Вам также может понравиться
- Witchcraft, Population Catastrophe and Economic Crisis in Renaissance Europe - An Alternative Macroeconomic ExplanationДокумент38 страницWitchcraft, Population Catastrophe and Economic Crisis in Renaissance Europe - An Alternative Macroeconomic Explanationthewolf37100% (1)
- Review Questions & Answers For Midterm1: BA 203 - Financial Accounting Fall 2019-2020Документ11 страницReview Questions & Answers For Midterm1: BA 203 - Financial Accounting Fall 2019-2020Ulaş GüllenoğluОценок пока нет
- Recent Developments in The Study of The Great European Witch HuntДокумент10 страницRecent Developments in The Study of The Great European Witch HuntChristineОценок пока нет
- (Adolescence and Education) Tim Urdan, Frank Pajares - Academic Motivation of Adolescents-IAP - Information Age Publishing (2004) PDFДокумент384 страницы(Adolescence and Education) Tim Urdan, Frank Pajares - Academic Motivation of Adolescents-IAP - Information Age Publishing (2004) PDFAllenОценок пока нет
- Dumont's Theory of Caste.Документ4 страницыDumont's Theory of Caste.Vikram Viner50% (2)
- A Brief History of StatisticsДокумент60 страницA Brief History of StatisticsDM267% (3)
- Brief History of StatisticsДокумент60 страницBrief History of StatisticsJeremiah MagcalasОценок пока нет
- Probability and StatisticsДокумент4 страницыProbability and StatisticsKeppy AricangoyОценок пока нет
- StatisticiansДокумент4 страницыStatisticiansKhamis TugbangОценок пока нет
- History of StatisticsДокумент1 страницаHistory of StatisticsRenz A. PagulayanОценок пока нет
- Module 1: Nature of StatisticsДокумент47 страницModule 1: Nature of StatisticsHannahbea LindoОценок пока нет
- Module 1: Nature of StatisticsДокумент47 страницModule 1: Nature of StatisticsHannah Bea LindoОценок пока нет
- Module 1: Nature of StatisticsДокумент29 страницModule 1: Nature of StatisticsHannahbea LindoОценок пока нет
- The History of StatisticsДокумент4 страницыThe History of StatisticsVenn Edward NicolasОценок пока нет
- The History of StatisticsДокумент4 страницыThe History of StatisticsVenn Edward NicolasОценок пока нет
- Handout#1 - Stat History - Terms - ExerciseДокумент5 страницHandout#1 - Stat History - Terms - ExerciseEn CyОценок пока нет
- Descriptive Statistics: Part OneДокумент10 страницDescriptive Statistics: Part OnearmihiskiaОценок пока нет
- STAT-APP-1 (1) - Converted-MergedДокумент60 страницSTAT-APP-1 (1) - Converted-MergedHannah Bea LindoОценок пока нет
- History of StatisticsДокумент2 страницыHistory of StatisticsAlexandre BritoОценок пока нет
- Additional StatДокумент5 страницAdditional StatKalei ReyesОценок пока нет
- EoB heathStatisticsHistoryДокумент7 страницEoB heathStatisticsHistorySanusi IsahОценок пока нет
- Calupig, Jessell H. Grade 11-STEM - A: History of StatisticsДокумент7 страницCalupig, Jessell H. Grade 11-STEM - A: History of StatisticspatrickОценок пока нет
- Timeline of StatisticsДокумент1 страницаTimeline of StatisticsudОценок пока нет
- ProbabilityДокумент4 страницыProbabilitysarjanreddyОценок пока нет
- Asian Development College Foundation Tacloban CityДокумент2 страницыAsian Development College Foundation Tacloban CityCaren FontijonОценок пока нет
- History of StatisticsДокумент4 страницыHistory of StatisticsZelline Picadizo100% (3)
- Sir William Petty FRSДокумент2 страницыSir William Petty FRSLee TingОценок пока нет
- Brief History of StatisticsДокумент20 страницBrief History of Statisticssheena bertolanoОценок пока нет
- History and Development of StatisticsДокумент4 страницыHistory and Development of Statisticsjosedenniolim96% (27)
- History Part15Документ7 страницHistory Part15Jane SatherОценок пока нет
- 35466489-Course SyllabusДокумент5 страниц35466489-Course SyllabusMia De GuzmanОценок пока нет
- Global Warming - Marshall SmithДокумент28 страницGlobal Warming - Marshall SmithIonut Dobrinescu100% (1)
- English Dictionary: I Should Like To Thank James E. Force For His Helpful Discussions and Comments On This PaperДокумент2 страницыEnglish Dictionary: I Should Like To Thank James E. Force For His Helpful Discussions and Comments On This PaperTanishq TayalОценок пока нет
- Meaning, Scope and Types of StatisticsДокумент21 страницаMeaning, Scope and Types of StatisticsPrakharMishraОценок пока нет
- Ilovepdf MergedДокумент32 страницыIlovepdf MergedLe Dinno SávioОценок пока нет
- The 5 Most Influential Data Visualizations of All Time PDFДокумент17 страницThe 5 Most Influential Data Visualizations of All Time PDFydesugariОценок пока нет
- IMG EnlightenmentДокумент6 страницIMG EnlightenmentIrene GirtonОценок пока нет
- John GrauntДокумент4 страницыJohn Grauntanik_kurpОценок пока нет
- Research Proposal FinalДокумент16 страницResearch Proposal Finalapi-246627753Оценок пока нет
- 2 Eliz EnglandsДокумент8 страниц2 Eliz EnglandsAstelle R. LevantОценок пока нет
- Epidemiology BioДокумент9 страницEpidemiology Bioiandnvn96Оценок пока нет
- Exercise 1Документ6 страницExercise 1Kirstian Aldin NgalotОценок пока нет
- Astrological Forecasting and The TurkishДокумент16 страницAstrological Forecasting and The TurkishJeff ChapmanОценок пока нет
- To 1200 - Beginnings:: 17364015 Against The GodsДокумент5 страницTo 1200 - Beginnings:: 17364015 Against The GodsArpita Mouli MustafiОценок пока нет
- Moran HistoriographyofIntelinUK 7 June2011Документ24 страницыMoran HistoriographyofIntelinUK 7 June2011Mihai GhitulescuОценок пока нет
- Selangor 2 Ans WMДокумент17 страницSelangor 2 Ans WMBryan WongОценок пока нет
- Deciphering Cryptographic Messages, Containing Detailed Discussions On Statistics. (1) ItДокумент4 страницыDeciphering Cryptographic Messages, Containing Detailed Discussions On Statistics. (1) ItPoi Mei CincoОценок пока нет
- Azul y Verde Llamativo y Vívido Progreso de Proyecto Línea de Tiempo InfografíaДокумент2 страницыAzul y Verde Llamativo y Vívido Progreso de Proyecto Línea de Tiempo Infografíadanna belloОценок пока нет
- Neil Duxbury The Challenge of FormalismДокумент14 страницNeil Duxbury The Challenge of FormalismstrlawОценок пока нет
- KELLER. Accounting For InventionДокумент24 страницыKELLER. Accounting For InventionpilarywОценок пока нет
- History of StatisticsДокумент40 страницHistory of StatisticsDarry Jurilla PortesОценок пока нет
- Supplement To "Natu1 E," December 5, 1931: History of DemographyДокумент1 страницаSupplement To "Natu1 E," December 5, 1931: History of DemographyYuukii ChiiОценок пока нет
- Saavedra DISS Activity2Документ10 страницSaavedra DISS Activity2Danielle SaavedraОценок пока нет
- Thesis Statement For Spanish InfluenzaДокумент5 страницThesis Statement For Spanish Influenzasheritorizsaltlakecity100% (1)
- From the Flood to the Reign of George Iii: Developmental History and the Scottish EnlightenmentОт EverandFrom the Flood to the Reign of George Iii: Developmental History and the Scottish EnlightenmentОценок пока нет
- Futures Volume 7 Issue 3 1975 (Doi 10.1016/0016-3287 (75) 90068-3) I.F. Clarke - 7. The Calculus of Probabilities, 1870-1914Документ6 страницFutures Volume 7 Issue 3 1975 (Doi 10.1016/0016-3287 (75) 90068-3) I.F. Clarke - 7. The Calculus of Probabilities, 1870-1914Manticora VenerabilisОценок пока нет
- Stat ManualДокумент18 страницStat ManualemilynОценок пока нет
- Crisis A5 8th ChapterДокумент6 страницCrisis A5 8th Chapter3adrianОценок пока нет
- History of Political Thought December 3 The Scientific RevolutionДокумент2 страницыHistory of Political Thought December 3 The Scientific Revolutionapi-19497174Оценок пока нет
- Improving Downstream Processes To Recover Tartaric AcidДокумент10 страницImproving Downstream Processes To Recover Tartaric AcidFabio CastellanosОценок пока нет
- Positive Accounting TheoryДокумент47 страницPositive Accounting TheoryAshraf Uz ZamanОценок пока нет
- Post Cold WarДокумент70 страницPost Cold WarZainab WaqarОценок пока нет
- Cover Letter For Lettings Negotiator JobДокумент9 страницCover Letter For Lettings Negotiator Jobsun1g0gujyp2100% (1)
- MOM-II Lec 9 Unsymmetrical BendingДокумент27 страницMOM-II Lec 9 Unsymmetrical BendingNashit AhmedОценок пока нет
- End of Semester Student SurveyДокумент2 страницыEnd of Semester Student SurveyJoaquinОценок пока нет
- Georgia Jean Weckler 070217Документ223 страницыGeorgia Jean Weckler 070217api-290747380Оценок пока нет
- German Lesson 1Документ7 страницGerman Lesson 1itsme_ayuuОценок пока нет
- Panlilio vs. Regional Trial Court, Branch 51, City of ManilaДокумент10 страницPanlilio vs. Regional Trial Court, Branch 51, City of ManilaMaria Nicole VaneeteeОценок пока нет
- Kolehiyo NG Lungsod NG Lipa: College of Teacher EducationДокумент3 страницыKolehiyo NG Lungsod NG Lipa: College of Teacher EducationPrincess LopezОценок пока нет
- BCG-How To Address HR Challenges in Recession PDFДокумент16 страницBCG-How To Address HR Challenges in Recession PDFAnkit SinghalОценок пока нет
- UXBenchmarking 101Документ42 страницыUXBenchmarking 101Rodrigo BucketbranchОценок пока нет
- Oral Oncology: Jingyi Liu, Yixiang DuanДокумент9 страницOral Oncology: Jingyi Liu, Yixiang DuanSabiran GibranОценок пока нет
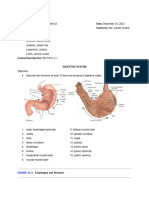
- Digestive System LabsheetДокумент4 страницыDigestive System LabsheetKATHLEEN MAE HERMOОценок пока нет
- Qafqaz UniversityДокумент3 страницыQafqaz UniversityQafqazlife QUОценок пока нет
- HDFC Bank-Centurion Bank of Punjab: Presented By: Sachi Bani Perhar Mba-Ib 2010-2012Документ40 страницHDFC Bank-Centurion Bank of Punjab: Presented By: Sachi Bani Perhar Mba-Ib 2010-2012Sumit MalikОценок пока нет
- Barangay AppointmentДокумент2 страницыBarangay AppointmentArlyn Gumahad CahanapОценок пока нет
- Is Electronic Writing or Document and Data Messages Legally Recognized? Discuss The Parameters/framework of The LawДокумент6 страницIs Electronic Writing or Document and Data Messages Legally Recognized? Discuss The Parameters/framework of The LawChess NutsОценок пока нет
- Introduction To Emerging TechnologiesДокумент145 страницIntroduction To Emerging TechnologiesKirubel KefyalewОценок пока нет
- Kozier Erbs Fundamentals of Nursing 8E Berman TBДокумент4 страницыKozier Erbs Fundamentals of Nursing 8E Berman TBdanie_pojОценок пока нет
- Boot CommandДокумент40 страницBoot CommandJimmywang 王修德Оценок пока нет
- National Rural Employment Guarantee Act, 2005Документ17 страницNational Rural Employment Guarantee Act, 2005praharshithaОценок пока нет
- Slides 99 Netslicing Georg Mayer 3gpp Network Slicing 04Документ13 страницSlides 99 Netslicing Georg Mayer 3gpp Network Slicing 04malli gaduОценок пока нет
- 1 Piling LaranganДокумент3 страницы1 Piling LaranganHannie Jane Salazar HerreraОценок пока нет
- Seangio Vs ReyesДокумент2 страницыSeangio Vs Reyespja_14Оценок пока нет
- PS4 ListДокумент67 страницPS4 ListAnonymous yNw1VyHОценок пока нет
- Jewish Standard, September 16, 2016Документ72 страницыJewish Standard, September 16, 2016New Jersey Jewish StandardОценок пока нет