Вам также может понравиться
- Bargalló Escrivá, María (1989) - Apuntes Sobre Terminología GramaticalДокумент8 страницBargalló Escrivá, María (1989) - Apuntes Sobre Terminología GramaticalmbujalanceОценок пока нет
- Azpiazu Torres, Susana - ¿Es Factible Un Diccionario de Adverbios en - Mente PDFДокумент25 страницAzpiazu Torres, Susana - ¿Es Factible Un Diccionario de Adverbios en - Mente PDFmbujalanceОценок пока нет
- Bargallo Escrivá, María (2001) - La Información Gramatical en Los Diccionarios EspecializadosДокумент12 страницBargallo Escrivá, María (2001) - La Información Gramatical en Los Diccionarios EspecializadosmbujalanceОценок пока нет
- Las Innovaciones en Cuestiones Gramaticales Del Diccionario Manual e Ilustrado de La Lengua Espaola de La Rae 0Документ8 страницLas Innovaciones en Cuestiones Gramaticales Del Diccionario Manual e Ilustrado de La Lengua Espaola de La Rae 0LoboslasendaОценок пока нет
- Cambios Estructurales y de Contenido Entre La 22. Ed. (2001) y La 23. (2014) Del Diccionario de La Real Academia EspañolaДокумент26 страницCambios Estructurales y de Contenido Entre La 22. Ed. (2001) y La 23. (2014) Del Diccionario de La Real Academia EspañolambujalanceОценок пока нет
- Bajo Pérez, Elena - El Nuevo Diccionario de La Lengua Castellana Dirigido Por R. BarciaДокумент13 страницBajo Pérez, Elena - El Nuevo Diccionario de La Lengua Castellana Dirigido Por R. BarciambujalanceОценок пока нет
- Azofra, M. Elena (2010) - Antes y Ahora en La Diacronía Del Español. Sintaxis Histórica y Aplicación Lexicográfica PDFДокумент32 страницыAzofra, M. Elena (2010) - Antes y Ahora en La Diacronía Del Español. Sintaxis Histórica y Aplicación Lexicográfica PDFmbujalanceОценок пока нет
- Arribas Jiménez, María (2008) - Algunos Aspectos de La Elaboración Del Diccionario Del Padre Terreros Fuentes Orales y Observación DirectaДокумент7 страницArribas Jiménez, María (2008) - Algunos Aspectos de La Elaboración Del Diccionario Del Padre Terreros Fuentes Orales y Observación DirectambujalanceОценок пока нет
- Azofra, M. Elena (2007) - Criterio Normativo y Uso General Culto en El DPDДокумент10 страницAzofra, M. Elena (2007) - Criterio Normativo y Uso General Culto en El DPDmbujalanceОценок пока нет
- Azofra, M. Elena (2012) - Procesos de Formación de Conectores Aditivos en Español MedievalДокумент34 страницыAzofra, M. Elena (2012) - Procesos de Formación de Conectores Aditivos en Español MedievalmbujalanceОценок пока нет
- Arrizabalaga, Carlos (2014) - Creatividad Léxica y Tratamiento Lexicográfico El Caso de Vargas Llosa y La Casa VerdeДокумент11 страницArrizabalaga, Carlos (2014) - Creatividad Léxica y Tratamiento Lexicográfico El Caso de Vargas Llosa y La Casa VerdembujalanceОценок пока нет
- Ariza, Manuel (1993) - Nombre Propio y Diccionario (Breve Estudio de Los Lexicógrafos Clásicos Españoles)Документ16 страницAriza, Manuel (1993) - Nombre Propio y Diccionario (Breve Estudio de Los Lexicógrafos Clásicos Españoles)mbujalanceОценок пока нет
- Dialnet PropuestasMetodologicasParaElEstudioDelLexico 231978 PDFДокумент24 страницыDialnet PropuestasMetodologicasParaElEstudioDelLexico 231978 PDFTaipe Lopez AndyОценок пока нет
- Anglada, Emilia y Bargalló, María - Principios de Lexicografía Moderna en Diccionarios Del Siglo XIXДокумент8 страницAnglada, Emilia y Bargalló, María - Principios de Lexicografía Moderna en Diccionarios Del Siglo XIXmbujalanceОценок пока нет
- Arribas, Nieves (2006) - Consideraciones Metalexicográficas Sobre Fraseología y Lexicografía Italo-EspañolasДокумент32 страницыArribas, Nieves (2006) - Consideraciones Metalexicográficas Sobre Fraseología y Lexicografía Italo-EspañolasmbujalanceОценок пока нет
- Martos García, Paula (2014) - Propuesta de Un Modelo Lexicográfico para Un Diccionario Histórico de Colocaciones Verbo+sustantivo CDДокумент15 страницMartos García, Paula (2014) - Propuesta de Un Modelo Lexicográfico para Un Diccionario Histórico de Colocaciones Verbo+sustantivo CDmbujalanceОценок пока нет
- Anaya Revuelta, Inmaculada (2000) - Los Diccionarios Enciclopédicos Del Español ActualДокумент29 страницAnaya Revuelta, Inmaculada (2000) - Los Diccionarios Enciclopédicos Del Español ActualmbujalanceОценок пока нет
- Martínez, Fernando Antonio (1947) - Contribución A Una Teoría de La Lexicografía Española PDFДокумент57 страницMartínez, Fernando Antonio (1947) - Contribución A Una Teoría de La Lexicografía Española PDFmbujalanceОценок пока нет
- La Funcion Onomasiologica de Los DiccionariosДокумент20 страницLa Funcion Onomasiologica de Los DiccionariosNEMESIUSОценок пока нет
- Cambios en El Léxico Español Del Vocabulista de Fray Pedro de Alcalá (1505) Con Respecto Al Diccionario de Nebrija (¿1495?)Документ7 страницCambios en El Léxico Español Del Vocabulista de Fray Pedro de Alcalá (1505) Con Respecto Al Diccionario de Nebrija (¿1495?)mbujalance100% (1)
- Bernal, Elisenda (2007) - Diccionario y Gramática. Propuestas para Un Diccionario DigitalДокумент14 страницBernal, Elisenda (2007) - Diccionario y Gramática. Propuestas para Un Diccionario DigitalmbujalanceОценок пока нет
- Martos García, Paula (2016) - Lexicografía y Combinaciones LéxicasДокумент20 страницMartos García, Paula (2016) - Lexicografía y Combinaciones LéxicasmbujalanceОценок пока нет
- Contreras Izquierdo, Narciso M. (2003) - La Lexicografía Monolingüe Del Español en Los Siglos XIX y XXДокумент10 страницContreras Izquierdo, Narciso M. (2003) - La Lexicografía Monolingüe Del Español en Los Siglos XIX y XXmbujalanceОценок пока нет
- Martínez, Fernando Antonio (1958) - La Continuación Del Diccionario de Construcción y Régimen de CuervoДокумент10 страницMartínez, Fernando Antonio (1958) - La Continuación Del Diccionario de Construcción y Régimen de CuervombujalanceОценок пока нет
- Martos García, Paula (2016) - Lexicografía y Combinaciones LéxicasДокумент20 страницMartos García, Paula (2016) - Lexicografía y Combinaciones LéxicasmbujalanceОценок пока нет
- Ynduráin Pardo de Santayana, Carlos (2020) - Los Adjetivos Dimensionales en La Descripción Del Desplazamiento Aproximación LexicográficaДокумент32 страницыYnduráin Pardo de Santayana, Carlos (2020) - Los Adjetivos Dimensionales en La Descripción Del Desplazamiento Aproximación LexicográficambujalanceОценок пока нет
- Ahumada Lara, Ignacio (2008) - de Los Primeros Tratados Metalexicográficos Del Español (Siglos XVIII-XIX)Документ5 страницAhumada Lara, Ignacio (2008) - de Los Primeros Tratados Metalexicográficos Del Español (Siglos XVIII-XIX)mbujalanceОценок пока нет
- Tratamiento de Los Elementos Compositivos en La Lexicografa Espaola Acadmica y Extraacadmica Del Siglo XX 0Документ9 страницTratamiento de Los Elementos Compositivos en La Lexicografa Espaola Acadmica y Extraacadmica Del Siglo XX 0Eddy BosquezОценок пока нет
- Ahumada Lara, Ignacio - La Base de Datos Terminográfica Torres Quevedo Fase ExperimentalДокумент5 страницAhumada Lara, Ignacio - La Base de Datos Terminográfica Torres Quevedo Fase ExperimentalmbujalanceОценок пока нет
- Aarli, Gunn y Juan A. Martínez López - Algunos Problemas en La Lematización de Las Unidades FraseológicasДокумент5 страницAarli, Gunn y Juan A. Martínez López - Algunos Problemas en La Lematización de Las Unidades FraseológicasmbujalanceОценок пока нет
- DWWWRДокумент2 страницыDWWWRBruno Raul Fernandez GutierrezОценок пока нет
- Reprogramacion CodigosДокумент1 страницаReprogramacion CodigosHugo SanchezОценок пока нет
- TelarДокумент5 страницTelarElizabeth MarinОценок пока нет
- Recientemente Se Logró Manufacturar GrafenoДокумент3 страницыRecientemente Se Logró Manufacturar GrafenoAlexandra PintoОценок пока нет
- Jake y Los Piratas - Decoración Banderines FEДокумент24 страницыJake y Los Piratas - Decoración Banderines FENatalia ColacchioОценок пока нет
- Liso Fris SatinadoДокумент4 страницыLiso Fris SatinadoJuan Carlos Barriente CastilloОценок пока нет
- Informe Final Tecnico Uniones HDPE y Pruebas de Linea.Документ62 страницыInforme Final Tecnico Uniones HDPE y Pruebas de Linea.Jorge Flores MerinoОценок пока нет
- Bitácora Estudiantes 1ro. BguДокумент2 страницыBitácora Estudiantes 1ro. BguIsaac CadenaОценок пока нет
- PNL Aplicada A La Comunicacion PDFДокумент1 страницаPNL Aplicada A La Comunicacion PDFJuanОценок пока нет
- Manual Del Sistema de Gestion Ambiental PDFДокумент24 страницыManual Del Sistema de Gestion Ambiental PDFAndres GarzonОценок пока нет
- FORMATO - Requisición de PersonalДокумент2 страницыFORMATO - Requisición de PersonalandresОценок пока нет
- Practica 2 AutomatizacionДокумент3 страницыPractica 2 AutomatizacionAndres LliguisacaОценок пока нет
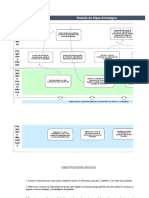
- Guia Insumo Modelo de Mapa EstratégicoДокумент8 страницGuia Insumo Modelo de Mapa EstratégicoIsadely BarreraОценок пока нет
- Guias de RemisionДокумент7 страницGuias de RemisionYonny LizarragaОценок пока нет
- Catia V6Документ4 страницыCatia V6Elvis AsteteОценок пока нет
- Bandura SituadoДокумент5 страницBandura SituadoAntonio PazosОценок пока нет
- Yaskawa l7 ManualДокумент41 страницаYaskawa l7 ManualRicardo BurgosОценок пока нет
- Listado de Homologacion 12 04 2019 PDFДокумент91 страницаListado de Homologacion 12 04 2019 PDFMichel Rosero100% (1)
- Guia Configuracion Comillas-WIFI EstandarДокумент7 страницGuia Configuracion Comillas-WIFI EstandarEdy AchalmaОценок пока нет
- Poemas para Recordar A Elena GarroДокумент21 страницаPoemas para Recordar A Elena GarroJuan BissioОценок пока нет
- ¿Cómo Se Realiza La Prospección en Network Marketing?Документ3 страницы¿Cómo Se Realiza La Prospección en Network Marketing?marcos2017Оценок пока нет
- Lab Rac PLCДокумент8 страницLab Rac PLCAlex ChallcoОценок пока нет
- Manual Rltool y SisotoolДокумент13 страницManual Rltool y Sisotooldecofcb10Оценок пока нет
- Nom 009 STPS 2011 EscalerasДокумент2 страницыNom 009 STPS 2011 EscalerasLuisSantiagoОценок пока нет
- SC 106 SPДокумент154 страницыSC 106 SPMarco DiazОценок пока нет
- Astmd15592bn 090602062145 Phpapp02Документ25 страницAstmd15592bn 090602062145 Phpapp02lool llloplloОценок пока нет
- Comunicacion Oral y Escrita Semana 8Документ4 страницыComunicacion Oral y Escrita Semana 8alan naiz tobar pino100% (3)
- Trabajo - Practico4 Ejercicios de Esfuerzo EfectivoДокумент4 страницыTrabajo - Practico4 Ejercicios de Esfuerzo Efectivorafael romanОценок пока нет
- Actividad 1 SenaДокумент11 страницActividad 1 SenaJavier Jose Salgado RodriguezОценок пока нет
- Informe Del Proyecto Teoria de JuegosДокумент21 страницаInforme Del Proyecto Teoria de JuegosSaúl F. MendietaОценок пока нет