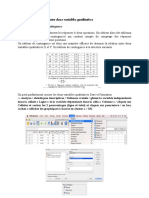
Вам также может понравиться
- Recueil D'exercices Corrigés de MicroéconomieДокумент134 страницыRecueil D'exercices Corrigés de MicroéconomieOverDoc100% (15)
- Gestion de La Petite CaisseДокумент4 страницыGestion de La Petite CaisseFélix AndjiОценок пока нет
- 2010 - Analyse en Composantes Principales - TutorielДокумент7 страниц2010 - Analyse en Composantes Principales - TutorielFranck DernoncourtОценок пока нет
- La Recherche Participative Comme Mode de Production Des Savoirs, Un Etat Des Lieux Des Pratiques en FranceДокумент94 страницыLa Recherche Participative Comme Mode de Production Des Savoirs, Un Etat Des Lieux Des Pratiques en FranceAbrahamОценок пока нет
- Voir en ReveДокумент1 страницаVoir en Revehakim100% (1)
- ACP, SPSS InterpretaionДокумент8 страницACP, SPSS InterpretaionmarocОценок пока нет
- Fiche Data AnalysisДокумент6 страницFiche Data AnalysischarpentierОценок пока нет
- Protocole Reherche 15 Sept 2023Документ78 страницProtocole Reherche 15 Sept 2023Ali AIT-MOHANDОценок пока нет
- ROQYA Contre Mauvais Oeil Et JalousieДокумент2 страницыROQYA Contre Mauvais Oeil Et JalousieEl Hadji Ndoye100% (2)
- Audit Cours n02 EpiДокумент30 страницAudit Cours n02 EpiAdel ArezkiОценок пока нет
- Stat - Ad Siagh ArДокумент24 страницыStat - Ad Siagh Aranfal JijОценок пока нет
- Résumé de L'analyse Du Discours S5Документ6 страницRésumé de L'analyse Du Discours S5Houcine Mohamed0% (1)
- AnalyseMultivarieeDonneesGeographiques PDFДокумент144 страницыAnalyseMultivarieeDonneesGeographiques PDFDouaa ImpératriceОценок пока нет
- Fiche Realiser Une Pyramide Des Ages Sur ExcelДокумент4 страницыFiche Realiser Une Pyramide Des Ages Sur ExcelFATIMA ZAHRA AIT HAMD-OUHSAINОценок пока нет
- Introduction À L Epidémiologie 1 - CanvasДокумент52 страницыIntroduction À L Epidémiologie 1 - Canvasbilal.bendami.bb7Оценок пока нет
- ACP, SPSS InterpretaionДокумент10 страницACP, SPSS InterpretaionZakaria HamaneОценок пока нет
- EchantillonageДокумент26 страницEchantillonagehamzzaaОценок пока нет
- Acp ADDДокумент60 страницAcp ADDadam smithОценок пока нет
- Classification AcpДокумент5 страницClassification AcpMbaye AwОценок пока нет
- Programmation Sur EviewsДокумент19 страницProgrammation Sur Eviews.cadeau01Оценок пока нет
- Modèle PV AG ConstitutiveДокумент11 страницModèle PV AG ConstitutiveEl Hadji NdoyeОценок пока нет
- Regles RamadanДокумент13 страницRegles RamadanEl Hadji NdoyeОценок пока нет
- Cours Biostat 1AM 15 Sept 2015 PDFДокумент42 страницыCours Biostat 1AM 15 Sept 2015 PDFAliou FayeОценок пока нет
- Corrigé Examen2 ECO1502B Automne 2015Документ35 страницCorrigé Examen2 ECO1502B Automne 2015asdaОценок пока нет
- La Mise en Application de La Methdologie D Etude EvenementsДокумент9 страницLa Mise en Application de La Methdologie D Etude EvenementsAhmed MohamedОценок пока нет
- Etude 1Документ3 страницыEtude 1Abdelhadi BoutimameОценок пока нет
- Meta Donnees SNIS PDFДокумент232 страницыMeta Donnees SNIS PDFAndré SOMEОценок пока нет
- Protocole de Recherche Et Méthodes (Mode de Compatibilité)Документ66 страницProtocole de Recherche Et Méthodes (Mode de Compatibilité)ChàdîÂlaouiSoulimaniОценок пока нет
- ch3 EchantionnageДокумент24 страницыch3 EchantionnageAkram BousetaОценок пока нет
- Risque D'estimation Et Choix de Portefeuille Dans Le Cadre Des Moments Partiels InferieursДокумент32 страницыRisque D'estimation Et Choix de Portefeuille Dans Le Cadre Des Moments Partiels InferieursB.I100% (3)
- Cours ElkamliДокумент60 страницCours ElkamliElgharibiОценок пока нет
- PDF 2.3-Epidem Analytique Methodes StandardisationДокумент22 страницыPDF 2.3-Epidem Analytique Methodes StandardisationGoungounga Juste AristideОценок пока нет
- Se1 1 Introduction Web PDFДокумент40 страницSe1 1 Introduction Web PDFDanil LebedevОценок пока нет
- Relation Entre Deux Variables QualitativesДокумент10 страницRelation Entre Deux Variables QualitativesDanteОценок пока нет
- Chapitre 1 ADДокумент73 страницыChapitre 1 ADAref ChaariОценок пока нет
- GAB S2 StatistiqueДокумент140 страницGAB S2 StatistiqueayaelhadraouiОценок пока нет
- Simulation Des Lois de Probabilités Sous RДокумент6 страницSimulation Des Lois de Probabilités Sous RAbdallahi Sidi100% (1)
- Cours 1Документ17 страницCours 1Hamdja SouaibouОценок пока нет
- Méthodes en ÉpidémiologieДокумент20 страницMéthodes en ÉpidémiologieAlejandra Salamanca RomeroОценок пока нет
- L'approche Macroeconomique Du Taux de Change Reel D'equilibre - Application Au Taux de Change Algerien Modele NatrexДокумент12 страницL'approche Macroeconomique Du Taux de Change Reel D'equilibre - Application Au Taux de Change Algerien Modele NatrexHasni AbderrahimОценок пока нет
- Test Stat RДокумент54 страницыTest Stat RYAMEOGOОценок пока нет
- PAO StatistiqueДокумент21 страницаPAO Statistiquesimao_sabrosa7794Оценок пока нет
- Le Traitement Statistique PDFДокумент5 страницLe Traitement Statistique PDFZandry BefitiaОценок пока нет
- Poly Freg Var QualiДокумент71 страницаPoly Freg Var QualiAyoub JelloulОценок пока нет
- Chapitre ACPДокумент5 страницChapitre ACPBird000Оценок пока нет
- 1 PBДокумент21 страница1 PBSylvestreYapo100% (1)
- S2 Méthodes Quantitatives de GestionДокумент41 страницаS2 Méthodes Quantitatives de GestionsidwhnОценок пока нет
- Beamer Statistique Descriptive PDFДокумент66 страницBeamer Statistique Descriptive PDFAYOUB MANSOURОценок пока нет
- Ponderation Et RedressementДокумент41 страницаPonderation Et RedressementAnonymous qeolzNIFdfОценок пока нет
- 1.méthodes de Sondage & Sources D'info-1Документ54 страницы1.méthodes de Sondage & Sources D'info-1maryeme amkarОценок пока нет
- Enoncé - ExamenДокумент3 страницыEnoncé - ExamenZiad NabaouiОценок пока нет
- Notion de Test D - HypotheseДокумент6 страницNotion de Test D - HypotheseMahdi El BahiОценок пока нет
- Explo StatДокумент104 страницыExplo StatGangster marocianОценок пока нет
- Cours Stat DescriptiveДокумент73 страницыCours Stat Descriptive[AE]Оценок пока нет
- Méthodologie de Conception D'un Produit MécatroniqueДокумент6 страницMéthodologie de Conception D'un Produit MécatroniqueZakarya BendahmaneОценок пока нет
- Dependance Variables QualitativesДокумент135 страницDependance Variables QualitativesThomas DeblemeОценок пока нет
- Cours - Econo Variables Qualitatives - M1 Eco - 2021-2022Документ14 страницCours - Econo Variables Qualitatives - M1 Eco - 2021-2022Prince DemОценок пока нет
- Cours 4Документ34 страницыCours 4Fatima Zahra Elhajjami100% (1)
- Exposé - Estimation de La ProportionДокумент14 страницExposé - Estimation de La ProportionAbdel MoussaОценок пока нет
- TsДокумент178 страницTsAdel RoОценок пока нет
- ACP Avec RДокумент5 страницACP Avec RAlioune Badara DiopОценок пока нет
- GR 47Документ119 страницGR 47Mina OulОценок пока нет
- Cours Sante Publique Lepidemiologie - HTMLДокумент19 страницCours Sante Publique Lepidemiologie - HTMLFivos FivОценок пока нет
- Echantillonnage PDFДокумент18 страницEchantillonnage PDFsamira HAMОценок пока нет
- Rapport RAJI OussamaДокумент90 страницRapport RAJI OussamaYassine AboulanourОценок пока нет
- Chapitre 2. Diustribution EchantillonnagevfДокумент43 страницыChapitre 2. Diustribution EchantillonnagevfFiras BellakhelОценок пока нет
- Modélisation de l'ingénierie publique: Tome 2 : Contexte territorialОт EverandModélisation de l'ingénierie publique: Tome 2 : Contexte territorialОценок пока нет
- FR Tanagra AFDMДокумент13 страницFR Tanagra AFDMKasaОценок пока нет
- Lignes - Directrices Recrutement ConseillersДокумент7 страницLignes - Directrices Recrutement ConseillersEl Hadji NdoyeОценок пока нет
- Lignes Directrices Gestion Offres Spontanees - PPPДокумент8 страницLignes Directrices Gestion Offres Spontanees - PPPEl Hadji NdoyeОценок пока нет
- PV GieДокумент1 страницаPV Giesamba fall dialloОценок пока нет
- Modele-Evaluation PrealableДокумент5 страницModele-Evaluation PrealableEl Hadji NdoyeОценок пока нет
- Flyers BCДокумент1 страницаFlyers BCEl Hadji NdoyeОценок пока нет
- Cadeau de Mariage Daara Serigne Mor DiopДокумент2 страницыCadeau de Mariage Daara Serigne Mor DiopEl Hadji NdoyeОценок пока нет
- Diligences EsДокумент5 страницDiligences EsEl Hadji Ndoye100% (1)
- Formulaire de Demande de Subvention - IndividuelДокумент12 страницFormulaire de Demande de Subvention - IndividuelEl Hadji NdoyeОценок пока нет
- Guide de Demarrage Dolibarr PDFДокумент28 страницGuide de Demarrage Dolibarr PDFJohann CalvinОценок пока нет
- Guide de Demarrage Dolibarr PDFДокумент28 страницGuide de Demarrage Dolibarr PDFJohann CalvinОценок пока нет
- Doua Baqara À NassiДокумент1 страницаDoua Baqara À NassiEl Hadji NdoyeОценок пока нет
- Fiche Pièces À Fournir CI 23 03 2010Документ4 страницыFiche Pièces À Fournir CI 23 03 2010Assane BasseneОценок пока нет
- Calendrier General Des Examens Et-Concours 2018Документ7 страницCalendrier General Des Examens Et-Concours 2018El Hadji NdoyeОценок пока нет
- Etudes Des Cas Formation FIDA YaoundeДокумент23 страницыEtudes Des Cas Formation FIDA YaoundeEl Hadji NdoyeОценок пока нет
- Plan de Passation Des Marches Pour La Gestion 20 : (Insérer: Entête de L'autorité Contractante)Документ1 страницаPlan de Passation Des Marches Pour La Gestion 20 : (Insérer: Entête de L'autorité Contractante)El Hadji NdoyeОценок пока нет
- La Gestion Du Risque CrA Dit Par La Ma Thode Du ScoringДокумент15 страницLa Gestion Du Risque CrA Dit Par La Ma Thode Du ScoringRahil MonteiroОценок пока нет
- Prise en ChargeДокумент2 страницыPrise en ChargeEl Hadji NdoyeОценок пока нет
- Chap It Re 1Документ8 страницChap It Re 1Kakou BattikhОценок пока нет
- VbaPourExcel2007 PDFДокумент87 страницVbaPourExcel2007 PDFsaghrouchniОценок пока нет
- ScoringДокумент20 страницScoringEl Hadji NdoyeОценок пока нет
- Travail Et Energie Cinetique Corrige Serie D Exercices 1 2 PDFДокумент9 страницTravail Et Energie Cinetique Corrige Serie D Exercices 1 2 PDFJules Koutoumboga100% (1)
- TH Sess 5FR Le Lac Nord de TunisДокумент59 страницTH Sess 5FR Le Lac Nord de TunisHatem EllouzeОценок пока нет
- Stress Lun VFДокумент14 страницStress Lun VFNouhaila EllamtiОценок пока нет
- Cours de MacrodynamiqueДокумент87 страницCours de MacrodynamiqueHans Herman100% (1)
- EmpennagesДокумент18 страницEmpennagesbochra jarhdouraОценок пока нет
- Régression Linéaire (Pour TD)Документ10 страницRégression Linéaire (Pour TD)Mohamed EL AmineОценок пока нет
- Support de Cours Algèbre 3 SMIAДокумент78 страницSupport de Cours Algèbre 3 SMIAHAMZA ELYAAKOUBIОценок пока нет
- Echelle Cuve 30m3Документ1 страницаEchelle Cuve 30m3Ben Abdallah BecemОценок пока нет
- A DjeddiДокумент7 страницA DjeddioussamaОценок пока нет
- 5 Étapes Pour Décrocher Mes 1ers ClientsДокумент11 страниц5 Étapes Pour Décrocher Mes 1ers ClientsEric TambourОценок пока нет
- Ao 1 TDДокумент2 страницыAo 1 TDBerbaoui KamelОценок пока нет
- TP 1 HydrauliqueДокумент6 страницTP 1 HydrauliqueHa DjerОценок пока нет
- M12 - Notions D'électronique GE-REEДокумент77 страницM12 - Notions D'électronique GE-REEKesraoui HichemОценок пока нет
- 2021 ESIEE-Amiens Energetique Et Batiments Intelligents Plaquette WebДокумент13 страниц2021 ESIEE-Amiens Energetique Et Batiments Intelligents Plaquette WebBOATENG AUGUSTEОценок пока нет
- Communication Interpersonnelle Cours PDFДокумент2 страницыCommunication Interpersonnelle Cours PDFAshleyОценок пока нет
- TGDCДокумент18 страницTGDCAZZEDDINE BAGGARОценок пока нет
- Eléments de Correction: Systèmes Multitâches Et Temps Réel Contrôle Avril 2006 Durée: 2 HeuresДокумент15 страницEléments de Correction: Systèmes Multitâches Et Temps Réel Contrôle Avril 2006 Durée: 2 HeuresHàjàr KcimОценок пока нет
- Comment Faire Pour Copier Des Jeux Xbox 360Документ2 страницыComment Faire Pour Copier Des Jeux Xbox 360commegemmesgratuitОценок пока нет
- FAVIER - Partie I - Le MuscleДокумент24 страницыFAVIER - Partie I - Le MuscleAntoine FlorenceОценок пока нет
- IsisdevoileeДокумент1 645 страницIsisdevoileeyo2aОценок пока нет
- CentrifugationДокумент8 страницCentrifugationManal IdaliОценок пока нет
- Agri-Food 4.0 Drivers and Links To Innovation and Eco-Innovation FRДокумент21 страницаAgri-Food 4.0 Drivers and Links To Innovation and Eco-Innovation FRSaÏd BaaouiОценок пока нет
- Cours Series NumeriquesДокумент4 страницыCours Series NumeriquesNadiaa KodadОценок пока нет
- Histoire Des GranulatsДокумент1 страницаHistoire Des GranulatsAchour AchourkouiderОценок пока нет
- Mimoune Samir Et Merzag AbdelatifДокумент103 страницыMimoune Samir Et Merzag AbdelatifSalah LblОценок пока нет
- DNBblanc 2Документ12 страницDNBblanc 2Ophelie LE RAT50% (2)
- Math2 CorДокумент8 страницMath2 CorAhmed MbarekОценок пока нет