Вам также может понравиться
- Design and Analysis of Underground Circular & Rectangular Water Tank and Intze Water TankДокумент5 страницDesign and Analysis of Underground Circular & Rectangular Water Tank and Intze Water TankGRD JournalsОценок пока нет
- GRDJEV06I060005Документ7 страницGRDJEV06I060005GRD JournalsОценок пока нет
- Image Based Virtual Try On NetworkДокумент4 страницыImage Based Virtual Try On NetworkGRD JournalsОценок пока нет
- Chronic Kidney Disease Stage Prediction in HIV Infected Patient Using Deep LearningДокумент8 страницChronic Kidney Disease Stage Prediction in HIV Infected Patient Using Deep LearningGRD JournalsОценок пока нет
- Optimization of Xanthan Gum Fermentation Utilizing Food WasteДокумент11 страницOptimization of Xanthan Gum Fermentation Utilizing Food WasteGRD JournalsОценок пока нет
- Automatic Face Recognition Attendance System Using Python and OpenCvДокумент7 страницAutomatic Face Recognition Attendance System Using Python and OpenCvGRD Journals100% (1)
- Evaluate The Performance of MongoDB NoSQL Database Using PythonДокумент5 страницEvaluate The Performance of MongoDB NoSQL Database Using PythonGRD JournalsОценок пока нет
- Design and Simulation of LNA Using Advanced Design Systems (ADS)Документ6 страницDesign and Simulation of LNA Using Advanced Design Systems (ADS)GRD JournalsОценок пока нет
- Grdjev06i010003 PDFДокумент4 страницыGrdjev06i010003 PDFGRD JournalsОценок пока нет
- Simulation and Prediction of LULC Change Detection Using Markov Chain and Geo-Spatial Analysis, A Case Study in Ningxia North ChinaДокумент13 страницSimulation and Prediction of LULC Change Detection Using Markov Chain and Geo-Spatial Analysis, A Case Study in Ningxia North ChinaGRD JournalsОценок пока нет
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5794)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (400)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (345)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (121)
- Regional Manager Business Development in Atlanta GA Resume Jay GriffithДокумент2 страницыRegional Manager Business Development in Atlanta GA Resume Jay GriffithJayGriffithОценок пока нет
- Babe Ruth Saves BaseballДокумент49 страницBabe Ruth Saves BaseballYijun PengОценок пока нет
- Mahesh R Pujar: (Volume3, Issue2)Документ6 страницMahesh R Pujar: (Volume3, Issue2)Ignited MindsОценок пока нет
- Soujanya Reddy (New)Документ6 страницSoujanya Reddy (New)durgaОценок пока нет
- Hazardous Locations: C.E.C. ClassificationsДокумент4 страницыHazardous Locations: C.E.C. ClassificationsThananuwat SuksaroОценок пока нет
- Prospekt Puk U5 en Mail 1185Документ8 страницProspekt Puk U5 en Mail 1185sakthivelОценок пока нет
- Moquerio - Defense Mechanism ActivityДокумент3 страницыMoquerio - Defense Mechanism ActivityRoxan MoquerioОценок пока нет
- Native VLAN and Default VLANДокумент6 страницNative VLAN and Default VLANAaliyah WinkyОценок пока нет
- GE 7 ReportДокумент31 страницаGE 7 ReportMark Anthony FergusonОценок пока нет
- Colorfastness of Zippers To Light: Standard Test Method ForДокумент2 страницыColorfastness of Zippers To Light: Standard Test Method ForShaker QaidiОценок пока нет
- Sankranthi PDFДокумент39 страницSankranthi PDFMaruthiОценок пока нет
- A Review of Service Quality ModelsДокумент8 страницA Review of Service Quality ModelsJimmiJini100% (1)
- Arduino Uno CNC ShieldДокумент11 страницArduino Uno CNC ShieldMărian IoanОценок пока нет
- BSBITU314 Assessment Workbook FIllableДокумент51 страницаBSBITU314 Assessment Workbook FIllableAryan SinglaОценок пока нет
- JFC 180BBДокумент2 страницыJFC 180BBnazmulОценок пока нет
- Civ Beyond Earth HotkeysДокумент1 страницаCiv Beyond Earth HotkeysExirtisОценок пока нет
- Facebook: Daisy BuchananДокумент5 страницFacebook: Daisy BuchananbelenrichardiОценок пока нет
- Grade 9 Science Biology 1 DLPДокумент13 страницGrade 9 Science Biology 1 DLPManongdo AllanОценок пока нет
- Conservation Assignment 02Документ16 страницConservation Assignment 02RAJU VENKATAОценок пока нет
- UM-140-D00221-07 SeaTrac Developer Guide (Firmware v2.4)Документ154 страницыUM-140-D00221-07 SeaTrac Developer Guide (Firmware v2.4)Antony Jacob AshishОценок пока нет
- Seabank Statement 20220726Документ4 страницыSeabank Statement 20220726Alesa WahabappОценок пока нет
- H13 611 PDFДокумент14 страницH13 611 PDFMonchai PhaichitchanОценок пока нет
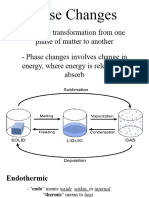
- General Chemistry 2 Q1 Lesson 5 Endothermic and Exotheric Reaction and Heating and Cooling CurveДокумент19 страницGeneral Chemistry 2 Q1 Lesson 5 Endothermic and Exotheric Reaction and Heating and Cooling CurveJolo Allexice R. PinedaОценок пока нет
- Ecs h61h2-m12 Motherboard ManualДокумент70 страницEcs h61h2-m12 Motherboard ManualsarokihОценок пока нет
- COURTESY Reception Good MannersДокумент1 страницаCOURTESY Reception Good MannersGulzina ZhumashevaОценок пока нет
- TFGДокумент46 страницTFGAlex Gigena50% (2)
- Dominion Wargame RulesДокумент301 страницаDominion Wargame Rules4544juutf100% (4)
- Alkosign Product CatalogeДокумент20 страницAlkosign Product CatalogeShree AgrawalОценок пока нет
- CLG418 (Dcec) PM 201409022-EnДокумент1 143 страницыCLG418 (Dcec) PM 201409022-EnMauricio WijayaОценок пока нет
- PE MELCs Grade 3Документ4 страницыPE MELCs Grade 3MARISSA BERNALDOОценок пока нет