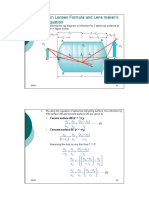
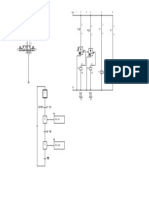
Вам также может понравиться
- Mechanics of Vibration Formula SheetДокумент3 страницыMechanics of Vibration Formula Sheetshah saadОценок пока нет
- Formula Sheet For Gas DynamicsДокумент3 страницыFormula Sheet For Gas DynamicsAdnan PirbhaiОценок пока нет
- Hs 342Документ45 страницHs 342Fernando Martinez ContrerasОценок пока нет
- NaphthaleneДокумент4 страницыNaphthaleneAntonio VeraОценок пока нет
- Y625U - PCB Board Diagram PDFДокумент2 страницыY625U - PCB Board Diagram PDFAlee LópezОценок пока нет
- Statistical Tables and Charts SummaryДокумент28 страницStatistical Tables and Charts SummaryMasitha LuthfiyaОценок пока нет
- Microwave Amplifier Design GuideДокумент40 страницMicrowave Amplifier Design GuideKubilay ÖzdemirОценок пока нет
- Negative Resistance Oscillators: Ceramic Oscillator (CRO) Dielectric Oscillator (DRO)Документ50 страницNegative Resistance Oscillators: Ceramic Oscillator (CRO) Dielectric Oscillator (DRO)megadaveОценок пока нет
- Al Girar Alrededor de Su Hipotenusa Un Triangulo Rectángulo Isósceles, Genera Un Volumen De, Halla El Área de Dicho TrianguloДокумент6 страницAl Girar Alrededor de Su Hipotenusa Un Triangulo Rectángulo Isósceles, Genera Un Volumen De, Halla El Área de Dicho TrianguloFernando PonceОценок пока нет
- Chapter - 2 Load Flow Method For Radial Distribution SystemsДокумент23 страницыChapter - 2 Load Flow Method For Radial Distribution SystemsAA RR100% (1)
- UntitledДокумент11 страницUntitledPennyОценок пока нет
- ESTADISTICOSДокумент1 страницаESTADISTICOSMagali FleitasОценок пока нет
- Tugas Fisik LanjutДокумент7 страницTugas Fisik LanjutAdya PradiptaОценок пока нет
- IzolateДокумент7 страницIzolateGaál Csaba NimródОценок пока нет
- SF017 Thin Lenses FormulaДокумент2 страницыSF017 Thin Lenses FormulaNivegad HerОценок пока нет
- Formula RioДокумент3 страницыFormula RioJean Taipe ChavezОценок пока нет
- Formula RioДокумент3 страницыFormula RioJean Taipe ChavezОценок пока нет
- MESB 203 Lab No. 6: Flow Rate Measurement TechniquesДокумент6 страницMESB 203 Lab No. 6: Flow Rate Measurement Techniquesusebio64Оценок пока нет
- Week 7: LECTURE 2: CH 14.3: Double Integrals in Polar CoordinatesДокумент12 страницWeek 7: LECTURE 2: CH 14.3: Double Integrals in Polar CoordinatesLayan NandОценок пока нет
- Appendices: Appendix A. Statistical Tables and Charts 651Документ27 страницAppendices: Appendix A. Statistical Tables and Charts 651mt40mОценок пока нет
- A3 - Earthquake - Ce4-3 - Aningga, John LinardДокумент5 страницA3 - Earthquake - Ce4-3 - Aningga, John LinardJohn Linard AninggaОценок пока нет
- Ms Xii Physics Set 4Документ4 страницыMs Xii Physics Set 4Yohan BabuОценок пока нет
- Standard Laplace Transforms TableДокумент2 страницыStandard Laplace Transforms TablemeloОценок пока нет
- Function Approximation Case Study: Smart SensorДокумент10 страницFunction Approximation Case Study: Smart SensorAlee LópezОценок пока нет
- MECH4450 Introduction To Finite Element Methods: FEM of 1-D Problems: ApplicationsДокумент40 страницMECH4450 Introduction To Finite Element Methods: FEM of 1-D Problems: ApplicationsAnimesh Kumar JhaОценок пока нет
- Face Recognition Using Neural NetworksДокумент32 страницыFace Recognition Using Neural NetworksSajal MahajanОценок пока нет
- Appendix A Statistical Tables and ChartsДокумент26 страницAppendix A Statistical Tables and ChartsbobОценок пока нет
- 9FM0-01 Sample Question Paper Candidate ExemplarsДокумент62 страницы9FM0-01 Sample Question Paper Candidate ExemplarsscribdОценок пока нет
- STAT 2601 Test 3 Formula Sheet (Official)Документ1 страницаSTAT 2601 Test 3 Formula Sheet (Official)subui613Оценок пока нет
- Partial GДокумент50 страницPartial GnemaderakeshОценок пока нет
- Screenshot 2024-03-22 at 10.38.20 AMДокумент82 страницыScreenshot 2024-03-22 at 10.38.20 AMPhorn DevithОценок пока нет
- Frame Analysis Byfinite Element Method: Finite Element Method by G. R. Liu and S. S. QuekДокумент29 страницFrame Analysis Byfinite Element Method: Finite Element Method by G. R. Liu and S. S. QuekananiaОценок пока нет
- PlateДокумент13 страницPlateRajendra PraharajОценок пока нет
- Flowrate MeasurementДокумент5 страницFlowrate Measurementhezree hilmanОценок пока нет
- A System of Reaction Diffusion Equations Modeling The Spread of Resistance To Anti-Malarial DrugsДокумент15 страницA System of Reaction Diffusion Equations Modeling The Spread of Resistance To Anti-Malarial DrugspostscriptОценок пока нет
- 11 Rational Functions of Sinx and CosxДокумент3 страницы11 Rational Functions of Sinx and CosxRosewill AlcaideОценок пока нет
- Practical Training Issues: Network Training Steps and Data PreprocessingДокумент34 страницыPractical Training Issues: Network Training Steps and Data PreprocessingAlee LópezОценок пока нет
- CJC 2018 Promo Solution - EditedДокумент17 страницCJC 2018 Promo Solution - Editedtoh tim lamОценок пока нет
- Miscellaneous Questions Bank SolutionsДокумент16 страницMiscellaneous Questions Bank SolutionsJee AspirantОценок пока нет
- Network ParametersДокумент55 страницNetwork Parametersmehul03ecОценок пока нет
- 2022 JEE Main 16 SolutionsДокумент15 страниц2022 JEE Main 16 SolutionsHimanshu SinghОценок пока нет
- Expression of Network Power Loss As A Function of Generation PowerДокумент20 страницExpression of Network Power Loss As A Function of Generation PowerPradip KhatriОценок пока нет
- 4.3 Orthogonal DiagonalizationДокумент11 страниц4.3 Orthogonal DiagonalizationNor adilahОценок пока нет
- NetworkДокумент55 страницNetworkIman El HilahОценок пока нет
- 05 Combinational Logic Building BlocksДокумент17 страниц05 Combinational Logic Building BlocksAyhan AbdulAzizОценок пока нет
- Model QP-02 08 FON PDFДокумент26 страницModel QP-02 08 FON PDFNanda KumarОценок пока нет
- Business Statistics Formula - SheetДокумент7 страницBusiness Statistics Formula - SheetSushmaОценок пока нет
- Chapter IIДокумент30 страницChapter IISwarndevi KmОценок пока нет
- RF Communication Circuits S-ParametersДокумент55 страницRF Communication Circuits S-ParametersAnonymous U8awvgZ3pDОценок пока нет
- Advanced Math 2Документ4 страницыAdvanced Math 2Anonymous flP4bZ4OОценок пока нет
- DC Circuits: Fundamentals of Electric CircuitsДокумент39 страницDC Circuits: Fundamentals of Electric CircuitsHoàng HoàngAnhОценок пока нет
- Microwave NetworksДокумент14 страницMicrowave NetworksDenis CarlosОценок пока нет
- Advanced Level Problem Solving (ALPS-5) - SolutionДокумент19 страницAdvanced Level Problem Solving (ALPS-5) - SolutionAyush guptaОценок пока нет
- Grafcet 22Документ1 страницаGrafcet 22Ivor JerkicОценок пока нет
- (AM) KED Set1 SKEMA K2Документ18 страниц(AM) KED Set1 SKEMA K2Aqhinatul QatriahОценок пока нет
- BernoulliДокумент12 страницBernoullijegaОценок пока нет
- MAT231BT - Inverse Laplace TransformsДокумент12 страницMAT231BT - Inverse Laplace TransformsRochakОценок пока нет
- Ch19_Two-Port NetworksДокумент26 страницCh19_Two-Port NetworksdadsdОценок пока нет
- MA306 - Formula SheetДокумент2 страницыMA306 - Formula SheetTinlu BaananteОценок пока нет
- ELL 100 Introduction To Electrical Engineering: L 22: T - P NДокумент66 страницELL 100 Introduction To Electrical Engineering: L 22: T - P Nconference RequirementsОценок пока нет
- Planta de Trazo Y Replanteo: A B C DДокумент1 страницаPlanta de Trazo Y Replanteo: A B C DcleverОценок пока нет
- Prediction Case Study: Magnetic LevitationДокумент15 страницPrediction Case Study: Magnetic LevitationAlee LópezОценок пока нет
- Ch9 Presnedit PDFДокумент22 страницыCh9 Presnedit PDFAlee LópezОценок пока нет
- Supervised Hebbian LearningДокумент14 страницSupervised Hebbian LearningAlee LópezОценок пока нет
- Ch9 Presn PDFДокумент22 страницыCh9 Presn PDFAlee LópezОценок пока нет
- Pattern Recognition Case Study: EKG AnalysisДокумент14 страницPattern Recognition Case Study: EKG AnalysisAlee LópezОценок пока нет
- Clustering Forest Cover Types Using SOMДокумент10 страницClustering Forest Cover Types Using SOMAlee LópezОценок пока нет
- Widrow-Hoff Learning: (LMS Algorithm)Документ26 страницWidrow-Hoff Learning: (LMS Algorithm)Alee LópezОценок пока нет
- Ch6 Presn PDFДокумент24 страницыCh6 Presn PDFAlee LópezОценок пока нет
- Taylor Series Expansion for Performance SurfacesДокумент24 страницыTaylor Series Expansion for Performance SurfacesAlee LópezОценок пока нет
- LMS Algorithm ExplainedДокумент26 страницLMS Algorithm ExplainedAlee LópezОценок пока нет
- Ch21 Presn PDFДокумент30 страницCh21 Presn PDFAlee LópezОценок пока нет
- Ch20 Presn PDFДокумент21 страницаCh20 Presn PDFAlee LópezОценок пока нет
- Function Approximation Case Study: Smart SensorДокумент10 страницFunction Approximation Case Study: Smart SensorAlee LópezОценок пока нет
- Ch18 Presn PDFДокумент32 страницыCh18 Presn PDFAlee LópezОценок пока нет
- Ch14 Presn PDFДокумент47 страницCh14 Presn PDFAlee LópezОценок пока нет
- NNDesign PDFДокумент1 012 страницNNDesign PDFClemilton VasconcelosОценок пока нет
- Probability Estimation Case Study: Molecular DynamicsДокумент15 страницProbability Estimation Case Study: Molecular DynamicsAlee LópezОценок пока нет
- Ch13 Presn PDFДокумент47 страницCh13 Presn PDFAlee LópezОценок пока нет
- Practical Training Issues: Network Training Steps and Data PreprocessingДокумент34 страницыPractical Training Issues: Network Training Steps and Data PreprocessingAlee LópezОценок пока нет
- Ch19 Presn PDFДокумент30 страницCh19 Presn PDFAlee LópezОценок пока нет
- License Guitar Pro 5Документ3 страницыLicense Guitar Pro 5kaicuhchansenОценок пока нет
- Ch16 Presn PDFДокумент28 страницCh16 Presn PDFAlee LópezОценок пока нет
- Backpropagation Variations for Neural Network OptimizationДокумент31 страницаBackpropagation Variations for Neural Network OptimizationAlee LópezОценок пока нет
- Analysis of The Light J 3 Mesons in QCD Sum RulesДокумент11 страницAnalysis of The Light J 3 Mesons in QCD Sum Rulesubik59Оценок пока нет
- Grade 4Документ6 страницGrade 4Kimberly SalvadorОценок пока нет
- Power Electronics and Drives Laboratory ManualДокумент71 страницаPower Electronics and Drives Laboratory ManualSureshОценок пока нет
- Geosynthetic Institute: GRI Test Method GM19Документ12 страницGeosynthetic Institute: GRI Test Method GM19HeiderHuertaОценок пока нет
- Ed081p36 1Документ1 страницаEd081p36 1IHN SisОценок пока нет
- 22 - Muhammad Rifky Hasan - 172112238Документ4 страницы22 - Muhammad Rifky Hasan - 172112238Rifky hasanОценок пока нет
- D 4176Документ4 страницыD 4176Salma FarooqОценок пока нет
- Rabin CryptosystemДокумент41 страницаRabin CryptosystemArkadev GhoshОценок пока нет
- Lecture20 Drilled ShaftsДокумент57 страницLecture20 Drilled ShaftsAsia WardОценок пока нет
- Kathrein 80010761Документ2 страницыKathrein 80010761Sego Megono100% (1)
- Tda 2170Документ8 страницTda 2170ricdem11_42047Оценок пока нет
- EOR Screening Part 2 Taber-MartinДокумент7 страницEOR Screening Part 2 Taber-MartinPerwira HandhikoОценок пока нет
- GCSE Mini Test 4: Foundation Maths QuestionsДокумент2 страницыGCSE Mini Test 4: Foundation Maths QuestionsSuiatz (Suiatz)Оценок пока нет
- 6 W1 P 7 K FQ MlitДокумент309 страниц6 W1 P 7 K FQ MlitnicolaunmОценок пока нет
- ABB SR 60 Years of HVDC - 72dpi PDFДокумент72 страницыABB SR 60 Years of HVDC - 72dpi PDFroyclhorОценок пока нет
- Lesoon PHI 20188 Lesson NotesДокумент77 страницLesoon PHI 20188 Lesson NotesGlennОценок пока нет
- Ugima 4404 HMДокумент3 страницыUgima 4404 HMReginaldoОценок пока нет
- CFD Application Tutorials 2Документ35 страницCFD Application Tutorials 2Jubril AkinwandeОценок пока нет
- Effects of Geopathic Stress and VastuДокумент12 страницEffects of Geopathic Stress and VastuDeepak Singh RaghuvansheОценок пока нет
- Lesson 3-F5 PhysicsДокумент14 страницLesson 3-F5 PhysicsCheng WLОценок пока нет
- IR Drop PDFДокумент3 страницыIR Drop PDFarammartОценок пока нет
- Bdm100 User ManualДокумент36 страницBdm100 User Manualsimon_someone217Оценок пока нет
- Development of Xbloc Concrete Breakwater Armour Units Canada 2003Документ12 страницDevelopment of Xbloc Concrete Breakwater Armour Units Canada 2003r_anzarОценок пока нет
- TDS - Micro-Air 120Документ3 страницыTDS - Micro-Air 120aahtagoОценок пока нет
- Application of The Giroud - Han Design Method For Geosynthetic Reinforced Unpaved Roads With Tencate Mirafi GeosyntheticsДокумент7 страницApplication of The Giroud - Han Design Method For Geosynthetic Reinforced Unpaved Roads With Tencate Mirafi GeosyntheticsFaten Abou ShakraОценок пока нет
- Sample Calculus Problems: Single Variable FunctionsДокумент155 страницSample Calculus Problems: Single Variable Functionsmoustafa.mehanna7564Оценок пока нет
- Las 1-Earth Sci and LifeДокумент4 страницыLas 1-Earth Sci and LifeAlria CabugОценок пока нет
- 614460-Multi-Objective Material Selection For Wind Turbine Blade and Tower - Ashby's Approach - 10Документ12 страниц614460-Multi-Objective Material Selection For Wind Turbine Blade and Tower - Ashby's Approach - 10Erika Kawakami VasconcelosОценок пока нет
- Divine Particles Pressnote by Sanatan SansthaДокумент4 страницыDivine Particles Pressnote by Sanatan SansthaHaindava KeralamОценок пока нет