Вам также может понравиться
- Eliminate Voltage Unbalance On Induction Motors-TipsДокумент2 страницыEliminate Voltage Unbalance On Induction Motors-TipsGyogi MitsutaОценок пока нет
- The Hot Issue of Motor Temperature Ratings - Ed Cowern-EC&MДокумент5 страницThe Hot Issue of Motor Temperature Ratings - Ed Cowern-EC&MGyogi MitsutaОценок пока нет
- A Comparative Study On Bearings Faults Classification by Artificial Neural NetworksДокумент8 страницA Comparative Study On Bearings Faults Classification by Artificial Neural NetworksGyogi MitsutaОценок пока нет
- Air Compressor FMEAДокумент32 страницыAir Compressor FMEAJitu Jena67% (6)
- Hierarchy Knoeledge Engineering From Wei ZhaoДокумент245 страницHierarchy Knoeledge Engineering From Wei ZhaoGyogi MitsutaОценок пока нет
- ABB Case StudyДокумент2 страницыABB Case StudyGyogi MitsutaОценок пока нет
- Estimation of The Economic Effect of Implementing RCM On A Maritime VesselДокумент109 страницEstimation of The Economic Effect of Implementing RCM On A Maritime VesselGyogi MitsutaОценок пока нет
- An Assessment of RPN Prioritization in A FMECAДокумент7 страницAn Assessment of RPN Prioritization in A FMECAGyogi MitsutaОценок пока нет
- Failure Finding Frequency For Repairable System Subject To Hidden Failures PDFДокумент19 страницFailure Finding Frequency For Repairable System Subject To Hidden Failures PDFGyogi MitsutaОценок пока нет
- Failure Finding Frequency For Repairable System Subject To Hidden Failures PDFДокумент19 страницFailure Finding Frequency For Repairable System Subject To Hidden Failures PDFGyogi MitsutaОценок пока нет
- Dynamic Change in Reliability StrategyДокумент3 страницыDynamic Change in Reliability StrategyGyogi MitsutaОценок пока нет
- Maintainability Prediction For Aircraft Mechanical ComponentДокумент206 страницMaintainability Prediction For Aircraft Mechanical ComponentGyogi MitsutaОценок пока нет
- Pump Vibration-Case StudiesДокумент10 страницPump Vibration-Case StudiesGyogi MitsutaОценок пока нет
- AITP-L02 Appendix 04-03 PDFДокумент75 страницAITP-L02 Appendix 04-03 PDFNaveen SoysaОценок пока нет
- Maintenance Strategies To Reduce Downtime Due To Machine Positional ErrorsДокумент8 страницMaintenance Strategies To Reduce Downtime Due To Machine Positional ErrorsHugoCabanillasОценок пока нет
- The Lean Toolbox - 25 Essential Lean ToolsДокумент3 страницыThe Lean Toolbox - 25 Essential Lean ToolsGyogi MitsutaОценок пока нет
- Improving Aircraft Fleet Maintenance - IAAI97-212Документ8 страницImproving Aircraft Fleet Maintenance - IAAI97-212gmitsutaОценок пока нет
- Distribution Models-Theory PDFДокумент307 страницDistribution Models-Theory PDFGyogi MitsutaОценок пока нет
- Montacarga Hyster - H80-120FT TechGuide PDFДокумент16 страницMontacarga Hyster - H80-120FT TechGuide PDFGyogi MitsutaОценок пока нет
- Maintenance Planning SystemsДокумент55 страницMaintenance Planning SystemsGyogi MitsutaОценок пока нет
- Reliability Maintenance Is Good MedicineДокумент12 страницReliability Maintenance Is Good MedicineGyogi MitsutaОценок пока нет
- Work Cycle Based SchedulingДокумент10 страницWork Cycle Based SchedulingGyogi MitsutaОценок пока нет
- Electrical Engineering Centrifugal Pumps Vibration PDFДокумент25 страницElectrical Engineering Centrifugal Pumps Vibration PDFGyogi MitsutaОценок пока нет
- Axxim Brochure LloydsДокумент3 страницыAxxim Brochure LloydsGyogi MitsutaОценок пока нет
- Centrifugal Pump Problems ChecklistsДокумент39 страницCentrifugal Pump Problems ChecklistsionesqОценок пока нет
- Bosch Lean Manufacturing Guidebook-1Документ16 страницBosch Lean Manufacturing Guidebook-1minal potavatreОценок пока нет
- Montacarga Toyota 8FG 8FDДокумент24 страницыMontacarga Toyota 8FG 8FDGyogi Mitsuta100% (1)
- Importance of FRACAS To Ensure Product Reliability PDFДокумент5 страницImportance of FRACAS To Ensure Product Reliability PDFGyogi MitsutaОценок пока нет
- Introduction To Lean ProductionДокумент11 страницIntroduction To Lean ProductionGyogi MitsutaОценок пока нет
- PTC Fracas Best Practices WP enДокумент9 страницPTC Fracas Best Practices WP ennicocla94maramОценок пока нет
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5783)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (890)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (399)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (265)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (344)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (119)
- Thermodynamic Properties of Lithium Bromide Water Solutions at High TemperaturesДокумент17 страницThermodynamic Properties of Lithium Bromide Water Solutions at High TemperaturesAnonymous 7IKdlmОценок пока нет
- Mahindra&mahindraДокумент95 страницMahindra&mahindraAshik R GowdaОценок пока нет
- Pattern MatchingДокумент58 страницPattern Matchingamitavaghosh1Оценок пока нет
- Regal Raptor DAYTONA Euro IV Owner ManualДокумент25 страницRegal Raptor DAYTONA Euro IV Owner ManualKrzysztof Jakiś50% (2)
- Lecture Notes 8b - Slope Deflection Frames No Sidesway PDFДокумент12 страницLecture Notes 8b - Slope Deflection Frames No Sidesway PDFShavin ChandОценок пока нет
- Chapter 3 - Equilibrium of Particles: ObjectivesДокумент17 страницChapter 3 - Equilibrium of Particles: ObjectivesRhey LuceroОценок пока нет
- The Future of De-Icing: Safeaero 220Документ8 страницThe Future of De-Icing: Safeaero 220焦中华Оценок пока нет
- BFC 31901 Structure LabsheetДокумент11 страницBFC 31901 Structure LabsheetAshyra JamilОценок пока нет
- CRP900 Benchtop PRO Assembly Instructions v2019Q1 1Документ86 страницCRP900 Benchtop PRO Assembly Instructions v2019Q1 1glamura100% (1)
- Ece 230Документ4 страницыEce 230JackОценок пока нет
- Parts Catalog: 1270D Wheel Harvester (0001-0997)Документ772 страницыParts Catalog: 1270D Wheel Harvester (0001-0997)NunesSergioОценок пока нет
- 2014 ELECTRICAL Lighting - Schematic Wiring Diagrams - LaCrosseДокумент21 страница2014 ELECTRICAL Lighting - Schematic Wiring Diagrams - LaCrosseMon DiОценок пока нет
- Modicom M340Документ267 страницModicom M340Davis AcuñaОценок пока нет
- TSC List of Correspondents 201711 PDFДокумент180 страницTSC List of Correspondents 201711 PDFbaroon1234Оценок пока нет
- Buok Chapter 2Документ15 страницBuok Chapter 2Edmil Jhon AriquezОценок пока нет
- OS X ShortcutsДокумент19 страницOS X Shortcutsia_moheetОценок пока нет
- NorsokДокумент133 страницыNorsokNuzuliana EnuzОценок пока нет
- Schem SPI Administration ModuleДокумент491 страницаSchem SPI Administration Modulejeeva438475% (4)
- Classical Mechanics 2Документ109 страницClassical Mechanics 2pticicaaaОценок пока нет
- Fuji FCR 5000 Service ManualДокумент892 страницыFuji FCR 5000 Service Manualmasroork_270% (10)
- Glycol Dehydration UnitДокумент11 страницGlycol Dehydration UnitarispriyatmonoОценок пока нет
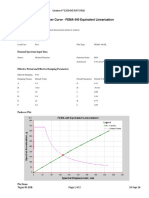
- FEMA 440 equivalent linearization pushover analysisДокумент2 страницыFEMA 440 equivalent linearization pushover analysisAdam JrОценок пока нет
- Project Report On GearsДокумент40 страницProject Report On GearsHaNan KhaLeelОценок пока нет
- 1g Mitsubishi 6G72 - FusesДокумент5 страниц1g Mitsubishi 6G72 - Fusesaren_mendoza75% (4)
- Vectron+1-6 300713 en 1.6Документ24 страницыVectron+1-6 300713 en 1.6kikokadolaОценок пока нет
- ResistanceДокумент72 страницыResistanceParisDelaCruzОценок пока нет
- Amines Plant PresentationДокумент22 страницыAmines Plant Presentationirsanti dewiОценок пока нет
- T 2 ReviewДокумент5 страницT 2 ReviewAYA707Оценок пока нет
- Conservation of Momentum Worksheet PDFДокумент8 страницConservation of Momentum Worksheet PDFChristopher John Inamac Gayta (Chris)Оценок пока нет
- How To Install and Root Your Android Emulator - Cyber Treat Defense On Security TutorialsДокумент11 страницHow To Install and Root Your Android Emulator - Cyber Treat Defense On Security TutorialsCarlos SanchezОценок пока нет