Вам также может понравиться
- IT6006 Data Analytics Clustering Techniques Partitioning and Hierarchical MethodsДокумент27 страницIT6006 Data Analytics Clustering Techniques Partitioning and Hierarchical Methodsemperor penguinОценок пока нет
- ClusteringДокумент61 страницаClusteringRashul ChutaniОценок пока нет
- Dbscan: Presented By: Garrett PoppeДокумент22 страницыDbscan: Presented By: Garrett PoppeShivani ChandelОценок пока нет
- Clustters AlgorithmДокумент20 страницClustters AlgorithmbhaskarОценок пока нет
- Module5 - Outlier - Analysis: Reference: "Data Mining The Text Book", Charu C. Aggarwal, Springer, 2015. (Chapters 8)Документ21 страницаModule5 - Outlier - Analysis: Reference: "Data Mining The Text Book", Charu C. Aggarwal, Springer, 2015. (Chapters 8)Rohith RohОценок пока нет
- Clustering Partitioning MethodsДокумент20 страницClustering Partitioning Methods2K19/BMBA/13 RITIKAОценок пока нет
- Cluster Analysis - Approach 1Документ28 страницCluster Analysis - Approach 1Charan NaiduОценок пока нет
- CT075!3!2 DTM Topic 10 Cluster AnalysisДокумент21 страницаCT075!3!2 DTM Topic 10 Cluster Analysiskishanselvarajah80Оценок пока нет
- 8.hierarchical AGNES DIANAДокумент46 страниц8.hierarchical AGNES DIANAShreyas ParajОценок пока нет
- What Is Cluster Analysis?: - Cluster: A Collection of Data ObjectsДокумент77 страницWhat Is Cluster Analysis?: - Cluster: A Collection of Data ObjectsChristopherОценок пока нет
- Self Esteem Basic SheetДокумент1 страницаSelf Esteem Basic SheetLoОценок пока нет
- Lecture 13Документ45 страницLecture 13zafar.phdcs82Оценок пока нет
- ClusteringДокумент125 страницClusteringFariya AfrinОценок пока нет
- Ludwig The Holy BladeДокумент3 страницыLudwig The Holy BladeGabriel PortoОценок пока нет
- 4.3 K-MedoidsДокумент31 страница4.3 K-MedoidsPynshngainОценок пока нет
- TreeДокумент18 страницTreealiОценок пока нет
- Lecture 3 - Herirachical MethodsДокумент16 страницLecture 3 - Herirachical MethodsManikandan MОценок пока нет
- ClusterДокумент20 страницClustersondaravalliОценок пока нет
- Improv Intro Fusion Tk1: Cracking The Code: Oz Noy Interview 1Документ3 страницыImprov Intro Fusion Tk1: Cracking The Code: Oz Noy Interview 1Carlos Iafelice Junior Musica e LazerОценок пока нет
- Oz Noy Interview Fusion ImprovДокумент3 страницыOz Noy Interview Fusion ImprovGenaro OlivieriОценок пока нет
- DM Lec 14 Clustering-II - KmedoidДокумент15 страницDM Lec 14 Clustering-II - KmedoidJAMEEL AHMADОценок пока нет
- Child Stuttering Severity Chart v2 Dec 2022Документ1 страницаChild Stuttering Severity Chart v2 Dec 2022Sana AlviОценок пока нет
- Depreciation SchedulesДокумент1 страницаDepreciation SchedulesMary100% (1)
- ClusteringДокумент84 страницыClusteringmanmeet singh tutejaОценок пока нет
- Rey PicadoДокумент1 страницаRey Picadolee geddyОценок пока нет
- Wasting Love Benato PDFДокумент7 страницWasting Love Benato PDFrafael benatoОценок пока нет
- Numerical Methods For PDEs (Upto Tenth or Higher Order), Edition 1, 2021Документ10 страницNumerical Methods For PDEs (Upto Tenth or Higher Order), Edition 1, 2021N. T. DadlaniОценок пока нет
- Count Watches, Pens and QuailsДокумент1 страницаCount Watches, Pens and QuailsAnniemah UsmanОценок пока нет
- Boiler EquationsДокумент155 страницBoiler Equationspulakjaiswal85Оценок пока нет
- Table of Specification - ToS TABLE - Sample Template (Excel Format) v2Документ2 страницыTable of Specification - ToS TABLE - Sample Template (Excel Format) v2Eric Orquista67% (3)
- Productivity Planner A3Документ1 страницаProductivity Planner A3Rohit SharmaОценок пока нет
- Clustering Data MiningДокумент27 страницClustering Data MiningAndrewОценок пока нет
- 4A. 2017 Lecture 4 Monte Carlo HW4 0304Документ21 страница4A. 2017 Lecture 4 Monte Carlo HW4 0304Kurniasari FitriaОценок пока нет
- Measure The Following Objects:: ExampleДокумент5 страницMeasure The Following Objects:: Examplemomztutelage4182Оценок пока нет
- Napoleon Coste Andante in DmДокумент2 страницыNapoleon Coste Andante in DmTom EdskesОценок пока нет
- Asbuild Drawing Ipal TinondoДокумент12 страницAsbuild Drawing Ipal TinondoVerdy SaputraОценок пока нет
- M16A2 TargetДокумент1 страницаM16A2 Targetdeolexrex100% (6)
- IPAL Point Monitoring at Lalolae Health CenterДокумент12 страницIPAL Point Monitoring at Lalolae Health CenterVerdy SaputraОценок пока нет
- Kami Export - K - G - K - SCH - anVzdGluLmZsdWhhcnR5QG92aWRlbHNpZS5vcmc - MMM - 2021Документ1 страницаKami Export - K - G - K - SCH - anVzdGluLmZsdWhhcnR5QG92aWRlbHNpZS5vcmc - MMM - 2021Travis WrightОценок пока нет
- Table of TimeДокумент1 страницаTable of TimeMiguel BenitoОценок пока нет
- Part Part Whole Assessments or WorksheetsДокумент4 страницыPart Part Whole Assessments or WorksheetsDinDinОценок пока нет
- Transform Your Well-Being with the Wheel of Life ExerciseДокумент2 страницыTransform Your Well-Being with the Wheel of Life ExercisePooja Punjabi100% (1)
- خلي - بالك - من - عقلك جيتارДокумент1 страницаخلي - بالك - من - عقلك جيتارMena E. NasryОценок пока нет
- Wks. 2.2 - Standard Form of Quad EqДокумент2 страницыWks. 2.2 - Standard Form of Quad EqSusie GreenОценок пока нет
- 1 SubtractionДокумент1 страница1 SubtractionNaNa NaNaОценок пока нет
- NUMERATION SYSTEMS EXPLAINEDДокумент21 страницаNUMERATION SYSTEMS EXPLAINEDrvedОценок пока нет
- 7D cinema floor planДокумент1 страница7D cinema floor planFawad jamshidiОценок пока нет
- Construction of DOH Provincial Office BuildingДокумент1 страницаConstruction of DOH Provincial Office BuildingHerbee ZevlagОценок пока нет
- C Major Scale All PositionsДокумент2 страницыC Major Scale All PositionsjosebussoОценок пока нет
- Cluster Analysis Methods and TechniquesДокумент19 страницCluster Analysis Methods and TechniquesManikandan MОценок пока нет
- MRAD 100 Yard Zero TargetДокумент1 страницаMRAD 100 Yard Zero TargetEnivan Gentil BarraganОценок пока нет
- Gloria Al Nino Ricardo by Paco de LuciaДокумент15 страницGloria Al Nino Ricardo by Paco de Lucialove mursyid100% (1)
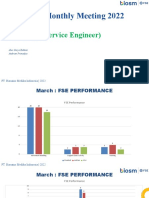
- Laporan FSE Maret 2022Документ13 страницLaporan FSE Maret 2022Andre PrimaОценок пока нет
- Colour FamilyДокумент1 страницаColour FamilynitaОценок пока нет
- TURMAДокумент3 страницыTURMAkarin gasserОценок пока нет
- (Almaran) Historia de Un Amor 2 (TAB)Документ4 страницы(Almaran) Historia de Un Amor 2 (TAB)Luis Alberto RameixОценок пока нет
- Meters The-Cissy StrutДокумент3 страницыMeters The-Cissy StrutEmanuele Clemente SkinnyОценок пока нет
- 2 - More or LessДокумент1 страница2 - More or LessYuyu Dewi AnggreiniОценок пока нет
- Manual de Derecho AdministrativoДокумент5 страницManual de Derecho AdministrativoMarvin DanielОценок пока нет
- Padasalai Net Accountancy English 11th Publich Exam Model Question PaperДокумент12 страницPadasalai Net Accountancy English 11th Publich Exam Model Question PaperAdalberto Macdonald100% (2)
- TLE Assessment on Technical Drafting Tool SafetyДокумент3 страницыTLE Assessment on Technical Drafting Tool SafetyMa Rieza FatallaОценок пока нет
- EPS PASSERS INFORMATIONДокумент2 страницыEPS PASSERS INFORMATIONRoxanne BorlonganОценок пока нет
- Bahauddin Zakariya University Fee Deposit ChallanДокумент1 страницаBahauddin Zakariya University Fee Deposit ChallanAbdul WahidОценок пока нет
- Multiple ChoiceДокумент61 страницаMultiple ChoiceDenaiya Watton Leeh100% (7)
- HP PSC 2210 - Press Enter To Align Cartridges - HP® Customer SupportДокумент7 страницHP PSC 2210 - Press Enter To Align Cartridges - HP® Customer Supportanon_567508053Оценок пока нет
- Keenpac in Detail Issue 3Документ8 страницKeenpac in Detail Issue 3Benjamin RamirezОценок пока нет
- CELIO - INS-QUAL-CI-006-Version A-Chap.6-EN-BOX PACKAGINGДокумент23 страницыCELIO - INS-QUAL-CI-006-Version A-Chap.6-EN-BOX PACKAGINGDebashishDolonОценок пока нет
- ITB-Sect 1 - 15247Документ29 страницITB-Sect 1 - 15247hash117Оценок пока нет
- LabelДокумент6 страницLabelHey GotemОценок пока нет
- Twin Wire Formers ExplainedДокумент10 страницTwin Wire Formers ExplainedArunPThomasОценок пока нет
- Design Technology Higher Level and Standard Level Paper 2: Instructions To CandidatesДокумент24 страницыDesign Technology Higher Level and Standard Level Paper 2: Instructions To Candidatesmanuela corralesОценок пока нет
- Rationale (Brochure)Документ1 страницаRationale (Brochure)Chariz CasidsidОценок пока нет
- Rizal National High School RFQ for Epson PrintersДокумент3 страницыRizal National High School RFQ for Epson PrintersPau PerezОценок пока нет
- ENTREPRENEURSHIP PERFORMANCE TASKS Quarter 1 PDFДокумент2 страницыENTREPRENEURSHIP PERFORMANCE TASKS Quarter 1 PDFKurt Karl GuinesОценок пока нет
- Country Paper Native Abaca Bags Export To FranceДокумент35 страницCountry Paper Native Abaca Bags Export To FranceCharlene MamantaОценок пока нет
- Parking MapДокумент2 страницыParking MapDonjОценок пока нет
- TQM Old ToolsДокумент69 страницTQM Old ToolsnavadithaОценок пока нет
- 2018-2019 Work Immersion PlanДокумент4 страницы2018-2019 Work Immersion PlanDonny BuenoОценок пока нет
- Epson T-Series Brochure PDFДокумент8 страницEpson T-Series Brochure PDFNair YadukrishnanОценок пока нет
- Mail Merge StepsДокумент5 страницMail Merge StepsLarry Siga-an ConcepcionОценок пока нет
- Mega Process Core Branch Banking Deposit GenerationДокумент8 страницMega Process Core Branch Banking Deposit GenerationJanice Calunsag ChavezОценок пока нет
- My GCSE AQA Product Design (Graphics) Hobby Kit CourseworkДокумент20 страницMy GCSE AQA Product Design (Graphics) Hobby Kit CourseworkProject STRATOSОценок пока нет
- Writing A Business LetterДокумент28 страницWriting A Business LetterReina100% (1)
- KeyboardingДокумент6 страницKeyboardingRaji musharafОценок пока нет
- Carrier Scac and 29 Other Reports For U S Imports Shipments of Face ShieldДокумент107 страницCarrier Scac and 29 Other Reports For U S Imports Shipments of Face ShieldVân Gỗ Anpro SànОценок пока нет
- Guide To The Florence Agreement and Nairobi ProtocolДокумент28 страницGuide To The Florence Agreement and Nairobi ProtocolManuel L. Quezon III100% (2)
- Ontario Manual Effective May 1, 2010 NB and July, 1 2010 RENДокумент755 страницOntario Manual Effective May 1, 2010 NB and July, 1 2010 RENGregОценок пока нет