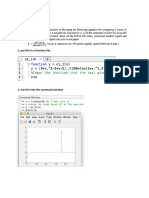
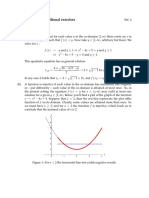
Вам также может понравиться
- Quadratic Equations MethodsДокумент29 страницQuadratic Equations MethodsPaula FanaОценок пока нет
- SQL TutorialДокумент182 страницыSQL Tutorialfera susantiОценок пока нет
- Solutions to selected exercises from Jehle and Reny (2001): Advanced Microeconomic TheoryДокумент38 страницSolutions to selected exercises from Jehle and Reny (2001): Advanced Microeconomic TheorySyed Yusuf Saadat100% (7)
- Solution Exercises 2011 PartIДокумент27 страницSolution Exercises 2011 PartIcecch001100% (1)
- Trigonometric Ratios to Transformations (Trigonometry) Mathematics E-Book For Public ExamsОт EverandTrigonometric Ratios to Transformations (Trigonometry) Mathematics E-Book For Public ExamsРейтинг: 5 из 5 звезд5/5 (1)
- Introduction To Management ScienceДокумент30 страницIntroduction To Management ScienceVenice Marie Arroyo100% (1)
- Math 221 Solution To ProblemsДокумент16 страницMath 221 Solution To ProblemsRyan Kristoffer NuñezОценок пока нет
- Mathematics 1St First Order Linear Differential Equations 2Nd Second Order Linear Differential Equations Laplace Fourier Bessel MathematicsОт EverandMathematics 1St First Order Linear Differential Equations 2Nd Second Order Linear Differential Equations Laplace Fourier Bessel MathematicsОценок пока нет
- Non Linear Programming ProblemsДокумент66 страницNon Linear Programming Problemsbits_who_am_iОценок пока нет
- Metodo Simple X Ejemplo MotocicletasДокумент42 страницыMetodo Simple X Ejemplo MotocicletasPedro Jesus Yac RobleroОценок пока нет
- Mathematics TДокумент62 страницыMathematics TRosdy Dyingdemon100% (1)
- Ode Q&aДокумент12 страницOde Q&aJohnОценок пока нет
- Project 1Документ13 страницProject 1sunjeevОценок пока нет
- Introduction To Management Science Quantitative Approaches To Decision Making 14th Edition Anderson Solutions ManualДокумент26 страницIntroduction To Management Science Quantitative Approaches To Decision Making 14th Edition Anderson Solutions ManualTraciLewispwng100% (62)
- Computation of KKT PointsДокумент2 страницыComputation of KKT Pointsarash501Оценок пока нет
- m820 Sol 2011Документ234 страницыm820 Sol 2011Tom DavisОценок пока нет
- Final Practice SolДокумент11 страницFinal Practice SolChris MoodyОценок пока нет
- 12 International Mathematics Competition For University StudentsДокумент4 страницы12 International Mathematics Competition For University StudentsMuhammad Al KahfiОценок пока нет
- Classical Optimization Theory Quadratic Forms: Let Be A N-VectorДокумент48 страницClassical Optimization Theory Quadratic Forms: Let Be A N-VectorAngad SehdevОценок пока нет
- Problem Set 10Документ2 страницыProblem Set 10phani saiОценок пока нет
- Practice Questions - 1 PDFДокумент5 страницPractice Questions - 1 PDFJunaidZafarОценок пока нет
- Difference Calculus and Generating Functions. Santos, D. A. 2005Документ34 страницыDifference Calculus and Generating Functions. Santos, D. A. 2005José Daniel Rivera Medina100% (1)
- Optimality Conditions and Optimization AlgorithmsДокумент6 страницOptimality Conditions and Optimization AlgorithmscarolinarvsocnОценок пока нет
- Microeconomie Livre Micro de Jehly SolutionnaireДокумент33 страницыMicroeconomie Livre Micro de Jehly Solutionnaireramcesse89Оценок пока нет
- Math 432 HW SolutionsДокумент6 страницMath 432 HW SolutionsArini MelanieОценок пока нет
- Handout Counting PrincipleДокумент4 страницыHandout Counting Principleabhi231594Оценок пока нет
- Hu2010 Article IterationCalculationsOfPeriodiДокумент6 страницHu2010 Article IterationCalculationsOfPeriodiIdris anderson Dzeugoua DjibouengОценок пока нет
- MATHEMATICS FOR MICROECONOMICS SOLUTIONSДокумент8 страницMATHEMATICS FOR MICROECONOMICS SOLUTIONSAsia ButtОценок пока нет
- ELLIPTIC EQUATION SOLVERДокумент11 страницELLIPTIC EQUATION SOLVERApurba barmanОценок пока нет
- Numerical Methods Test 1Документ17 страницNumerical Methods Test 1Ashley StraubОценок пока нет
- Assignment 2Документ2 страницыAssignment 2Lokesh Kumar GuptaОценок пока нет
- 2013 Ui Mock Putnam Exam September 25, 2013, 5 PM - 7 PM SolutionsДокумент4 страницы2013 Ui Mock Putnam Exam September 25, 2013, 5 PM - 7 PM SolutionsGag PafОценок пока нет
- 07 Method of Variation of ParametersДокумент37 страниц07 Method of Variation of Parameterstinkug163Оценок пока нет
- Lagrange MultiplierДокумент5 страницLagrange MultiplierAdantey MichaelОценок пока нет
- OR6205 M9 Practice Exam 2Документ5 страницOR6205 M9 Practice Exam 2Mohan BollaОценок пока нет
- Chapter 1 SolutionДокумент5 страницChapter 1 SolutionFaraa BellaОценок пока нет
- Sol 9 Fall 04Документ8 страницSol 9 Fall 04Daniel Cervantes CabreraОценок пока нет
- MAT Paper 2010 SolutionsДокумент8 страницMAT Paper 2010 SolutionsXu SarahОценок пока нет
- MAS 201 Spring 2021 (CD) Chapter 3 Higher-Order Differential EquationsДокумент23 страницыMAS 201 Spring 2021 (CD) Chapter 3 Higher-Order Differential EquationsBlue horseОценок пока нет
- Tutorial 1Документ15 страницTutorial 1situvnnОценок пока нет
- Calculus Exercises 2 SolutionsДокумент7 страницCalculus Exercises 2 SolutionsHenkОценок пока нет
- MATH20602 - 2014 exam questionsДокумент15 страницMATH20602 - 2014 exam questionsMuhammad KamranОценок пока нет
- Basis Math1 Sol PDFДокумент84 страницыBasis Math1 Sol PDFPieter RubensОценок пока нет
- Practice Exam3 21b SolДокумент6 страницPractice Exam3 21b SolUmer Iftikhar AhmedОценок пока нет
- Tutorial For MathsДокумент15 страницTutorial For Mathsmukesh3021Оценок пока нет
- Solutions of Final Exam: Prof Abu and DR AzeddineДокумент9 страницSolutions of Final Exam: Prof Abu and DR AzeddineGharib MahmoudОценок пока нет
- Saddle Points and Second Derivative TestДокумент16 страницSaddle Points and Second Derivative TestShubham TejuОценок пока нет
- We Have Next ProblemДокумент5 страницWe Have Next ProblemKateryna TernovaОценок пока нет
- Quadratic Eq. Class 9th Icse ML AggarwalДокумент5 страницQuadratic Eq. Class 9th Icse ML Aggarwalaaravchoudhary8102009Оценок пока нет
- Math 105 Practice Exam 3 SolutionsДокумент3 страницыMath 105 Practice Exam 3 SolutionsexamkillerОценок пока нет
- 7.1 Introduction of Optimal Economic Dispatch of GenerationДокумент36 страниц7.1 Introduction of Optimal Economic Dispatch of GenerationSwathi PrasadОценок пока нет
- Solutions To Chapter 12 MP Review ProblemsДокумент7 страницSolutions To Chapter 12 MP Review ProblemsAmar MokhaОценок пока нет
- Jan98 MA1002 CalculusДокумент6 страницJan98 MA1002 CalculusZama MakhathiniОценок пока нет
- Hw1 2 SolutionsДокумент7 страницHw1 2 SolutionsFrancisco AlvesОценок пока нет
- Quardatic Equation-02-Solved ExamДокумент14 страницQuardatic Equation-02-Solved ExamRaju SinghОценок пока нет
- Algebra: Complete The Square For ExpressionsДокумент5 страницAlgebra: Complete The Square For ExpressionsTuyếnĐặngОценок пока нет
- Lagrange Multipliers BasicsДокумент7 страницLagrange Multipliers BasicsVictor AlvesОценок пока нет
- Special FunctionsДокумент39 страницSpecial FunctionsAakash NairОценок пока нет
- SOLUTIONS TO DIFFERENTIAL EQUATIONSДокумент9 страницSOLUTIONS TO DIFFERENTIAL EQUATIONSDaniel Cervantes CabreraОценок пока нет
- Seminar Serii de PuteriДокумент6 страницSeminar Serii de PuteriDaniel C.Оценок пока нет
- Mathematics 307 Final ExamДокумент5 страницMathematics 307 Final ExamAhmadОценок пока нет
- Final ReportДокумент97 страницFinal ReportAnonymous qf0zYAP5UH100% (2)
- A Hybrid Trust Evaluation Framework For E-Commerce in Online Social Network: A Factor Enrichment PerspectiveДокумент17 страницA Hybrid Trust Evaluation Framework For E-Commerce in Online Social Network: A Factor Enrichment PerspectiveajithОценок пока нет
- Vaishnavbenitas 1Документ3 страницыVaishnavbenitas 1ajithОценок пока нет
- 2017-18 Big Data TitlesДокумент6 страниц2017-18 Big Data TitlesajithОценок пока нет
- New Text DocumentДокумент1 страницаNew Text DocumentajithОценок пока нет
- Unit 3 CFДокумент24 страницыUnit 3 CFajithОценок пока нет
- Minimum-Cost Cloud Storage Service Across Multiple Cloud ProvidersДокумент10 страницMinimum-Cost Cloud Storage Service Across Multiple Cloud ProvidersajithОценок пока нет
- Min Max Sum AlgorithmДокумент1 страницаMin Max Sum AlgorithmajithОценок пока нет
- IBReg FormДокумент1 страницаIBReg FormAbhishek KoliОценок пока нет
- New Text DocumentДокумент1 страницаNew Text DocumentajithОценок пока нет
- CS6702-Graph Theory and ApplicationsДокумент22 страницыCS6702-Graph Theory and ApplicationsajithОценок пока нет
- Sbi PDFДокумент10 страницSbi PDFdisewazoОценок пока нет
- Java Ieee Projects 2017Документ8 страницJava Ieee Projects 2017ajithОценок пока нет
- CS6704 UwДокумент94 страницыCS6704 UwajithОценок пока нет
- #DataVault, Irc Warez (Ty 4 Moving X)Документ2 страницы#DataVault, Irc Warez (Ty 4 Moving X)Ko ChoОценок пока нет
- Min Max Sum AlgorithmДокумент1 страницаMin Max Sum AlgorithmajithОценок пока нет
- Hacker RanlДокумент1 страницаHacker RanlajithОценок пока нет
- New Text DocumentДокумент1 страницаNew Text DocumentajithОценок пока нет
- UPSC Civil Services Notification 2017 - Out!!Документ92 страницыUPSC Civil Services Notification 2017 - Out!!nidhi tripathiОценок пока нет
- Vaishnavbenitas 1Документ3 страницыVaishnavbenitas 1ajithОценок пока нет
- Q. 1 - Q. 5 Carry One Mark EachДокумент2 страницыQ. 1 - Q. 5 Carry One Mark EachajithОценок пока нет
- Hacker RankДокумент1 страницаHacker RankajithОценок пока нет
- Linear Programming: Mcgraw-Hill/IrwinДокумент20 страницLinear Programming: Mcgraw-Hill/IrwinSagar MurtyОценок пока нет
- Management Science PDFДокумент131 страницаManagement Science PDFAngela Lei SanJuan BucadОценок пока нет
- CHEM-E7155 Production Planning and Control: Exercise 1 Simplex MethodДокумент19 страницCHEM-E7155 Production Planning and Control: Exercise 1 Simplex MethodgabboudehОценок пока нет
- Maximum Flow: Max-Flow Min-Cut Theorem (Ford Fukerson's Algorithm)Документ33 страницыMaximum Flow: Max-Flow Min-Cut Theorem (Ford Fukerson's Algorithm)MrkvicaTikvićОценок пока нет
- Longest Path DAG Dynamic ProgrammingДокумент4 страницыLongest Path DAG Dynamic ProgrammingFibo LaОценок пока нет
- Chap 2 MindTapДокумент9 страницChap 2 MindTapAdrian NgОценок пока нет
- Effect of "Operations Research" in Science and Industry: I J C R BДокумент7 страницEffect of "Operations Research" in Science and Industry: I J C R BLydia Rejas Villanueva TomadaОценок пока нет
- 01 2.1 Clustering CoefficientДокумент16 страниц01 2.1 Clustering CoefficientdeniceОценок пока нет
- Module 1 - Introduction To orДокумент26 страницModule 1 - Introduction To orsrk bhaiОценок пока нет
- Operations Research Paper SampleДокумент8 страницOperations Research Paper SampleAngelicaBernardoОценок пока нет
- Ford-Fulkerson AlgorithmДокумент6 страницFord-Fulkerson Algorithmテラン みさおОценок пока нет
- ECON3202 Mathematical Economics Assignment SolutionsДокумент5 страницECON3202 Mathematical Economics Assignment Solutionsyizzy0% (1)
- Buy Now To Create PDF Without Trial Watermark!!: Linear Program - Original Data Linear Program - Original DataДокумент3 страницыBuy Now To Create PDF Without Trial Watermark!!: Linear Program - Original Data Linear Program - Original DataTato FloresОценок пока нет
- OD7 PL Integer ProgrammingДокумент6 страницOD7 PL Integer ProgrammingcarolinarvsocnОценок пока нет
- CPU SchedulingДокумент10 страницCPU Schedulingemmanuel AumsuriОценок пока нет
- Dijkstra's AlgorithmДокумент16 страницDijkstra's AlgorithmAndrei NecuţăОценок пока нет
- f22 hw7 SolДокумент12 страницf22 hw7 SolPeter RosenbergОценок пока нет
- JCL Mainframebrasil PDFДокумент165 страницJCL Mainframebrasil PDFRicardo Azeredo FeitosaОценок пока нет
- SpreadsheetModeling 5e PPT Chap02Документ36 страницSpreadsheetModeling 5e PPT Chap02Ronald KahoraОценок пока нет
- Individual Assignment #1 - Network Diagram ExerciseДокумент8 страницIndividual Assignment #1 - Network Diagram ExerciseveenajkumarОценок пока нет
- OR-Notes: J E BeasleyДокумент11 страницOR-Notes: J E BeasleyVilas GhorbandОценок пока нет
- Assignment and Transportation ProblrmДокумент20 страницAssignment and Transportation ProblrmHarish SrinivasОценок пока нет
- FordДокумент5 страницFordsharadacgОценок пока нет
- OM Introduction Productivity MeasurementДокумент30 страницOM Introduction Productivity MeasurementSinem Dilara HaşimoğluОценок пока нет
- Introduction To Operations Research: N Onur BakırДокумент9 страницIntroduction To Operations Research: N Onur Bakırmhmd2222Оценок пока нет
- VIKOR MethodДокумент3 страницыVIKOR MethodChiah YingОценок пока нет
- Linear Programming Simplex Method GuideДокумент39 страницLinear Programming Simplex Method GuideDimas PrasetyoОценок пока нет