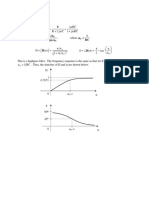
Вам также может понравиться
- Adv Topic Compiler Supported ILPSlidesДокумент18 страницAdv Topic Compiler Supported ILPSlidesAtharvaОценок пока нет
- 1 - 6. Exploiting ILPДокумент45 страниц1 - 6. Exploiting ILPMd JubairОценок пока нет
- Lecture: Static ILP: Topics: Predication, Speculation (Sections C.5, 3.2)Документ26 страницLecture: Static ILP: Topics: Predication, Speculation (Sections C.5, 3.2)Purab RanjanОценок пока нет
- Exploiting ILP With Software ApproachДокумент104 страницыExploiting ILP With Software Approachhalimabanu916270Оценок пока нет
- HW3 Sol PDFДокумент5 страницHW3 Sol PDFAnonymous GJK5Z8ZОценок пока нет
- cs433 Fa19 hw4 SolutionДокумент12 страницcs433 Fa19 hw4 Solutionheba AladwanОценок пока нет
- Tomasulo 2Документ8 страницTomasulo 2tesfuОценок пока нет
- CS/EE-520 - Computer Architecture Quiz-4 (Sec 2), November 07, 2017 (Fall 2017)Документ1 страницаCS/EE-520 - Computer Architecture Quiz-4 (Sec 2), November 07, 2017 (Fall 2017)dash spiderОценок пока нет
- Lec 11Документ19 страницLec 11jyothibellary4233Оценок пока нет
- CS/EE-520 - Computer Architecture Quiz-4 (Sec 1), November 07, 2017 (Fall 2017)Документ1 страницаCS/EE-520 - Computer Architecture Quiz-4 (Sec 1), November 07, 2017 (Fall 2017)dash spiderОценок пока нет
- HardwareДокумент24 страницыHardwarepriyankaОценок пока нет
- Assignment 2Документ2 страницыAssignment 2Fateh Ali AlimОценок пока нет
- Chapter 03Документ19 страницChapter 03bchang412Оценок пока нет
- Latencies For Different Execution Units: FP Add/Sub: 2 CC FP MUL: 10 CC FP DIV: 25 CC INT ALU op/LD/SD: 1 CC 1. Without Data ForwardingДокумент2 страницыLatencies For Different Execution Units: FP Add/Sub: 2 CC FP MUL: 10 CC FP DIV: 25 CC INT ALU op/LD/SD: 1 CC 1. Without Data ForwardingAnum MansoorОценок пока нет
- Cycles Int Op 1 Intop2 Memop1 Memop2 FP Addition FP Subtraction FP Multiply 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18Документ2 страницыCycles Int Op 1 Intop2 Memop1 Memop2 FP Addition FP Subtraction FP Multiply 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18Rameshwar MishraОценок пока нет
- Chapter 03 SolutionДокумент19 страницChapter 03 SolutionAnonymous ZaO7fL4tОценок пока нет
- Intro To Static Pipelining: CS252 Graduate Computer ArchitectureДокумент52 страницыIntro To Static Pipelining: CS252 Graduate Computer Architectureشايك يوسفОценок пока нет
- HW3 SolutionДокумент14 страницHW3 Solutionpavan saiОценок пока нет
- CSE 560 - Practice Problem Set 5 SolutionДокумент9 страницCSE 560 - Practice Problem Set 5 SolutionFgfughuОценок пока нет
- 4.multicycle and ExceptionsДокумент75 страниц4.multicycle and ExceptionsasaksjaksОценок пока нет
- Compiler Techniques For Exposing ILPДокумент4 страницыCompiler Techniques For Exposing ILPGan EshОценок пока нет
- Lecture04 DynamicSchedulingДокумент81 страницаLecture04 DynamicSchedulingNikitasОценок пока нет
- Advanced Computer Architecture-06CS81 Hardware Based Speculation (Unit 3)Документ5 страницAdvanced Computer Architecture-06CS81 Hardware Based Speculation (Unit 3)Swastik NayakОценок пока нет
- Keyboard Scan CodesДокумент2 страницыKeyboard Scan CodesVivekpuri Lalpuri GoswamiОценок пока нет
- Lecture 20Документ28 страницLecture 20Udai ValluruОценок пока нет
- Nota 28 Ago 2023Документ2 страницыNota 28 Ago 2023Gael Jose Quintanilla GarciaОценок пока нет
- L11 DS PDFДокумент41 страницаL11 DS PDFDarshanОценок пока нет
- Lect12 TomasuloExample PDFДокумент41 страницаLect12 TomasuloExample PDFAhmad AsgharОценок пока нет
- TDA7442Документ16 страницTDA7442gusagus2775Оценок пока нет
- ETABS Shell Asignment GuideДокумент2 страницыETABS Shell Asignment GuideJaher WasimОценок пока нет
- Calculating The Area of A CircleДокумент4 страницыCalculating The Area of A Circleshreeku007Оценок пока нет
- Computer ArchitectureДокумент46 страницComputer Architecturejaime_parada3097100% (2)
- Display MultipleДокумент2 страницыDisplay MultipleYozef PazmiñoОценок пока нет
- Keyboard Scan Codes: Set 2: 101-, 102-, and 104-Key KeyboardsДокумент2 страницыKeyboard Scan Codes: Set 2: 101-, 102-, and 104-Key Keyboardsbadu51Оценок пока нет
- Basic Compiler Techniques For Exposing ILP: by Bhanu Kiran BДокумент8 страницBasic Compiler Techniques For Exposing ILP: by Bhanu Kiran BMalli VadlamudiОценок пока нет
- TDA7442 TDA7442D: Tone Control and Surround Digitally Controlled Audio ProcessorДокумент17 страницTDA7442 TDA7442D: Tone Control and Surround Digitally Controlled Audio ProcessorTorikul HabibОценок пока нет
- Assigment Schedule With Critical PathДокумент1 страницаAssigment Schedule With Critical PathEng GaaxeelОценок пока нет
- Midterm Solutions Mar 30Документ6 страницMidterm Solutions Mar 30Sahil SethОценок пока нет
- BOM - H-Bridge Motor Control With Ir2110 and Arduino (TVTC-JED)Документ1 страницаBOM - H-Bridge Motor Control With Ir2110 and Arduino (TVTC-JED)Muhammad RajibОценок пока нет
- Exe On PipeliningДокумент12 страницExe On PipeliningKshitij ZutshiОценок пока нет
- Lecture 18Документ38 страницLecture 18Udai ValluruОценок пока нет
- Ee660 2017 Spring Materials Week 04 AssgДокумент3 страницыEe660 2017 Spring Materials Week 04 Assgqaesz0% (1)
- BOM - Tl494 Inverter 1000wДокумент1 страницаBOM - Tl494 Inverter 1000wSergio AzevedoОценок пока нет
- All All: Published With MATLAB® R2016aДокумент4 страницыAll All: Published With MATLAB® R2016avalОценок пока нет
- MVURWI HIGH SCHOOL Mid Year Timetable 2023Документ8 страницMVURWI HIGH SCHOOL Mid Year Timetable 2023tinarwowaisheОценок пока нет
- ) (, Where: Chapter 14, Solution 1Документ120 страниц) (, Where: Chapter 14, Solution 1최준범Оценок пока нет
- Lec02 Superscalar SW VLIW 22 23Документ34 страницыLec02 Superscalar SW VLIW 22 23oqw10668Оценок пока нет
- HW 2 Is Out! Due 9/25!Документ21 страницаHW 2 Is Out! Due 9/25!tauqeerahmadpk786Оценок пока нет
- LC1/LC2 - D40 D50 D65 D80 D95: Schütze / WendeschützeДокумент8 страницLC1/LC2 - D40 D50 D65 D80 D95: Schütze / Wendeschützeiman wahyudinОценок пока нет
- Machine Learning-Based Soft Sensors For Vacuum DisДокумент9 страницMachine Learning-Based Soft Sensors For Vacuum DismontasheriОценок пока нет
- Datasheet Tr425Документ1 страницаDatasheet Tr425Basmal KadirОценок пока нет
- BH345 Final1Документ6 страницBH345 Final1jakirakaОценок пока нет
- GPSUser ManualДокумент15 страницGPSUser ManualaravindbprasadОценок пока нет
- MN Loop UnrollingДокумент5 страницMN Loop UnrollingVilceanu Doru WylОценок пока нет
- Tomasulo With Re-Order Buffer-V3Документ10 страницTomasulo With Re-Order Buffer-V3prakash_shrОценок пока нет
- Update Partlist Ampli Gitar Lm3886Документ2 страницыUpdate Partlist Ampli Gitar Lm3886Rohan JoshiОценок пока нет
- Laboratorio Iv: 1) 1 Motor C.C deДокумент4 страницыLaboratorio Iv: 1) 1 Motor C.C deBoris Benites CalenzaniОценок пока нет
- AN2002 Application Note: Using The Demoboard For The TD350 Advanced IGBT DriverДокумент8 страницAN2002 Application Note: Using The Demoboard For The TD350 Advanced IGBT Driverbokic88Оценок пока нет
- PipeliningДокумент36 страницPipelinings_subbulakshmiОценок пока нет
- BITS MTech Microelectronics Question PaperДокумент22 страницыBITS MTech Microelectronics Question Papers_subbulakshmi100% (1)
- Junction Field Effect Transistors: Class 7Документ47 страницJunction Field Effect Transistors: Class 7s_subbulakshmi100% (1)
- Adv Comp ArchДокумент5 страницAdv Comp Archjulianraja20Оценок пока нет
- A Practical Introduction To Hardwaresoftware Codesign 1Документ64 страницыA Practical Introduction To Hardwaresoftware Codesign 1s_subbulakshmiОценок пока нет
- Device Electronics For Integrated Circuits 3rd Edition 1 PDFДокумент270 страницDevice Electronics For Integrated Circuits 3rd Edition 1 PDFKidane Kebede0% (1)
- Physics SolutionДокумент13 страницPhysics Solutions_subbulakshmiОценок пока нет
- Current Source and SinkДокумент12 страницCurrent Source and Sinkapoorva10393Оценок пока нет
- Device Electronics For Integrated Circuits 3rd Edition 1 PDFДокумент270 страницDevice Electronics For Integrated Circuits 3rd Edition 1 PDFKidane Kebede0% (1)
- Solutions To Homework 5: Problem 1Документ4 страницыSolutions To Homework 5: Problem 1Eladhio BurgosОценок пока нет
- Chip Exam atДокумент24 страницыChip Exam atAmit GoyalОценок пока нет
- MCQ-Diodes and TransistorsДокумент102 страницыMCQ-Diodes and Transistorsaksaltaf913774% (23)
- J. Le Coz, B. Pelloux-Prayer, B. Giraud, F. Giner, P. Flatresse Stmicroelectronics, Crolles, France Cea-Leti-Minatec, Grenoble, FranceДокумент2 страницыJ. Le Coz, B. Pelloux-Prayer, B. Giraud, F. Giner, P. Flatresse Stmicroelectronics, Crolles, France Cea-Leti-Minatec, Grenoble, Frances_subbulakshmiОценок пока нет
- Digital ElectronicsДокумент91 страницаDigital Electronicss_subbulakshmiОценок пока нет
- Proximity Effect ModelsДокумент9 страницProximity Effect Modelss_subbulakshmiОценок пока нет
- Import JavaДокумент2 страницыImport Javas_subbulakshmiОценок пока нет
- Std12 Phy Vol 1Документ237 страницStd12 Phy Vol 1Aaron Merrill50% (2)
- Career Advice PDFДокумент3 страницыCareer Advice PDFs_subbulakshmiОценок пока нет
- 2009 04 FaricelliДокумент49 страниц2009 04 Faricellipetit ciОценок пока нет
- Sze PhysicsOfSemiconductorDevicesДокумент830 страницSze PhysicsOfSemiconductorDevicessameera_subramaniyanОценок пока нет
- MTechMicroelectronics Jan2017Документ2 страницыMTechMicroelectronics Jan2017s_subbulakshmiОценок пока нет
- WarningДокумент3 страницыWarnings_subbulakshmiОценок пока нет
- Paper 2Документ23 страницыPaper 2arvind pandeyОценок пока нет
- Vlsi Basic RsumДокумент2 страницыVlsi Basic Rsums_subbulakshmiОценок пока нет
- Advanced Sentence Correction 7 - AnswersДокумент1 страницаAdvanced Sentence Correction 7 - Answerss_subbulakshmi0% (1)
- MOCK TEST-gateДокумент19 страницMOCK TEST-gates_subbulakshmiОценок пока нет
- 2electronic Devices - Sample ChapterДокумент76 страниц2electronic Devices - Sample ChapterJoshua DuffyОценок пока нет
- Gate Ece Previous Papers 1996-2013 by KanodiaДокумент250 страницGate Ece Previous Papers 1996-2013 by KanodiaNaresh Kumar80% (5)
- Ece Practice Book PDFДокумент16 страницEce Practice Book PDFs_subbulakshmi0% (1)
- The Business Analyst and The SDLCДокумент8 страницThe Business Analyst and The SDLCErlet ShaqeОценок пока нет
- Unit - 2 SatcommДокумент35 страницUnit - 2 SatcommVerzeo group projectОценок пока нет
- Introduction To Weapon & AmmunitionДокумент141 страницаIntroduction To Weapon & Ammunitionk2kkhanna105100% (1)
- EPLAN Print Job PDFДокумент167 страницEPLAN Print Job PDFrammu2001Оценок пока нет
- 213078Документ38 страниц213078Mbade NDONGОценок пока нет
- DPC6HG Aa00 G0000 ZS001 - 001 - 01Документ6 страницDPC6HG Aa00 G0000 ZS001 - 001 - 01rajitkumar.3005Оценок пока нет
- Funambol Whatisnewinv10 June11Документ23 страницыFunambol Whatisnewinv10 June11Eftakhar Chowdhury PallabОценок пока нет
- Flare Gas Reduction: Recent Global Trends and Policy Considerations by GE Energy, January 2011Документ60 страницFlare Gas Reduction: Recent Global Trends and Policy Considerations by GE Energy, January 2011Randall WestОценок пока нет
- Scope of The WorkДокумент5 страницScope of The Worklogu RRОценок пока нет
- Brevity CodeДокумент18 страницBrevity CodeArash AziziОценок пока нет
- 1.1 Proj Cost Esitimating - OverviewДокумент42 страницы1.1 Proj Cost Esitimating - OverviewSam CherniakОценок пока нет
- Us MP News ReleaseДокумент3 страницыUs MP News ReleaseMetro Los AngelesОценок пока нет
- CMM COMPONENT ELT 570-5000 - Rev - AДокумент81 страницаCMM COMPONENT ELT 570-5000 - Rev - AREY DAVIDОценок пока нет
- CMA June 2018 ExamДокумент2 страницыCMA June 2018 ExamMuhammad Ziaul HaqueОценок пока нет
- Ticketswap-Betonhofi-Slaybania-Ticket-20808722 2Документ1 страницаTicketswap-Betonhofi-Slaybania-Ticket-20808722 2Anderlik-Makkai GergelyОценок пока нет
- English Today Vol 2Документ10 страницEnglish Today Vol 2StancuLucianОценок пока нет
- Chapter 5 Hydraulic JumpДокумент31 страницаChapter 5 Hydraulic JumpUsman AliОценок пока нет
- Pappu Suryanarayana Murthy: Career ObjectiveДокумент3 страницыPappu Suryanarayana Murthy: Career ObjectiveSuurya PrabhathОценок пока нет
- Pass Transistor LogicДокумент36 страницPass Transistor LogicMuneza NaeemОценок пока нет
- Gravity Analog Dissolved Oxygen Sensor SKU SEN0237 DFRobot Electronic Product Wiki and Tutorial Arduino and Robot WikiДокумент8 страницGravity Analog Dissolved Oxygen Sensor SKU SEN0237 DFRobot Electronic Product Wiki and Tutorial Arduino and Robot WikihipolitoОценок пока нет
- Muhammad Ali - CHRP (Canada)Документ8 страницMuhammad Ali - CHRP (Canada)Muhammad AliОценок пока нет
- Field Trip Grading RubricДокумент1 страницаField Trip Grading Rubricapi-242613835Оценок пока нет
- Aug 26 PDFДокумент4 страницыAug 26 PDFwilliam_malonzoОценок пока нет
- Boq IДокумент7 страницBoq IAmolОценок пока нет
- Product Data: 58GP, GS Upflow Natural-Draft Gas-Fired FurnaceДокумент8 страницProduct Data: 58GP, GS Upflow Natural-Draft Gas-Fired FurnaceMichael MartinОценок пока нет
- Introduction To Public Health LaboratoriesДокумент45 страницIntroduction To Public Health LaboratoriesLarisa Izabela AndronecОценок пока нет
- Api-1169 Pipeline Construction Inspector: Body of KnowledgeДокумент9 страницApi-1169 Pipeline Construction Inspector: Body of KnowledgeKhalilahmad KhatriОценок пока нет
- Copia de FORMATO AmefДокумент2 страницыCopia de FORMATO AmefDavid SaucedoОценок пока нет
- w170 w190 w230c - 30644gb 123bbДокумент20 страницw170 w190 w230c - 30644gb 123bbJIMISINGОценок пока нет