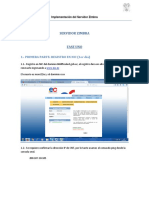
Вам также может понравиться
- Operaciones Con Sistema de RedДокумент7 страницOperaciones Con Sistema de RedByron PuetateОценок пока нет
- SNMP PDFДокумент7 страницSNMP PDFCarlos MayoОценок пока нет
- Control IntegralДокумент9 страницControl IntegralGerardo Arturo Rivera De Santiago100% (1)
- Prácticas de WiresharkДокумент4 страницыPrácticas de WiresharkMario García ToscanoОценок пока нет
- Administración de Imágenes Del IOS de Cisco - CCNA Desde CeroДокумент6 страницAdministración de Imágenes Del IOS de Cisco - CCNA Desde CeroArocha CesarinОценок пока нет
- Listas de Control de Acceso y Vlan-Cap Upla-2009Документ33 страницыListas de Control de Acceso y Vlan-Cap Upla-2009Ronald SotoОценок пока нет
- Capitulo3 - Programación de Comunicaciones en RedДокумент57 страницCapitulo3 - Programación de Comunicaciones en RedJuan PedroОценок пока нет
- Manual Instalacion y Configuracion Zimbra Zcs 8.5.1 OkДокумент18 страницManual Instalacion y Configuracion Zimbra Zcs 8.5.1 OkNelson SupelanoОценок пока нет
- 1.3.1.3 Lab - Mapping The Internet - ResueltoДокумент11 страниц1.3.1.3 Lab - Mapping The Internet - ResueltoJohn Rodriguez100% (1)
- Esquematizacion de Una RedДокумент16 страницEsquematizacion de Una RedBryan TqОценок пока нет
- Entendiendo El Modelo OSIДокумент8 страницEntendiendo El Modelo OSIHerbert Jorge Carrasco ForneОценок пока нет
- Unidad 3 Análisis y Monitoreo Briceño Gamboa Daniel EstebanДокумент8 страницUnidad 3 Análisis y Monitoreo Briceño Gamboa Daniel EstebanDaniel BriceñoОценок пока нет
- tp4 Automatización de TareasДокумент3 страницыtp4 Automatización de TareasFabricio MonteroОценок пока нет
- Seguridad y Alta Disponibilidad Tema2Документ74 страницыSeguridad y Alta Disponibilidad Tema2dfrr2000Оценок пока нет
- T6 Monitorizacion y Uso Del Sistema Operativo PDFДокумент5 страницT6 Monitorizacion y Uso Del Sistema Operativo PDFJCDIОценок пока нет
- Replicación de Base de Datos MysqlДокумент12 страницReplicación de Base de Datos MysqlYaritza Paola ArevaloОценок пока нет
- Servidor ZimbraДокумент24 страницыServidor ZimbraGalo CaisaguanoОценок пока нет
- Preguntas Cap2Документ8 страницPreguntas Cap2Jano Jesus AlexОценок пока нет
- Práctica de Laboratorio 5.6.1Документ9 страницPráctica de Laboratorio 5.6.1tatto1105100% (1)
- Laboratorio No 1 (Wireshark)Документ13 страницLaboratorio No 1 (Wireshark)Franklin Vargas MoriОценок пока нет
- 5.2.1.9 Lab - Researching Network Monitoring Software PDFДокумент3 страницы5.2.1.9 Lab - Researching Network Monitoring Software PDFJuan David OchoaОценок пока нет
- Sistemas ServidoresДокумент29 страницSistemas ServidoresnathaОценок пока нет
- Resumen Capitulo 2 CCNA3Документ12 страницResumen Capitulo 2 CCNA3Denas SenaОценок пока нет
- Configuracion DHCP en RouterДокумент5 страницConfiguracion DHCP en RouterAngel Ren Hero SaranghaeОценок пока нет
- Formato Del Paquete IPДокумент30 страницFormato Del Paquete IPJose Mauricio Bravo BaqueОценок пока нет
- Chat Con SocketsДокумент4 страницыChat Con SocketsDaniel Rocabado RojasОценок пока нет
- 11 6 1Документ4 страницы11 6 1afserrano4100% (2)
- Laboratorio 11 - Servidor Samba Como AD DCДокумент12 страницLaboratorio 11 - Servidor Samba Como AD DCGodolfredo Noa TaparacoОценок пока нет
- 1 - Herramientas de MonitoreoДокумент22 страницы1 - Herramientas de MonitoreoK-ren PàezОценок пока нет
- Practica WiresharkДокумент14 страницPractica Wiresharkjhoan sebastian campos castroОценок пока нет
- Diseño e Implementación de Un Esquema de Direccionamiento VLSM TopologíaДокумент7 страницDiseño e Implementación de Un Esquema de Direccionamiento VLSM TopologíaAna Carolina Melendez MontesОценок пока нет
- CCNA4 Lab 5 2 5 EsДокумент7 страницCCNA4 Lab 5 2 5 EsBorjaUndaОценок пока нет
- Control IntegralДокумент5 страницControl IntegralLeonardo Risco TantajulcaОценок пока нет
- Resumen SISTEMAS OPERATIVOS Momento 1 PDFДокумент7 страницResumen SISTEMAS OPERATIVOS Momento 1 PDFÁngela PoláОценок пока нет
- Configuracin DHCP Server PDFДокумент4 страницыConfiguracin DHCP Server PDFAlberto RiveraОценок пока нет
- 1.2 Configuración de Servidores LanДокумент18 страниц1.2 Configuración de Servidores LanKatia Rubit Benitez Castro50% (2)
- Taller Redes SDNДокумент26 страницTaller Redes SDNJhon Janer100% (2)
- Examen de Prueba Preliminar de CN Cisco v5.0Документ10 страницExamen de Prueba Preliminar de CN Cisco v5.0Omar Garcia50% (2)
- Arquitecturas de Gestión de RedДокумент17 страницArquitecturas de Gestión de Redhelfa31100% (3)
- Reporte Practica No. 2 REDESДокумент7 страницReporte Practica No. 2 REDESLudKaf0% (1)
- Implementacion - Proxy en Distribución - Zentyal - 38110Документ68 страницImplementacion - Proxy en Distribución - Zentyal - 38110johana55Оценок пока нет
- Ejercicios Redes Tema 2Документ2 страницыEjercicios Redes Tema 2christianОценок пока нет
- Formato Factibilidad IntranetДокумент5 страницFormato Factibilidad IntranetCamilo Andrés Díaz SerranoОценок пока нет
- T-2 Practica 10 WiresharkДокумент26 страницT-2 Practica 10 WiresharkPerla Jennifer Mendoza MartinezОценок пока нет
- PKT9 7 1Документ4 страницыPKT9 7 1Raul FeroОценок пока нет
- Resolución de La Guia Numero 1Документ13 страницResolución de La Guia Numero 1joseОценок пока нет
- Capa de Transporte Del Modelo OSIДокумент24 страницыCapa de Transporte Del Modelo OSIMonica SilvaОценок пока нет
- Unidad 4 Configuracion de Protocolos Vector DistanciaДокумент20 страницUnidad 4 Configuracion de Protocolos Vector DistanciaDiego Galindo100% (1)
- 072 Gestion de Redes Con SNMP PDFДокумент15 страниц072 Gestion de Redes Con SNMP PDFajmq1986Оценок пока нет
- Tesis VPN SSLДокумент11 страницTesis VPN SSLHèctor EaОценок пока нет
- Subnetting SupernettingДокумент6 страницSubnetting SupernettingKevin BarjaОценок пока нет
- Redes ATMДокумент15 страницRedes ATMWalter Lopez “Walter36Prof”Оценок пока нет
- Comandos Configuración VPN Server Packet TracerДокумент3 страницыComandos Configuración VPN Server Packet TracerJohn Sharp100% (1)
- CainДокумент1 страницаCainHenry RodriguezbОценок пока нет
- Gestión de Red SimpleДокумент6 страницGestión de Red SimpleOscar MartinezОценок пока нет
- Manual SNMPДокумент9 страницManual SNMPchavarryaОценок пока нет
- Trabajo de InvestigaciónДокумент2 страницыTrabajo de Investigaciónkatherine FajardoОценок пока нет
- Unidad 3Документ15 страницUnidad 3Kerick KingОценок пока нет
- SNMP GeneralidadesДокумент17 страницSNMP Generalidadeskaly20Оценок пока нет
- Comando - SNMPДокумент10 страницComando - SNMPfÑancupilОценок пока нет
- Concentrum, Plus y Orbit - Equipamiento Modular para GinecologíaДокумент72 страницыConcentrum, Plus y Orbit - Equipamiento Modular para GinecologíaSamantha LópezОценок пока нет
- Adalid ContrerasДокумент2 страницыAdalid ContrerasIsa AráozОценок пока нет
- INFORME Eje Levas MotoresДокумент4 страницыINFORME Eje Levas MotoresPatty CondoriОценок пока нет
- Proyecto TecnológicoДокумент3 страницыProyecto TecnológicoLaura GonzalezОценок пока нет
- Campo de Chuchupa PDFДокумент16 страницCampo de Chuchupa PDFXime GomezОценок пока нет
- Nuevo Formato Salud AllianzДокумент3 страницыNuevo Formato Salud AllianzDavid FajardoОценок пока нет
- Caso CompaqДокумент2 страницыCaso CompaqEUJ2011Оценок пока нет
- Cot.179-MAJ-19 CELDAS QM +SM6 (ABB) +TRANSFORMADOR SECO 315KVA, 10-0.398-0.23 KV, CELDA ENVOLVENTE + TRAFORMIX ING. GUTIERREZ - PUNOДокумент5 страницCot.179-MAJ-19 CELDAS QM +SM6 (ABB) +TRANSFORMADOR SECO 315KVA, 10-0.398-0.23 KV, CELDA ENVOLVENTE + TRAFORMIX ING. GUTIERREZ - PUNOCesarCondoriОценок пока нет
- Mec LocДокумент33 страницыMec LocLauraОценок пока нет
- 87 10383 RevA SPau HFC 090828 Espanol PDFДокумент96 страниц87 10383 RevA SPau HFC 090828 Espanol PDFVíctor MayaОценок пока нет
- Auditoria y Revisión de La Alta Dirección Del Sistema de Gestión de Seguridad y Salud en El Trabajo SG-SST. Foro 4 SemanaДокумент1 страницаAuditoria y Revisión de La Alta Dirección Del Sistema de Gestión de Seguridad y Salud en El Trabajo SG-SST. Foro 4 SemanaAngie RojasОценок пока нет
- Ley Del Contrato de Seguro y Reglamentos Relacionados - 2021Документ40 страницLey Del Contrato de Seguro y Reglamentos Relacionados - 2021Luz Marina Suarez LlerenaОценок пока нет
- Produccion 1 Eje 3Документ7 страницProduccion 1 Eje 3Jeison MaciasОценок пока нет
- B.ppto General TRES VALLESДокумент30 страницB.ppto General TRES VALLESMgraciela Quispe GutОценок пока нет
- Ejercicio El Industrial (Estado de Perdidas y Ganancias)Документ9 страницEjercicio El Industrial (Estado de Perdidas y Ganancias)copgo6iОценок пока нет
- Evidencia-2-Instalacion y Prueba FuncionalДокумент11 страницEvidencia-2-Instalacion y Prueba Funcionaldiego collazosОценок пока нет
- Syllabus Curso Metodologia de La InvestigacionДокумент13 страницSyllabus Curso Metodologia de La Investigacionluis gabrielОценок пока нет
- 05 Herramientas CatapultaДокумент39 страниц05 Herramientas CatapultaCarlos Luque ViveroОценок пока нет
- La Organización Del FuturoДокумент9 страницLa Organización Del FuturoRODRIGOОценок пока нет
- Tesis CapriДокумент84 страницыTesis CapriIleana Fernandez100% (2)
- Practica #3 - Mecanismos Del AutomovilДокумент3 страницыPractica #3 - Mecanismos Del AutomovilCristian Najar OcharanОценок пока нет
- Calificación de AuditoresДокумент2 страницыCalificación de AuditoresJorge L. OlmedoОценок пока нет
- Aluminio en Py Bienvenido 2Документ2 страницыAluminio en Py Bienvenido 2Guillermo Lopez-FloresОценок пока нет
- 13 WWW - Unx.mx: Ver ExplicaciónДокумент3 страницы13 WWW - Unx.mx: Ver ExplicaciónAbraham Priego FernandezОценок пока нет
- PDF Lab 2 Resonancia DDДокумент39 страницPDF Lab 2 Resonancia DDTheDroidDrummer0% (1)
- Informe TG2 CT Aguaytia PDFДокумент105 страницInforme TG2 CT Aguaytia PDFMarkoQuispeОценок пока нет
- Ejemplo de Proyecto Beca Condonable IcetexДокумент8 страницEjemplo de Proyecto Beca Condonable IcetexCristhian Hurtado MelgarОценок пока нет
- Unidad III. Interés CompuestoДокумент29 страницUnidad III. Interés CompuestoJon NievesОценок пока нет
- Elaboracion de Alimento para GanadoДокумент11 страницElaboracion de Alimento para GanadoMarcelo Marquina100% (4)
- Corrupción, Metafora de AmbiciónДокумент3 страницыCorrupción, Metafora de AmbiciónFernanda Latorre BermúdezОценок пока нет