Вам также может понравиться
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5783)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (890)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (399)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (265)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (344)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (119)
- 5 Job Interview Tips For IntrovertsДокумент5 страниц5 Job Interview Tips For IntrovertsSendhil RevuluriОценок пока нет
- Updated Syllabus - ME CSE Word Document PDFДокумент62 страницыUpdated Syllabus - ME CSE Word Document PDFGayathri R HICET CSE STAFFОценок пока нет
- Inquisitor Character Creation and AdvancementДокумент10 страницInquisitor Character Creation and AdvancementMichael MonchampОценок пока нет
- Human Resource Strategy: Atar Thaung HtetДокумент16 страницHuman Resource Strategy: Atar Thaung HtetaungnainglattОценок пока нет
- The Directors Six SensesДокумент31 страницаThe Directors Six SensesMichael Wiese Productions93% (14)
- Ashida Relay Operating ManualДокумент16 страницAshida Relay Operating ManualVivek Kakkoth100% (1)
- Ass. 2 English Revision WsДокумент3 страницыAss. 2 English Revision WsRishab ManochaОценок пока нет
- Chap 006Документ50 страницChap 006Martin TrịnhОценок пока нет
- Comparative Summary of 5 Learning TheoriesДокумент2 страницыComparative Summary of 5 Learning TheoriesMonique Gabrielle Nacianceno AalaОценок пока нет
- Homework #3 - Coursera CorrectedДокумент10 страницHomework #3 - Coursera CorrectedSaravind67% (3)
- Anthony Browder - The Mysteries of MelaninДокумент4 страницыAnthony Browder - The Mysteries of MelaninHidden Truth82% (11)
- Objective/Multiple Type QuestionДокумент14 страницObjective/Multiple Type QuestionMITALI TAKIAR100% (1)
- Analogs of Quantum Hall Effect Edge States in Photonic CrystalsДокумент23 страницыAnalogs of Quantum Hall Effect Edge States in Photonic CrystalsSangat BaikОценок пока нет
- Full Research PaperДокумент31 страницаFull Research PaperMeo ĐenОценок пока нет
- Ps FontfileДокумент6 страницPs FontfileRikárdo CamposОценок пока нет
- List of TNA MaterialsДокумент166 страницList of TNA MaterialsRamesh NayakОценок пока нет
- SM pc300350 lc6 PDFДокумент788 страницSM pc300350 lc6 PDFGanda Praja100% (2)
- Maternal and Perinatal Outcome in Jaundice Complicating PregnancyДокумент10 страницMaternal and Perinatal Outcome in Jaundice Complicating PregnancymanognaaaaОценок пока нет
- 677 1415 1 SMДокумент5 страниц677 1415 1 SMAditya RizkyОценок пока нет
- Certification Exam: Take A Business OnlineДокумент15 страницCertification Exam: Take A Business OnlineezerkaОценок пока нет
- Pulp Fiction DeconstructionДокумент3 страницыPulp Fiction Deconstructiondomatthews09Оценок пока нет
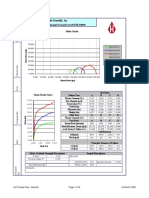
- Humboldt Scientific, Inc.: Normal Stress (Psi)Документ9 страницHumboldt Scientific, Inc.: Normal Stress (Psi)Dilson Loaiza CruzОценок пока нет
- A Review of The Book That Made Your World. by Vishal MangalwadiДокумент6 страницA Review of The Book That Made Your World. by Vishal Mangalwadigaylerob100% (1)
- Akhila-Rasamrta-Murtih Prasrmara-Ruci-Ruddha-Taraka-PalihДокумент44 страницыAkhila-Rasamrta-Murtih Prasrmara-Ruci-Ruddha-Taraka-PalihSauri ChaitanyaОценок пока нет
- Watch Blow Fly Arrang e Sleep Go Cook Clean Hear Cut Give Fall Open See Listen Carry Visit Buy Bring Write Bake Make Sit Play DrawДокумент3 страницыWatch Blow Fly Arrang e Sleep Go Cook Clean Hear Cut Give Fall Open See Listen Carry Visit Buy Bring Write Bake Make Sit Play DrawEmily NytОценок пока нет
- Figures of Speech AND 21 Literary GenresДокумент33 страницыFigures of Speech AND 21 Literary GenresMike AsuncionОценок пока нет
- Motor Driving School ReportДокумент39 страницMotor Driving School ReportAditya Krishnakumar73% (11)
- Sid The Science Kid - The Ruler of Thumb Cd1.avi Sid The Science Kid - The Ruler of Thumb Cd2.aviДокумент27 страницSid The Science Kid - The Ruler of Thumb Cd1.avi Sid The Science Kid - The Ruler of Thumb Cd2.avisheena2saОценок пока нет
- Determinants of Cash HoldingsДокумент26 страницDeterminants of Cash Holdingspoushal100% (1)
- Numerology Speaking PDFДокумент7 страницNumerology Speaking PDFValeria NoginaОценок пока нет