Вам также может понравиться
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (345)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (121)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- Final Mangonel Group ProjectДокумент7 страницFinal Mangonel Group ProjectAarohan Verma100% (2)
- Mechanical Behavior Mostly Ceramics, Glasses and PolymersДокумент26 страницMechanical Behavior Mostly Ceramics, Glasses and PolymersNorozKhanОценок пока нет
- What Are Batch Element Entry (BEE) ?: B E E (BEE)Документ20 страницWhat Are Batch Element Entry (BEE) ?: B E E (BEE)arun9698Оценок пока нет
- OpenVPX - B196910460 - BKP6 CEN10 11.2.4 4Документ11 страницOpenVPX - B196910460 - BKP6 CEN10 11.2.4 4NorozKhanОценок пока нет
- Proceedings of Spie: EM Modeling of Far-Field Radiation Patterns For Antennas On The GMA-TT UAVДокумент9 страницProceedings of Spie: EM Modeling of Far-Field Radiation Patterns For Antennas On The GMA-TT UAVNorozKhanОценок пока нет
- Calibration of Direction Finding Antennas in Complex EnvironmentДокумент4 страницыCalibration of Direction Finding Antennas in Complex EnvironmentNorozKhanОценок пока нет
- TableДокумент27 страницTableNorozKhanОценок пока нет
- MSC Research Proposal Template EndowmentДокумент6 страницMSC Research Proposal Template EndowmentNorozKhanОценок пока нет
- Top 10 Considerations For Your High-Spe..Документ7 страницTop 10 Considerations For Your High-Spe..NorozKhanОценок пока нет
- Practical FIR Filter Design - Part 1 - Design With Octave or MatlabДокумент9 страницPractical FIR Filter Design - Part 1 - Design With Octave or MatlabNorozKhanОценок пока нет
- Eval Ad76xxedzДокумент23 страницыEval Ad76xxedzNorozKhanОценок пока нет
- IviScope Configure Acquisition Type - IVI Driver Help - National InstrumentsДокумент1 страницаIviScope Configure Acquisition Type - IVI Driver Help - National InstrumentsNorozKhanОценок пока нет
- ClassPrefix Initialize With Options - IVI Driver Help - National InstrumentsДокумент2 страницыClassPrefix Initialize With Options - IVI Driver Help - National InstrumentsNorozKhanОценок пока нет
- Aerospace and Defense Mobilize Insatiable Bandwidth ApplicationsДокумент4 страницыAerospace and Defense Mobilize Insatiable Bandwidth ApplicationsNorozKhanОценок пока нет
- Extended Algorithms For Sample Rate ConversionДокумент8 страницExtended Algorithms For Sample Rate ConversionNorozKhanОценок пока нет
- Digital Channelized Receiver Based On Time Frequency Analysis For Signal InterceptionДокумент20 страницDigital Channelized Receiver Based On Time Frequency Analysis For Signal InterceptionNorozKhanОценок пока нет
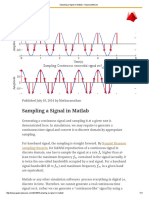
- Sampling A Signal in Matlab - GaussianWavesДокумент11 страницSampling A Signal in Matlab - GaussianWavesNorozKhanОценок пока нет
- Sampling Theorem - Bandpass or Intermediate or Under Sampling - GaussianWavesДокумент12 страницSampling Theorem - Bandpass or Intermediate or Under Sampling - GaussianWavesNorozKhanОценок пока нет
- Time Frequency Representation of Digital Signals and Systems Based On Short TimeДокумент15 страницTime Frequency Representation of Digital Signals and Systems Based On Short TimeNorozKhanОценок пока нет
- Sampling Theorem - Bandpass or Intermediate or Under Sampling - GaussianWavesДокумент12 страницSampling Theorem - Bandpass or Intermediate or Under Sampling - GaussianWavesNorozKhanОценок пока нет
- Signal Analysis - Calculate and Interpret The Instantaneous Frequency - Signal Processing Stack ExchangeДокумент6 страницSignal Analysis - Calculate and Interpret The Instantaneous Frequency - Signal Processing Stack ExchangeNorozKhanОценок пока нет
- Detector Performance Analysis Using ROC CurvesДокумент7 страницDetector Performance Analysis Using ROC CurvesNorozKhanОценок пока нет
- Wigner Ville Distribution in Signal Processing, Using Scilab EnvironmentДокумент6 страницWigner Ville Distribution in Signal Processing, Using Scilab EnvironmentNorozKhanОценок пока нет
- Constant False Alarm Rate (CFAR) DetectionДокумент8 страницConstant False Alarm Rate (CFAR) DetectionNorozKhanОценок пока нет
- Harvey Newman Receives Department of Energy, Office of High Energy Physics Lifelong Achievement AwardДокумент2 страницыHarvey Newman Receives Department of Energy, Office of High Energy Physics Lifelong Achievement AwardMaria SpiropuluОценок пока нет
- Manual de Reparacion MCR Serie 32-33Документ34 страницыManual de Reparacion MCR Serie 32-33Fernando Tapia Gibson100% (2)
- ACS450 PC Software For Burner Management System LMV5... : Operating InstructionsДокумент75 страницACS450 PC Software For Burner Management System LMV5... : Operating InstructionsShahan MehboobОценок пока нет
- Volvo Tad 660ve SpecsДокумент5 страницVolvo Tad 660ve SpecsAhmed Mostafa YoussefОценок пока нет
- 5-HK5 Miniature Solenoid ValvesДокумент6 страниц5-HK5 Miniature Solenoid ValvessakscribОценок пока нет
- NEW Colchester Typhoon Twin Spindle CNC Turning Centre Brochure 2018Документ12 страницNEW Colchester Typhoon Twin Spindle CNC Turning Centre Brochure 2018Marlon GilerОценок пока нет
- ERP ArchitectureДокумент43 страницыERP ArchitectureÄkshít ŠhàŕmäОценок пока нет
- Smart Water Vending Machine: A.DIVYA (17S11A0469) V.MAHESH (17S11A0474) A.AMITH (17S11A0468) Mr.J.I.ChakravarthyДокумент28 страницSmart Water Vending Machine: A.DIVYA (17S11A0469) V.MAHESH (17S11A0474) A.AMITH (17S11A0468) Mr.J.I.ChakravarthyDivya AdusumalliОценок пока нет
- SAP CloudДокумент512 страницSAP CloudyabbaОценок пока нет
- MGT1021 Digital and Social Media MarketingДокумент29 страницMGT1021 Digital and Social Media MarketingAminaОценок пока нет
- Multicast Routing Protocols in Wireless Sensor Networks (WSNS)Документ9 страницMulticast Routing Protocols in Wireless Sensor Networks (WSNS)Journal of Computing100% (1)
- General Notes: Fourth Floor PlanДокумент1 страницаGeneral Notes: Fourth Floor PlanJuan IstilОценок пока нет
- The Systems Life Cycle - Form 5Документ14 страницThe Systems Life Cycle - Form 5Hatz ProОценок пока нет
- Plant Maintenance StrategyДокумент8 страницPlant Maintenance Strategymirdza94Оценок пока нет
- Excel 2010 Data AnalysisДокумент6 страницExcel 2010 Data AnalysisHugo MartinsОценок пока нет
- Bocada GuideДокумент24 страницыBocada GuideKarthikeyan SundaramОценок пока нет
- 18,21. Naidian CatalogueДокумент31 страница18,21. Naidian CatalogueTaQuangDucОценок пока нет
- New CVДокумент3 страницыNew CVDhiraj ShindeОценок пока нет
- DTC P0171 System Too Lean (Bank 1) DTC P0172 System Too Rich (Bank 1)Документ14 страницDTC P0171 System Too Lean (Bank 1) DTC P0172 System Too Rich (Bank 1)Willie AustineОценок пока нет
- Endress-Hauser Cerabar S PMP71 PTДокумент7 страницEndress-Hauser Cerabar S PMP71 PTCleiton MonicoОценок пока нет
- Final DocumentДокумент51 страницаFinal DocumentDhineshОценок пока нет
- Sap Erp Financials Configuration and Design 2nd Ed 59c5c66e1723dd42ad224565Документ1 страницаSap Erp Financials Configuration and Design 2nd Ed 59c5c66e1723dd42ad224565VManiKishoreОценок пока нет
- Ahnlab Monthly Security Report Security Trend - November 2012 Special Feature: Malicious Code AnalysisДокумент32 страницыAhnlab Monthly Security Report Security Trend - November 2012 Special Feature: Malicious Code AnalysisChirri CorpОценок пока нет
- Type 2625 and 2625NS Volume BoostersДокумент4 страницыType 2625 and 2625NS Volume Boostershamz786Оценок пока нет
- 7UT85Документ9 страниц7UT85sparkCE100% (1)
- ACA UNIT-5 NotesДокумент15 страницACA UNIT-5 Notespraveennegiuk07Оценок пока нет
- House Wiring ReportДокумент9 страницHouse Wiring ReportCovid VirusОценок пока нет
- Case Study NasariaДокумент20 страницCase Study NasariaHarsh SinhaОценок пока нет