edition: Practical recipes that combine strategies, attacks, and tools for advanced penetration testing, 2nd EditionРейтинг: 5 из 5 звезд5/5 (1)
- iPhone 14 Guide for Seniors: Unlocking Seamless Simplicity for the Golden Generation with Step-by-Step ScreenshotsОт EverandiPhone 14 Guide for Seniors: Unlocking Seamless Simplicity for the Golden Generation with Step-by-Step ScreenshotsРейтинг: 5 из 5 звезд5/5 (2)