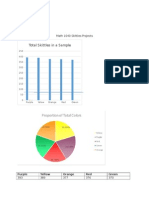
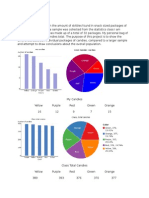
Вам также может понравиться
- The Rainbow ReportДокумент11 страницThe Rainbow Reportapi-316991888Оценок пока нет
- Math 1040 Term ProjectДокумент7 страницMath 1040 Term Projectapi-340188424Оценок пока нет
- Skittles ProjectДокумент6 страницSkittles Projectapi-319345408Оценок пока нет
- TP 2 StatsДокумент5 страницTP 2 Statsapi-240850453Оценок пока нет
- Final Math ProjectДокумент7 страницFinal Math Projectapi-316775963Оценок пока нет
- Math 1040 Statistics Term Project: Blake FreemanДокумент10 страницMath 1040 Statistics Term Project: Blake Freemanapi-252919218Оценок пока нет
- Stats ProjectДокумент14 страницStats Projectapi-302666758Оценок пока нет
- Math 1040 Skittles Term ProjectДокумент9 страницMath 1040 Skittles Term Projectapi-319881085Оценок пока нет
- Term Project - EportfolioДокумент7 страницTerm Project - Eportfolioapi-251981709Оценок пока нет
- Croot Part6 EportfolioДокумент16 страницCroot Part6 Eportfolioapi-276896975Оценок пока нет
- Skittles Project With ReflectionДокумент7 страницSkittles Project With Reflectionapi-234712126100% (1)
- Skittle Pareto ChartДокумент7 страницSkittle Pareto Chartapi-272391081Оценок пока нет
- Term Project Part 7Документ8 страницTerm Project Part 7api-291870758Оценок пока нет
- Skittles AssignmentДокумент8 страницSkittles Assignmentapi-291800396Оценок пока нет
- The Science of Collecting, Organizing, Summarizing, and Analyzing Information To Draw Conclusions or Answer QuestionsДокумент7 страницThe Science of Collecting, Organizing, Summarizing, and Analyzing Information To Draw Conclusions or Answer Questionsapi-438148756Оценок пока нет
- The Skittles Project FinalДокумент8 страницThe Skittles Project Finalapi-316760667Оценок пока нет
- Skittles Final ProjectДокумент5 страницSkittles Final Projectapi-251571777Оценок пока нет
- Final ProjectДокумент6 страницFinal Projectapi-283261340Оценок пока нет
- Skittles ProДокумент9 страницSkittles Proapi-241124972Оценок пока нет
- Skittles ProjectДокумент9 страницSkittles Projectapi-242873849Оценок пока нет
- Math Skittles Term Project-1Документ6 страницMath Skittles Term Project-1api-241771020Оценок пока нет
- EportfolioДокумент12 страницEportfolioapi-251934892Оценок пока нет
- Skittle Term ProjectДокумент15 страницSkittle Term Projectapi-260271892Оценок пока нет
- Final SkittlesДокумент6 страницFinal Skittlesapi-272838320Оценок пока нет
- Skittles Term Project StatsДокумент8 страницSkittles Term Project Statsapi-302549779Оценок пока нет
- SkittlesdataclassprojectДокумент8 страницSkittlesdataclassprojectapi-399586872Оценок пока нет
- Term Project: Part 2 - IndividualДокумент13 страницTerm Project: Part 2 - Individualapi-289345421Оценок пока нет
- Skittles Term Project 11 9 14Документ5 страницSkittles Term Project 11 9 14api-192489685Оценок пока нет
- Skittles Project 5-02Документ8 страницSkittles Project 5-02api-354040698Оценок пока нет
- Skittles Project 1Документ7 страницSkittles Project 1api-299868669100% (2)
- Final ProjectДокумент9 страницFinal Projectapi-262329757Оценок пока нет
- Math 1040 Skittles Term Project AynoaДокумент15 страницMath 1040 Skittles Term Project Aynoaapi-301347675Оценок пока нет
- Math 1030 Skittles Term ProjectДокумент8 страницMath 1030 Skittles Term Projectapi-340538273Оценок пока нет
- Skittles WordДокумент5 страницSkittles Wordapi-285645725Оценок пока нет
- The Full Skittles ProjectДокумент6 страницThe Full Skittles Projectapi-340271527100% (1)
- Term Project ReportДокумент9 страницTerm Project Reportapi-238585685Оценок пока нет
- Math Project Part B With ConclusionДокумент5 страницMath Project Part B With Conclusionapi-273321131Оценок пока нет
- Math 1040 Skittles Term Project EportfolioДокумент7 страницMath 1040 Skittles Term Project Eportfolioapi-260817278Оценок пока нет
- Skittles Term Project - Kai Galbiso Stat1040Документ6 страницSkittles Term Project - Kai Galbiso Stat1040api-316758771Оценок пока нет
- Math 1040 Final ProjectДокумент3 страницыMath 1040 Final Projectapi-285380759Оценок пока нет
- Final Stats ProjectДокумент8 страницFinal Stats Projectapi-238717717100% (2)
- Skittles Term Project Math 1040Документ6 страницSkittles Term Project Math 1040api-316781222Оценок пока нет
- Skittles FinalДокумент12 страницSkittles Finalapi-241861434Оценок пока нет
- Skittles ProjectДокумент6 страницSkittles Projectapi-366671561Оценок пока нет
- Skittles Project Math 1030Документ9 страницSkittles Project Math 1030api-305867098Оценок пока нет
- Statistics Term Project E-Portfolio ReflectionДокумент8 страницStatistics Term Project E-Portfolio Reflectionapi-258147701Оценок пока нет
- Skittles 2 FinalДокумент12 страницSkittles 2 Finalapi-242194552Оценок пока нет
- Skittles ProjectДокумент5 страницSkittles Projectapi-271444168Оценок пока нет
- Skittles Statistics ProjectДокумент9 страницSkittles Statistics Projectapi-325825295Оценок пока нет
- EportfolioДокумент8 страницEportfolioapi-242211470Оценок пока нет
- Group Project #1 - SkittlesДокумент9 страницGroup Project #1 - Skittlesapi-245266056Оценок пока нет
- Skittles Project FinalДокумент5 страницSkittles Project Finalapi-271348941Оценок пока нет
- Stats StuffДокумент7 страницStats Stuffapi-242298926Оценок пока нет
- Skittles Project Stats 1040Документ8 страницSkittles Project Stats 1040api-301336765Оценок пока нет
- Full Skittles ProjectДокумент13 страницFull Skittles Projectapi-537189505Оценок пока нет
- Skittles Project Part 1Документ6 страницSkittles Project Part 1api-457501806Оценок пока нет
- Box and Whisker LessonДокумент4 страницыBox and Whisker Lessonapi-283856329Оценок пока нет
- 1040 Term ProjectДокумент8 страниц1040 Term Projectapi-316127151Оценок пока нет
- HumanlifespanДокумент2 страницыHumanlifespanapi-325102852Оценок пока нет
- Pipeline Solution Calc2Документ2 страницыPipeline Solution Calc2api-325102852Оценок пока нет
- Project 3 4Документ9 страницProject 3 4api-325102852Оценок пока нет
- Math 1060 ProjectДокумент4 страницыMath 1060 Projectapi-325102852Оценок пока нет
- Contemporary HRMFlyerДокумент3 страницыContemporary HRMFlyerdsdОценок пока нет
- Defense PaperДокумент4 страницыDefense PaperBrittany StallworthОценок пока нет
- Kövecses EmotionconceptsДокумент46 страницKövecses Emotionconceptsivana иванаОценок пока нет
- (Antón & Dicamilla) Sociocognitive Functions of L1 Collaborative Interaction in The L2 ClassroomДокумент15 страниц(Antón & Dicamilla) Sociocognitive Functions of L1 Collaborative Interaction in The L2 ClassroomDaniloGarridoОценок пока нет
- Disc Personality Test Result - Free Disc Types Test Online at 123testДокумент4 страницыDisc Personality Test Result - Free Disc Types Test Online at 123testapi-434626717Оценок пока нет
- Cutting Edge Intermediate Scope and SequencesДокумент4 страницыCutting Edge Intermediate Scope and Sequencesgavjrm81Оценок пока нет
- Music Lesson PlanДокумент15 страницMusic Lesson PlanSharmaine Scarlet FranciscoОценок пока нет
- Grade 9 Science LP Week 4Документ13 страницGrade 9 Science LP Week 4venicer balaodОценок пока нет
- HKIE M3 Routes To MembershipДокумент25 страницHKIE M3 Routes To Membershipcu1988Оценок пока нет
- Qualitative Data AnalysisДокумент4 страницыQualitative Data AnalysisShambhav Lama100% (1)
- Mental Stress Evaluation Using Heart Rate Variability AnalysisДокумент7 страницMental Stress Evaluation Using Heart Rate Variability AnalysisKalpeshPatilОценок пока нет
- Jude Anthony Beato Fabellare: ObjectiveДокумент3 страницыJude Anthony Beato Fabellare: ObjectiveJude FabellareОценок пока нет
- OB Robbins Chapter 2Документ21 страницаOB Robbins Chapter 2Tawfeeq HasanОценок пока нет
- UNIT II Project EvaluationДокумент26 страницUNIT II Project Evaluationvinothkumar hОценок пока нет
- Level of Learning Motivation of The Grade 12 Senior High School in Labayug National High SchoolДокумент10 страницLevel of Learning Motivation of The Grade 12 Senior High School in Labayug National High SchoolMc Gregor TorioОценок пока нет
- Purposive AssignmentДокумент3 страницыPurposive AssignmentJune Clear Olivar LlabanОценок пока нет
- Descriptive Essay Introduction ExamplesДокумент5 страницDescriptive Essay Introduction ExampleszobvbccafОценок пока нет
- Slave Contract Level 1Документ2 страницыSlave Contract Level 1mg10183% (6)
- Your Honor, We Would Like To Have This Psychological Assessment Marked As P-10Документ7 страницYour Honor, We Would Like To Have This Psychological Assessment Marked As P-10Claudine ArrabisОценок пока нет
- What Is Geography WorksheetДокумент3 страницыWhat Is Geography Worksheetlambchop142009Оценок пока нет
- Minitab Survey Analysis With ANOVA and MoreДокумент4 страницыMinitab Survey Analysis With ANOVA and MoreAdnan MustafićОценок пока нет
- EPT Reviewer - Reading ComprehensionДокумент4 страницыEPT Reviewer - Reading ComprehensionLuther Gersin CañaОценок пока нет
- Final MBBS Part I Lectures Vol I PDFДокумент82 страницыFinal MBBS Part I Lectures Vol I PDFHan TunОценок пока нет
- Open Research Online: Kinky Clients, Kinky Counselling? The Challenges and Potentials of BDSMДокумент37 страницOpen Research Online: Kinky Clients, Kinky Counselling? The Challenges and Potentials of BDSMmonica cozarevОценок пока нет
- HouseДокумент19 страницHouseSandy100% (2)
- Outsiders To Love: The Psychopathic Character and DilemmaДокумент24 страницыOutsiders To Love: The Psychopathic Character and DilemmaCristina MirceanОценок пока нет
- Iskolar-Bos TM (Final) 2011Документ184 страницыIskolar-Bos TM (Final) 2011gpn1006Оценок пока нет
- 3 July - BSBLDR511 Student Version PDFДокумент61 страница3 July - BSBLDR511 Student Version PDFPrithu YashasОценок пока нет
- Annotated Bibliography 1Документ7 страницAnnotated Bibliography 1api-355663066Оценок пока нет
- Management Extit Exam Questions and Answers Part 2Документ8 страницManagement Extit Exam Questions and Answers Part 2yeabsrabaryagabrОценок пока нет