Вам также может понравиться
- SQL InterviewДокумент62 страницыSQL InterviewNgô HoàngОценок пока нет
- RDBMS Concepts: DatabaseДокумент75 страницRDBMS Concepts: Databasepervezdafedar312100% (1)
- SQL Interview Questions - JavatpointДокумент6 страницSQL Interview Questions - JavatpointR VuppulaОценок пока нет
- SQLДокумент18 страницSQLanon-339347100% (11)
- Corejava PDFДокумент250 страницCorejava PDFsai srinivasОценок пока нет
- Top 50 JDBC Interview Questions and AnswersДокумент14 страницTop 50 JDBC Interview Questions and Answersat1988Оценок пока нет
- JDBC Interview QuestionsДокумент4 страницыJDBC Interview QuestionsRk PatanaikОценок пока нет
- HTML TagsДокумент6 страницHTML Tagsvishwanathyadav649Оценок пока нет
- SQL Interview Questions and AnswersДокумент9 страницSQL Interview Questions and AnswersOana AchiteiОценок пока нет
- Oracle 10g Material FinalДокумент145 страницOracle 10g Material Finalsbabu4u100% (1)
- SQL Notes PDFДокумент15 страницSQL Notes PDFAОценок пока нет
- 13 Multi Threading PDFДокумент13 страниц13 Multi Threading PDFKhanОценок пока нет
- SQL InterviewДокумент37 страницSQL InterviewNaveen LazarusОценок пока нет
- 1.1 JShell PDFДокумент49 страниц1.1 JShell PDFsonamОценок пока нет
- MySQL NotesДокумент58 страницMySQL NotesPrecious WaseniОценок пока нет
- JDBCДокумент121 страницаJDBCLakshmi Vijayasimha Sarma KaipaОценок пока нет
- A Perfect Place For All ResourcesДокумент98 страницA Perfect Place For All ResourcesSoumava ChakrabortyОценок пока нет
- Introduction To OopДокумент27 страницIntroduction To OopFawzyОценок пока нет
- Java ImpДокумент85 страницJava Impmsurfudeen6681Оценок пока нет
- DURGA's SCJP Material on Flow ControlДокумент7 страницDURGA's SCJP Material on Flow ControlkasimОценок пока нет
- SQL Notes by TopicДокумент134 страницыSQL Notes by TopicKumarОценок пока нет
- SQL Interview QuestionsДокумент14 страницSQL Interview QuestionsRamu Yadav M100% (1)
- Learn SQL in 40 CharactersДокумент92 страницыLearn SQL in 40 Charactersravisappu100% (1)
- Top 33 JDBC Interview QuestionsДокумент8 страницTop 33 JDBC Interview QuestionsSatish BabuОценок пока нет
- Development PDFДокумент20 страницDevelopment PDFSpritual ThoughtsОценок пока нет
- SSRS 2012 MaterialДокумент58 страницSSRS 2012 MaterialSubrahmanyam SudiОценок пока нет
- DotNet SQL Interview QuestionsДокумент115 страницDotNet SQL Interview Questionsapi-3736566100% (1)
- Oracle 11g Murali Naresh TechnologyДокумент127 страницOracle 11g Murali Naresh Technologysaket123india83% (12)
- Java 8 Supplier Functional InterfaceДокумент5 страницJava 8 Supplier Functional InterfaceLakshmi Vijayasimha Sarma KaipaОценок пока нет
- SQL QueriesДокумент19 страницSQL QueriesJaya Swamy100% (3)
- Latest Chapter Wise PLSQL Inteerview Questions and Answers PDFДокумент9 страницLatest Chapter Wise PLSQL Inteerview Questions and Answers PDFiqshub100% (6)
- XML Notes by Sekhar Sir JavabynataraJДокумент99 страницXML Notes by Sekhar Sir JavabynataraJsiddarthkantedОценок пока нет
- MongoDB Query Document PDFДокумент4 страницыMongoDB Query Document PDFRahul SinghОценок пока нет
- MySQL Interview Questions and Answers For Experienced and FreshersДокумент5 страницMySQL Interview Questions and Answers For Experienced and FreshersMohmad Ashik M AОценок пока нет
- SQL Server by RN ReddyДокумент233 страницыSQL Server by RN ReddyKoushik SadhuОценок пока нет
- JVM ArchitectureДокумент21 страницаJVM Architecturemanojraj9584100% (1)
- ETL Operations GuideДокумент7 страницETL Operations GuideSudhakar UppalapatiОценок пока нет
- SQL Server NotesДокумент75 страницSQL Server NotesShashiBTITОценок пока нет
- Java Means Durgasoft: An Introduction To AntДокумент13 страницJava Means Durgasoft: An Introduction To Antasad_raza4uОценок пока нет
- PL/SQL Home Oracle MaterialДокумент182 страницыPL/SQL Home Oracle MaterialPrasadОценок пока нет
- Spring Natraj Satya BestДокумент236 страницSpring Natraj Satya BestrushikeshОценок пока нет
- Core Java Interview Questions - pdf-2 PDFДокумент15 страницCore Java Interview Questions - pdf-2 PDFVinoth VelayuthamОценок пока нет
- Adv - Java Means Durga Sir... : Durgasoft, Plot No: 202, Iind Floor, Huda Maitrivanam, Ameerpet, Hyderabad-500038Документ14 страницAdv - Java Means Durga Sir... : Durgasoft, Plot No: 202, Iind Floor, Huda Maitrivanam, Ameerpet, Hyderabad-500038KhanОценок пока нет
- SQL ModifiedДокумент136 страницSQL ModifiedRaJu SinGh100% (2)
- Design PatternsДокумент8 страницDesign PatternsShreyanshi GuptaОценок пока нет
- Final Krishna - Oracle BookДокумент351 страницаFinal Krishna - Oracle Bookp.navyasree100% (1)
- Durga CДокумент2 страницыDurga CRaJu BhaiОценок пока нет
- DurgaSoft SCJP Notes Part 2 JavabynataraJДокумент401 страницаDurgaSoft SCJP Notes Part 2 JavabynataraJJeffrey JonesОценок пока нет
- Spring Sekhar Sir PDFДокумент9 страницSpring Sekhar Sir PDFreddyОценок пока нет
- CORE JAVA Interview Questions You'll Most Likely Be AskedОт EverandCORE JAVA Interview Questions You'll Most Likely Be AskedРейтинг: 3.5 из 5 звезд3.5/5 (11)
- Java/J2EE Design Patterns Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesОт EverandJava/J2EE Design Patterns Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesОценок пока нет
- Interview Questions and Answers On Database BasicsДокумент13 страницInterview Questions and Answers On Database BasicsDebsankha GhoshОценок пока нет
- Different SQL statements and database concepts explainedДокумент10 страницDifferent SQL statements and database concepts explainedManishkantMahtoОценок пока нет
- What Do You Understand by Database, and What Does It Have?Документ26 страницWhat Do You Understand by Database, and What Does It Have?Sai KiranОценок пока нет
- Top SQL Interview QuestionsДокумент27 страницTop SQL Interview QuestionsAyalОценок пока нет
- SQL Interview QuestionsДокумент9 страницSQL Interview QuestionsRadheshyam Nayak100% (1)
- TextДокумент15 страницTextAlfiya ShaikhОценок пока нет
- AgileДокумент14 страницAgileletmeinwillya46% (13)
- AgileДокумент14 страницAgileletmeinwillya46% (13)
- Quote 62378627836278Документ1 страницаQuote 62378627836278Mayank SharmaОценок пока нет
- Advanced Scrum Master - Quiz 1Документ4 страницыAdvanced Scrum Master - Quiz 1Mayank SharmaОценок пока нет
- Scrum Master Interview QuestionsДокумент93 страницыScrum Master Interview QuestionsTanmoy Das100% (9)
- AgileДокумент14 страницAgileletmeinwillya46% (13)
- AgileДокумент14 страницAgileletmeinwillya46% (13)
- SAFe Advanced Scrum Master B&W Slides (4.6) PDFДокумент148 страницSAFe Advanced Scrum Master B&W Slides (4.6) PDFMayank Sharma100% (1)
- Configuring Microsoft Exchange Server 2007 and 2010 For Integration With Cisco Unified Presence (Over EWS)Документ12 страницConfiguring Microsoft Exchange Server 2007 and 2010 For Integration With Cisco Unified Presence (Over EWS)Mayank SharmaОценок пока нет
- ISTQB Dump PDFДокумент9 страницISTQB Dump PDFMayank SharmaОценок пока нет
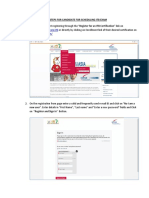
- Steps For Candidate For Scheduling Itb ExamДокумент17 страницSteps For Candidate For Scheduling Itb ExamMayank SharmaОценок пока нет
- Setup Guide For Exchange ServerДокумент36 страницSetup Guide For Exchange ServerManibalan MunusamyОценок пока нет
- ToolkitsGuide PDFДокумент50 страницToolkitsGuide PDFMayank SharmaОценок пока нет
- Index: Nit No.: 283/2018-19/Pawd-Iii/DelhiДокумент48 страницIndex: Nit No.: 283/2018-19/Pawd-Iii/DelhiMayank SharmaОценок пока нет
- Steps For Candidate For Scheduling Itb ExamДокумент17 страницSteps For Candidate For Scheduling Itb ExamMayank SharmaОценок пока нет
- Tutorial Database Testing Using SQLДокумент0 страницTutorial Database Testing Using SQLmanu2020Оценок пока нет
- Introduction to Management Information SystemsДокумент13 страницIntroduction to Management Information SystemsYus MartianОценок пока нет
- InformationДокумент6 страницInformationMayank SharmaОценок пока нет
- SQL Interview QuestionsДокумент9 страницSQL Interview QuestionsMayank SharmaОценок пока нет
- Database TestingДокумент19 страницDatabase TestingMayank SharmaОценок пока нет
- 1Документ1 страница1Mayank SharmaОценок пока нет
- Business IntelligenceДокумент4 страницыBusiness IntelligenceMayank SharmaОценок пока нет
- Artificial Neural Networks: Torsten ReilДокумент47 страницArtificial Neural Networks: Torsten ReilAtul SaxenaОценок пока нет
- Tutorial Database Testing Using SQLДокумент0 страницTutorial Database Testing Using SQLmanu2020Оценок пока нет
- Database NormalizationДокумент5 страницDatabase NormalizationMayank SharmaОценок пока нет
- Unit 1 (Adbms)Документ35 страницUnit 1 (Adbms)Mayank SharmaОценок пока нет
- E Hrmguide PDFДокумент33 страницыE Hrmguide PDFsonuОценок пока нет
- Sociology Model Paper Free Online Solved QuestionsДокумент10 страницSociology Model Paper Free Online Solved QuestionsMayank SharmaОценок пока нет
- HAT ARE THE Most Common Types OF Information System IN AN OrganizationДокумент5 страницHAT ARE THE Most Common Types OF Information System IN AN OrganizationMayank SharmaОценок пока нет
- Professional Conduct and Ethical Module 1Документ8 страницProfessional Conduct and Ethical Module 1moradasj0502Оценок пока нет
- Wireless ChargingДокумент27 страницWireless ChargingPratik KotkarОценок пока нет
- Chinese Proficiency TestДокумент32 страницыChinese Proficiency TestRichatolo W. Boulanger100% (1)
- PGH FC FB Fuer s7cp 76Документ191 страницаPGH FC FB Fuer s7cp 76Surit ApiwanОценок пока нет
- History (Hazrat Ibrahim)Документ4 страницыHistory (Hazrat Ibrahim)shullyumerbalochОценок пока нет
- Pub - Principles of Concurrent and Distributed Programmi PDFДокумент746 страницPub - Principles of Concurrent and Distributed Programmi PDFCОценок пока нет
- Apache Hive EssentialsДокумент27 страницApache Hive Essentialscloudtraining2023Оценок пока нет
- Chords - Jesus (Draylin Young) (D)Документ2 страницыChords - Jesus (Draylin Young) (D)Zarita Carranza100% (2)
- AIR Basic Calculus Q3 W2 Module 2Документ12 страницAIR Basic Calculus Q3 W2 Module 2Jasmin AquinoОценок пока нет
- Remanent (Residual) Flux in A Transformer Energization StudyДокумент5 страницRemanent (Residual) Flux in A Transformer Energization Studyvignesh kОценок пока нет
- Victor Turner's Processual Symbolic Analysis of Ritual, Anti-Structure and ReligionДокумент26 страницVictor Turner's Processual Symbolic Analysis of Ritual, Anti-Structure and Religiononyame3838Оценок пока нет
- Galatians Chapter Six by Oliver B. GreeneДокумент9 страницGalatians Chapter Six by Oliver B. GreeneLawrence GarnerОценок пока нет
- CA2 TEL203 2023 Sept QuestionДокумент22 страницыCA2 TEL203 2023 Sept QuestionRuvenderan SuburamaniamОценок пока нет
- Data SheetДокумент26 страницData SheetAnonymous CNSSoLI2wiОценок пока нет
- Alpha Chap 01Документ1 страницаAlpha Chap 01pkjohnstonОценок пока нет
- 5 2reynoldsДокумент35 страниц5 2reynoldsBryan O.Оценок пока нет
- Narrative Text. CinderellaДокумент4 страницыNarrative Text. CinderellaDevini Dwi RahayuОценок пока нет
- Examples of Informal EssaysДокумент7 страницExamples of Informal Essaysafhbdbsyx100% (2)
- Aeneid: Aeneas Flees Burning TroyДокумент14 страницAeneid: Aeneas Flees Burning TroyAndre Maurice ReyОценок пока нет
- Anime Girl - Google SearchДокумент1 страницаAnime Girl - Google SearchCassie Sky50% (2)
- AllahumaДокумент8 страницAllahumaAbul MalОценок пока нет
- An Efficient Design of 16 Bit MAC Unit Using Vedic MathematicsДокумент4 страницыAn Efficient Design of 16 Bit MAC Unit Using Vedic MathematicsRami ReddyОценок пока нет
- Timothy Titus TobitДокумент25 страницTimothy Titus TobitEnokmanОценок пока нет
- Test Paper - Class 6Документ7 страницTest Paper - Class 6Anina Mariana MihaiОценок пока нет
- CV and Resume ReportДокумент10 страницCV and Resume ReportnayabОценок пока нет
- Ignacio - Hualde, - Jon - Ortiz - de - Urbina - A - Grammar of Basque PDFДокумент977 страницIgnacio - Hualde, - Jon - Ortiz - de - Urbina - A - Grammar of Basque PDFFrancisco Jose Machado Leiva100% (2)
- Reading Rhetorical Theory: Speech, Representation, and PowerДокумент338 страницReading Rhetorical Theory: Speech, Representation, and PowerJosephine GutsaОценок пока нет
- Megillah 21Документ79 страницMegillah 21Julian Ungar-SargonОценок пока нет
- Artikel IlmiahДокумент10 страницArtikel IlmiahikaОценок пока нет
- 13. Grade 8 - Review 1 (Lesson 1) - Cơ bảnДокумент11 страниц13. Grade 8 - Review 1 (Lesson 1) - Cơ bảntramydinhthi11108Оценок пока нет