Вам также может понравиться
- Inmunodifusión en GelДокумент11 страницInmunodifusión en GelGustavo ParedesОценок пока нет
- Identificación de Carbapenemasas Por Test de Hodge TritonДокумент24 страницыIdentificación de Carbapenemasas Por Test de Hodge TritonDannie Troncoso0% (1)
- 2010 Técnicas InmunologicasДокумент5 страниц2010 Técnicas InmunologicasJorge Alberto Santiago-SanchezОценок пока нет
- Planificacion Funcion Logaritmica Nuevo PDFДокумент11 страницPlanificacion Funcion Logaritmica Nuevo PDFLuciano GaleanoОценок пока нет
- Microarrays - Grupo 2Документ26 страницMicroarrays - Grupo 2HAROL ANDRÉS BEDOYA CHAPARRO100% (1)
- Caso Clinico Numero 3Документ3 страницыCaso Clinico Numero 3DxnielxSanzRiversОценок пока нет
- Anticuerpos NaturalesДокумент1 страницаAnticuerpos NaturalesDesvin Yauri calderonОценок пока нет
- Clase DX Serologico Brucelosis 2015Документ68 страницClase DX Serologico Brucelosis 2015ehloco30Оценок пока нет
- Microbiología, Patogénesis, Epidemiología, Clínica y Diagnóstico de Las Infecciones Producidas PorДокумент15 страницMicrobiología, Patogénesis, Epidemiología, Clínica y Diagnóstico de Las Infecciones Producidas PorluisОценок пока нет
- Interpretación Clínica Del HemogramaДокумент13 страницInterpretación Clínica Del HemogramaJUAN JESÚSОценок пока нет
- Informe de Laboratorio 3 MicologíaДокумент12 страницInforme de Laboratorio 3 MicologíaJesus Castillo GuzmanОценок пока нет
- Aplicaciones MALDI TOFДокумент12 страницAplicaciones MALDI TOFYolanda ValenciaОценок пока нет
- Lab 11 - MÉTODOS DE DIAGNÓSTICO BACTERIOLÓGICOДокумент12 страницLab 11 - MÉTODOS DE DIAGNÓSTICO BACTERIOLÓGICODenilson David Loayza CallisayaОценок пока нет
- Corpusculo de BarrДокумент9 страницCorpusculo de BarrSander San MartínОценок пока нет
- Rinosporidiosis - Jaime Jara Alvarado - G9Документ18 страницRinosporidiosis - Jaime Jara Alvarado - G9Jaime Jara AlvaradoОценок пока нет
- Clase 4 ELISAsДокумент20 страницClase 4 ELISAsangelamadridgОценок пока нет
- Tecnicas Inmunoenzimaticas para Ensayos Clinicos de Vacunas y Estudios InmunoepidemiologicosДокумент120 страницTecnicas Inmunoenzimaticas para Ensayos Clinicos de Vacunas y Estudios InmunoepidemiologicosclodingoОценок пока нет
- StaphylococcusДокумент5 страницStaphylococcusHilder Baldeon NuñezОценок пока нет
- Nomenclatura CromosomicaДокумент11 страницNomenclatura CromosomicaShahidi AzzâmОценок пока нет
- Instructivo PEVED INS 2016Документ14 страницInstructivo PEVED INS 2016MILAGROS VIDARTE MALDONADOОценок пока нет
- TFG ContinuacionДокумент33 страницыTFG ContinuacionSergio Messaoudi100% (1)
- Enzimas de Harper 29 Edicion Version CompletaДокумент37 страницEnzimas de Harper 29 Edicion Version CompletaJavierОценок пока нет
- Fiebre Tifoidea Reacciones Febriles PDFДокумент2 страницыFiebre Tifoidea Reacciones Febriles PDFJeremyОценок пока нет
- 11 Parasitos Generalidades (Diapositivas)Документ21 страница11 Parasitos Generalidades (Diapositivas)jose gutierrez100% (2)
- ELISA-Ensayo Inmunezimatico 2020Документ32 страницыELISA-Ensayo Inmunezimatico 2020Mayra Hernandez100% (1)
- Taller 2 Interferencias Hematologia y Tinciones ComunesДокумент4 страницыTaller 2 Interferencias Hematologia y Tinciones ComunesMaria Victoria Torres AlvarezОценок пока нет
- Diagnostico LeucemiasДокумент9 страницDiagnostico LeucemiasBlanca Rosa Briceño MunguiaОценок пока нет
- Neutropenia FebrilДокумент53 страницыNeutropenia Febrilapi-3742102100% (2)
- Diferencial LeucocitarioДокумент14 страницDiferencial LeucocitarioGeysell JarquinОценок пока нет
- Resistencia AntimicrobianaДокумент61 страницаResistencia AntimicrobianaChristian Quintana CalderónОценок пока нет
- Recuento Celular Sanguíneo PDFДокумент2 страницыRecuento Celular Sanguíneo PDFCristian E. RosalesОценок пока нет
- Clase QPCRДокумент55 страницClase QPCRJohanna Jazmin Acevedo MirandaОценок пока нет
- Fenomeno de Zona 1 1Документ9 страницFenomeno de Zona 1 1Ruth Nizama LezamaОценок пока нет
- MALDITOFДокумент11 страницMALDITOFKatherine DiazОценок пока нет
- La-Participacion-En-Salud-Factores-Que-Favorecen PDFДокумент11 страницLa-Participacion-En-Salud-Factores-Que-Favorecen PDFWilliam C Carrillo Sarabia100% (1)
- Test de CoombsДокумент3 страницыTest de CoombsSheyla SantiagoОценок пока нет
- 1 Luis Martinez PDFДокумент24 страницы1 Luis Martinez PDFAlfonso MoratoОценок пока нет
- LEUCEMIASДокумент64 страницыLEUCEMIASFernando GarciaОценок пока нет
- Guia Práctica CitogeneticaДокумент28 страницGuia Práctica CitogeneticaJuan C. OrmeñoОценок пока нет
- Actividad 4 Histologia ChidaДокумент5 страницActividad 4 Histologia ChidaAlejandra Luna RuanoОценок пока нет
- Coli Uropatógeno El Patógeno Que Produce Más Del 80Документ3 страницыColi Uropatógeno El Patógeno Que Produce Más Del 80Montesinos CarolinaОценок пока нет
- CRUP EPIDEMIOLOGIA 2.en - EsДокумент7 страницCRUP EPIDEMIOLOGIA 2.en - EsCarolina Mora RuedaОценок пока нет
- Instructivo Montaje de Quimica ClinicaДокумент49 страницInstructivo Montaje de Quimica ClinicaMicrobiologia ArcasaludОценок пока нет
- Manual Prueba Rapida Dengue NS1 IgG IgMДокумент2 страницыManual Prueba Rapida Dengue NS1 IgG IgMshiruba pioОценок пока нет
- PSA Staphylococcus Panel 33 de MicroScan y CLSI 2014Документ172 страницыPSA Staphylococcus Panel 33 de MicroScan y CLSI 2014ROSY_LABRONTGОценок пока нет
- Neutropenia InmuneДокумент10 страницNeutropenia InmuneOlivier RodОценок пока нет
- Anticuerpos Irregulares Anti-EДокумент5 страницAnticuerpos Irregulares Anti-EtecnologosmedicosОценок пока нет
- Detección de Toxoplasmosis en Suero o Plasma Humano Mediante Prueba de ELISAДокумент9 страницDetección de Toxoplasmosis en Suero o Plasma Humano Mediante Prueba de ELISAClaudio Zepeda del ValleОценок пока нет
- Microbiología e Inmunología-Bioseguridad-Semana 1-16Документ51 страницаMicrobiología e Inmunología-Bioseguridad-Semana 1-16Aracely Escarleth Aguirre de la CruzОценок пока нет
- Bacilos Gramneg Klebs - Ent y Prot - 2011 - 10Документ78 страницBacilos Gramneg Klebs - Ent y Prot - 2011 - 10royer944100% (1)
- OuchterlonyДокумент2 страницыOuchterlonyDavid Tritono Di BallastrossОценок пока нет
- RabdomiosarcomaДокумент9 страницRabdomiosarcomaAndieLopezОценок пока нет
- Folleto Cobas 6000 C501 PDFДокумент2 страницыFolleto Cobas 6000 C501 PDFCarinaVillasantiОценок пока нет
- Pruebas de Diagnóstico para CovidДокумент5 страницPruebas de Diagnóstico para CovidLitzy MedinaОценок пока нет
- Resistencia Macrolidos Lincosamidas Estreptograminas CartillaДокумент3 страницыResistencia Macrolidos Lincosamidas Estreptograminas CartillaCristina SaavedraОценок пока нет
- Mmi PruebasДокумент29 страницMmi PruebasJesús LoretoОценок пока нет
- BioterrorismoДокумент7 страницBioterrorismoZaira GonzalezОценок пока нет
- Test de IndependenciaДокумент2 страницыTest de IndependenciaVicente AriasОценок пока нет
- Test Estadísticos para Variables CualitativasДокумент37 страницTest Estadísticos para Variables CualitativasAlejandro ApazaОценок пока нет
- Prueba de Homogeineidad de Varianza LeveneДокумент20 страницPrueba de Homogeineidad de Varianza Levenemanu_xtrОценок пока нет
- P27598 LED HIGHBAY 240W CW GC350 DIM (Ficha)Документ1 страницаP27598 LED HIGHBAY 240W CW GC350 DIM (Ficha)Vicente AriasОценок пока нет
- Clases Pro 2Документ73 страницыClases Pro 2Vicente AriasОценок пока нет
- Burden-Issuupdf 2Документ40 страницBurden-Issuupdf 2Vicente AriasОценок пока нет
- Test de IndependenciaДокумент2 страницыTest de IndependenciaVicente AriasОценок пока нет
- Agüero CyДокумент167 страницAgüero CyVicente Arias50% (2)
- 9 Analisis de La Homogeneidad de Varianza Homocedasticidad PDFДокумент7 страниц9 Analisis de La Homogeneidad de Varianza Homocedasticidad PDFVicente AriasОценок пока нет
- Tarea 1 Adriana LujanДокумент4 страницыTarea 1 Adriana LujanJose VilaОценок пока нет
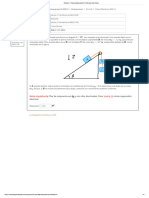
- Parcial 2 - Física Mecánica 2021-2 - Revisión Del IntentoДокумент4 страницыParcial 2 - Física Mecánica 2021-2 - Revisión Del IntentoMARIA ANDREA HERNANDEZ ARIASОценок пока нет
- PolinomiosДокумент7 страницPolinomiosPaola OrdazОценок пока нет
- Flexion en Vigas 1Документ57 страницFlexion en Vigas 1Daniel AponteОценок пока нет
- Lopez Camarena Andres M11S3AI6Документ3 страницыLopez Camarena Andres M11S3AI6Andres Camarena100% (1)
- Feria de Los Materiales DidácticosДокумент2 страницыFeria de Los Materiales DidácticosaidaОценок пока нет
- Bredlow-Parménides o La Identidad ImposibleДокумент9 страницBredlow-Parménides o La Identidad ImposibleLucía Martínez100% (2)
- Lamina-15 Teorema de Thales y Euclides (2016) - PROДокумент2 страницыLamina-15 Teorema de Thales y Euclides (2016) - PROSindy Aracely Severino DiazОценок пока нет
- Interes CompuestoДокумент40 страницInteres CompuestoDaniela Benavente100% (3)
- Algoritmos en PSeIntДокумент19 страницAlgoritmos en PSeIntrash270% (2)
- Conceptos Basicos InferencialesДокумент3 страницыConceptos Basicos InferencialesKurama YahikoОценок пока нет
- Guía Repaso para Evaluación N°2Документ4 страницыGuía Repaso para Evaluación N°2Valentina CelisОценок пока нет
- Trabajo Mecanico (TPE) Ficha 8 OkДокумент14 страницTrabajo Mecanico (TPE) Ficha 8 OkALFREDOОценок пока нет
- Practica 6Документ7 страницPractica 6Dvd PerezОценок пока нет
- Teorema de PitagorasДокумент3 страницыTeorema de Pitagorascristian renne GutierrezОценок пока нет
- Algebra Productos NotablesДокумент4 страницыAlgebra Productos NotablesAlvaro Ccosco MendozaОценок пока нет
- Tarea 3 Matematica SuperiorДокумент3 страницыTarea 3 Matematica SuperiorStephanie Marun BerroaОценок пока нет
- Genichi TaguchiДокумент11 страницGenichi TaguchiJOSE ANTONIOОценок пока нет
- Excel Apuntes 3r EsoДокумент23 страницыExcel Apuntes 3r EsocolquisОценок пока нет
- Sucesiones, Series y Convergencias - Karla - VeraДокумент15 страницSucesiones, Series y Convergencias - Karla - VeraKarly Vera Guerrero0% (1)
- 4to Grado AritmetiicaДокумент47 страниц4to Grado AritmetiicaMar SolОценок пока нет
- RODRÍGUEZ OCHOA, Jairo Javier PDFДокумент259 страницRODRÍGUEZ OCHOA, Jairo Javier PDFYoser Rios RoldanОценок пока нет
- Analisis 123Документ17 страницAnalisis 123omarcarbajal10Оценок пока нет
- Informe - Rápida, Ecuaciones EmpiricasДокумент9 страницInforme - Rápida, Ecuaciones EmpiricasMate Cien CiasОценок пока нет
- Evaluación Proyecto y Quiz Econometría Básica 2019Документ3 страницыEvaluación Proyecto y Quiz Econometría Básica 2019Jose Pablo Serrano OconitrilloОценок пока нет
- Corrientes Fundamentales en PsicoterapiaДокумент5 страницCorrientes Fundamentales en PsicoterapiaPaola Carolina CenturiónОценок пока нет
- Informe 5 Sebastian AlvarezДокумент9 страницInforme 5 Sebastian AlvarezSebastian AlvarezОценок пока нет
- Clase 1 Semana 1Документ4 страницыClase 1 Semana 1Tatiana CanizalesОценок пока нет
- PD 09Документ4 страницыPD 09karlaОценок пока нет