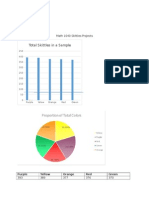
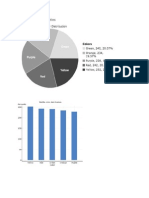
Вам также может понравиться
- Skittles Project 2Документ5 страницSkittles Project 2api-355504623Оценок пока нет
- Skittles Project Stats 1040Документ8 страницSkittles Project Stats 1040api-301336765Оценок пока нет
- Skittles 2 FinalДокумент12 страницSkittles 2 Finalapi-242194552Оценок пока нет
- Team Project Part 6 Final ReportДокумент8 страницTeam Project Part 6 Final Reportapi-316794103Оценок пока нет
- Stats ProjectДокумент14 страницStats Projectapi-302666758Оценок пока нет
- Skittles ProДокумент9 страницSkittles Proapi-241124972Оценок пока нет
- SkittlesДокумент7 страницSkittlesapi-244615173Оценок пока нет
- Final ProjectДокумент9 страницFinal Projectapi-262329757Оценок пока нет
- Skittles Project CompleteДокумент8 страницSkittles Project Completeapi-312645878Оценок пока нет
- The Rainbow ReportДокумент11 страницThe Rainbow Reportapi-316991888Оценок пока нет
- Skittles Proyect Part 5Документ7 страницSkittles Proyect Part 5api-509398997Оценок пока нет
- Skittles FinalДокумент7 страницSkittles Finalapi-470226556Оценок пока нет
- Skittles Project 2Документ10 страницSkittles Project 2api-316655135Оценок пока нет
- Final ProjectДокумент3 страницыFinal Projectapi-265661554Оценок пока нет
- Skittle Pareto ChartДокумент7 страницSkittle Pareto Chartapi-272391081Оценок пока нет
- Math 1040 Term ProjectДокумент7 страницMath 1040 Term Projectapi-340188424Оценок пока нет
- Skittles ProjectДокумент5 страницSkittles Projectapi-271444168Оценок пока нет
- Skittles Project - My Page VersionДокумент22 страницыSkittles Project - My Page Versionapi-272829351Оценок пока нет
- Final ProjectДокумент6 страницFinal Projectapi-283261340Оценок пока нет
- Skittles Project Part 1Документ6 страницSkittles Project Part 1api-457501806Оценок пока нет
- Skittles Term Project 11 9 14Документ5 страницSkittles Term Project 11 9 14api-192489685Оценок пока нет
- Math 1040 Statistics Term Project: Blake FreemanДокумент10 страницMath 1040 Statistics Term Project: Blake Freemanapi-252919218Оценок пока нет
- SkittlesdataclassprojectДокумент8 страницSkittlesdataclassprojectapi-399586872Оценок пока нет
- TP 2 StatsДокумент5 страницTP 2 Statsapi-240850453Оценок пока нет
- Final Stats ProjectДокумент8 страницFinal Stats Projectapi-238717717100% (2)
- Skittles Project 1Документ7 страницSkittles Project 1api-299868669100% (2)
- Project FinalДокумент10 страницProject Finalapi-300399896Оценок пока нет
- EportfolioДокумент8 страницEportfolioapi-242211470Оценок пока нет
- Term Project ReportДокумент9 страницTerm Project Reportapi-238585685Оценок пока нет
- Math 1040 Skittles Term ProjectДокумент10 страницMath 1040 Skittles Term Projectapi-310671451Оценок пока нет
- Math 1040 Skittles Term ProjectДокумент9 страницMath 1040 Skittles Term Projectapi-319881085Оценок пока нет
- Skittles Term ProjectДокумент10 страницSkittles Term Projectapi-273060240Оценок пока нет
- The Full Skittles ProjectДокумент6 страницThe Full Skittles Projectapi-340271527100% (1)
- Skittles ReportДокумент5 страницSkittles Reportapi-242736484Оценок пока нет
- Term Project - EportfolioДокумент7 страницTerm Project - Eportfolioapi-251981709Оценок пока нет
- Skittles ReportДокумент9 страницSkittles Reportapi-311878992Оценок пока нет
- Skittles Project Math 1040Документ8 страницSkittles Project Math 1040api-495044194Оценок пока нет
- Skittles Final ProjectДокумент5 страницSkittles Final Projectapi-251571777Оценок пока нет
- The Skittles Project FinalДокумент8 страницThe Skittles Project Finalapi-316760667Оценок пока нет
- 1040 ProjectДокумент4 страницы1040 Projectapi-279808770Оценок пока нет
- Comprehensive Skittles Project Math 1040Документ7 страницComprehensive Skittles Project Math 1040api-316732019Оценок пока нет
- Skittles AssignmentДокумент8 страницSkittles Assignmentapi-291800396Оценок пока нет
- Group Project #1 - SkittlesДокумент9 страницGroup Project #1 - Skittlesapi-245266056Оценок пока нет
- Reflection and EportfolioДокумент8 страницReflection and Eportfolioapi-252747849Оценок пока нет
- Skittles ProjectДокумент6 страницSkittles Projectapi-495018964Оценок пока нет
- Full Skittles ProjectДокумент13 страницFull Skittles Projectapi-537189505Оценок пока нет
- Skittles 2Документ4 страницыSkittles 2api-437551719Оценок пока нет
- Skittles ProjectДокумент9 страницSkittles Projectapi-242873849Оценок пока нет
- Final Project 2017Документ7 страницFinal Project 2017api-314058561Оценок пока нет
- Stats StuffДокумент7 страницStats Stuffapi-242298926Оценок пока нет
- Skittles Project 5-02Документ8 страницSkittles Project 5-02api-354040698Оценок пока нет
- Term Project Part 8Документ9 страницTerm Project Part 8api-242224172Оценок пока нет
- Skittles FinalДокумент12 страницSkittles Finalapi-241861434Оценок пока нет
- The Science of Collecting, Organizing, Summarizing, and Analyzing Information To Draw Conclusions or Answer QuestionsДокумент7 страницThe Science of Collecting, Organizing, Summarizing, and Analyzing Information To Draw Conclusions or Answer Questionsapi-438148756Оценок пока нет
- Skittles ReportДокумент15 страницSkittles Reportapi-271901299Оценок пока нет
- Skittles Statistics ProjectДокумент9 страницSkittles Statistics Projectapi-325825295Оценок пока нет
- Skittles ProjectДокумент4 страницыSkittles Projectapi-299945887Оценок пока нет
- Skittles WordДокумент5 страницSkittles Wordapi-285645725Оценок пока нет
- Croot Part6 EportfolioДокумент16 страницCroot Part6 Eportfolioapi-276896975Оценок пока нет
- Diabetes Kats NutritionДокумент6 страницDiabetes Kats Nutritionapi-303044832Оценок пока нет
- EportfolioДокумент1 страницаEportfolioapi-303044832Оценок пока нет
- EportfolioДокумент1 страницаEportfolioapi-303044832Оценок пока нет
- Reflective Writing PieceДокумент2 страницыReflective Writing Pieceapi-303044832Оценок пока нет
- Education in U S AДокумент9 страницEducation in U S Aapi-303044832Оценок пока нет
- Last Project For Math 1040Документ15 страницLast Project For Math 1040api-303044832Оценок пока нет
- Last Project For Math 1040Документ15 страницLast Project For Math 1040api-303044832Оценок пока нет
- Biology Lab SummaryДокумент4 страницыBiology Lab Summaryapi-303044832Оценок пока нет
- How To Make Mango and Sticky RiceДокумент10 страницHow To Make Mango and Sticky Riceapi-303044832Оценок пока нет
- MATH 204 - LESSON 3 - Statistical GraphsДокумент2 страницыMATH 204 - LESSON 3 - Statistical GraphsFmega jemОценок пока нет
- Jitter DistributionДокумент7 страницJitter DistributionMahesh MahiОценок пока нет
- Brooks, Suchey 1990 PDFДокумент12 страницBrooks, Suchey 1990 PDFEDAОценок пока нет
- Kartik Lab Assignment DocumentedДокумент75 страницKartik Lab Assignment DocumentedKartik SujanОценок пока нет
- Chapter 2 Methods of Data Collection and OrganizingДокумент82 страницыChapter 2 Methods of Data Collection and OrganizingGetabalew EndazenawОценок пока нет
- Quality Management Review TemplateДокумент12 страницQuality Management Review Templateselinasimpson321Оценок пока нет
- Business Analytics: Describing The Distribution of A Single VariableДокумент58 страницBusiness Analytics: Describing The Distribution of A Single VariableQuỳnh Anh NguyễnОценок пока нет
- Lesson 9 - Binomial Distributions: Return To Cover PageДокумент6 страницLesson 9 - Binomial Distributions: Return To Cover PagezaenalkmiОценок пока нет
- RWTH Bachelor Advanced Lab Course - Gaseous Ionisation DetectorsДокумент26 страницRWTH Bachelor Advanced Lab Course - Gaseous Ionisation DetectorsEnzo SanfratelloОценок пока нет
- Study Test For Fundamentals of StatisticsДокумент14 страницStudy Test For Fundamentals of StatisticsRaphael AtiyehОценок пока нет
- Learning Book - AnyLogic 6 Enterprise Library Tutorial PDFДокумент43 страницыLearning Book - AnyLogic 6 Enterprise Library Tutorial PDFhoussem eddineОценок пока нет
- Taxi Deployment: Data Extraction and IntroductionДокумент16 страницTaxi Deployment: Data Extraction and IntroductionAnand SharmaОценок пока нет
- Magnets and Pain ProjectДокумент6 страницMagnets and Pain Projectapi-31712503650% (2)
- Sheet 3 StatДокумент3 страницыSheet 3 Statmariamh01247Оценок пока нет
- PRELIS Examples Guide PDFДокумент78 страницPRELIS Examples Guide PDFHidayah Ina QodriyaniОценок пока нет
- 2 Graphical Descriptive TechniquesДокумент49 страниц2 Graphical Descriptive TechniquesYenoh SisoОценок пока нет
- Best Practices Managing Optimizer StatisticsДокумент69 страницBest Practices Managing Optimizer StatisticsmcarmenzvaОценок пока нет
- Using GAN-Based Encryption To Secure Digital Images With Reconstruction Through Customized Super Resolution NetworkДокумент8 страницUsing GAN-Based Encryption To Secure Digital Images With Reconstruction Through Customized Super Resolution NetworkabcОценок пока нет
- Bafbana Module 5Документ12 страницBafbana Module 5VILLANUEVA, RAQUEL NONAОценок пока нет
- Describing Data:: Frequency Tables, Frequency Distributions, and Graphic PresentationДокумент15 страницDescribing Data:: Frequency Tables, Frequency Distributions, and Graphic PresentationImam AwaluddinОценок пока нет
- Bin Frequencycumulative % Bin Frequencycumulative %Документ42 страницыBin Frequencycumulative % Bin Frequencycumulative %Mohamed RizwanОценок пока нет
- Wayne DanielДокумент186 страницWayne Danielkmeena73100% (6)
- Sta108 Group Project - As1204iДокумент25 страницSta108 Group Project - As1204iKiddo KyokolaОценок пока нет
- Ken Black QA ch02Документ28 страницKen Black QA ch02Rushabh VoraОценок пока нет
- 21BBST08P - Statistics - Sheet 3Документ9 страниц21BBST08P - Statistics - Sheet 3naglaa alyОценок пока нет
- HTTPS:WWW Clinicalkey Com:service:content:pdf:watermarked:3-S2 0-B9780702066962000023 Pdf?locale en - US&searchIndexДокумент10 страницHTTPS:WWW Clinicalkey Com:service:content:pdf:watermarked:3-S2 0-B9780702066962000023 Pdf?locale en - US&searchIndexJenifer Magdalena BolangОценок пока нет
- Aea 501Документ156 страницAea 501Folasade ElizabethОценок пока нет
- Statistics MCQ'S I.Com Part 2Документ8 страницStatistics MCQ'S I.Com Part 2Shafique Ur Rehman82% (17)
- Problem Solving Tools: Training Module OnДокумент46 страницProblem Solving Tools: Training Module Onmiso73Оценок пока нет
- Analyzing Histograms TaskДокумент6 страницAnalyzing Histograms Taskapi-298215585Оценок пока нет