Вам также может понравиться
- Recommendation SystemДокумент4 страницыRecommendation SystemNishant TripathiОценок пока нет
- Data Analytics - ClusteringДокумент2 страницыData Analytics - ClusteringNishant TripathiОценок пока нет
- Top 20 Machine Learning ResourcesДокумент6 страницTop 20 Machine Learning ResourcesNishant TripathiОценок пока нет
- CS229 Machine Learning CheatsheetДокумент16 страницCS229 Machine Learning Cheatsheetsercharnaud100% (1)
- ShayariДокумент2 страницыShayariNishant TripathiОценок пока нет
- Cart and c5.0Документ5 страницCart and c5.0Nishant TripathiОценок пока нет
- Forecast Time Series-NotesДокумент138 страницForecast Time Series-NotesflorinОценок пока нет
- Unnamed: 0 Sample Rock - Type Sio2 Tio2 Al2O3 Fe2O3 Mno Mgo Cao Na2O K2O P2O5 0 0 1 1 2 2 3 3 4 4Документ1 страницаUnnamed: 0 Sample Rock - Type Sio2 Tio2 Al2O3 Fe2O3 Mno Mgo Cao Na2O K2O P2O5 0 0 1 1 2 2 3 3 4 4Nishant TripathiОценок пока нет
- Course Outline Aacsb Mba 611 Management AccountingДокумент6 страницCourse Outline Aacsb Mba 611 Management AccountingNishant TripathiОценок пока нет
- BI QuestionsДокумент13 страницBI Questionsdkanand86Оценок пока нет
- Letter WritingДокумент14 страницLetter WritingNishant TripathiОценок пока нет
- Price Elasticity of Demand: Lecture #2Документ50 страницPrice Elasticity of Demand: Lecture #2Bokajgovic NenadОценок пока нет
- MemorandumДокумент8 страницMemorandumNishant TripathiОценок пока нет
- Letter WritingДокумент14 страницLetter WritingNishant TripathiОценок пока нет
- Reference List of Synonyms PDFДокумент18 страницReference List of Synonyms PDFpiyush13juОценок пока нет
- EssaysДокумент215 страницEssaysNishant TripathiОценок пока нет
- (WWW - Entrance-Exam - Net) - EIL Placement Sample Paper 1Документ15 страниц(WWW - Entrance-Exam - Net) - EIL Placement Sample Paper 1pushkal786Оценок пока нет
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5783)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (890)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (265)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (344)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2219)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (119)
- UCS C Series Rack Servers CLI Commands For Troubleshooting HDD IssuesДокумент5 страницUCS C Series Rack Servers CLI Commands For Troubleshooting HDD IssuesYrving BlancoОценок пока нет
- Serial Port Communication LabviewДокумент5 страницSerial Port Communication Labviewpj_bank100% (2)
- Ergonomics in Game Controllers and ConsolesДокумент5 страницErgonomics in Game Controllers and ConsolesAlex GregorieОценок пока нет
- The Best Web App To Convert JPG To PDFДокумент1 страницаThe Best Web App To Convert JPG To PDFJekly MoningkaОценок пока нет
- Curso Execution in SAP Transportation Management - Modulo 1Документ67 страницCurso Execution in SAP Transportation Management - Modulo 1reibeltorresОценок пока нет
- 8251 PciДокумент14 страниц8251 PciSoham ChatterjeeОценок пока нет
- Activity Exemplar Product BacklogДокумент4 страницыActivity Exemplar Product BacklogHello Kitty100% (2)
- Attendance Management System Using Barco PDFДокумент7 страницAttendance Management System Using Barco PDFJohnrich GarciaОценок пока нет
- TLE - Davao Room Assignments For September 2013 LETДокумент53 страницыTLE - Davao Room Assignments For September 2013 LETScoopBoyОценок пока нет
- Canoscan 5600fДокумент8 страницCanoscan 5600fRadenko RasevicОценок пока нет
- KMP Algorithm - Find Patterns in Linear TimeДокумент4 страницыKMP Algorithm - Find Patterns in Linear TimeGrama SilviuОценок пока нет
- Aliza JaneДокумент3 страницыAliza Janeواجد چوھدریОценок пока нет
- Unit One - Supervise The Identification of Types of Information and Commonly Created Office RecordsДокумент44 страницыUnit One - Supervise The Identification of Types of Information and Commonly Created Office RecordsArefayne EsheteОценок пока нет
- ASaP LNG Sampler Brochure 01-2018Документ5 страницASaP LNG Sampler Brochure 01-2018Arfan NОценок пока нет
- Introduction To InformaticsДокумент16 страницIntroduction To InformaticsBenjamin FlavianОценок пока нет
- Python & Spark for Big Data ProcessingДокумент2 страницыPython & Spark for Big Data ProcessingsfazistОценок пока нет
- 2.BP Travel - Create Quotes - Process Definition Document (PDD)Документ15 страниц2.BP Travel - Create Quotes - Process Definition Document (PDD)jeevaОценок пока нет
- Comptia Security Sy0 701 Exam Objectives (5 0)Документ21 страницаComptia Security Sy0 701 Exam Objectives (5 0)Erick Camilo50% (4)
- Crop Yield Prediction Using Random Forest AlgorithmДокумент11 страницCrop Yield Prediction Using Random Forest AlgorithmVj KumarОценок пока нет
- OmegaДокумент7 страницOmegaSuzanne KiteОценок пока нет
- AR Research PaperДокумент18 страницAR Research PaperShresh KumarОценок пока нет
- US23-0920-02 UniSlide Install Manual Rev D (12!16!2010)Документ72 страницыUS23-0920-02 UniSlide Install Manual Rev D (12!16!2010)sq9memОценок пока нет
- Cambridge Assessment International Education: Computer Science 2210/13 October/November 2019Документ14 страницCambridge Assessment International Education: Computer Science 2210/13 October/November 2019Sarim JavedОценок пока нет
- CT TAE 1 Vaibhav DeshpandeДокумент5 страницCT TAE 1 Vaibhav Deshpandedobari8717Оценок пока нет
- Lecture 5 Principles of Parallel Algorithm DesignДокумент30 страницLecture 5 Principles of Parallel Algorithm Designnimranoor137Оценок пока нет
- PFB2N60/PFF2N60 DatasheetДокумент7 страницPFB2N60/PFF2N60 DatasheetCostel CojocaruОценок пока нет
- CAE BrochureДокумент8 страницCAE BrochurecimasukОценок пока нет
- CTRPF AR Cheat Code DatabaseДокумент180 страницCTRPF AR Cheat Code DatabaseIndraSwacharyaОценок пока нет
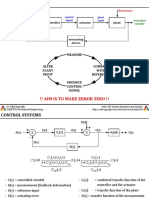
- CONTROL SYSTEMS: MINIMIZING ERRORSДокумент11 страницCONTROL SYSTEMS: MINIMIZING ERRORScapturemrahОценок пока нет
- AFFIDAVIT OF ONE AND THE SAME PERSON - FRM EmailДокумент2 страницыAFFIDAVIT OF ONE AND THE SAME PERSON - FRM EmailAnna Ray Eleanor De GuiaОценок пока нет