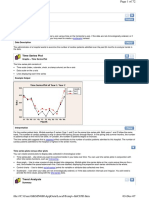
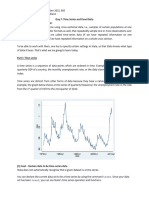
Вам также может понравиться
- Time Series with Python: How to Implement Time Series Analysis and Forecasting Using PythonОт EverandTime Series with Python: How to Implement Time Series Analysis and Forecasting Using PythonРейтинг: 3 из 5 звезд3/5 (1)
- Efficient Pair Selection For Pair-Trading StrategiesДокумент16 страницEfficient Pair Selection For Pair-Trading Strategiesalexa_sherpyОценок пока нет
- Global Logistics & Supply Chain Management Chapter 7 MCQДокумент21 страницаGlobal Logistics & Supply Chain Management Chapter 7 MCQVeninsta Yap100% (3)
- Project ForecastingДокумент23 страницыProject ForecastingSarath ChandraОценок пока нет
- Time Series ForcastingДокумент19 страницTime Series ForcastingSanan OlacheryОценок пока нет
- Gas ProductionДокумент29 страницGas ProductionPranav ViswanathanОценок пока нет
- Chapter 3Документ36 страницChapter 3asdasdasd122Оценок пока нет
- Image AnalysisДокумент6 страницImage Analysissageson_m-1Оценок пока нет
- Plugin Seasonal+Adjustment+ +Instructions+for+Seasonal+Adjustment+With+Demetra+ (Sept.+2009)Документ25 страницPlugin Seasonal+Adjustment+ +Instructions+for+Seasonal+Adjustment+With+Demetra+ (Sept.+2009)any_gОценок пока нет
- Time Series Analysis of Air Duality DataДокумент7 страницTime Series Analysis of Air Duality DataECRD100% (1)
- Forecasting Sales Through Time Series ClusteringДокумент18 страницForecasting Sales Through Time Series ClusteringLewis TorresОценок пока нет
- CHAPTER-6 FORECASTING TECHNIQUES - Formatted PDFДокумент46 страницCHAPTER-6 FORECASTING TECHNIQUES - Formatted PDFDrShaik FarookОценок пока нет
- TS Gas ReportДокумент43 страницыTS Gas Reportsravanthi mОценок пока нет
- Adding Additional Features To Improve Time Series PredictionДокумент7 страницAdding Additional Features To Improve Time Series PredictionWF1 Hackathon1Оценок пока нет
- Project 5 - GasДокумент17 страницProject 5 - GasAreej Aftab SiddiquiОценок пока нет
- What Were They ThinkingДокумент11 страницWhat Were They ThinkingtychesterОценок пока нет
- Moving Average PDFДокумент15 страницMoving Average PDFSachen KulandaivelОценок пока нет
- Minitab Statguide Time SeriesДокумент72 страницыMinitab Statguide Time SeriesSuraj singhОценок пока нет
- Predictive Models For Proactive Network Management: Application To A Production Web ServerДокумент14 страницPredictive Models For Proactive Network Management: Application To A Production Web ServerkurtovicОценок пока нет
- Institute of Management Science: Time Series AnalysisДокумент19 страницInstitute of Management Science: Time Series AnalysisMohammad AzanОценок пока нет
- Decomposition MethodДокумент73 страницыDecomposition MethodAbdirahman DeereОценок пока нет
- How To: Forecast Seasonal Time Series Data Using STATGRAPHICS CenturionДокумент15 страницHow To: Forecast Seasonal Time Series Data Using STATGRAPHICS Centurionlouish9175841Оценок пока нет
- Chap 3 ForecastingДокумент23 страницыChap 3 ForecastingEilham ArashyОценок пока нет
- TS Gas ReportДокумент40 страницTS Gas ReportRaja Sekhar PОценок пока нет
- Unit+8 (Block 2)Документ24 страницыUnit+8 (Block 2)Nitish BhaskarОценок пока нет
- QAM-Business Forecasting (Session 6)Документ7 страницQAM-Business Forecasting (Session 6)Nirajan SharmaОценок пока нет
- Project 6 - To Forecast Australian Monthly Gas Production PDFДокумент32 страницыProject 6 - To Forecast Australian Monthly Gas Production PDFMustafa A RangoonwalaОценок пока нет
- Operations Manager For Excel (C) 1997-2003, User Solutions, IncДокумент18 страницOperations Manager For Excel (C) 1997-2003, User Solutions, IncRabih DarwishОценок пока нет
- Chapter 3Документ61 страницаChapter 3Ibn Al-MutawkelОценок пока нет
- Trend Analysis PDFДокумент15 страницTrend Analysis PDFSachen KulandaivelОценок пока нет
- Organizing and Summarizing Data: StatisticsДокумент23 страницыOrganizing and Summarizing Data: Statisticssalah ashrafОценок пока нет
- PANELДокумент7 страницPANELapurva.tudekarОценок пока нет
- S 5Документ19 страницS 5Emmanuel LazoОценок пока нет
- ForecastingДокумент48 страницForecastingJennyne PeipeiОценок пока нет
- Decompositin Lengkap PDFДокумент18 страницDecompositin Lengkap PDFLuthfan Zul FahmiОценок пока нет
- Rainfall Prediction Based On Rainfall Statistical DataДокумент6 страницRainfall Prediction Based On Rainfall Statistical DataEditor IJRITCCОценок пока нет
- 1.4 Forecasting Data and MethodsДокумент4 страницы1.4 Forecasting Data and MethodsVicente Camarillo AdameОценок пока нет
- Industrial Engineering: Sales and Demand ForecastingДокумент47 страницIndustrial Engineering: Sales and Demand ForecastingKAMAL PATIОценок пока нет
- It's About Time Appendix DДокумент18 страницIt's About Time Appendix DSujana BaruОценок пока нет
- GraphingДокумент4 страницыGraphingapi-257668156Оценок пока нет
- Methods of Time SeriesДокумент12 страницMethods of Time SeriesSntn UaОценок пока нет
- Proposal Bab3Документ8 страницProposal Bab3Arivval PratamaОценок пока нет
- IOSR JournalsДокумент2 страницыIOSR JournalsInternational Organization of Scientific Research (IOSR)Оценок пока нет
- End Term Project (BA)Документ19 страницEnd Term Project (BA)atmagaragОценок пока нет
- Data Mining User BehaviorДокумент9 страницData Mining User BehaviortychesterОценок пока нет
- Introduction To MechatronicДокумент19 страницIntroduction To MechatronicAmirul Arif0% (1)
- Exponential SmoothingДокумент5 страницExponential Smoothingzeeshan_ipscОценок пока нет
- Arima and Holt Winter PDFДокумент43 страницыArima and Holt Winter PDFshekarthimmappaОценок пока нет
- Marketing Analytics - Group 7Документ9 страницMarketing Analytics - Group 7ankitОценок пока нет
- Mod 4Документ24 страницыMod 4José Manuel MedranoОценок пока нет
- Statistical Analysis and Forecasting of Solar Energy (Inter-States)Документ21 страницаStatistical Analysis and Forecasting of Solar Energy (Inter-States)Chaitanya BalaniОценок пока нет
- Descriptive StatisticsДокумент27 страницDescriptive Statisticschan kyoОценок пока нет
- Run Chart: Basic Tools For Process ImprovementДокумент38 страницRun Chart: Basic Tools For Process ImprovementKar HamdhaniОценок пока нет
- Final ReportДокумент30 страницFinal ReportThương VănОценок пока нет
- Use of Statistics by ScientistДокумент22 страницыUse of Statistics by Scientistvzimak2355Оценок пока нет
- Time SeriesДокумент34 страницыTime SeriesPriti67% (3)
- LakshmiY 12110035 SolutionsДокумент10 страницLakshmiY 12110035 SolutionsLakshmi Harshitha YechuriОценок пока нет
- Lab 3 Counting StatisticsДокумент10 страницLab 3 Counting StatisticsPataki SandorОценок пока нет
- Multimega Parti 3Документ0 страницMultimega Parti 3Riccardo MelisОценок пока нет
- Start Predicting In A World Of Data Science And Predictive AnalysisОт EverandStart Predicting In A World Of Data Science And Predictive AnalysisОценок пока нет
- Six Sigma Green Belt, Round 2: Making Your Next Project Better than the Last OneОт EverandSix Sigma Green Belt, Round 2: Making Your Next Project Better than the Last OneОценок пока нет
- Tumuluri Sarath Chandra Resume V4Документ1 страницаTumuluri Sarath Chandra Resume V4Sarath ChandraОценок пока нет
- Project Main To PrintДокумент69 страницProject Main To PrintSarath ChandraОценок пока нет
- Cover Letter SarathchandraДокумент1 страницаCover Letter SarathchandraSarath ChandraОценок пока нет
- Dr. P. Ravinder ReddyДокумент1 страницаDr. P. Ravinder ReddySarath ChandraОценок пока нет
- Fuel Injectors ModifiedДокумент10 страницFuel Injectors ModifiedSarath ChandraОценок пока нет
- Chapter 3 - Demand Forecasting: # Het Begint Met Een IdeeДокумент32 страницыChapter 3 - Demand Forecasting: # Het Begint Met Een IdeeThy NguyễnОценок пока нет
- Chapter 4 Market and Demand AnalysisДокумент33 страницыChapter 4 Market and Demand Analysispritish mohantyОценок пока нет
- Tutorial 3 SolutionДокумент8 страницTutorial 3 Solutionthanusha selvamanyОценок пока нет
- Forelæsning 6 Forecasting-IДокумент53 страницыForelæsning 6 Forecasting-IBelal FaizОценок пока нет
- BSA Unit-II Topic - Time Series & Index No.Документ55 страницBSA Unit-II Topic - Time Series & Index No.singhsaurabhh91Оценок пока нет
- Forecasting For Exports and Imports in IndonesiaДокумент5 страницForecasting For Exports and Imports in IndonesiaInternational Journal of Innovative Science and Research TechnologyОценок пока нет
- OM Narrative ReportДокумент9 страницOM Narrative ReportJinx Cyrus RodilloОценок пока нет
- Data Dictionary:: Variable NameДокумент8 страницData Dictionary:: Variable NameWildShyamОценок пока нет
- 03 Aggregate Operations PlanningДокумент79 страниц03 Aggregate Operations PlanningstefpossemiersОценок пока нет
- Industrial Engineering by S K MondalДокумент5 страницIndustrial Engineering by S K MondalRaghuChouhanОценок пока нет
- Operations MGMT - AIMAДокумент549 страницOperations MGMT - AIMATata SatishkumarОценок пока нет
- Sample Quiz1 QuestionsДокумент8 страницSample Quiz1 QuestionsBig DataОценок пока нет
- Forecasting in Industrial EngineeringДокумент61 страницаForecasting in Industrial EngineeringSuneel Kumar Meena100% (9)
- POM File 6 ForecastingДокумент6 страницPOM File 6 ForecastingGela LaceronaОценок пока нет
- Index NumbersДокумент112 страницIndex NumbersryanharunОценок пока нет
- OM Assignment 1Документ16 страницOM Assignment 1soham agarwalОценок пока нет
- Agri Supply Chain Management: Shraddha BhatiaДокумент9 страницAgri Supply Chain Management: Shraddha BhatiaYashu ShuklaОценок пока нет
- Modelling Risk For Commodities in Brazil: An Application To Live Cattle Spot and Futures PricesДокумент28 страницModelling Risk For Commodities in Brazil: An Application To Live Cattle Spot and Futures PriceskarepanmanОценок пока нет
- Chase - Shankar - JacobsДокумент44 страницыChase - Shankar - JacobsSaurav PandabОценок пока нет
- Hci in Business, Government and Organizations: Ecommerce and Consumer BehaviorДокумент393 страницыHci in Business, Government and Organizations: Ecommerce and Consumer BehaviorRahulChampОценок пока нет
- Sales and Distribution MGMT - Tapan K PandaДокумент195 страницSales and Distribution MGMT - Tapan K PandaAvnit Chaudhary84% (19)
- Project Management: Demand ForecastДокумент30 страницProject Management: Demand ForecastRam Krishna Singh100% (1)
- Chapter 5 - GeДокумент17 страницChapter 5 - Gewcm007Оценок пока нет
- Time Series ForecastingДокумент52 страницыTime Series ForecastingAniket ChauhanОценок пока нет
- Business Forecasting MethodsДокумент5 страницBusiness Forecasting MethodsgauravОценок пока нет
- Forecast Pro TRAC V5 User's GuideДокумент420 страницForecast Pro TRAC V5 User's GuideCristian Ionita-ManiaОценок пока нет
- Forecasting 1Документ27 страницForecasting 1Abhishek KumarОценок пока нет
- Demand Forecasting PDFДокумент30 страницDemand Forecasting PDFVijay ParuchuriОценок пока нет
- Lesson 7 ForecastingДокумент116 страницLesson 7 ForecastingJohn Philip ReyesОценок пока нет