Вам также может понравиться
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5782)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (890)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (265)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (344)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2219)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (119)
- What Is InterpolДокумент5 страницWhat Is InterpolJimmy Jr Comahig LapeОценок пока нет
- Chapter 4-Market EquilibriumДокумент24 страницыChapter 4-Market EquilibriumAiman Daniel100% (2)
- Servo LubesДокумент2 страницыServo LubesVignesh VickyОценок пока нет
- Vandergrift - Listening, Modern Theory & PracticeДокумент6 страницVandergrift - Listening, Modern Theory & PracticeKarolina CiОценок пока нет
- Newman News January 2017 EditionДокумент12 страницNewman News January 2017 EditionSonya MathesonОценок пока нет
- Service Manual: Applicable Models Model CodeДокумент39 страницService Manual: Applicable Models Model CodeAndres BicaОценок пока нет
- 9Документ2 страницы9هلال العمديОценок пока нет
- O Bio Summarize Notes For RevisionДокумент31 страницаO Bio Summarize Notes For RevisionAfifa AmerОценок пока нет
- SITXWHS001 Participate in Safe Work Practices - Training ManualДокумент82 страницыSITXWHS001 Participate in Safe Work Practices - Training ManualIsuru AbhimanОценок пока нет
- Assessment Nursing Diagnosis Scientific Rationale Planning Intervention Rationale EvaluationДокумент9 страницAssessment Nursing Diagnosis Scientific Rationale Planning Intervention Rationale Evaluationclydell joyce masiarОценок пока нет
- Responsibility Matrix D&B Rev 3 22 - Sep - 2014Документ10 страницResponsibility Matrix D&B Rev 3 22 - Sep - 2014hatemsharkОценок пока нет
- Bank 12Документ19 страницBank 12Shivangi GuptaОценок пока нет
- Alpacon Degreaser BIO GENДокумент2 страницыAlpacon Degreaser BIO GENFahmi Ali100% (1)
- The Muscle and Strength Training Pyramid v2.0 Training by Eric Helms-9Документ31 страницаThe Muscle and Strength Training Pyramid v2.0 Training by Eric Helms-9Hamada MansourОценок пока нет
- Monster c4 Thread Text - Edited (Way Long) Version2 - Ford Muscle Cars Tech ForumДокумент19 страницMonster c4 Thread Text - Edited (Way Long) Version2 - Ford Muscle Cars Tech Forumjohn larsonОценок пока нет
- CeramicsДокумент39 страницCeramicsD4-dc1 Kelas100% (1)
- GI Tags Complete ListДокумент17 страницGI Tags Complete Listrameshb87Оценок пока нет
- Art of Editing PDFДокумент8 страницArt of Editing PDFpremОценок пока нет
- Fundamental Powers of The State (Police Power) Ynot v. IAC Facts: Ermita Malate v. City of Manila 20 SCRA 849 (1967)Документ18 страницFundamental Powers of The State (Police Power) Ynot v. IAC Facts: Ermita Malate v. City of Manila 20 SCRA 849 (1967)Ella QuiОценок пока нет
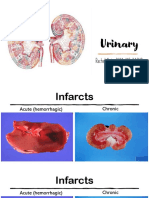
- Urinary: Rachel Neto, DVM, MS, DACVP May 28 2020Документ15 страницUrinary: Rachel Neto, DVM, MS, DACVP May 28 2020Rachel AutranОценок пока нет
- Module 3 FP Client AssessmentДокумент54 страницыModule 3 FP Client AssessmentJhunna TalanganОценок пока нет
- Admission Form BA BSC Composite PDFДокумент6 страницAdmission Form BA BSC Composite PDFKhurram ShahzadОценок пока нет
- Speeduino Manual-7Документ16 страницSpeeduino Manual-7Makson VieiraОценок пока нет
- CamScanner Scanned PDF DocumentДокумент205 страницCamScanner Scanned PDF DocumentNabila Tsuroya BasyaОценок пока нет
- VNL-Essar Field Trial: Nairobi-KenyaДокумент13 страницVNL-Essar Field Trial: Nairobi-Kenyapoppy tooОценок пока нет
- English Assignment AnswersДокумент4 страницыEnglish Assignment AnswersAfidaОценок пока нет
- Cambridge O Level: Agriculture 5038/12 October/November 2020Документ30 страницCambridge O Level: Agriculture 5038/12 October/November 2020Sraboni ChowdhuryОценок пока нет
- Ye Zindagi Aur Mujhe Fanaa KardeДокумент9 страницYe Zindagi Aur Mujhe Fanaa Kardeankur9359saxenaОценок пока нет
- Dialysis PowerpointДокумент10 страницDialysis Powerpointapi-266328774Оценок пока нет