Вам также может понравиться
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (344)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (120)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (399)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- Hotel Reservation System ProposalДокумент13 страницHotel Reservation System Proposaltaani_ann56% (9)
- Hotel Reservation System ProposalДокумент13 страницHotel Reservation System Proposaltaani_ann56% (9)
- Hotel Reservation System ProposalДокумент13 страницHotel Reservation System Proposaltaani_ann56% (9)
- Hotel Reservation System ProposalДокумент13 страницHotel Reservation System Proposaltaani_ann56% (9)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- Thermo 5th Chap03P061Документ22 страницыThermo 5th Chap03P061IENCSОценок пока нет
- ProfileДокумент21 страницаProfileAddisuBantayehuОценок пока нет
- Chapter 6Документ14 страницChapter 6AddisuBantayehuОценок пока нет
- Introd Ana System Imple Test Re March April May June July AugustДокумент1 страницаIntrod Ana System Imple Test Re March April May June July AugustAddisuBantayehuОценок пока нет
- Windows Shortcuts Doc Carolyn1Документ2 страницыWindows Shortcuts Doc Carolyn1AddisuBantayehuОценок пока нет
- 4.3 An Application of Binary Trees - Huffman Code ConstructionДокумент2 страницы4.3 An Application of Binary Trees - Huffman Code ConstructionAddisuBantayehuОценок пока нет
- Profile On Water Filter CandlesДокумент21 страницаProfile On Water Filter CandlesAddisuBantayehuОценок пока нет
- Ijiset V1 I9 92 PDFДокумент6 страницIjiset V1 I9 92 PDFsetsuna9993Оценок пока нет
- LicenseДокумент6 страницLicenseanon-764465Оценок пока нет
- Proposal 140914030216 Phpapp02 PDFДокумент8 страницProposal 140914030216 Phpapp02 PDFJonreyLendioLumayagОценок пока нет
- Felege BirhanДокумент2 страницыFelege BirhanAddisuBantayehuОценок пока нет
- Huffman Code - ExampleДокумент1 страницаHuffman Code - ExampleAddisuBantayehuОценок пока нет
- Module Descriptions Bachelor Degree Course:: Electrical Engineering Und Information Technology (B-EI)Документ53 страницыModule Descriptions Bachelor Degree Course:: Electrical Engineering Und Information Technology (B-EI)AddisuBantayehuОценок пока нет
- Ijiset V1 I9 92 PDFДокумент6 страницIjiset V1 I9 92 PDFsetsuna9993Оценок пока нет
- Huffman Code - ExampleДокумент1 страницаHuffman Code - ExampleAddisuBantayehuОценок пока нет
- Project Report Presentation FormatДокумент5 страницProject Report Presentation FormatAddisuBantayehuОценок пока нет
- Hulet Eji EneseДокумент1 страницаHulet Eji EneseAddisuBantayehuОценок пока нет
- Thermal PhysicsДокумент42 страницыThermal Physicskrishkhatri1501Оценок пока нет
- Communication Systems: Phasor & Line SpectraДокумент20 страницCommunication Systems: Phasor & Line SpectraMubashir Ghaffar100% (1)
- Group Theory For Physicists - Christoph LudelingДокумент123 страницыGroup Theory For Physicists - Christoph LudelingteolsukОценок пока нет
- A Comparison Test For Improper IntegralsДокумент4 страницыA Comparison Test For Improper IntegralsGeorge SmithОценок пока нет
- MGT 6203 - Sri - M5 - Treatment Effects v042919Документ21 страницаMGT 6203 - Sri - M5 - Treatment Effects v042919lexleong9610Оценок пока нет
- Solar Radiation Model: L.T. Wong, W.K. ChowДокумент34 страницыSolar Radiation Model: L.T. Wong, W.K. ChowSubhash ChandОценок пока нет
- Speed Controller of Servo Trainer Part 2Документ8 страницSpeed Controller of Servo Trainer Part 2jameswattОценок пока нет
- SubtractorДокумент11 страницSubtractorRocky SamratОценок пока нет
- Weekly QuestionsДокумент6 страницWeekly QuestionsLungsodaan NhsОценок пока нет
- Lesson 2 - Variables and Data TypeДокумент21 страницаLesson 2 - Variables and Data TypeJohn SonОценок пока нет
- Fractions, Decimals, Percents: Learners Module in Business MathematicsДокумент29 страницFractions, Decimals, Percents: Learners Module in Business MathematicsJamaica C. AquinoОценок пока нет
- Developing Health Management Information Systems: A Practical Guide For Developing CountriesДокумент60 страницDeveloping Health Management Information Systems: A Practical Guide For Developing CountriesRahul DharОценок пока нет
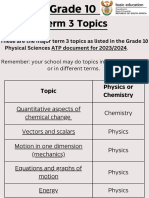
- Grade 10 Term 3 TopicsДокумент10 страницGrade 10 Term 3 TopicsOwamiirh RsaОценок пока нет
- Module 2 Manpower LevelingДокумент24 страницыModule 2 Manpower LevelingrandomstalkingwomenОценок пока нет
- Immediate InferenceДокумент56 страницImmediate InferenceEdgardoОценок пока нет
- Statistics and Aprobability Q3 - Quarterly AssessmentДокумент3 страницыStatistics and Aprobability Q3 - Quarterly AssessmentRomnickCelestinoОценок пока нет
- Chetan PrakashДокумент48 страницChetan PrakashpatrickОценок пока нет
- Attenuation and DispersionДокумент92 страницыAttenuation and Dispersionscribd01Оценок пока нет
- Assignment ModelДокумент3 страницыAssignment ModelSophia April100% (1)
- Chapter 1Документ24 страницыChapter 1Sadam GebiОценок пока нет
- Handout-1 Foundations of SetsДокумент3 страницыHandout-1 Foundations of Setsapi-253679034Оценок пока нет
- Workbook Group TheoryДокумент62 страницыWorkbook Group TheoryLi NguyenОценок пока нет
- C4 Vectors - Vector Lines PDFДокумент33 страницыC4 Vectors - Vector Lines PDFMohsin NaveedОценок пока нет
- XI AssignmentДокумент5 страницXI AssignmentPrashant DangiОценок пока нет
- MMW Chapter 2Документ43 страницыMMW Chapter 2Ada Edaleen A. Diansuy100% (1)
- Bonus LectureДокумент13 страницBonus Lectureminuch00newsОценок пока нет
- Bernoulli Vs Newton: Lift Vs DragДокумент4 страницыBernoulli Vs Newton: Lift Vs DragABHIJEETОценок пока нет
- Gating System Design (HPDC) - C3P SoftwareДокумент6 страницGating System Design (HPDC) - C3P SoftwareIndra Pratap SengarОценок пока нет
- ABSTRACTДокумент41 страницаABSTRACTSaidhaОценок пока нет