Вам также может понравиться
- AIT HomeWork 2Документ4 страницыAIT HomeWork 2bhulbhal6269Оценок пока нет
- HOMEWORK ASSIGNMENT 3 SOLUTIONS MAXIMAL FUNCTIONSДокумент5 страницHOMEWORK ASSIGNMENT 3 SOLUTIONS MAXIMAL FUNCTIONShugo manceraОценок пока нет
- 1 HCV Unit and DimensionsДокумент40 страниц1 HCV Unit and DimensionsKanika SinghОценок пока нет
- Semi-Random Notes On NumbersДокумент22 страницыSemi-Random Notes On NumbersTytus MetryckiОценок пока нет
- Bending Deflection - Macaulay Step Functions: AE1108-II: Aerospace Mechanics of MaterialsДокумент9 страницBending Deflection - Macaulay Step Functions: AE1108-II: Aerospace Mechanics of MaterialsAyanwale-cole pelumi AkeemОценок пока нет
- Deflection Via Step FunctionsДокумент9 страницDeflection Via Step FunctionsAyanwale-cole pelumi AkeemОценок пока нет
- Fourier Series and Oscillatory MotionДокумент7 страницFourier Series and Oscillatory MotionChrisОценок пока нет
- Prosta Greda: H H M V M VДокумент4 страницыProsta Greda: H H M V M VJoeMassinoОценок пока нет
- In-Plane Behavior of Beam-ColumnsДокумент27 страницIn-Plane Behavior of Beam-ColumnsQazi Abdul MoeedОценок пока нет
- Linear Project 1Документ13 страницLinear Project 1Megan WheelerОценок пока нет
- Krylov Subspace Methods and Preconditioning: Are Magnus BruasetДокумент36 страницKrylov Subspace Methods and Preconditioning: Are Magnus BruasetEnrique FloresОценок пока нет
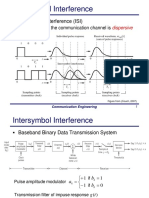
- Intersymbol Interference (ISI)Документ21 страницаIntersymbol Interference (ISI)PeaceОценок пока нет
- Sparsity-Driven Impulsive Noise Removal: A Discrete Hermite Transform Case StudyДокумент14 страницSparsity-Driven Impulsive Noise Removal: A Discrete Hermite Transform Case StudylosmibrajovicОценок пока нет
- Lecture 18Документ32 страницыLecture 18Axel Coronado PopperОценок пока нет
- CLS ENG 20 21 XI Phy Target 3 Level 2 Chapter 6Документ20 страницCLS ENG 20 21 XI Phy Target 3 Level 2 Chapter 6Mahendra SonawaneОценок пока нет
- Gaussian Mixture Model and The EM Algorithm in Speech RecognitionДокумент22 страницыGaussian Mixture Model and The EM Algorithm in Speech RecognitionMohammadОценок пока нет
- 2 Photonpropagator PDF 15403Документ26 страниц2 Photonpropagator PDF 15403schrodingerscat693Оценок пока нет
- Phys 203 Princeton University Fall 2006 Final Exam: K R K VДокумент5 страницPhys 203 Princeton University Fall 2006 Final Exam: K R K Vmichael pasquiОценок пока нет
- Markov Chain Monte Carlo (MCMC) Methods: Example 11 (Matlab)Документ21 страницаMarkov Chain Monte Carlo (MCMC) Methods: Example 11 (Matlab)Anindya Apriliyanti Pravitasari KurniawanОценок пока нет
- PH 203 Quantum Mechanics I - Assignment 4Документ5 страницPH 203 Quantum Mechanics I - Assignment 4NANDEESH KUMAR K MОценок пока нет
- Small Oscillations and Normal ModesДокумент10 страницSmall Oscillations and Normal Modesjit1986Оценок пока нет
- Using Eigenvalues To Find Solutions To Dampened Spring ProblemsДокумент4 страницыUsing Eigenvalues To Find Solutions To Dampened Spring ProblemsJainil RanaОценок пока нет
- Kap 3Документ26 страницKap 3J MОценок пока нет
- Matrix MultДокумент6 страницMatrix Multdaweley389Оценок пока нет
- WC Unit 5Документ53 страницыWC Unit 5Shamil DawoodОценок пока нет
- Module - 3 Lecture Notes - 5 Revised Simplex Method, Duality and Sensitivity AnalysisДокумент11 страницModule - 3 Lecture Notes - 5 Revised Simplex Method, Duality and Sensitivity Analysismedardo77Оценок пока нет
- X (N) y (N) 1Документ4 страницыX (N) y (N) 1jamesyuОценок пока нет
- Scattering Processes in QED and Electron Anomalous Magnetic MomentДокумент26 страницScattering Processes in QED and Electron Anomalous Magnetic MomentABHINANDAN YADAVОценок пока нет
- CAE in der Regelungstechnik ExercisesДокумент7 страницCAE in der Regelungstechnik ExercisesRiddhijit ChattopadhyayОценок пока нет
- Development, W and PlotДокумент3 страницыDevelopment, W and PlotErnest MilianОценок пока нет
- AIEEE 2007 SolutionsДокумент18 страницAIEEE 2007 Solutionsapi-19826463Оценок пока нет
- Modified QMFДокумент5 страницModified QMFdhermioneОценок пока нет
- Lab 6 - AnswersДокумент9 страницLab 6 - AnswersEdivaldo BartolomeuОценок пока нет
- Some Uniqueness Results For Dependent Measure Spaces: C. Sato and L. ShastriДокумент12 страницSome Uniqueness Results For Dependent Measure Spaces: C. Sato and L. ShastristefanonicotriОценок пока нет
- Sol - 08Документ2 страницыSol - 08kirthanaОценок пока нет
- HW 4 SolutionsДокумент5 страницHW 4 SolutionsKiran AdhikariОценок пока нет
- PARAMAGNETISM LECTUREДокумент12 страницPARAMAGNETISM LECTUREawaisaОценок пока нет
- Matrix Multiplication AlgorithmsДокумент32 страницыMatrix Multiplication AlgorithmsuanuliОценок пока нет
- Variance of a Binomial DistributionДокумент3 страницыVariance of a Binomial DistributionpaulicalejerОценок пока нет
- Linear Complementarity Problems and Their Sources: Z 0, Q+MZ 0, ZДокумент19 страницLinear Complementarity Problems and Their Sources: Z 0, Q+MZ 0, ZSumit RayОценок пока нет
- Cgnotes PDFДокумент11 страницCgnotes PDFBijaya PandeyОценок пока нет
- Core Solution P-6Документ10 страницCore Solution P-6Ahana Singh XI S5Оценок пока нет
- Partial Differential Equations Handout: 1 Boundary-Value ProblemsДокумент28 страницPartial Differential Equations Handout: 1 Boundary-Value Problemsmohinuddin12456Оценок пока нет
- Beams Non-Compact Sections and Shear StrengthwДокумент36 страницBeams Non-Compact Sections and Shear StrengthwErica MillendezОценок пока нет
- Presentation Magnetism 1594842079 208447Документ10 страницPresentation Magnetism 1594842079 208447Khilendra MandleОценок пока нет
- Polynomial Transform Based DCT ImplementationДокумент5 страницPolynomial Transform Based DCT Implementation1googleОценок пока нет
- Problem Solution ch5 ch7Документ12 страницProblem Solution ch5 ch7윤희상Оценок пока нет
- Physics FormulasДокумент2 страницыPhysics FormulasKristine BalansagОценок пока нет
- Integral Transforms For Heat and Fluid Flow in Two-And Three-Dimensional Porous MediaДокумент11 страницIntegral Transforms For Heat and Fluid Flow in Two-And Three-Dimensional Porous MediaHà Đăng ToànОценок пока нет
- Chap 3Документ183 страницыChap 3AmandaОценок пока нет
- Single Quantum Deletion Error-Correcting Codes: Ayumu Nakayama Manabu HAGIWARAДокумент14 страницSingle Quantum Deletion Error-Correcting Codes: Ayumu Nakayama Manabu HAGIWARAudslvОценок пока нет
- Linear-Phase FIR Filter Design by Least SquaresДокумент8 страницLinear-Phase FIR Filter Design by Least SquaresJonasHirataОценок пока нет
- Chapter 4 Multiple-Degree-of-Freedom (MDOF) Systems ExamplesДокумент17 страницChapter 4 Multiple-Degree-of-Freedom (MDOF) Systems ExamplesprashanthОценок пока нет
- MIT8 03SCF16 Lec6 PDFДокумент5 страницMIT8 03SCF16 Lec6 PDFRohan JoshiОценок пока нет
- PHYSICS 2760 Formula Sheet Exam 2 4 10 Wb/Am × 1.6 10 × CДокумент2 страницыPHYSICS 2760 Formula Sheet Exam 2 4 10 Wb/Am × 1.6 10 × CKrutikОценок пока нет
- Final Exam Formu PDFДокумент2 страницыFinal Exam Formu PDFJoØrsh Ênrique Tu Xikytø NînîØflowОценок пока нет
- Presenter: Mostafa Barzegari May 2010: Authors Mostafa Barzegari, S.M.T Bathaee, Mohsen AlizadehДокумент10 страницPresenter: Mostafa Barzegari May 2010: Authors Mostafa Barzegari, S.M.T Bathaee, Mohsen Alizadehkarimi-15Оценок пока нет
- Problem Sheet 1 MechanicsДокумент2 страницыProblem Sheet 1 MechanicsJonatanОценок пока нет
- Cap 5 Diseño de Elementos A Torsión - 1Документ7 страницCap 5 Diseño de Elementos A Torsión - 1Nahomi JnОценок пока нет
- Archive of SIDДокумент11 страницArchive of SIDOmar SaeedОценок пока нет
- Calculations of Stratified Wavy Two-Phase Ow in Pipes: Petter Andreas Berthelsen, Tor YtrehusДокумент22 страницыCalculations of Stratified Wavy Two-Phase Ow in Pipes: Petter Andreas Berthelsen, Tor YtrehusOmar SaeedОценок пока нет
- General Catalogue 0819 Gb-3Документ186 страницGeneral Catalogue 0819 Gb-3Omar SaeedОценок пока нет
- Fast and straightforward determination of RON, MON, aromatics, benzene, and olefins in gasoline by near-infrared spectroscopyДокумент4 страницыFast and straightforward determination of RON, MON, aromatics, benzene, and olefins in gasoline by near-infrared spectroscopyOmar SaeedОценок пока нет
- Combustion Research Unit CRU Tool PDFДокумент5 страницCombustion Research Unit CRU Tool PDFOmar SaeedОценок пока нет
- Quality Control of Gasoline: Rapid Determination of RON, MON, AKI, Aromatic Content, and DensityДокумент5 страницQuality Control of Gasoline: Rapid Determination of RON, MON, AKI, Aromatic Content, and DensityOmar SaeedОценок пока нет
- Applied Mathematical Modelling: David Winfield, Nick Croft, Mark Cross, David PaddisonДокумент14 страницApplied Mathematical Modelling: David Winfield, Nick Croft, Mark Cross, David PaddisonOmar SaeedОценок пока нет
- AN-DOWINETANK-E RevB 0919 v1Документ5 страницAN-DOWINETANK-E RevB 0919 v1Omar SaeedОценок пока нет
- Design Two-Phase Separators Within The Right Limits: October 1993Документ9 страницDesign Two-Phase Separators Within The Right Limits: October 1993kishna009Оценок пока нет
- iN7kgJ Temperature Controller Ai518518p Operation Manual PDFДокумент57 страницiN7kgJ Temperature Controller Ai518518p Operation Manual PDFOmar SaeedОценок пока нет
- Catalytic Steam Gasification of Mengdong Coal in The Presence of Iron Ore For Hydrogen-Rich Gas ProductionДокумент13 страницCatalytic Steam Gasification of Mengdong Coal in The Presence of Iron Ore For Hydrogen-Rich Gas ProductionOmar SaeedОценок пока нет
- Unequally Numerical DifferentiationДокумент4 страницыUnequally Numerical DifferentiationOmar SaeedОценок пока нет
- Catalytic Steam Gasification of Mengdong Coal in The Presence of Iron Ore For Hydrogen-Rich Gas ProductionДокумент13 страницCatalytic Steam Gasification of Mengdong Coal in The Presence of Iron Ore For Hydrogen-Rich Gas ProductionOmar SaeedОценок пока нет
- Bionic ShieldДокумент3 страницыBionic ShieldOmar SaeedОценок пока нет
- 1200C Hydrogen Atmosphere Furnace PDFДокумент10 страниц1200C Hydrogen Atmosphere Furnace PDFOmar SaeedОценок пока нет
- Combustion Research Unit CRU Tool PDFДокумент5 страницCombustion Research Unit CRU Tool PDFOmar SaeedОценок пока нет
- ConversationДокумент1 страницаConversationOmar SaeedОценок пока нет
- Tipikal Gas Composition PDFДокумент6 страницTipikal Gas Composition PDFdaralextiany100% (1)
- Low Profile Side Access Calibration TrailerДокумент2 страницыLow Profile Side Access Calibration TrailerOmar SaeedОценок пока нет
- Book 2Документ2 страницыBook 2Omar SaeedОценок пока нет
- DehydrogenationДокумент6 страницDehydrogenationOmar SaeedОценок пока нет
- FORZA Oxidation IHT Copy. - CompressedДокумент1 страницаFORZA Oxidation IHT Copy. - CompressedOmar SaeedОценок пока нет
- Atg Worksheet Beornobe1 PDFДокумент2 страницыAtg Worksheet Beornobe1 PDFJeanCarlosAcostaPoloОценок пока нет
- Astm D-1552Документ7 страницAstm D-1552GianfrancoОценок пока нет
- Apa Style Sample PaperДокумент12 страницApa Style Sample Paperjoerunner407Оценок пока нет
- MODEL: 73VR21: Paperless Recording System Paperless Recorder (3) Power InputДокумент18 страницMODEL: 73VR21: Paperless Recording System Paperless Recorder (3) Power InputOmar SaeedОценок пока нет
- Approved Service CentresДокумент4 страницыApproved Service CentresOmar SaeedОценок пока нет
- Micromac Hardness On Line Analyzer For Hardness Monitoring in WaterДокумент2 страницыMicromac Hardness On Line Analyzer For Hardness Monitoring in WaterOmar SaeedОценок пока нет
- Cx2000 Conductivity/ Resistivity Transmitter: Product Specification SheetДокумент1 страницаCx2000 Conductivity/ Resistivity Transmitter: Product Specification SheetOmar SaeedОценок пока нет
- US ISB56 PH SelectionДокумент2 страницыUS ISB56 PH SelectionOmar SaeedОценок пока нет
- Chapter OneДокумент29 страницChapter Oneلطيف احمد حسنОценок пока нет
- Monte Carlo Algorithms for Pi and Sphere VolumeДокумент6 страницMonte Carlo Algorithms for Pi and Sphere VolumePradeep KumarОценок пока нет
- 2 Derivation Flow EquationsДокумент49 страниц2 Derivation Flow EquationsSudharsananPRSОценок пока нет
- Anti DerivativesДокумент9 страницAnti Derivativesedmark bonjОценок пока нет
- A. Find The Coordinates of All Maximum and Minimum Points On The Given Interval. Justify YourДокумент6 страницA. Find The Coordinates of All Maximum and Minimum Points On The Given Interval. Justify YourLara VillanuevaОценок пока нет
- IFS Mathematics 2016Документ10 страницIFS Mathematics 2016SreekanthPamuluruОценок пока нет
- Problem Solving in Math (Math 43900) Fall 2013: Easy Warm-Up ProblemsДокумент8 страницProblem Solving in Math (Math 43900) Fall 2013: Easy Warm-Up ProblemsDeeptanshОценок пока нет
- Assignment1 AtsalakiXanthoula Data StructuresДокумент6 страницAssignment1 AtsalakiXanthoula Data StructuresGlyko XamogelakiKritiОценок пока нет
- Math and Physics ProblemsДокумент2 страницыMath and Physics ProblemsjaniceОценок пока нет
- Assignment CLO 1: Relation, Function, and Recurrence: Discrete Mathematics (CII1G3)Документ10 страницAssignment CLO 1: Relation, Function, and Recurrence: Discrete Mathematics (CII1G3)maulanbach riburaneОценок пока нет
- Doppler Broadening: 1 Wavelength and TemperatureДокумент5 страницDoppler Broadening: 1 Wavelength and Temperatureakhilesh_353859963Оценок пока нет
- Numerical Tech For Interpolation & Curve FittingДокумент46 страницNumerical Tech For Interpolation & Curve FittingChatchai ManathamsombatОценок пока нет
- Graphs and Central TendencyДокумент44 страницыGraphs and Central TendencyMahima BhatnagarОценок пока нет
- Complex Analysis Math 322 Homework 4Документ3 страницыComplex Analysis Math 322 Homework 409polkmnpolkmnОценок пока нет
- AA SL Sequence and SeriesДокумент3 страницыAA SL Sequence and SeriesTaksh JethwaniОценок пока нет
- GCSE Mathematics A or Better Revison SheetsДокумент47 страницGCSE Mathematics A or Better Revison SheetsHannah PatelОценок пока нет
- Mathematics7 - Q2 - M20 - Basic - Terms - in - Algebra - v3 PDFДокумент35 страницMathematics7 - Q2 - M20 - Basic - Terms - in - Algebra - v3 PDFNorvin Agron50% (4)
- Ee 301 - Circuit Theory & Networks: Multiple Choice Type QuestionsДокумент5 страницEe 301 - Circuit Theory & Networks: Multiple Choice Type QuestionsGsn ReddyОценок пока нет
- Student Slides M2Документ13 страницStudent Slides M2captainhassОценок пока нет
- MATH - 2130 01 W19 Numerical Methods MATH - 2130 01 W19 Numerical MethodsДокумент4 страницыMATH - 2130 01 W19 Numerical Methods MATH - 2130 01 W19 Numerical MethodsMohamed HussainОценок пока нет
- Experiment No 9: Problem Using Lagrange's MethodДокумент4 страницыExperiment No 9: Problem Using Lagrange's Methodamol maliОценок пока нет
- ECSE343MidtermW2023 FinalДокумент8 страницECSE343MidtermW2023 FinalNoor JethaОценок пока нет
- ERRATA LIST FOR SET THEORYДокумент4 страницыERRATA LIST FOR SET THEORYKelvinОценок пока нет
- Form Finding of Shells by Structural OptimizationДокумент9 страницForm Finding of Shells by Structural OptimizationcaiguiОценок пока нет
- CompGeom-ch2 - Generalized Homogeneous Coordinates PDFДокумент34 страницыCompGeom-ch2 - Generalized Homogeneous Coordinates PDFHenrique Mariano AmaralОценок пока нет
- FIU - EGM3311 - Syllabus Summer 2015Документ3 страницыFIU - EGM3311 - Syllabus Summer 2015angelОценок пока нет
- Ace Signal and System PDFДокумент144 страницыAce Signal and System PDFYash Rai100% (1)
- 9, Frequency Response 2 Bode Plot PDFДокумент29 страниц9, Frequency Response 2 Bode Plot PDFwasif karimОценок пока нет
- Reliability AllocationДокумент7 страницReliability AllocationoecoepkjОценок пока нет
- Analysis of Vibrational SystemsДокумент4 страницыAnalysis of Vibrational SystemskevweОценок пока нет