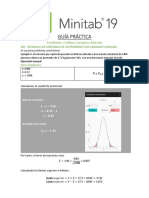
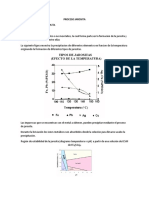
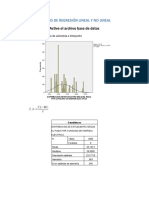
Вам также может понравиться
- PROB Y EST UNIDAD II Agosto 2019 Parte 2Документ34 страницыPROB Y EST UNIDAD II Agosto 2019 Parte 2Robert Rosas AgОценок пока нет
- Introducción a la programación estructurada con CДокумент4 страницыIntroducción a la programación estructurada con CJarboledaHОценок пока нет
- Unidad 2-Funciones VectorialesДокумент21 страницаUnidad 2-Funciones Vectoriales《SIN- NOMBRE》Оценок пока нет
- Prueba de Normalidad Jarque VeraДокумент2 страницыPrueba de Normalidad Jarque VeraMoisés Ríos RamosОценок пока нет
- Deteccion de OutliersДокумент43 страницыDeteccion de OutliersafsdhfkhsjdfОценок пока нет
- Informe Planta de VelocidadДокумент8 страницInforme Planta de VelocidadIsabel ArguelloОценок пока нет
- Distribución normal aplicacionesДокумент7 страницDistribución normal aplicacionesMiranda PérezОценок пока нет
- Evaluacion de Estadistica I Segundo ParcialДокумент4 страницыEvaluacion de Estadistica I Segundo ParcialFredy HernandezОценок пока нет
- An Introduction To ExcelДокумент10 страницAn Introduction To ExcelJairo Ruiz ChuquillanquiОценок пока нет
- Heterocedasticidad en importaciones del Perú (1990-2018Документ8 страницHeterocedasticidad en importaciones del Perú (1990-2018Kevinn PiñasОценок пока нет
- Prácticas SQL - MysqlДокумент11 страницPrácticas SQL - MysqlAnonymous R9tLTJtJoОценок пока нет
- Métodos de ajuste en regresión no linealДокумент20 страницMétodos de ajuste en regresión no linealCielo Isabel Suarez GameroОценок пока нет
- Distr Normal Prba NormalidadДокумент14 страницDistr Normal Prba NormalidadManuel Alejandro Cordero PenagosОценок пока нет
- Curso Basico de UNIXДокумент128 страницCurso Basico de UNIXvick619Оценок пока нет
- Guia de LaboratorioДокумент3 страницыGuia de LaboratorioNemuel LopezОценок пока нет
- Problemas VectoresДокумент9 страницProblemas VectoresIsabel CárdenasОценок пока нет
- Modelos Matematicos de La Fisiologia RespiratoriaДокумент5 страницModelos Matematicos de La Fisiologia RespiratoriaKimberly Villanueva RosalesОценок пока нет
- Actividad 3Документ4 страницыActividad 3KAREN YIRLEY JIMENEZ RODRIGUEZОценок пока нет
- No Central ChiДокумент5 страницNo Central ChiaracelytorresОценок пока нет
- Teoria de SistemasДокумент11 страницTeoria de SistemasUnited AppОценок пока нет
- 03 Ecuaciones DiferencialesДокумент4 страницы03 Ecuaciones DiferencialesJCMarisolОценок пока нет
- Practica 2 - Ayudantia - InF273Документ5 страницPractica 2 - Ayudantia - InF273IVONNE LORENA CASTRO SALASОценок пока нет
- Distribuciones de ProbabilidadДокумент235 страницDistribuciones de ProbabilidadMoon Oig100% (1)
- Modelo de Datos Espaciales PDFДокумент5 страницModelo de Datos Espaciales PDFYerzyd AlconОценок пока нет
- Problemario Unidad 1Документ11 страницProblemario Unidad 1Diana CasanovaОценок пока нет
- Guía para El Uso de R CommanderДокумент10 страницGuía para El Uso de R CommanderJavierBertelОценок пока нет
- Modelo No Lineal en EviewsДокумент5 страницModelo No Lineal en EviewsJeferson Ruiz.Оценок пока нет
- Laboratorio de Ejercicios-EstadisticaДокумент11 страницLaboratorio de Ejercicios-EstadisticaManuel Bautista castañeda67% (3)
- Regresion No LinealДокумент32 страницыRegresion No LinealEdson Valery Ramos PeñalozaОценок пока нет
- Ayala - Martha - Medidas de Tendencia Central y de Dispersión para Datos No Agrupados.Документ6 страницAyala - Martha - Medidas de Tendencia Central y de Dispersión para Datos No Agrupados.Yoselin AyalaОценок пока нет
- 4.3.2 Representación de Expresiones Booleanas Con Circuitos LógicosДокумент7 страниц4.3.2 Representación de Expresiones Booleanas Con Circuitos LógicosVictor Alberto Garcia ArizpeОценок пока нет
- Polinomio de Newton Diferencias FinitasДокумент16 страницPolinomio de Newton Diferencias FinitasDanielQC0% (3)
- Correlación de Datos BivariadosДокумент56 страницCorrelación de Datos Bivariadosbioestadistica5407Оценок пока нет
- Resumen Unidad 4 AlgebraДокумент10 страницResumen Unidad 4 AlgebraMisael NavaОценок пока нет
- 08 Estimacion de La Varianza PoblacionalДокумент17 страниц08 Estimacion de La Varianza PoblacionalDelsyОценок пока нет
- CURSO - ANALISIS ESTAD+ìSTICO DE DATOS USANDO RДокумент99 страницCURSO - ANALISIS ESTAD+ìSTICO DE DATOS USANDO RJulia Patricia Malca SanchezОценок пока нет
- Semana04 - Método Newton - Raphson - AplicacionesДокумент37 страницSemana04 - Método Newton - Raphson - AplicacionesJuan Jesús Soria QuijaiteОценок пока нет
- Informe LOTДокумент18 страницInforme LOTJonathan MeraОценок пока нет
- Planificación de ProcesosДокумент7 страницPlanificación de ProcesosXdarklordXОценок пока нет
- Ejercicios RegresionДокумент11 страницEjercicios RegresionLeyla Lizet Sandoval BarretoОценок пока нет
- Practica 1 Introduccion A Matlab SimulinkДокумент11 страницPractica 1 Introduccion A Matlab SimulinkJosé MiguelОценок пока нет
- Taller Metodos Numericos 2Документ3 страницыTaller Metodos Numericos 2Moncho Corpus SanctumОценок пока нет
- CP2Документ2 страницыCP2David montoyaОценок пока нет
- Practica NormalizacionДокумент2 страницыPractica NormalizacionAlex Elvis Gonzalez Rabaquino100% (1)
- Metodos Numericos, Gauss-Seidel, Jacobi y OtrosДокумент33 страницыMetodos Numericos, Gauss-Seidel, Jacobi y OtrosOscar Fernando Chevarria MezaОценок пока нет
- Practica MinitabДокумент17 страницPractica MinitabMarcelo OrellanaОценок пока нет
- GEPB0O154Документ2 страницыGEPB0O154David LLontopОценок пока нет
- Examen Final MD Fiis - Unac 2021-BДокумент3 страницыExamen Final MD Fiis - Unac 2021-BKelvin Hagler0% (1)
- Propiedades de Los LogaritmosДокумент5 страницPropiedades de Los LogaritmosMarcosОценок пока нет
- Métodos numéricos para resolver ecuaciones y sistemas - Trabajo 1Документ19 страницMétodos numéricos para resolver ecuaciones y sistemas - Trabajo 1Juan FelipeОценок пока нет
- Tarea3 Regresion - PsДокумент16 страницTarea3 Regresion - PsJosé Daniel Rivera MedinaОценок пока нет
- Simulacion de Sistemas Dinamicos Con SimulinkДокумент40 страницSimulacion de Sistemas Dinamicos Con Simulinkmanu79_7Оценок пока нет
- Cuadrado Grecolatino .XLSX - Buscar Con GoogleДокумент1 страницаCuadrado Grecolatino .XLSX - Buscar Con GoogleADRIAN URREGOОценок пока нет
- Tarea - Ejercicio Práctico de Prueba de Hipótesis y Análisis de ColinealidadДокумент6 страницTarea - Ejercicio Práctico de Prueba de Hipótesis y Análisis de ColinealidadmargaritaОценок пока нет
- Texto Ing. Lazo Calculo 2Документ89 страницTexto Ing. Lazo Calculo 2Roberto Aguilar HidalgoОценок пока нет
- Taller CrecimientoДокумент9 страницTaller CrecimientoJharid HernandezОценок пока нет
- TRABAJO FINAL- METODOLOGIA BOX-JENKINSДокумент27 страницTRABAJO FINAL- METODOLOGIA BOX-JENKINSjuancamilomillan22Оценок пока нет
- Informe de Validación Cobre TotalДокумент18 страницInforme de Validación Cobre TotaleggxmenОценок пока нет
- T2 P2 Santelices CarlosДокумент8 страницT2 P2 Santelices CarlosCarlos Santelices GómezОценок пока нет
- Introducción al análisis estadístico multivariado aplicado: Experiencia y casos en el Caribe colombianoОт EverandIntroducción al análisis estadístico multivariado aplicado: Experiencia y casos en el Caribe colombianoРейтинг: 5 из 5 звезд5/5 (2)
- LixiviacionДокумент7 страницLixiviacionalbertОценок пока нет
- Floc Flotacion de MalaquitaДокумент11 страницFloc Flotacion de MalaquitaFlia Diaz Zuniga100% (1)
- Milpo Memoria Anual 2007Документ121 страницаMilpo Memoria Anual 2007Ana Abanto AraujoОценок пока нет
- Reactivos QuimicosДокумент150 страницReactivos Quimicoscarlos50% (2)
- Lixiviacion de Cobre Coro CoroДокумент248 страницLixiviacion de Cobre Coro CoroJose Arias100% (1)
- Lixiviación de cobre con soluciones ácidasДокумент4 страницыLixiviación de cobre con soluciones ácidasalbertОценок пока нет
- ProcesoJarositaДокумент2 страницыProcesoJarositaalbertОценок пока нет
- EntropíaДокумент2 страницыEntropíaalbertОценок пока нет
- RLMM Art 82v2n1 p21Документ30 страницRLMM Art 82v2n1 p21albertОценок пока нет
- Hidrometalurgia de SulfurosДокумент6 страницHidrometalurgia de Sulfuroseder_1Оценок пока нет
- Higiene Ocupacional en El D.S. #024-2016-EM: Ing. Luz Bancayán HinostrozaДокумент62 страницыHigiene Ocupacional en El D.S. #024-2016-EM: Ing. Luz Bancayán HinostrozaCesarОценок пока нет
- Aplicaciones de La DerivadaДокумент29 страницAplicaciones de La DerivadaMaribaby GuzanithaОценок пока нет
- Apuntes Hierro Carbono (II)Документ10 страницApuntes Hierro Carbono (II)ninoghgОценок пока нет
- CobreДокумент115 страницCobreRommel Cm'Оценок пока нет
- Análisis de FactoresДокумент14 страницAnálisis de Factoresjustorfc100% (1)
- Higiene Ocupacional en El D.S. #024-2016-EM: Ing. Luz Bancayán HinostrozaДокумент62 страницыHigiene Ocupacional en El D.S. #024-2016-EM: Ing. Luz Bancayán HinostrozaCesarОценок пока нет
- Ajuste de Curva SnapStatДокумент8 страницAjuste de Curva SnapStatjustorfcОценок пока нет
- Libro de HidrometalurgiaДокумент169 страницLibro de Hidrometalurgiadiko100% (1)
- Bloque 3.2 ZincДокумент30 страницBloque 3.2 ZincClever Jhon Rojas BerrospiОценок пока нет
- Disposicion de RelavesДокумент39 страницDisposicion de RelavesJesús Guzmán LavaОценок пока нет
- Preparación de muestras metalográficas para análisis microscópicoДокумент50 страницPreparación de muestras metalográficas para análisis microscópico087kelly100% (2)
- Paper Lixiviacion en Pilas y BateasДокумент8 страницPaper Lixiviacion en Pilas y BateasKeno Contreras VilchesОценок пока нет
- Preparación de muestras metalográficas para análisis microscópicoДокумент50 страницPreparación de muestras metalográficas para análisis microscópico087kelly100% (2)
- Reglamento de Seguridad y Salud Ocupacional en Minería DS 024 2016 EM PDFДокумент57 страницReglamento de Seguridad y Salud Ocupacional en Minería DS 024 2016 EM PDFdiana saida mullisaca sonccoОценок пока нет
- Análisis de Capabilidad-VariablesДокумент31 страницаAnálisis de Capabilidad-Variablesjustorfc0% (2)
- Ajustando Distribución (Datos No Censurados)Документ27 страницAjustando Distribución (Datos No Censurados)justorfc100% (2)
- Ajustando Distribución (Datos No Censurados)Документ27 страницAjustando Distribución (Datos No Censurados)justorfc100% (2)
- Tabulacion CruzadaДокумент10 страницTabulacion CruzadaCan Tkm JoshelitoОценок пока нет
- Hamlet 2Документ6 страницHamlet 2albertОценок пока нет
- Investigacion CorrelacionalДокумент6 страницInvestigacion CorrelacionalFrank Euler Jibaja RamírezОценок пока нет
- Proyecto Shumba - PresentacionДокумент33 страницыProyecto Shumba - PresentacionIVAN NERIO DE LA CRUZОценок пока нет
- Investigación - Centro de Recursos en LíneaДокумент381 страницаInvestigación - Centro de Recursos en LíneaTetesitaAchocolatadita98% (42)
- Diagrama de dispersión: definición, pasos, interpretación y coeficiente de correlaciónДокумент19 страницDiagrama de dispersión: definición, pasos, interpretación y coeficiente de correlaciónTirza Abigail PadillaОценок пока нет
- Material+de+apoyo+unidad+dos+semana+2+cap +2+texto+cpa3+ AluДокумент18 страницMaterial+de+apoyo+unidad+dos+semana+2+cap +2+texto+cpa3+ AluAdonis MaquinОценок пока нет
- Correlación y Regresión Lineal Alumnos ClaseДокумент13 страницCorrelación y Regresión Lineal Alumnos ClasewysheidОценок пока нет
- In PRG AnaliticoДокумент188 страницIn PRG AnaliticoRolo NinaОценок пока нет
- Analisis de SenderosДокумент14 страницAnalisis de SenderosMaryEuContrerasОценок пока нет
- Practica 2 Estadistica Descriptiva BidimensionalДокумент19 страницPractica 2 Estadistica Descriptiva BidimensionalJenОценок пока нет
- 2 Solemne Finanzas II - Pauta - 1Документ3 страницы2 Solemne Finanzas II - Pauta - 1sofiaОценок пока нет
- Simulacion Papeleria CompletoДокумент78 страницSimulacion Papeleria CompletoCitlalii GarciiaОценок пока нет
- Uso de La Calculadora - Parte 3 Ajuste de Curvas - ActualizadaДокумент11 страницUso de La Calculadora - Parte 3 Ajuste de Curvas - ActualizadaFrancisco CastroОценок пока нет
- Escala de Conducta Disocial PDFДокумент28 страницEscala de Conducta Disocial PDFjose_vent16416100% (2)
- Metodo de Analisis de DatosДокумент4 страницыMetodo de Analisis de DatosWalter Manuel Vasquez MondragonОценок пока нет
- Introducción Abel 04 Modificado FinalДокумент28 страницIntroducción Abel 04 Modificado FinalVilelaGuevaraFiorellaОценок пока нет
- Proakis Ejercicios Cap 2Документ12 страницProakis Ejercicios Cap 2Anonymous yeTg3p1faHОценок пока нет
- Asimetría EstadísticaДокумент12 страницAsimetría EstadísticaJuan K. Gonzalez100% (4)
- PearsonДокумент10 страницPearsonAnibal Mejia BenavidesОценок пока нет
- Laboratorio Con SolucionДокумент11 страницLaboratorio Con SolucionJims Poma VilcahuamanОценок пока нет
- Examen Final Estadistica I AsturiasДокумент13 страницExamen Final Estadistica I AsturiasJ. E.94% (32)
- Tarea Medidas de Forma y RegresiónДокумент2 страницыTarea Medidas de Forma y Regresióniran choqueОценок пока нет
- Niveles de Investigación CientíficaДокумент13 страницNiveles de Investigación Científicashinidragon1Оценок пока нет
- Resumen Capitulo 10 Administración FinancieraДокумент7 страницResumen Capitulo 10 Administración FinancieraDianisieОценок пока нет
- Lv2013 Finanzas InterДокумент349 страницLv2013 Finanzas InterJavier Andrés Tinoco MarínОценок пока нет
- 6-Analisis MultivarianteДокумент26 страниц6-Analisis MultivarianteJoseОценок пока нет
- Medidas de Asociación Diseños ExpДокумент3 страницыMedidas de Asociación Diseños ExpJonatan JiménezОценок пока нет
- Actividad 7Документ4 страницыActividad 7Angie Tatiana Sánchez CanoОценок пока нет
- Rme Geocontrol Bieniawski CeladaДокумент6 страницRme Geocontrol Bieniawski CeladaalanОценок пока нет
- Pobre ZaДокумент540 страницPobre ZaEdgardo Olmedo SotomayorОценок пока нет
- Informe RocplaneДокумент16 страницInforme RocplaneAldo Ccahuana YanquiОценок пока нет