Вам также может понравиться
- A Survey On Uncertainty Estimation in Deep Learning Classification Systems From A Bayesian PerspectiveДокумент35 страницA Survey On Uncertainty Estimation in Deep Learning Classification Systems From A Bayesian Perspectivemouna MAYOUFОценок пока нет
- Probabilistic Selection Approaches in Decomposition-Based Evolutionary Algorithms For Offline Data-Driven Multiobjective OptimizationДокумент10 страницProbabilistic Selection Approaches in Decomposition-Based Evolutionary Algorithms For Offline Data-Driven Multiobjective Optimization刘哲宁Оценок пока нет
- tmp4BC6 TMPДокумент35 страницtmp4BC6 TMPFrontiersОценок пока нет
- Best Generalisation Error PDFДокумент28 страницBest Generalisation Error PDFlohit12Оценок пока нет
- Three-Way Decisions For Handling Uncertainty in Machine Learning A Narrative ReviewДокумент16 страницThree-Way Decisions For Handling Uncertainty in Machine Learning A Narrative ReviewAnwar ShahОценок пока нет
- UNIT 4 SeminarДокумент10 страницUNIT 4 SeminarPradeep Chaudhari50% (2)
- Sensitivity AnalysisДокумент17 страницSensitivity AnalysisBOBBY212Оценок пока нет
- Use of Information Uncertainty in Identification TasksДокумент6 страницUse of Information Uncertainty in Identification TasksGennady MankoОценок пока нет
- Uncertain and Sensitivity in LCAДокумент7 страницUncertain and Sensitivity in LCALiming WangОценок пока нет
- Li - 2020 - Software Reliability Growth Fault Correction Model Based On Machine Learning and Neural Network AlgorithmДокумент5 страницLi - 2020 - Software Reliability Growth Fault Correction Model Based On Machine Learning and Neural Network AlgorithmibrahimОценок пока нет
- Environmental Modelling & Software: Darren R. Broad, Graeme C. Dandy, Holger R. MaierДокумент14 страницEnvironmental Modelling & Software: Darren R. Broad, Graeme C. Dandy, Holger R. MaierFrancisco MirandaОценок пока нет
- Identification of Parameter Correlations For Parameter Estimation in Dynamic Biological ModelsДокумент12 страницIdentification of Parameter Correlations For Parameter Estimation in Dynamic Biological ModelsQuốc Đông VũОценок пока нет
- Comparison Adaptive Methods Function Estimation From SamplesДокумент16 страницComparison Adaptive Methods Function Estimation From SamplesÍcaro RodriguesОценок пока нет
- Wang 2017Документ12 страницWang 2017AI tailieuОценок пока нет
- Stability and Generalization: CMAP, Ecole Polytechnique F-91128 Palaiseau, FRANCEДокумент28 страницStability and Generalization: CMAP, Ecole Polytechnique F-91128 Palaiseau, FRANCEBlaise HanczarОценок пока нет
- Analysis of Common Supervised Learning Algorithms Through ApplicationДокумент20 страницAnalysis of Common Supervised Learning Algorithms Through Applicationacii journalОценок пока нет
- Explainable Deep Learning Models in Medical Image Analysis: ImagingДокумент19 страницExplainable Deep Learning Models in Medical Image Analysis: Imagingsaif alwailiОценок пока нет
- 2005 C Metrics LokanДокумент11 страниц2005 C Metrics Lokan20311a0135Оценок пока нет
- Score Normalization in Multimodal Biometric SystemsДокумент16 страницScore Normalization in Multimodal Biometric Systemsatelie 2Оценок пока нет
- Evidential Reasoning Approach For Multiattribute Decision Analysis Under Both Fuzzy and Interval UncertaintyДокумент15 страницEvidential Reasoning Approach For Multiattribute Decision Analysis Under Both Fuzzy and Interval UncertaintyRenzo ErikssonОценок пока нет
- Artificial Intelligence and Particle Swarm Optimization Algorithm For Optimization Problem in MicrogridsДокумент5 страницArtificial Intelligence and Particle Swarm Optimization Algorithm For Optimization Problem in MicrogridsDilawar Ali Naqi ShahОценок пока нет
- Bioinformatics: Original PaperДокумент7 страницBioinformatics: Original PaperSegredo SilvaОценок пока нет
- AI Techniques in Modelling, Assignment, Problem Solving and OptimizationДокумент8 страницAI Techniques in Modelling, Assignment, Problem Solving and OptimizationTech MitОценок пока нет
- Sensitivity Analysis - WikipediaДокумент13 страницSensitivity Analysis - WikipediaDaniel KrismantoroОценок пока нет
- Automatic Cell Image Segmentation Using Genetic AlgorithmsДокумент5 страницAutomatic Cell Image Segmentation Using Genetic AlgorithmsAintMustache AvedearenaОценок пока нет
- Robust Design Optimization in Aeronautics UsingДокумент21 страницаRobust Design Optimization in Aeronautics UsingReyMysterioОценок пока нет
- Warmink 2010Документ10 страницWarmink 2010Yerel MoralesОценок пока нет
- Uncertainty and Sensitivity AnalysisДокумент38 страницUncertainty and Sensitivity Analysisxinyi tangОценок пока нет
- A Generalized Probabilistic Framework and Its Variants For Training Top-K Recommender SystemsДокумент8 страницA Generalized Probabilistic Framework and Its Variants For Training Top-K Recommender SystemsOualid HichamОценок пока нет
- 10.1007@s00521 018 3712 X PDFДокумент13 страниц10.1007@s00521 018 3712 X PDFAnonymous JUPtdgLB7ZОценок пока нет
- 1 s2.0 S1364815213000236 MainДокумент8 страниц1 s2.0 S1364815213000236 MainCharles FonsecaОценок пока нет
- Ijrdet 0314 09 PDFДокумент9 страницIjrdet 0314 09 PDFAnonymous P8Bt46mk5IОценок пока нет
- Outros Métodos de InferenciasДокумент13 страницOutros Métodos de Inferenciasjoao lucio de souza júniorОценок пока нет
- 1170-Document Upload-6090-1-10-20201103Документ8 страниц1170-Document Upload-6090-1-10-20201103Theblock UniverseОценок пока нет
- Approximate Maximum Likelihood For Complex Structural ModelsДокумент56 страницApproximate Maximum Likelihood For Complex Structural ModelsthumarushikОценок пока нет
- Anomaly Detection Using Generative Adversarial Networks: Reviewing Methodological Progress and ChallengesДокумент13 страницAnomaly Detection Using Generative Adversarial Networks: Reviewing Methodological Progress and ChallengesJorge CasajusОценок пока нет
- Usr Tomcat7 Documents REZUMAT ENG Lemnaru CameliaДокумент6 страницUsr Tomcat7 Documents REZUMAT ENG Lemnaru CameliaqazОценок пока нет
- Effective Model Validation Using Machine LearningДокумент4 страницыEffective Model Validation Using Machine Learningprabu2125Оценок пока нет
- Journal of Statistical Software: Multiple Imputation With Diagnostics (Mi) in R: Opening Windows Into The Black BoxДокумент31 страницаJournal of Statistical Software: Multiple Imputation With Diagnostics (Mi) in R: Opening Windows Into The Black BoxAbi ZuñigaОценок пока нет
- Using Operational Research and Advanced Informatics For C - 2003 - IFAC ProceediДокумент6 страницUsing Operational Research and Advanced Informatics For C - 2003 - IFAC ProceediNGUYEN MANHОценок пока нет
- SimulationДокумент33 страницыSimulationHIRWA YVAN MVUNABOОценок пока нет
- Modeling Analysis and Optimization Under Uncertainty A ReviewДокумент37 страницModeling Analysis and Optimization Under Uncertainty A Review孔祥宇Оценок пока нет
- Infeasible GrossmanДокумент16 страницInfeasible GrossmanToy SoldierОценок пока нет
- Annu Maria-Introduction To Modelling and SimulationДокумент7 страницAnnu Maria-Introduction To Modelling and SimulationMiguel Dominguez de García0% (1)
- Introduction To Modeling and SimulationДокумент7 страницIntroduction To Modeling and SimulationAbiodun Gbenga100% (2)
- 2018-Machine Learning Approaches To Macroeconomic ForecastingДокумент19 страниц2018-Machine Learning Approaches To Macroeconomic ForecastingHoucine AchmakouОценок пока нет
- Project 2021Документ12 страницProject 2021Melvin EstolanoОценок пока нет
- 37316Документ4 страницы37316yesaya.tommyОценок пока нет
- Pr. Miguel Couceiro Dr. Amedeo Napoli: Final Report OnДокумент20 страницPr. Miguel Couceiro Dr. Amedeo Napoli: Final Report OnVikram WaradpandeОценок пока нет
- Why Combining WorksДокумент3 страницыWhy Combining WorksIsabella VinelliОценок пока нет
- 06-04-2022-1649216751-6-.-1. Engg - Analysis and Research On Credit Card Fraud Detection Based On Machine LearningДокумент10 страниц06-04-2022-1649216751-6-.-1. Engg - Analysis and Research On Credit Card Fraud Detection Based On Machine LearningImpact JournalsОценок пока нет
- Practical Fuzzy "Nite Element Analysis of Structures: U.O. Akpan, T.S. Koko, I.R. Orisamolu, B.K. GallantДокумент19 страницPractical Fuzzy "Nite Element Analysis of Structures: U.O. Akpan, T.S. Koko, I.R. Orisamolu, B.K. Gallantsaliah85Оценок пока нет
- Cosc2753 A1 MCДокумент8 страницCosc2753 A1 MCHuy NguyenОценок пока нет
- STR Safety 2015Документ12 страницSTR Safety 2015Jimmy PhoenixОценок пока нет
- Mathiassen - The Principle of Limited ReductionДокумент19 страницMathiassen - The Principle of Limited ReductioncelogcОценок пока нет
- 1.1. Understanding Black-Box Predictions Via Influence FunctionsДокумент12 страниц1.1. Understanding Black-Box Predictions Via Influence Functionsartemischen0606Оценок пока нет
- Validation and Updating of FE Models For Structural AnalysisДокумент10 страницValidation and Updating of FE Models For Structural Analysiskiran2381Оценок пока нет
- 1-2 The Problem 3-4 Proposed Solution 5-7 The Experiment 8-9 Experimental Results 10-11 Conclusion 12 References 13Документ14 страниц1-2 The Problem 3-4 Proposed Solution 5-7 The Experiment 8-9 Experimental Results 10-11 Conclusion 12 References 13NikhilLinSaldanhaОценок пока нет
- Tracking with Particle Filter for High-dimensional Observation and State SpacesОт EverandTracking with Particle Filter for High-dimensional Observation and State SpacesОценок пока нет
- 09931374A Clarus 690 User's GuideДокумент244 страницы09931374A Clarus 690 User's GuideLuz Idalia Ibarra Rodriguez0% (1)
- How To Size Hydropneumatic TankДокумент3 страницыHow To Size Hydropneumatic TankfelipeОценок пока нет
- Nueva Ecija University of Science and Technology Gapan Academic Extension CampusДокумент4 страницыNueva Ecija University of Science and Technology Gapan Academic Extension CampusErmercadoОценок пока нет
- Bill of Materials SampleДокумент31 страницаBill of Materials SampleOcsi YeahОценок пока нет
- Characteristics of Supercritical Flow in Rectangular ChannelДокумент10 страницCharacteristics of Supercritical Flow in Rectangular ChannelFatihОценок пока нет
- Yaskawa TM.J7.01Документ96 страницYaskawa TM.J7.01Salvador CrisantosОценок пока нет
- BS EN 12536-2000 Gas Welding Creep Resistant, Non-Alloy and Fine Grain PDFДокумент11 страницBS EN 12536-2000 Gas Welding Creep Resistant, Non-Alloy and Fine Grain PDFo_l_0Оценок пока нет
- Watchdog Relay: Rugged Hardware-Based Solution For Fail-Safe ShutdownДокумент2 страницыWatchdog Relay: Rugged Hardware-Based Solution For Fail-Safe Shutdownrodruren01Оценок пока нет
- Don't Just Lead, Govern: Implementing Effective IT GovernanceДокумент20 страницDon't Just Lead, Govern: Implementing Effective IT GovernanceWahyu Astri Kurniasari100% (1)
- Documents - The New Ostpolitik and German-German Relations: Permanent LegationsДокумент5 страницDocuments - The New Ostpolitik and German-German Relations: Permanent LegationsKhairun Nisa JОценок пока нет
- Times of India - Supply Chain Management of Newspapers and MagazinesДокумент18 страницTimes of India - Supply Chain Management of Newspapers and MagazinesPravakar Kumar33% (3)
- Gym Mega ForceДокумент3 страницыGym Mega ForceAnonymous iKb87OIОценок пока нет
- Performance Impact Analysis With KPP Using Application Response Measurement in E-Government SystemsДокумент4 страницыPerformance Impact Analysis With KPP Using Application Response Measurement in E-Government SystemsFredrick IshengomaОценок пока нет
- Service Pack 2Документ149 страницService Pack 2billwong169Оценок пока нет
- Group 2 (Oacc39)Документ3 страницыGroup 2 (Oacc39)viernazanne.viadoОценок пока нет
- 1 Chapter1 Introduction V5.5a1Документ13 страниц1 Chapter1 Introduction V5.5a1Alejandro LaraОценок пока нет
- Bank Statement - Feb.2020Документ5 страницBank Statement - Feb.2020TRIVEDI ANILОценок пока нет
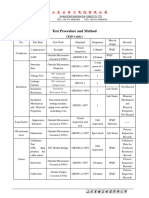
- Test Procedure and MethodДокумент1 страницаTest Procedure and MethodkmiqdОценок пока нет
- Hyperion Essbase 6 - 5 Bootcamp - Basic TrainingДокумент659 страницHyperion Essbase 6 - 5 Bootcamp - Basic Trainingrams08Оценок пока нет
- Rishabh SharmaДокумент72 страницыRishabh SharmaAmitt MalhotraОценок пока нет
- ES1022 y Midterm December 2013 With Final AnswersДокумент13 страницES1022 y Midterm December 2013 With Final AnswersGASR2017Оценок пока нет
- CM29, 03-16-17Документ3 страницыCM29, 03-16-17Louie PascuaОценок пока нет
- Getting To Windows 10:: Microsoft's New Options For Upgrading and OnboardingДокумент4 страницыGetting To Windows 10:: Microsoft's New Options For Upgrading and OnboardingMarcus IPTVОценок пока нет
- PESTLE Analysis Patanjali Ayurved LTDДокумент7 страницPESTLE Analysis Patanjali Ayurved LTDvaidehi50% (2)
- Bhopal Gas TragedyДокумент25 страницBhopal Gas TragedyHarry AroraОценок пока нет
- Summary of Change ASME 2021Документ8 страницSummary of Change ASME 2021Asep DarojatОценок пока нет
- Regional VP Sales Director in USA Resume Margo PappДокумент2 страницыRegional VP Sales Director in USA Resume Margo PappMargoPappОценок пока нет
- GSM Network Hash CodesДокумент5 страницGSM Network Hash CodesMd.Bellal HossainОценок пока нет
- ASSA ABLOY - Digital Cam LocksДокумент12 страницASSA ABLOY - Digital Cam LocksSales Project 2 VCPОценок пока нет