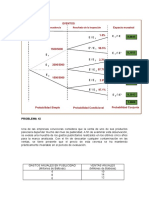
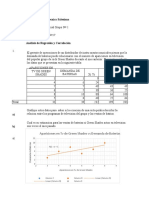
Вам также может понравиться
- R. MúltipleEjercicioДокумент8 страницR. MúltipleEjercicioEloisa Ovando80% (5)
- Examen de Estadística-2.0Документ5 страницExamen de Estadística-2.0Georgina Marquez100% (1)
- Taller M.T.C y Dispersión PsicologíaДокумент22 страницыTaller M.T.C y Dispersión PsicologíaDaniela OroscoОценок пока нет
- 5 SetДокумент39 страниц5 SetGioan LondoñoОценок пока нет
- Normativa Mecanicos AMERICA RPДокумент4 страницыNormativa Mecanicos AMERICA RPMatias VenegasОценок пока нет
- Evaluación (EAA)Документ3 страницыEvaluación (EAA)Matias VenegasОценок пока нет
- Auxiliar1, Pit OptimiserДокумент26 страницAuxiliar1, Pit OptimiserMatias VenegasОценок пока нет
- Analisis de Datos para Realizar Una Curva Tonelaje Ley PDFДокумент19 страницAnalisis de Datos para Realizar Una Curva Tonelaje Ley PDFMatias VenegasОценок пока нет
- Ejercicios Modelamiento - AДокумент6 страницEjercicios Modelamiento - AMatias VenegasОценок пока нет
- CXS 299s PDFДокумент6 страницCXS 299s PDFMatias VenegasОценок пока нет
- Atlas de Faenas Mineras Regiones de Valparaiso, Ohiggins y MetropolitanaДокумент356 страницAtlas de Faenas Mineras Regiones de Valparaiso, Ohiggins y MetropolitanaVictor Melo Muñoz100% (4)
- Integracion NumericaДокумент45 страницIntegracion NumericaMatias VenegasОценок пока нет
- U2 - Series de TiempoДокумент16 страницU2 - Series de Tiempoalma yunisОценок пока нет
- Plan Estadistica - CriminalДокумент5 страницPlan Estadistica - CriminalCUARENTENA CUT PREPAОценок пока нет
- Taller de DISTRIBUCIÓN DE MUESTREO APUNTESДокумент11 страницTaller de DISTRIBUCIÓN DE MUESTREO APUNTESAndres Felipe Herrera SalazarОценок пока нет
- Estadistica 3 2018Документ6 страницEstadistica 3 2018Cecilia Laura Torres Pariona0% (1)
- Evaluación para La Estimación de Una Media Con Desviación Estándar DesconocidaДокумент4 страницыEvaluación para La Estimación de Una Media Con Desviación Estándar Desconocidapablo angelОценок пока нет
- EstadisticaДокумент4 страницыEstadisticaDanna Cuervo marinОценок пока нет
- Actividad Ditribiciones de Probabilidad 16 Julio 2020Документ29 страницActividad Ditribiciones de Probabilidad 16 Julio 2020Greis Kelys ORTIZ CERAОценок пока нет
- Ejercicio Basicos Tema 3 - Alcocer VanessaДокумент3 страницыEjercicio Basicos Tema 3 - Alcocer VanessaJesusAlbertoReynaMaderaОценок пока нет
- Tablas de Frecuencias Con Datos AgrupadosДокумент7 страницTablas de Frecuencias Con Datos AgrupadosPedro David Flores Barriga100% (1)
- Variable DiscretaДокумент18 страницVariable DiscretaAstrid Sulay Sierra BoyacáОценок пока нет
- Capítulo 20 Análisis FactorialДокумент41 страницаCapítulo 20 Análisis Factorialkaremsanchez2410Оценок пока нет
- Practica Dirigida 5Документ5 страницPractica Dirigida 5IrwinUruchiОценок пока нет
- Ejercicios 1 - Descriptiva y Probabilidad PDFДокумент5 страницEjercicios 1 - Descriptiva y Probabilidad PDFCarlosОценок пока нет
- Taller 17Документ39 страницTaller 17Sebastian CuevaОценок пока нет
- Diseño de Experimentos de Un FactorДокумент36 страницDiseño de Experimentos de Un Factorzulema100% (3)
- Evelyn Colville Tarea Semana 8Документ7 страницEvelyn Colville Tarea Semana 8Evelyn Colville CorreaОценок пока нет
- Practica 4 - Distribucion F y ANOVAДокумент2 страницыPractica 4 - Distribucion F y ANOVAJosé Arturo HenriquezОценок пока нет
- 5º Trabajo - Saenz - Estadistica AplicadaДокумент25 страниц5º Trabajo - Saenz - Estadistica AplicadaLenin Chauca RamosОценок пока нет
- Estadística DescriptivaДокумент19 страницEstadística Descriptivacarlo belliОценок пока нет
- Indicador: Tasa de desempleo -Perú (%) : k=x± z σ nДокумент3 страницыIndicador: Tasa de desempleo -Perú (%) : k=x± z σ nliz usca100% (2)
- Solucionario de La Práctica EstadisticaДокумент14 страницSolucionario de La Práctica EstadisticaOscar KenDer AchalmaОценок пока нет
- Test No ParametricosДокумент54 страницыTest No Parametricosandres cernaОценок пока нет
- Actividad Tarea No. 3 EstadisticaДокумент7 страницActividad Tarea No. 3 EstadisticaAshleyОценок пока нет
- Est. Inf. 1+trabajo FinalДокумент6 страницEst. Inf. 1+trabajo FinalJorge Sosa TapiaОценок пока нет
- Infografia PDFДокумент1 страницаInfografia PDFJosue AguirreОценок пока нет
- Trabajo Final E.A.Документ9 страницTrabajo Final E.A.Carmen Pipa soriaОценок пока нет