Вам также может понравиться
- Ijetr022661 PDFДокумент3 страницыIjetr022661 PDFerpublicationОценок пока нет
- ULPFA: A New Efficient Design of A Power-Aware Full AdderДокумент9 страницULPFA: A New Efficient Design of A Power-Aware Full AdderDeepak RajeshОценок пока нет
- Control of Automated Guided Vehicle With PLC SIMATIC ET200S CPUДокумент7 страницControl of Automated Guided Vehicle With PLC SIMATIC ET200S CPUOye PradeepОценок пока нет
- A New Design For Array Multiplier With Trade Off in Power and AreaДокумент6 страницA New Design For Array Multiplier With Trade Off in Power and Areavenkat301485Оценок пока нет
- 20230914021427an Ultra Low Voltage Level Shifter With Embedded Re Configurable Logic and Time Borrowing Latch TechniДокумент7 страниц20230914021427an Ultra Low Voltage Level Shifter With Embedded Re Configurable Logic and Time Borrowing Latch Techni15022000rskushalОценок пока нет
- Online Detection and Location of Partial Discharges in MV CablesДокумент207 страницOnline Detection and Location of Partial Discharges in MV CablesFikre HailuОценок пока нет
- 2013 2014 Report1Документ64 страницы2013 2014 Report1Christian Gonzalez ArandaОценок пока нет
- Dynamic Testing of An IEC 61850 Based - JPEE - 2014091714182282Документ10 страницDynamic Testing of An IEC 61850 Based - JPEE - 2014091714182282Diego Quintana ValenzuelaОценок пока нет
- Fault Detection Method Using A Convolution Neural Network For Hybrid Active Neutral-Point Clamped InvertersДокумент11 страницFault Detection Method Using A Convolution Neural Network For Hybrid Active Neutral-Point Clamped InvertersareejОценок пока нет
- Advanced Computer Architecture 2Документ17 страницAdvanced Computer Architecture 2Pritesh PawarОценок пока нет
- Low-Power and Area-Efficient Shift Register Using Pulsed LatchДокумент5 страницLow-Power and Area-Efficient Shift Register Using Pulsed LatchGowtham SpОценок пока нет
- Parallel Self Timed AdderДокумент5 страницParallel Self Timed AdderjayaprasadkalluriОценок пока нет
- Recursive Approach To The Design of A Parallel Self-Timed Adder PDFДокумент5 страницRecursive Approach To The Design of A Parallel Self-Timed Adder PDFgestОценок пока нет
- TIE2014High PerformanceIndirectCurrentControlScheme PDFДокумент11 страницTIE2014High PerformanceIndirectCurrentControlScheme PDFPABLO MAUROОценок пока нет
- Fault Tolerance in Active Power Filters, Based On Multilevel NPC TopologyДокумент6 страницFault Tolerance in Active Power Filters, Based On Multilevel NPC TopologyEdsonОценок пока нет
- Co_ordination_of_Overcurrent_Relay_for_ChemistryДокумент4 страницыCo_ordination_of_Overcurrent_Relay_for_ChemistryChú cún sa mạcОценок пока нет
- The Design of A Simple Asynchronous ProcessorДокумент6 страницThe Design of A Simple Asynchronous ProcessorRashika MadanОценок пока нет
- Reusable Delay Path Synthesis For LighteningДокумент14 страницReusable Delay Path Synthesis For LighteningTRIAD TECHNO SERVICESОценок пока нет
- A Synthesisable Quasi-Delay Insensitive Result Forwarding Unit For An Asynchronous ProcessorДокумент8 страницA Synthesisable Quasi-Delay Insensitive Result Forwarding Unit For An Asynchronous ProcessorHoogahОценок пока нет
- Applying Synchronous Condenser For Damping Provision in Converter-Dominated Power SystemДокумент10 страницApplying Synchronous Condenser For Damping Provision in Converter-Dominated Power SystemAndré LuizОценок пока нет
- Mllcrolplpellnes: Ivan E. SutherlandДокумент19 страницMllcrolplpellnes: Ivan E. SutherlandKonstantin SelyuninОценок пока нет
- Welcome To International Journal of Engineering Research and Development (IJERD)Документ6 страницWelcome To International Journal of Engineering Research and Development (IJERD)IJERDОценок пока нет
- High Order Programmable and Tunable Analog Filter ICДокумент16 страницHigh Order Programmable and Tunable Analog Filter ICRahil JainОценок пока нет
- Low Cost Microcontroller Based Implementation of Modulation Techniques For Three-Phase Inverter ApplicationsДокумент7 страницLow Cost Microcontroller Based Implementation of Modulation Techniques For Three-Phase Inverter ApplicationsAijaz AhmedОценок пока нет
- Single Flux Quantum Circuit Technology Innovation For Backbone Router ApplicationsДокумент7 страницSingle Flux Quantum Circuit Technology Innovation For Backbone Router ApplicationsMAZEN S MALОценок пока нет
- Synchronism-Check Application Over A Wide-Area Network: Mercury Schweitzer Engineering Laboratories, IncДокумент8 страницSynchronism-Check Application Over A Wide-Area Network: Mercury Schweitzer Engineering Laboratories, IncEngr Fahimuddin QureshiОценок пока нет
- SDH PДокумент21 страницаSDH PVinicius GiovaneliОценок пока нет
- Adaptive Pipeline Depth Control For Processor Power ManagementДокумент4 страницыAdaptive Pipeline Depth Control For Processor Power ManagementPhuc HoangОценок пока нет
- Dynamic and Fair Management of Flow Routing in Openflow: June 2015Документ3 страницыDynamic and Fair Management of Flow Routing in Openflow: June 2015yaumilagusОценок пока нет
- Clear OnДокумент6 страницClear OnAbdalmoedAlaiashyОценок пока нет
- A Scalable Distributed Asynchronous Control Network For High Level Synthesis of Digital CircuitsДокумент4 страницыA Scalable Distributed Asynchronous Control Network For High Level Synthesis of Digital CircuitsVaishnavi B VОценок пока нет
- SPWM-based D - Digital Control For Paralleled 3 - Grid-Connected Inverters PDFДокумент7 страницSPWM-based D - Digital Control For Paralleled 3 - Grid-Connected Inverters PDF张明Оценок пока нет
- ISSN: 1311-8080 (Printed Version) ISSN: 1314-3395 (On-Line Version) Url: HTTP://WWW - Ijpam.eu Special IssueДокумент6 страницISSN: 1311-8080 (Printed Version) ISSN: 1314-3395 (On-Line Version) Url: HTTP://WWW - Ijpam.eu Special IssueSpandana RadhakrishnaОценок пока нет
- Design and Analysis of Phase Locked Loop in 90mm CmosДокумент7 страницDesign and Analysis of Phase Locked Loop in 90mm CmosabhishekОценок пока нет
- CMOS Digital Integrated Circuits - Analysis & DesignДокумент8 страницCMOS Digital Integrated Circuits - Analysis & DesignsykkesОценок пока нет
- IJETR032239Документ5 страницIJETR032239erpublicationОценок пока нет
- Improved Clock-Gating Control Scheme For Transparent PipelineДокумент6 страницImproved Clock-Gating Control Scheme For Transparent PipelineFabian ZamoraОценок пока нет
- A New Subthreshold Current-Mode Four Quadrant MultiplierДокумент6 страницA New Subthreshold Current-Mode Four Quadrant MultiplierEditor IJRITCCОценок пока нет
- SSB TransmitterДокумент19 страницSSB TransmitterShahrim MohdОценок пока нет
- PHD Thesis LiserreДокумент9 страницPHD Thesis LiserreShantha Kumar100% (1)
- Home Network Power-Line Communication Signal Processing Based On Wavelet Packet AnalysisДокумент7 страницHome Network Power-Line Communication Signal Processing Based On Wavelet Packet AnalysisAmir Al-ashtalОценок пока нет
- Online Monitoring of Underground Cables Using Low-Cost SensorsДокумент4 страницыOnline Monitoring of Underground Cables Using Low-Cost SensorspipotxОценок пока нет
- Reducing Power Consumption With Relaxed Quasi Delay-Insensitive CircuitsДокумент10 страницReducing Power Consumption With Relaxed Quasi Delay-Insensitive CircuitskattasrinivasОценок пока нет
- Low-Voltage Low-Overhead Asynchronous LogicДокумент6 страницLow-Voltage Low-Overhead Asynchronous LogicJon DCОценок пока нет
- Artificial Neural Network Based Approach To Analyze Transient Overvoltages During Capacitor Banks SwitchingДокумент8 страницArtificial Neural Network Based Approach To Analyze Transient Overvoltages During Capacitor Banks SwitchingFirly Azka NОценок пока нет
- ECE1352 Phase Interpolating Circuits Reading: Implementations and ApplicationsДокумент21 страницаECE1352 Phase Interpolating Circuits Reading: Implementations and Applicationsreader_188Оценок пока нет
- Evaluation of Travelling Wave Based Protection SCHДокумент6 страницEvaluation of Travelling Wave Based Protection SCHGeorge Ariel SantillánОценок пока нет
- Performance and Protocol Improvements For Very High Speed Optical Fiber Local Area Networks Using A Passive Star TopologyДокумент11 страницPerformance and Protocol Improvements For Very High Speed Optical Fiber Local Area Networks Using A Passive Star TopologyPrabhmandeep DhillonОценок пока нет
- QPSK Mod&Demodwith NoiseДокумент32 страницыQPSK Mod&Demodwith Noisemanaswini thogaruОценок пока нет
- Power Quality Improvement in Transmission Line Using DPFCДокумент7 страницPower Quality Improvement in Transmission Line Using DPFCVIVA-TECH IJRIОценок пока нет
- Synchronization in Asynchronously Communicating Digital SystemsДокумент8 страницSynchronization in Asynchronously Communicating Digital SystemsBilal Ahmed MalikОценок пока нет
- On The Implementation of Advanced Hybrid Controllers of AC/DC ConvertersДокумент7 страницOn The Implementation of Advanced Hybrid Controllers of AC/DC ConvertersRamón MirelesОценок пока нет
- Chapter 2, Traffic Detector Handbook - Third Edition-Volume I - FHWA-HRT-06-108Документ45 страницChapter 2, Traffic Detector Handbook - Third Edition-Volume I - FHWA-HRT-06-108Amarnath M Damodaran100% (1)
- IEC20 206185020 20Substation20Automation20based20on20IECДокумент7 страницIEC20 206185020 20Substation20Automation20based20on20IECGustavo CasabonaОценок пока нет
- Smart Metering For Low Voltage Using Arduino Due PDFДокумент6 страницSmart Metering For Low Voltage Using Arduino Due PDFUmeshОценок пока нет
- Test AbilityДокумент13 страницTest AbilityGaurav MehraОценок пока нет
- J MSR 11 2011Документ9 страницJ MSR 11 2011Horacio DorantesОценок пока нет
- Flip-Flop Grouping in Data-Driven Clock Gating: Varghese James A, Divya S, Seena GeorgeДокумент9 страницFlip-Flop Grouping in Data-Driven Clock Gating: Varghese James A, Divya S, Seena GeorgeDigvijay ReddyОценок пока нет
- Automatic Tuning of Cascaded Controllers for Power Converters using Eigenvalue Parametric SensitivitiesДокумент11 страницAutomatic Tuning of Cascaded Controllers for Power Converters using Eigenvalue Parametric SensitivitiesAdnan KutsiОценок пока нет
- Signal Integrity: From High-Speed to Radiofrequency ApplicationsОт EverandSignal Integrity: From High-Speed to Radiofrequency ApplicationsОценок пока нет
- DesigningHighspeedSequentialCircuits DraftДокумент15 страницDesigningHighspeedSequentialCircuits DraftaliqpskОценок пока нет
- Quantum Mechanics Postulates ExplainedДокумент1 страницаQuantum Mechanics Postulates ExplainedaliqpskОценок пока нет
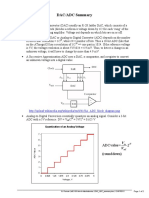
- DAC ADC SummaryДокумент2 страницыDAC ADC SummaryaliqpskОценок пока нет
- Adc F08Документ57 страницAdc F08Bhupati MakupallyОценок пока нет
- Notes OpampДокумент26 страницNotes OpampmamadhubalaОценок пока нет
- Lect08-2optimized 2Документ8 страницLect08-2optimized 2purwant10168Оценок пока нет
- ECE380 Intro to Digital Logic DesignДокумент6 страницECE380 Intro to Digital Logic DesignMoHsin KhОценок пока нет
- Complete Floor Coverage in Cleaning Robots Using Lateral Ultrasonic SensorsДокумент4 страницыComplete Floor Coverage in Cleaning Robots Using Lateral Ultrasonic SensorsaliqpskОценок пока нет
- Lecture 14Документ15 страницLecture 14aliqpskОценок пока нет
- How To Upgrade TP-LINK Wireless N Router (0.1&1.1)Документ3 страницыHow To Upgrade TP-LINK Wireless N Router (0.1&1.1)ALEJANDROОценок пока нет
- 823 PDFДокумент23 страницы823 PDFYoucef BenanibaОценок пока нет
- Trig functions, derivatives, properties & limitsДокумент4 страницыTrig functions, derivatives, properties & limitsaliqpskОценок пока нет
- Min Max TermДокумент8 страницMin Max TermAj CruzОценок пока нет
- 823 PDFДокумент23 страницы823 PDFYoucef BenanibaОценок пока нет
- Lecture On Numerical PDFДокумент3 страницыLecture On Numerical PDFaliqpskОценок пока нет
- Tip 122Документ4 страницыTip 122api-3827473Оценок пока нет
- The Detection of Fault-Prone Program Using A Neural NetworkДокумент6 страницThe Detection of Fault-Prone Program Using A Neural NetworkaliqpskОценок пока нет
- Fourier Transform of A Rectangular Pulse FunctionДокумент1 страницаFourier Transform of A Rectangular Pulse FunctionaliqpskОценок пока нет
- 81 81 1 PBДокумент7 страниц81 81 1 PBediabcОценок пока нет
- Active Filter Design and Specification For Control of Harmonics in Industrial and Commercial FacilitiesДокумент9 страницActive Filter Design and Specification For Control of Harmonics in Industrial and Commercial FacilitiestomgilmartinОценок пока нет
- Active Filter Design and Specification For Control of Harmonics in Industrial and Commercial FacilitiesДокумент9 страницActive Filter Design and Specification For Control of Harmonics in Industrial and Commercial FacilitiestomgilmartinОценок пока нет
- Lcleeresume 2008Документ9 страницLcleeresume 2008aliqpskОценок пока нет
- NewsletterДокумент1 страницаNewsletterapi-365545958Оценок пока нет
- Latest Ku ReportДокумент29 страницLatest Ku Reportsujeet.jha.311Оценок пока нет
- Qatar Star Network - As of April 30, 2019Документ7 страницQatar Star Network - As of April 30, 2019Gends DavoОценок пока нет
- Compassion and AppearancesДокумент9 страницCompassion and AppearancesriddhiОценок пока нет
- AmulДокумент4 страницыAmulR BОценок пока нет
- Writing Assessment and Evaluation Checklist - PeerДокумент1 страницаWriting Assessment and Evaluation Checklist - PeerMarlyn Joy YaconОценок пока нет
- Marylebone Construction UpdateДокумент2 страницыMarylebone Construction UpdatePedro SousaОценок пока нет
- List/Status of 655 Projects Upto 5.00 MW Capacity As On TodayДокумент45 страницList/Status of 655 Projects Upto 5.00 MW Capacity As On Todayganvaqqqzz21Оценок пока нет
- PORT DEVELOPMENT in MALAYSIAДокумент25 страницPORT DEVELOPMENT in MALAYSIAShhkyn MnОценок пока нет
- ScriptsДокумент6 страницScriptsDx CatОценок пока нет
- Who Are The Prosperity Gospel Adherents by Bradley A KochДокумент46 страницWho Are The Prosperity Gospel Adherents by Bradley A KochSimon DevramОценок пока нет
- Shilajit The Panacea For CancerДокумент48 страницShilajit The Panacea For Cancerliving63100% (1)
- Alluring 60 Dome MosqueДокумент6 страницAlluring 60 Dome Mosqueself sayidОценок пока нет
- LS1 Eng. Modules With Worksheets (Figure of Speech)Документ14 страницLS1 Eng. Modules With Worksheets (Figure of Speech)Bong CardonaОценок пока нет
- M8 UTS A. Sexual SelfДокумент10 страницM8 UTS A. Sexual SelfAnon UnoОценок пока нет
- Comparing and contrasting inductive learning and concept attainment strategiesДокумент3 страницыComparing and contrasting inductive learning and concept attainment strategiesKeira DesameroОценок пока нет
- SK Council Authorizes New Bank AccountДокумент3 страницыSK Council Authorizes New Bank Accountt3emo shikihiraОценок пока нет
- Cambridge IGCSE: 0500/12 First Language EnglishДокумент16 страницCambridge IGCSE: 0500/12 First Language EnglishJonathan ChuОценок пока нет
- Block 2 MVA 026Документ48 страницBlock 2 MVA 026abhilash govind mishraОценок пока нет
- Bazi BasicopdfДокумент54 страницыBazi BasicopdfThe3fun SistersОценок пока нет
- 3 QДокумент2 страницы3 QJerahmeel CuevasОценок пока нет
- Week 1 ITM 410Документ76 страницWeek 1 ITM 410Awesom QuenzОценок пока нет
- Booklet - CopyxДокумент20 страницBooklet - CopyxHåkon HallenbergОценок пока нет
- Statement. Cash.: M.B.A. Semester-Ill Exadinatioh Working Capital Management Paper-Mba/3103/FДокумент2 страницыStatement. Cash.: M.B.A. Semester-Ill Exadinatioh Working Capital Management Paper-Mba/3103/FPavan BasundeОценок пока нет
- Tattva Sandoha PujaДокумент2 страницыTattva Sandoha PujaSathis KumarОценок пока нет
- Food and ReligionДокумент8 страницFood and ReligionAniket ChatterjeeОценок пока нет
- English Course SyllabusДокумент3 страницыEnglish Course Syllabusalea rainОценок пока нет
- Accounting What The Numbers Mean 11th Edition Marshall Solutions Manual 1Документ36 страницAccounting What The Numbers Mean 11th Edition Marshall Solutions Manual 1amandawilkinsijckmdtxez100% (23)
- Navavarana ArticleДокумент9 страницNavavarana ArticleSingaperumal NarayanaОценок пока нет
- Ausensi (2020) A New Resultative Construction in SpanishДокумент29 страницAusensi (2020) A New Resultative Construction in SpanishcfmaОценок пока нет