
Вам также может понравиться
- Bigtable: A Distributed Storage System For Structured DataДокумент4 страницыBigtable: A Distributed Storage System For Structured DataEric John DailisanОценок пока нет
- Google BigtableДокумент3 страницыGoogle BigtableAmyОценок пока нет
- CAT 125 SP 15 SyllabusДокумент6 страницCAT 125 SP 15 SyllabusAlice DuongОценок пока нет
- Azure Cloud IntroДокумент34 страницыAzure Cloud IntroShivaraj KОценок пока нет
- Pywaw 80 Manageable Data Pipelines With Airflow and KubernetesДокумент57 страницPywaw 80 Manageable Data Pipelines With Airflow and Kubernetesbobquest33Оценок пока нет
- New Informatica Concepts - DayДокумент98 страницNew Informatica Concepts - DayChanukya Reddy MekalaОценок пока нет
- Twitter Sentiment AnalysisДокумент27 страницTwitter Sentiment AnalysisvenkatОценок пока нет
- Mongodb SparkДокумент13 страницMongodb SparkAtif Fayaz AliОценок пока нет
- Informatic 8-Training-BISP PDFДокумент271 страницаInformatic 8-Training-BISP PDFahmed_sftОценок пока нет
- 5 - Programming With RDDs and DataframesДокумент32 страницы5 - Programming With RDDs and Dataframesravikumar lankaОценок пока нет
- How Google Big Query Changed The GameДокумент11 страницHow Google Big Query Changed The GamePriya SharmaОценок пока нет
- Python Interview QuestionsДокумент2 страницыPython Interview Questionsriyaz husainОценок пока нет
- GCP-presented Diagram - DrawioДокумент60 страницGCP-presented Diagram - DrawioDinesh SehgalОценок пока нет
- Hive CommandsДокумент3 страницыHive CommandspkumarssОценок пока нет
- Spark ETL and ProcessДокумент15 страницSpark ETL and ProcessAnkita KukrejaОценок пока нет
- Hadoop Security S360 2015v8 PDFДокумент27 страницHadoop Security S360 2015v8 PDFLuis Demetrio Martinez RuizОценок пока нет
- Troubleshooting Spark ChallengesДокумент7 страницTroubleshooting Spark ChallengeshaaОценок пока нет
- Case Study Based On: Cloud Deployment and Service Delivery ModelsДокумент10 страницCase Study Based On: Cloud Deployment and Service Delivery ModelsNikunj JenaОценок пока нет
- Apache Spark ArchitectureДокумент4 страницыApache Spark ArchitecturenitinluckyОценок пока нет
- File Formats in Big DataДокумент13 страницFile Formats in Big DataMeghna SharmaОценок пока нет
- Top Answers To Couchbase Interview QuestionsДокумент3 страницыTop Answers To Couchbase Interview QuestionsPappu KhanОценок пока нет
- Bigdata With PythonДокумент19 страницBigdata With PythonAmrit ChhetribОценок пока нет
- 11 Beginner Tips For Learning Python Programming - Real PythonДокумент8 страниц11 Beginner Tips For Learning Python Programming - Real PythonPeter SalvadorОценок пока нет
- HDFS Encryption Zone Hive OrigДокумент47 страницHDFS Encryption Zone Hive OrigshyamsunderraiОценок пока нет
- DBMS Vs RDBMS PDFДокумент7 страницDBMS Vs RDBMS PDFvikasОценок пока нет
- Pyspark FuncamentalsДокумент10 страницPyspark FuncamentalsmamathaОценок пока нет
- Lesson 1 - Hadoop and Big Data OverviewДокумент57 страницLesson 1 - Hadoop and Big Data OverviewconyeeОценок пока нет
- Lab - GAEДокумент133 страницыLab - GAEVõ Tuấn AnhОценок пока нет
- PTC Big Data Analysis With ApacheS 27.11-28.11.2019 HandoutДокумент48 страницPTC Big Data Analysis With ApacheS 27.11-28.11.2019 Handoutgkuma020.in.ibm.comОценок пока нет
- Spark: Prepared by Dulari BhattДокумент19 страницSpark: Prepared by Dulari BhattDulari Bosamiya BhattОценок пока нет
- Pentaho Training Course CatalogДокумент13 страницPentaho Training Course CatalogAbdel AdimeОценок пока нет
- Software Testing and Quality Assurance: Testing State Transition DiagramsДокумент30 страницSoftware Testing and Quality Assurance: Testing State Transition DiagramsIuliana AndronacheОценок пока нет
- Informatica Powermart / Powercenter 8.6Документ239 страницInformatica Powermart / Powercenter 8.6DeepakОценок пока нет
- Big Data With Hadoop & Spark - IntroductionДокумент42 страницыBig Data With Hadoop & Spark - IntroductionCit AssocDean RosarioОценок пока нет
- INCEPTEZ TECHNOLOGIES Installation Guide: 1. Install SparkДокумент2 страницыINCEPTEZ TECHNOLOGIES Installation Guide: 1. Install SparkGiridharselvaОценок пока нет
- Mobile: 9000403491: Venkatasuresh VeginatiДокумент2 страницыMobile: 9000403491: Venkatasuresh VeginatiVenkata SureshОценок пока нет
- Unit I Introduction 1.1 What Motivated Data Mining? Why Is It Important?Документ18 страницUnit I Introduction 1.1 What Motivated Data Mining? Why Is It Important?ANITHA AMMUОценок пока нет
- CB Queryoptimization 01Документ78 страницCB Queryoptimization 01Jean-Marc BoivinОценок пока нет
- Facebook Hive POCДокумент18 страницFacebook Hive POCJayashree RaviОценок пока нет
- M3 - Cloud Dataflow Streaming FeaturesДокумент28 страницM3 - Cloud Dataflow Streaming FeaturesEdgar SanchezОценок пока нет
- SqoopTutorial Ver 2.0Документ51 страницаSqoopTutorial Ver 2.0bujjijulyОценок пока нет
- Capacity Planning For MongoDBДокумент36 страницCapacity Planning For MongoDBAlvin John RichardsОценок пока нет
- R TutorialДокумент119 страницR TutorialPrithwish GhoshОценок пока нет
- Spark Interview QuestionsДокумент3 страницыSpark Interview QuestionsGuruprasad VijayakumarОценок пока нет
- 2 Hadoop (Uploaded)Документ82 страницы2 Hadoop (Uploaded)Prateek PoleОценок пока нет
- Building Data Pipelines - 4Документ38 страницBuilding Data Pipelines - 4Gusti Adli AnshariОценок пока нет
- Hadoop Interviews QДокумент9 страницHadoop Interviews QS KОценок пока нет
- Operating SystemДокумент60 страницOperating SystemAnoppОценок пока нет
- Data Engineering Nanodegree Program SyllabusДокумент16 страницData Engineering Nanodegree Program SyllabusJonatas EleoterioОценок пока нет
- Sqoop Commands - LatestДокумент4 страницыSqoop Commands - LatestH S Manju NathОценок пока нет
- 1) Hadoop BasicsДокумент86 страниц1) Hadoop BasicsangelineОценок пока нет
- GCP Fund Module 8 Big Data and Machine Learning in The Cloud CourseraДокумент38 страницGCP Fund Module 8 Big Data and Machine Learning in The Cloud CourseraAvinash R GowdaОценок пока нет
- Apache Spark Ecosystem - Complete Spark Components Guide: 1. ObjectiveДокумент11 страницApache Spark Ecosystem - Complete Spark Components Guide: 1. Objectivedivya kolluriОценок пока нет
- Whitepaper BigData PDFДокумент21 страницаWhitepaper BigData PDFAnonymous ul5cehОценок пока нет
- To Build and Optimize ETL PipelineДокумент10 страницTo Build and Optimize ETL PipelineIJRASETPublicationsОценок пока нет
- 02 - Lecture Note - TensorFlow OpsДокумент21 страница02 - Lecture Note - TensorFlow OpsRoberto PereiraОценок пока нет
- Flume Case StudyДокумент2 страницыFlume Case StudyKoti EshwarОценок пока нет
- ReferencesДокумент1 страницаReferencesKamal ManchandaОценок пока нет
- Data Science & Analytics - KMДокумент8 страницData Science & Analytics - KMKamal ManchandaОценок пока нет
- IELTS Handbook 2007Документ22 страницыIELTS Handbook 2007srikwaits4u100% (15)
- Introduction To Information Systems SSC, Semester 6Документ35 страницIntroduction To Information Systems SSC, Semester 6tbenguaОценок пока нет
- Bar CodeДокумент20 страницBar CodeKamal ManchandaОценок пока нет
- Asp M2Документ18 страницAsp M2Kamal ManchandaОценок пока нет
- Oracle QueryДокумент1 страницаOracle QueryKamal ManchandaОценок пока нет
- You May Continue Ur Work Now...Документ1 страницаYou May Continue Ur Work Now...Kamal ManchandaОценок пока нет
- Informatica Interview QuestionДокумент12 страницInformatica Interview QuestionMukesh Kumar100% (4)
- Proc 010210Документ2 страницыProc 010210Kamal ManchandaОценок пока нет
- Design and Implementation of An Online Farm Management Information SystemДокумент45 страницDesign and Implementation of An Online Farm Management Information Systemoraemu chinonso100% (1)
- AccuWebHosting - Invoice #286138Документ6 страницAccuWebHosting - Invoice #286138Anonymous 6fRhXGОценок пока нет
- DSPace vs. GreenStoneДокумент26 страницDSPace vs. GreenStoneatukrani100% (1)
- Configure Instance Parameters and Modify Container Databases (CDB) and Pluggable Databases (PDB)Документ2 страницыConfigure Instance Parameters and Modify Container Databases (CDB) and Pluggable Databases (PDB)Ahmed NagyОценок пока нет
- Rac11g Exam Study Guide 330762Документ7 страницRac11g Exam Study Guide 330762ttawk465Оценок пока нет
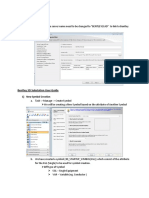
- SQL Installation: 1) New Symbol CreationДокумент23 страницыSQL Installation: 1) New Symbol CreationKullu23Оценок пока нет
- OMNITREND Center Manual 012020 enДокумент314 страницOMNITREND Center Manual 012020 enJuanCarlosDavaus50% (2)
- RakeshKumarGupta (14 0)Документ11 страницRakeshKumarGupta (14 0)sunilchopseyОценок пока нет
- Course Outline Grade 6-7-8-2012-2013Документ6 страницCourse Outline Grade 6-7-8-2012-2013api-125898803Оценок пока нет
- Unified Patents v. Grecia, IPR2016-00602Документ58 страницUnified Patents v. Grecia, IPR2016-00602Shawn AmbwaniОценок пока нет
- Connect JSP With MysqlДокумент2 страницыConnect JSP With MysqlIresh AllagiОценок пока нет
- ORA-01500 To ORA-02098Документ46 страницORA-01500 To ORA-02098Aijaz Sabir HussainОценок пока нет
- Database Design 1-3: History of The Database Practice ActivitiesДокумент3 страницыDatabase Design 1-3: History of The Database Practice ActivitiesEdward SolangОценок пока нет
- Romi Tfu 06 Casestudy Nov2015Документ109 страницRomi Tfu 06 Casestudy Nov2015HASANULОценок пока нет
- Gillani Content ManagementДокумент59 страницGillani Content Managementrizwan6666Оценок пока нет
- Research Paper in Filipino Tungkol Sa WikaДокумент5 страницResearch Paper in Filipino Tungkol Sa Wikazrdhvcaod100% (1)
- LIBRARY MANAGEMENT SYSTEM Final DocuДокумент21 страницаLIBRARY MANAGEMENT SYSTEM Final DocuJohnVincent Villarin YumangОценок пока нет
- Chapter Two Database System Concepts and ArchitectureДокумент9 страницChapter Two Database System Concepts and ArchitecturertyiookОценок пока нет
- Types of Data BaseДокумент10 страницTypes of Data BaseFaisal Awan100% (1)
- Access Lesson 1 Access Basics: Microsoft Office 2007: IntroductoryДокумент21 страницаAccess Lesson 1 Access Basics: Microsoft Office 2007: IntroductoryCodeModeОценок пока нет
- CS Practical File 2022-23-XiiДокумент54 страницыCS Practical File 2022-23-XiiPriyanshu jhaОценок пока нет
- Ife Efe Ie MatrixДокумент13 страницIfe Efe Ie MatrixAmy LlunarОценок пока нет
- Imagicle Proactive SupportДокумент9 страницImagicle Proactive Supportchindi.comОценок пока нет
- Modern Court Case Management SystemДокумент6 страницModern Court Case Management SystempembazakОценок пока нет
- AppBuild PDFДокумент312 страницAppBuild PDFVarun TejОценок пока нет
- Lecture 2-SOA Case StudiesДокумент23 страницыLecture 2-SOA Case Studiesزينب علىОценок пока нет
- CHAPTER 1 SolManДокумент17 страницCHAPTER 1 SolManAnjelica MarcoОценок пока нет
- CommerceSDK OverviewДокумент33 страницыCommerceSDK OverviewArthurHwangОценок пока нет
- Rename Relocate Data Files and Resizing Log Files in DR Env PDFДокумент15 страницRename Relocate Data Files and Resizing Log Files in DR Env PDFG.R.THIYAGU ; Oracle DBA50% (4)
- Blockchain Basics: A Non-Technical Introduction in 25 StepsОт EverandBlockchain Basics: A Non-Technical Introduction in 25 StepsРейтинг: 4.5 из 5 звезд4.5/5 (24)
- Optimizing DAX: Improving DAX performance in Microsoft Power BI and Analysis ServicesОт EverandOptimizing DAX: Improving DAX performance in Microsoft Power BI and Analysis ServicesОценок пока нет
- Grokking Algorithms: An illustrated guide for programmers and other curious peopleОт EverandGrokking Algorithms: An illustrated guide for programmers and other curious peopleРейтинг: 4 из 5 звезд4/5 (16)
- Fusion Strategy: How Real-Time Data and AI Will Power the Industrial FutureОт EverandFusion Strategy: How Real-Time Data and AI Will Power the Industrial FutureОценок пока нет
- THE STEP BY STEP GUIDE FOR SUCCESSFUL IMPLEMENTATION OF DATA LAKE-LAKEHOUSE-DATA WAREHOUSE: "THE STEP BY STEP GUIDE FOR SUCCESSFUL IMPLEMENTATION OF DATA LAKE-LAKEHOUSE-DATA WAREHOUSE"От EverandTHE STEP BY STEP GUIDE FOR SUCCESSFUL IMPLEMENTATION OF DATA LAKE-LAKEHOUSE-DATA WAREHOUSE: "THE STEP BY STEP GUIDE FOR SUCCESSFUL IMPLEMENTATION OF DATA LAKE-LAKEHOUSE-DATA WAREHOUSE"Рейтинг: 3 из 5 звезд3/5 (1)
- Joe Celko's SQL for Smarties: Advanced SQL ProgrammingОт EverandJoe Celko's SQL for Smarties: Advanced SQL ProgrammingРейтинг: 3 из 5 звезд3/5 (1)
- Business Intelligence Strategy and Big Data Analytics: A General Management PerspectiveОт EverandBusiness Intelligence Strategy and Big Data Analytics: A General Management PerspectiveРейтинг: 5 из 5 звезд5/5 (5)
- Microsoft Access Guide to Success: From Fundamentals to Mastery in Crafting Databases, Optimizing Tasks, & Making Unparalleled Impressions [III EDITION]От EverandMicrosoft Access Guide to Success: From Fundamentals to Mastery in Crafting Databases, Optimizing Tasks, & Making Unparalleled Impressions [III EDITION]Рейтинг: 5 из 5 звезд5/5 (8)
- SQL QuickStart Guide: The Simplified Beginner's Guide to Managing, Analyzing, and Manipulating Data With SQLОт EverandSQL QuickStart Guide: The Simplified Beginner's Guide to Managing, Analyzing, and Manipulating Data With SQLРейтинг: 4.5 из 5 звезд4.5/5 (46)
- DB2 9 System Administration for z/OS: Certification Study Guide: Exam 737От EverandDB2 9 System Administration for z/OS: Certification Study Guide: Exam 737Рейтинг: 3 из 5 звезд3/5 (2)
- Modelling Business Information: Entity relationship and class modelling for Business AnalystsОт EverandModelling Business Information: Entity relationship and class modelling for Business AnalystsОценок пока нет
- Data Architecture: A Primer for the Data Scientist: A Primer for the Data ScientistОт EverandData Architecture: A Primer for the Data Scientist: A Primer for the Data ScientistРейтинг: 4.5 из 5 звезд4.5/5 (3)
















































































































![Microsoft Access Guide to Success: From Fundamentals to Mastery in Crafting Databases, Optimizing Tasks, & Making Unparalleled Impressions [III EDITION]](https://imgv2-1-f.scribdassets.com/img/word_document/610686937/149x198/9ccfa6158e/1714467780?v=1)









