Вам также может понравиться
- Jacques Derrida Voice and Phenomenon Introduction To The Problem of The Sign in Husserls PhenomenologyДокумент157 страницJacques Derrida Voice and Phenomenon Introduction To The Problem of The Sign in Husserls PhenomenologyKeiji Kunigami100% (1)
- SWU Case StudyДокумент3 страницыSWU Case StudyschoolsamОценок пока нет
- Player Participation Guide v4.6 PDFДокумент31 страницаPlayer Participation Guide v4.6 PDFAlicia MorganОценок пока нет
- Competing AdvantageДокумент63 страницыCompeting Advantagejeremyclarkson02020% (4)
- Cost Comp - MF UF Vs TraditionalДокумент8 страницCost Comp - MF UF Vs TraditionalahanraОценок пока нет
- Baseball FundamentalsДокумент23 страницыBaseball FundamentalsNishank AgarwalОценок пока нет
- Data Science Linear RegressionДокумент105 страницData Science Linear RegressionJaime Prades KošćinaОценок пока нет
- Attendance of The 4 Major Sports LeaguesДокумент8 страницAttendance of The 4 Major Sports LeaguesgarrettherrОценок пока нет
- Translations of The Davenport TranslationsДокумент7 страницTranslations of The Davenport TranslationsNoahОценок пока нет
- LeBron James Stats, Height, Weight, Position, Dra 3Документ1 страницаLeBron James Stats, Height, Weight, Position, Dra 3josemi04Оценок пока нет
- Linear WeightsДокумент27 страницLinear WeightsAndres AlvaradoОценок пока нет
- Predicting The Outcome of NBA Playoffs Using The Naïve Bayes AlgorithmsДокумент9 страницPredicting The Outcome of NBA Playoffs Using The Naïve Bayes Algorithmsmensrea0Оценок пока нет
- Bnad Final ProjectДокумент9 страницBnad Final Projectapi-638485134Оценок пока нет
- Sports Metric Forecasting: Guides to Beating the Spreads in Major League Baseball, Basketball, and Football GamesОт EverandSports Metric Forecasting: Guides to Beating the Spreads in Major League Baseball, Basketball, and Football GamesОценок пока нет
- Futbol, El Juego Mas DificlДокумент2 страницыFutbol, El Juego Mas DificlJulio KaegiОценок пока нет
- BUS173 AssignmentДокумент19 страницBUS173 Assignmentসাবাতুম সাম্যОценок пока нет
- 11.13.12 Mariners Winter League ReportДокумент1 страница11.13.12 Mariners Winter League ReportRyan DivishОценок пока нет
- Using Markov Chains To Evaluate The Hitting of The 2009 Toronto Blue JaysДокумент13 страницUsing Markov Chains To Evaluate The Hitting of The 2009 Toronto Blue JaysDevin EnsingОценок пока нет
- Big Data Assn Document PDFДокумент22 страницыBig Data Assn Document PDFSRI PRAGATHIОценок пока нет
- 10.24.12 Mariners Winter League ReportДокумент1 страница10.24.12 Mariners Winter League ReportRyan DivishОценок пока нет
- Discrimination in Sports: (CITATION Law05 /L 1033)Документ5 страницDiscrimination in Sports: (CITATION Law05 /L 1033)Asim MalikОценок пока нет
- Height and Basketball True Shooting PercentageДокумент15 страницHeight and Basketball True Shooting PercentageSamia AkterОценок пока нет
- Stephen Curry Stats, Height, Weight, Position, DRДокумент1 страницаStephen Curry Stats, Height, Weight, Position, DRjosemi04Оценок пока нет
- How Mapping Shots in The NBA Changed It ForeverДокумент7 страницHow Mapping Shots in The NBA Changed It ForeverLautaro HernándezОценок пока нет
- 10.30.12 Mariners Winter League ReportДокумент1 страница10.30.12 Mariners Winter League ReportRyan DivishОценок пока нет
- NBA Salary Prediction PresentationДокумент29 страницNBA Salary Prediction PresentationKINN JOHN CHOWОценок пока нет
- Spract 6Документ40 страницSpract 6xtremfree5485Оценок пока нет
- VeteranPlayers 1 110 PDFДокумент110 страницVeteranPlayers 1 110 PDFDejan BlagojevicОценок пока нет
- 2012 Gameday Baseball Notes: Will County CrackerjacksДокумент6 страниц2012 Gameday Baseball Notes: Will County CrackerjackscrackerjacksbaseballОценок пока нет
- Professionally Written Analytical ReportДокумент7 страницProfessionally Written Analytical ReportbrookruleОценок пока нет
- 11.26.12 Mariners Winter League ReportДокумент1 страница11.26.12 Mariners Winter League ReportRyan DivishОценок пока нет
- Chance in BballДокумент12 страницChance in BballAnonymous iztPUhIiОценок пока нет
- Estimating A Demand Function - It's About TimeДокумент13 страницEstimating A Demand Function - It's About TimeSebastián RojasОценок пока нет
- NHL Attendance - Does Winning Really MatterДокумент11 страницNHL Attendance - Does Winning Really MatterChris MillerОценок пока нет
- PSY137 Assessment 2Документ4 страницыPSY137 Assessment 2AltairОценок пока нет
- Jim Albert, Jay Bennett-Curve Ball - Baseball, Statistics, and The Role of Chance in The Game (2003) (2003)Документ430 страницJim Albert, Jay Bennett-Curve Ball - Baseball, Statistics, and The Role of Chance in The Game (2003) (2003)AhmedОценок пока нет
- Screenshot 2023-01-04 at 11.49.30 AM PDFДокумент1 страницаScreenshot 2023-01-04 at 11.49.30 AM PDFHember RОценок пока нет
- 12.18.12 Mariners Winter League ReportДокумент1 страница12.18.12 Mariners Winter League ReportRyan DivishОценок пока нет
- Assignment1Документ9 страницAssignment1Subhajit RoyОценок пока нет
- Analysis of Chess Games With Chess EnginesДокумент16 страницAnalysis of Chess Games With Chess EnginesRuturaj SahuОценок пока нет
- Season Stats FB 2016 PDFДокумент9 страницSeason Stats FB 2016 PDFMarc MorehouseОценок пока нет
- Solutions To Practice Problems For Part VI: Regression StatisticsДокумент40 страницSolutions To Practice Problems For Part VI: Regression Statisticsshannon caseyОценок пока нет
- Analysis of Athletics DataДокумент18 страницAnalysis of Athletics DataNamdevОценок пока нет
- Predicting The Improvement of NBA Players ReportДокумент15 страницPredicting The Improvement of NBA Players ReportJohn GuacalaОценок пока нет
- Paper 09Документ10 страницPaper 09Łukasz Wiesław StrzałkowskiОценок пока нет
- The Loser'S Curse: Overconfidence vs. Market Efficiency in The National Football League DraftДокумент17 страницThe Loser'S Curse: Overconfidence vs. Market Efficiency in The National Football League Draftmoonie_phantharathОценок пока нет
- ECON FINAL - Statistical Coding Sample (Stata)Документ22 страницыECON FINAL - Statistical Coding Sample (Stata)Joel TomanelliОценок пока нет
- Stephen Curry Stats, Height, Weight, Position, DR 2Документ1 страницаStephen Curry Stats, Height, Weight, Position, DR 2josemi04Оценок пока нет
- Predicting Football Results With Statistical Modelling in PythonДокумент19 страницPredicting Football Results With Statistical Modelling in PythonaryantoОценок пока нет
- Chapter 4 Project: Data SetДокумент4 страницыChapter 4 Project: Data Setapi-345780702Оценок пока нет
- Automated TradingДокумент28 страницAutomated TradingagonzalezfОценок пока нет
- MathessaysportsstatsДокумент5 страницMathessaysportsstatsapi-285591884Оценок пока нет
- Stats - Assignment 3Документ18 страницStats - Assignment 3haonanzhangОценок пока нет
- Game 52, Road Game 27 Saturday, Feb. 3, 2018 - 2:30 PM CT STAPLES Center NBCSCH / WSCR Am 670Документ17 страницGame 52, Road Game 27 Saturday, Feb. 3, 2018 - 2:30 PM CT STAPLES Center NBCSCH / WSCR Am 670miguelОценок пока нет
- Today's GamesДокумент1 страницаToday's Gamesdaved echeverria arteagaОценок пока нет
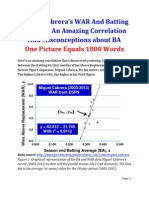
- Miguel Cabrera's Career Wins Above Replacement (WAR) and Batting Average (BA) : An Amazing CorrelationДокумент33 страницыMiguel Cabrera's Career Wins Above Replacement (WAR) and Batting Average (BA) : An Amazing CorrelationVj LaxmananОценок пока нет
- TLS Orthogonal Regression VBAДокумент16 страницTLS Orthogonal Regression VBAPeter Urbani0% (1)
- Statis Pro Rules 5-2013Документ8 страницStatis Pro Rules 5-2013peppylepepper100% (1)
- 2086-Sports Analytics IEEE Seminar 1-17-17Документ74 страницы2086-Sports Analytics IEEE Seminar 1-17-17Prashanth MohanОценок пока нет
- HRM Assignment - AnalyticsДокумент7 страницHRM Assignment - AnalyticsDeeksha VermaОценок пока нет
- Curriculum Vitae: Basanta BhowmikДокумент5 страницCurriculum Vitae: Basanta BhowmikBasanta BhowmikОценок пока нет
- Kellogg's Case StudyДокумент3 страницыKellogg's Case StudyÁkos Marian50% (2)
- A Paradox in The Interpretation of Group Comparisons: Frederic M. LordДокумент2 страницыA Paradox in The Interpretation of Group Comparisons: Frederic M. Lordajax_telamonioОценок пока нет
- KPO An Opportunity For CAДокумент5 страницKPO An Opportunity For CApathan1990Оценок пока нет
- Cover LetterДокумент1 страницаCover LetterJobJobОценок пока нет
- CD Ch08 VariableHeatCapacitiesДокумент9 страницCD Ch08 VariableHeatCapacitiesEric BowlsОценок пока нет
- Agar Cube LabДокумент2 страницыAgar Cube LabairulyantiОценок пока нет
- Specific Heat of GasesДокумент22 страницыSpecific Heat of Gasesthinkiit0% (1)
- PB115 Connection ReferenceДокумент278 страницPB115 Connection ReferenceJose Andres LeonОценок пока нет
- ANSI ISA 12.01.01 2013 Clasif Areas de Riesgo PDFДокумент100 страницANSI ISA 12.01.01 2013 Clasif Areas de Riesgo PDFLuis Humberto Ruiz Betanzos100% (1)
- Standards Booklet For Igsce Sociology (0495)Документ64 страницыStandards Booklet For Igsce Sociology (0495)Ingrit AgustinОценок пока нет
- Yamamoto KuwaharaДокумент15 страницYamamoto KuwaharapravinsuryaОценок пока нет
- Error DetailsДокумент3 страницыError Detailsnaresh kumarОценок пока нет
- Biometrics IN Network SecurityДокумент10 страницBiometrics IN Network SecurityARVINDОценок пока нет
- HD ROV Datasheet PDFДокумент2 страницыHD ROV Datasheet PDFpepeОценок пока нет
- Electric CircuitsДокумент546 страницElectric CircuitsRAGHU_RAGHU100% (7)
- 01 IntroductionДокумент26 страниц01 IntroductionDaniel CrashOverride ShaferОценок пока нет
- Application Satellite Image in Mineral ExplorationДокумент17 страницApplication Satellite Image in Mineral ExplorationHifdzulFikriОценок пока нет
- Bei 076 III II AntenamarksДокумент8 страницBei 076 III II Antenamarksshankar bhandariОценок пока нет
- Performance ViceДокумент7 страницPerformance ViceVicente Cortes RuzОценок пока нет
- Darwin Geologist PDFДокумент3 страницыDarwin Geologist PDFKendallhernandez100% (1)
- MENG4662 Chapter 2 Rankine CycleДокумент67 страницMENG4662 Chapter 2 Rankine CycleSamuel GeorgeОценок пока нет
- Valve Stem SealsДокумент2 страницыValve Stem SealsBinny Samuel Christy100% (1)
- Microsoft Power Point 2007-IntroductionДокумент27 страницMicrosoft Power Point 2007-IntroductionizahusniОценок пока нет
- Cot Angel Eng 3Документ3 страницыCot Angel Eng 3Arjay GarboОценок пока нет
- Microsoft Word Quality Manual Edition 10 Revision 00 Effective Date 2019-02-01Документ76 страницMicrosoft Word Quality Manual Edition 10 Revision 00 Effective Date 2019-02-01Vikram BillalОценок пока нет
- Literature SurveyДокумент6 страницLiterature SurveyAnonymous j0aO95fgОценок пока нет