Вам также может понравиться
- Tables of The Legendre Functions P—½+it(x): Mathematical Tables SeriesОт EverandTables of The Legendre Functions P—½+it(x): Mathematical Tables SeriesОценок пока нет
- Mt129 Name IdДокумент16 страницMt129 Name IdEe BОценок пока нет
- Tabla de DerivadasДокумент4 страницыTabla de DerivadasLuisa Elena Ramírez GómezОценок пока нет
- Primer Taller Métodos OficialДокумент5 страницPrimer Taller Métodos OficialVALERIA AGUDELO ESCUDEROОценок пока нет
- Encuentre La Linealización L (X) de F (X) en A 0Документ1 страницаEncuentre La Linealización L (X) de F (X) en A 0lorena isabel Gonzalez bОценок пока нет
- Mat CeroДокумент17 страницMat CeroYuber CcoaОценок пока нет
- Taller #3 Calculo MultivariableДокумент8 страницTaller #3 Calculo MultivariableJose Robles MorenoОценок пока нет
- TYPE V - Intergrating Factor by FormulasДокумент3 страницыTYPE V - Intergrating Factor by FormulasKimberly BorjaОценок пока нет
- Formulaire de Derivation PDFДокумент1 страницаFormulaire de Derivation PDFAshraeОценок пока нет
- Tarea 5 Analisis MatematicoДокумент5 страницTarea 5 Analisis MatematicoMr TomОценок пока нет
- Applied CALC 2nd Edition Frank Wilson Solutions Manual 1Документ36 страницApplied CALC 2nd Edition Frank Wilson Solutions Manual 1eugenehallgqdcsamwtn100% (26)
- Applied CALC 2nd Edition Frank Wilson Solutions Manual 1Документ41 страницаApplied CALC 2nd Edition Frank Wilson Solutions Manual 1daisy100% (30)
- Applied Calc 2Nd Edition Frank Wilson Solutions Manual Full Chapter PDFДокумент36 страницApplied Calc 2Nd Edition Frank Wilson Solutions Manual Full Chapter PDFarthur.brown523100% (16)
- Integral Transforms Formula SheetДокумент2 страницыIntegral Transforms Formula SheetgrrrmoОценок пока нет
- Punto 1Документ7 страницPunto 1Luis JJCОценок пока нет
- DerivadasДокумент3 страницыDerivadaswwfcctkxkbОценок пока нет
- Mathematics: MTHE01P03Документ15 страницMathematics: MTHE01P03Mohamed FathyОценок пока нет
- Chapter 8: Performance Surfaces and Optimum Points: Brandon Morgan 1/15/2021Документ10 страницChapter 8: Performance Surfaces and Optimum Points: Brandon Morgan 1/15/2021samaneh keshavarziОценок пока нет
- Vector Calculus Colley 4th Edition Solutions ManualДокумент51 страницаVector Calculus Colley 4th Edition Solutions ManualSharonScottdizmr100% (52)
- Extra HW - Calculus - Chapter 2Документ3 страницыExtra HW - Calculus - Chapter 2siriОценок пока нет
- Taylor Series: DF (X) DX X AДокумент12 страницTaylor Series: DF (X) DX X ATayyip TahiroğluОценок пока нет
- Derivees E0003Документ3 страницыDerivees E0003foundoux242Оценок пока нет
- Homework 4 SolutionsДокумент5 страницHomework 4 SolutionsJhovanny AlexanderОценок пока нет
- Recognition Patterns: Jean Carlo Grandas Franco March 2020Документ9 страницRecognition Patterns: Jean Carlo Grandas Franco March 2020Jean Carlo GfОценок пока нет
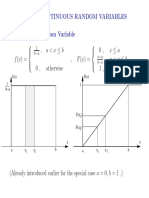
- Discrete Continuous: P X X F X X P XДокумент4 страницыDiscrete Continuous: P X X F X X P XKevin YauОценок пока нет
- Exercises and Answers To Chapter 1Документ35 страницExercises and Answers To Chapter 1norman camarenaОценок пока нет
- Chapter 5Документ20 страницChapter 5Sp MaxxОценок пока нет
- Worksheet IIДокумент1 страницаWorksheet IISagni LamessaОценок пока нет
- 45 An Algorithm For Curve SketchingДокумент4 страницы45 An Algorithm For Curve SketchingDan AvrukhОценок пока нет
- Math Exam Functions .Quadratic Equations - System.limits .DerivativesДокумент2 страницыMath Exam Functions .Quadratic Equations - System.limits .DerivativeswaelОценок пока нет
- Function ReviewWorksheetДокумент1 страницаFunction ReviewWorksheetJeevan MalsisariaОценок пока нет
- Seminar 1. Derivarea Funct Iilor Reale de o Variabil A Real A (Recapitulare)Документ5 страницSeminar 1. Derivarea Funct Iilor Reale de o Variabil A Real A (Recapitulare)Zvy MazelОценок пока нет
- Ex Análise Erick WeberДокумент4 страницыEx Análise Erick Webererickweber852Оценок пока нет
- 0surveying Chapter0 DerivativeДокумент10 страниц0surveying Chapter0 Derivativeqwertyuiop789qazwsxОценок пока нет
- Tabla de Derivadas: Elementales Cadena de FuncionesДокумент1 страницаTabla de Derivadas: Elementales Cadena de FuncionesmadremiademividaОценок пока нет
- Taylor SeriesДокумент9 страницTaylor SeriesAbdul Wasiq KhanОценок пока нет
- Function Review WorksheetДокумент2 страницыFunction Review WorksheetAnonymous g9tCvwОценок пока нет
- MR and RI Assigment - PESP2020.CHAIRIN GHILLANDA.4202421018Документ2 страницыMR and RI Assigment - PESP2020.CHAIRIN GHILLANDA.4202421018ChairinОценок пока нет
- Worksheet 3 SolutionsДокумент8 страницWorksheet 3 SolutionsXuze ChenОценок пока нет
- Linearization TheoriesДокумент174 страницыLinearization Theoriessafeer_siddickyОценок пока нет
- Cálculo de Límites y DerivadasДокумент1 страницаCálculo de Límites y DerivadasAlbaОценок пока нет
- وظيفة منزلية 1 دالة ناطقةДокумент1 страницаوظيفة منزلية 1 دالة ناطقةOuarezguia sofianeОценок пока нет
- MAFE208IU-L9 - Numerical DifferentiationДокумент24 страницыMAFE208IU-L9 - Numerical DifferentiationThy VũОценок пока нет
- Derivtion 1 Bac SM 2024Документ4 страницыDerivtion 1 Bac SM 2024Sonia SadekОценок пока нет
- EE/Ma 126b Information Theory - Homework Set #4Документ5 страницEE/Ma 126b Information Theory - Homework Set #4ArjunОценок пока нет
- Llistafuncions Figures c1 PlanouДокумент1 страницаLlistafuncions Figures c1 PlanoualberttauleraОценок пока нет
- Lecture 2Документ10 страницLecture 2Rohan GopeОценок пока нет
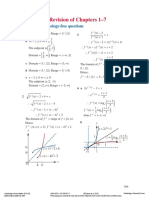
- Chapter 8 - Revision of Chapters 1-7: Solutions To Technology-Free QuestionsДокумент25 страницChapter 8 - Revision of Chapters 1-7: Solutions To Technology-Free QuestionsAnonymous 69Оценок пока нет
- DERIVATIVESДокумент12 страницDERIVATIVESmike capitoОценок пока нет
- Chapter 6. Power Flow (Load Flow) AnalysisДокумент38 страницChapter 6. Power Flow (Load Flow) AnalysisSerajОценок пока нет
- Graduate Macro Theory II: Notes On Log-Linearization: Eric Sims University of Notre Dame Spring 2011Документ5 страницGraduate Macro Theory II: Notes On Log-Linearization: Eric Sims University of Notre Dame Spring 2011Dynamix SolverОценок пока нет
- E1 251 Linear and Nonlinear Op2miza2on: Chapter 4: Convex and Quadra2c Func2onsДокумент35 страницE1 251 Linear and Nonlinear Op2miza2on: Chapter 4: Convex and Quadra2c Func2onsdata scienceОценок пока нет
- Assignment Functions 1Документ6 страницAssignment Functions 1Ishita Bharambe (Ish)Оценок пока нет
- UPSC Civil Services Main 1983 - Mathematics Calculus: Sunder LalДокумент7 страницUPSC Civil Services Main 1983 - Mathematics Calculus: Sunder Lalsayhigaurav07Оценок пока нет
- NM 2018111086 PDFДокумент32 страницыNM 2018111086 PDFrajaduraiОценок пока нет
- 6410Документ25 страниц6410Ruben Mark Salazar TocasОценок пока нет
- January 2022 ExamДокумент6 страницJanuary 2022 ExamjidsjijsdwdОценок пока нет
- Skiciranje Grafika Funkcije Zadaci Za VezbuДокумент1 страницаSkiciranje Grafika Funkcije Zadaci Za VezbuRanko VindzanovicОценок пока нет
- ModuloДокумент3 страницыModuloJerssie GonzálezОценок пока нет
- Revisão de Funções e ComposiçõesДокумент2 страницыRevisão de Funções e Composiçõesmarinaalmondes16Оценок пока нет
- Y625U - PCB Board Diagram PDFДокумент2 страницыY625U - PCB Board Diagram PDFAlee LópezОценок пока нет
- Supervised Hebbian LearningДокумент14 страницSupervised Hebbian LearningAlee LópezОценок пока нет
- Ch9 Presnedit PDFДокумент22 страницыCh9 Presnedit PDFAlee LópezОценок пока нет
- Prediction Case Study: Magnetic LevitationДокумент15 страницPrediction Case Study: Magnetic LevitationAlee LópezОценок пока нет
- Ch9 Presn PDFДокумент22 страницыCh9 Presn PDFAlee LópezОценок пока нет
- Clustering Case Study: Forest Cover TypesДокумент10 страницClustering Case Study: Forest Cover TypesAlee LópezОценок пока нет
- Widrow-Hoff Learning: (LMS Algorithm)Документ26 страницWidrow-Hoff Learning: (LMS Algorithm)Alee LópezОценок пока нет
- Ch14 Presn PDFДокумент47 страницCh14 Presn PDFAlee LópezОценок пока нет
- Ch6 Presn PDFДокумент24 страницыCh6 Presn PDFAlee LópezОценок пока нет
- Pattern Recognition Case Study: EKG AnalysisДокумент14 страницPattern Recognition Case Study: EKG AnalysisAlee LópezОценок пока нет
- Ch17 Presn PDFДокумент29 страницCh17 Presn PDFAlee LópezОценок пока нет
- Widrow-Hoff Learning: (LMS Algorithm)Документ26 страницWidrow-Hoff Learning: (LMS Algorithm)Alee LópezОценок пока нет
- Function Approximation Case Study: Smart SensorДокумент10 страницFunction Approximation Case Study: Smart SensorAlee LópezОценок пока нет
- Ch19 Presn PDFДокумент30 страницCh19 Presn PDFAlee LópezОценок пока нет
- Probability Estimation Case Study: Molecular DynamicsДокумент15 страницProbability Estimation Case Study: Molecular DynamicsAlee LópezОценок пока нет
- Ch12 Presn PDFДокумент31 страницаCh12 Presn PDFAlee LópezОценок пока нет
- Ch22 Presn PDFДокумент34 страницыCh22 Presn PDFAlee LópezОценок пока нет
- Ext Abstract BERCYANDYAДокумент8 страницExt Abstract BERCYANDYAvirtualqueen02Оценок пока нет
- Coneplot (20170407)Документ30 страницConeplot (20170407)LinggaОценок пока нет
- Dist Census Book Latur PDFДокумент770 страницDist Census Book Latur PDFMP100% (1)
- Audit Sampling (Chapter 9)Документ25 страницAudit Sampling (Chapter 9)cris100% (2)
- Motorola Pt4 - VHF - WWW - Manualesderadios.com - ArДокумент24 страницыMotorola Pt4 - VHF - WWW - Manualesderadios.com - Arpisy74Оценок пока нет
- Lesson Plan #4 - Electrostatic ForceДокумент4 страницыLesson Plan #4 - Electrostatic Forcedmart033100% (1)
- Json Out InvoiceДокумент2 страницыJson Out Invoicetkpatel529Оценок пока нет
- HPC Module 1Документ48 страницHPC Module 1firebazzОценок пока нет
- CPE-214 Computer-Aided Engineering Design - Lab - Manual - OBE - 2 PDFДокумент64 страницыCPE-214 Computer-Aided Engineering Design - Lab - Manual - OBE - 2 PDFHamza RaufОценок пока нет
- Quotes PsДокумент10 страницQuotes PsSrinivasan ParthasarathyОценок пока нет
- Unit-V 191eec303t LicДокумент80 страницUnit-V 191eec303t LicPonkarthika BОценок пока нет
- Dynamic Modelling of Gas TurbinesДокумент8 страницDynamic Modelling of Gas TurbinesdannyОценок пока нет
- CNC RoboticsДокумент17 страницCNC RoboticsKunal DuttОценок пока нет
- 040 X52-62-72 UNIC-flex V1Документ63 страницы040 X52-62-72 UNIC-flex V1Антон Сорока100% (2)
- Separation of Asphalt Into Four Fractions: Standard Test Methods ForДокумент7 страницSeparation of Asphalt Into Four Fractions: Standard Test Methods Foryulia100% (1)
- Rele A Gas BuchholtsДокумент18 страницRele A Gas BuchholtsMarco GiraldoОценок пока нет
- Beechcraft B200 POH - 05. Supplemental InfoДокумент8 страницBeechcraft B200 POH - 05. Supplemental InfoAgustinОценок пока нет
- 11+ CEM English and Verbal Reasoning PRACTICE PAPER 1Документ15 страниц11+ CEM English and Verbal Reasoning PRACTICE PAPER 1OlawaleОценок пока нет
- Lesson Plan in Mathematics Grade9Документ6 страницLesson Plan in Mathematics Grade9Abegail VillanuevaОценок пока нет
- LP40W LED Driver 2017Документ4 страницыLP40W LED Driver 2017Daniel MéndezОценок пока нет
- 1380 eДокумент6 страниц1380 ewisjaro01100% (3)
- Bird Et Al (2005)Документ11 страницBird Et Al (2005)Ewan MurrayОценок пока нет
- 2010 Ue CДокумент7 страниц2010 Ue CLau Sze WaОценок пока нет
- 4UIE - AB - Nov 23Документ2 страницы4UIE - AB - Nov 23aaaОценок пока нет
- Chapter 2 - Analysis of Steam Power Plant CycleДокумент61 страницаChapter 2 - Analysis of Steam Power Plant Cyclerrhoshack100% (1)
- Manual SomachineДокумент228 страницManual SomachineMauricio NaranjoОценок пока нет
- E-Rpms Portfolio (Design 3) - Depedclick-1Документ42 страницыE-Rpms Portfolio (Design 3) - Depedclick-1angeliОценок пока нет
- CV - Pinki Arindra P&GДокумент6 страницCV - Pinki Arindra P&GPinqi Arindra PutraОценок пока нет
- Python Cheat SheetДокумент11 страницPython Cheat SheetWasswa OpioОценок пока нет