Вам также может понравиться
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (344)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (121)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- Dubealex - 'S RGSS and Ruby TutorialДокумент67 страницDubealex - 'S RGSS and Ruby TutorialMatahari Bhakti 'dida' NendyaОценок пока нет
- Calling An Oracle Stored Proc in JasperДокумент10 страницCalling An Oracle Stored Proc in Jasperlorenzofranchi6371Оценок пока нет
- Best Practice For B2B ExpresswayДокумент124 страницыBest Practice For B2B Expresswaykepke86Оценок пока нет
- 17 Siebel Business ComponentsДокумент18 страниц17 Siebel Business ComponentsJayaRam KothaОценок пока нет
- D80194GC11 sg1Документ310 страницD80194GC11 sg1hilordОценок пока нет
- Ghost Software) - Wikipedi....Документ9 страницGhost Software) - Wikipedi....cassescouilleОценок пока нет
- Designing and Implementing HP SAN Storage Solution: How To Design A Networked StorageДокумент13 страницDesigning and Implementing HP SAN Storage Solution: How To Design A Networked Storagecaje_mac6960Оценок пока нет
- A Report On Introduction To Computer SystemsДокумент6 страницA Report On Introduction To Computer Systemschaulagainajeet50% (4)
- C++ Proposed Exercises (Chapter 9: The C++ Programing Language, Fourth Edition)Документ2 страницыC++ Proposed Exercises (Chapter 9: The C++ Programing Language, Fourth Edition)Mauricio Bedoya100% (1)
- PIC24F Family Reference ManualДокумент16 страницPIC24F Family Reference ManualMirna ValenciaОценок пока нет
- Samsung Interview ExpДокумент18 страницSamsung Interview ExpMohit SinghОценок пока нет
- Tes MikrotikДокумент6 страницTes MikrotikMuhammad YogiОценок пока нет
- TSE - VGA Final Project Report - Using Arduino and GameduinoДокумент65 страницTSE - VGA Final Project Report - Using Arduino and GameduinoZahidur Ovi RahmanОценок пока нет
- Arquitectura Popular Dominicana by Banco Popular Dominicano PDFДокумент672 страницыArquitectura Popular Dominicana by Banco Popular Dominicano PDFErika LombertОценок пока нет
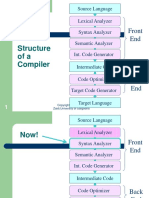
- Structure Ofa Compiler: Front EndДокумент95 страницStructure Ofa Compiler: Front EndHassan AliОценок пока нет
- Online Tailoring Management System PDFДокумент51 страницаOnline Tailoring Management System PDFFareeha AslamОценок пока нет
- ReadmeV8 0 enДокумент7 страницReadmeV8 0 enDonald Santana BautistaОценок пока нет
- FY100 FY101 FY400 FY600 FY700 FY800 FY900: Communication ManualДокумент28 страницFY100 FY101 FY400 FY600 FY700 FY800 FY900: Communication ManualMandeep BoparaiОценок пока нет
- DSP Lab 1 Introduction To DSP Kit and Code Composer StudioДокумент3 страницыDSP Lab 1 Introduction To DSP Kit and Code Composer StudioAli AhmadОценок пока нет
- Sim 160 DMДокумент569 страницSim 160 DMingjguedezОценок пока нет
- Quick Start Guide en SystemRescueCdДокумент4 страницыQuick Start Guide en SystemRescueCdalmagataОценок пока нет
- Best Practices For Integrating OS X With Active DirectoryДокумент20 страницBest Practices For Integrating OS X With Active DirectorymugilanitОценок пока нет
- NSX 64 TroubleshootingДокумент249 страницNSX 64 TroubleshootingRajОценок пока нет
- Chethan-Advanced Database-QuizДокумент20 страницChethan-Advanced Database-QuizaksОценок пока нет
- SyllabusДокумент2 страницыSyllabusnsavi16eduОценок пока нет
- Type of Public HolidaysДокумент7 страницType of Public HolidaysBoban VasiljevicОценок пока нет
- Cs201 MCQ SamarДокумент7 страницCs201 MCQ SamarJaved IqbalОценок пока нет
- Floating-Point Division and Square Root Implementation Using A Taylor-Series Expansion AlgorithmДокумент4 страницыFloating-Point Division and Square Root Implementation Using A Taylor-Series Expansion AlgorithmShubham MishraОценок пока нет
- HP StoreVirtual Multipathing User Guide AX696-10022Документ23 страницыHP StoreVirtual Multipathing User Guide AX696-10022Anonymous DZo049gMОценок пока нет
- PresentationДокумент15 страницPresentationgenfinОценок пока нет