Вам также может понравиться
- Normalización y Dependencia FuncionalДокумент7 страницNormalización y Dependencia FuncionalHernando Rodríguez QuinteroОценок пока нет
- Teorema de NyquistДокумент2 страницыTeorema de NyquistJose ColungaОценок пока нет
- Conectividad en BDДокумент15 страницConectividad en BDmendez gabrielОценок пока нет
- Cuadro Comparativo 1Документ3 страницыCuadro Comparativo 1Brian RcОценок пока нет
- U4 Informe 1 - Relleno, Iluminación y SombreadoДокумент17 страницU4 Informe 1 - Relleno, Iluminación y SombreadoRafael RizoОценок пока нет
- VeraCrypt para Windows - Almacenamiento Seguro de ArchivosДокумент71 страницаVeraCrypt para Windows - Almacenamiento Seguro de ArchivosWlarry PiОценок пока нет
- Actividad Entregable - Unidad - 2 PDFДокумент5 страницActividad Entregable - Unidad - 2 PDFjaimebdОценок пока нет
- 1.2 Dispositivos PasivosДокумент7 страниц1.2 Dispositivos PasivosCarlos OcheitaОценок пока нет
- Interpolacion de LagrangeДокумент3 страницыInterpolacion de LagrangeMarlyu GuzmanОценок пока нет
- Cuadro ComparativoДокумент5 страницCuadro ComparativoAlfredo Avendaño SerranoОценок пока нет
- Unidad 3. Transformada de LaplaceДокумент20 страницUnidad 3. Transformada de LaplaceAquilino RodriguezОценок пока нет
- Instalacion Jflex y CupДокумент8 страницInstalacion Jflex y CupKaterin AmayaОценок пока нет
- Práctica No1Документ31 страницаPráctica No1javiОценок пока нет
- Arboles IntroducciónДокумент17 страницArboles IntroducciónScarlett M GonzálezОценок пока нет
- Ejemplo de Uso de Hashmap en JavaДокумент4 страницыEjemplo de Uso de Hashmap en JavaAlejandro CominaОценок пока нет
- Unidad 2 Poo Clases y ObjetosДокумент10 страницUnidad 2 Poo Clases y ObjetosKennethCoolОценок пока нет
- 7.1.4. Desarrollar Prácticas para Realizar La Conexión A La Base de Datos Desde El Lenguaje Huésped.Документ3 страницы7.1.4. Desarrollar Prácticas para Realizar La Conexión A La Base de Datos Desde El Lenguaje Huésped.Lissie Dianela Chuc UicabОценок пока нет
- Sistemas de Archivos y Recursos (NFS, Impresoras)Документ1 страницаSistemas de Archivos y Recursos (NFS, Impresoras)JESUS ABRAHAM VILLANUEVA LOERAОценок пока нет
- Emilmar Programación Estructuras PDFДокумент19 страницEmilmar Programación Estructuras PDFEmilmar Cuarez100% (1)
- Problema 24: SoluciónДокумент2 страницыProblema 24: SoluciónAlex CAОценок пока нет
- Programa de Algoritmo Congruencial MultiplicativoДокумент8 страницPrograma de Algoritmo Congruencial MultiplicativoDaniela BlancoОценок пока нет
- Mapa Conceptual DiferenciaciónДокумент2 страницыMapa Conceptual DiferenciaciónpatriciaОценок пока нет
- VRC LRC CRCДокумент2 страницыVRC LRC CRCJessica PinillosОценок пока нет
- 1.2 Conceptos Básicos de RedesДокумент3 страницы1.2 Conceptos Básicos de RedescokecarrilloОценок пока нет
- REDES Y COMUNICACIONES Actividad 2Документ5 страницREDES Y COMUNICACIONES Actividad 2oscar arangoОценок пока нет
- Equipo de Ingeniería WebДокумент6 страницEquipo de Ingeniería WebErwin Alexander Villegas TunОценок пока нет
- C3-T2 Describir Gráficamente Problemas en Términos de Espacios de EstadosДокумент3 страницыC3-T2 Describir Gráficamente Problemas en Términos de Espacios de EstadosLish GarciaОценок пока нет
- Tarea 06 VectoresДокумент2 страницыTarea 06 Vectoresandrse camacho0% (1)
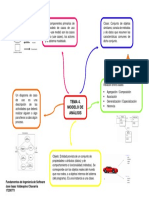
- Tema 4 Modelo de AnálisisДокумент1 страницаTema 4 Modelo de AnálisisIsaac ValdespinoОценок пока нет
- Examen de Diagnostico Conmutación y EnrutamientoДокумент2 страницыExamen de Diagnostico Conmutación y EnrutamientoAntonioJSMОценок пока нет
- Manual de Programacion en PrologДокумент33 страницыManual de Programacion en PrologWendellGarciaОценок пока нет
- SISTEMAS PROGRAMABLES (Sensores Opticos)Документ4 страницыSISTEMAS PROGRAMABLES (Sensores Opticos)alberto michelОценок пока нет
- 1.4 Modelo Matemático de Una SeñalДокумент18 страниц1.4 Modelo Matemático de Una SeñalJesús HernandezОценок пока нет
- Cuadro ComparativoДокумент2 страницыCuadro ComparativoMargenis CoelloОценок пока нет
- Informe Final SatelitalДокумент21 страницаInforme Final SatelitalwellingtonОценок пока нет
- Memoria Principal RAM-InterrupcionesДокумент7 страницMemoria Principal RAM-InterrupcionesCarlos Mtz SerranoОценок пока нет
- 6-Comportamiento de Una Señal Eléctrica y ÓpticaДокумент7 страниц6-Comportamiento de Una Señal Eléctrica y ÓpticaAngel Kauil KumulОценок пока нет
- Programación II-Unidad 1 (1-28)Документ28 страницProgramación II-Unidad 1 (1-28)christianramirez9Оценок пока нет
- Rep Prac 8 JNRS, DAGV, MAXBДокумент48 страницRep Prac 8 JNRS, DAGV, MAXBjose25% (4)
- Cartel de Texto Pasante Utilizando Matriz de Leds en Labview EditadoДокумент25 страницCartel de Texto Pasante Utilizando Matriz de Leds en Labview EditadoFISORG0% (1)
- Expresiones Regulares (Lenguajes y Autómatas)Документ11 страницExpresiones Regulares (Lenguajes y Autómatas)charitoveraaОценок пока нет
- Apuntes Procesamiento VectorialДокумент23 страницыApuntes Procesamiento VectorialLidia RondonОценок пока нет
- Ensayo Base de Datos OOs V02 - DgualeДокумент7 страницEnsayo Base de Datos OOs V02 - DgualedolferguОценок пока нет
- Fundamentos de Programación Unidad 5Документ5 страницFundamentos de Programación Unidad 5Panchoxman UrendaОценок пока нет
- Entregrable 1 Estructura de DatosДокумент6 страницEntregrable 1 Estructura de DatosAngelОценок пока нет
- Los Índices en Oracle, Creación, Eliminación, Reconstrucción Proyecto AjpdSoftДокумент11 страницLos Índices en Oracle, Creación, Eliminación, Reconstrucción Proyecto AjpdSoftcsalas71Оценок пока нет
- Unidad 4Документ12 страницUnidad 4Don CarloОценок пока нет
- Manejo de GrafosДокумент2 страницыManejo de GrafosMArtih StОценок пока нет
- Programación Orientada A Objetos (Poo)Документ8 страницProgramación Orientada A Objetos (Poo)renatoledezmaОценок пока нет
- Campo MagnéticoДокумент3 страницыCampo MagnéticoArturo Avila CamachoОценок пока нет
- Conceptos Principales Del Paradigma de POOДокумент4 страницыConceptos Principales Del Paradigma de POOvictormontalvo10Оценок пока нет
- Arquitectura de Computadores - Cuestionario ResueltoДокумент3 страницыArquitectura de Computadores - Cuestionario ResueltoJuanPabloValdiviesoMosqueraОценок пока нет
- Diseño de Redes - Cuadro Comparativo Entre Ethernet y Token RingДокумент6 страницDiseño de Redes - Cuadro Comparativo Entre Ethernet y Token RingAlex Mota TorresОценок пока нет
- Cuadro Comparativo SGBDДокумент4 страницыCuadro Comparativo SGBDjuanОценок пока нет
- Relación de RecurrenciaДокумент8 страницRelación de RecurrenciaLupita GarciaОценок пока нет
- PRACTICA 6. Modulación FM y AMДокумент16 страницPRACTICA 6. Modulación FM y AMLuis Francisco Ramos UcОценок пока нет
- Programación AsíncronaДокумент14 страницProgramación AsíncronaJuanxo CarrascoОценок пока нет
- Dependencias FuncionalesДокумент4 страницыDependencias Funcionalesribel2910Оценок пока нет
- NormalizacionДокумент71 страницаNormalizacionOrlando Choque AОценок пока нет
- Resumen de Introducción a la Lógica y al Método Científico de Cohen y Nagel: RESÚMENES UNIVERSITARIOSОт EverandResumen de Introducción a la Lógica y al Método Científico de Cohen y Nagel: RESÚMENES UNIVERSITARIOSРейтинг: 1 из 5 звезд1/5 (1)
- Plan de TesisДокумент38 страницPlan de TesisYerzyd AlconОценок пока нет
- 02 Sistema Drone FV-8 TopodronДокумент6 страниц02 Sistema Drone FV-8 Topodronjkrlos_188441100% (1)
- Paula Núñez Calleja Ortofotos DronДокумент59 страницPaula Núñez Calleja Ortofotos DronRodrigolecturaОценок пока нет
- Phantom 4 Pro Pro Plus User Manual ESДокумент67 страницPhantom 4 Pro Pro Plus User Manual ESPercy RobertОценок пока нет
- Modo CinematicoДокумент102 страницыModo CinematicoYerzyd AlconОценок пока нет
- Teledeteccion PDFДокумент520 страницTeledeteccion PDFRamos Arave100% (3)
- Drones en FotogrametríaДокумент5 страницDrones en FotogrametríalcgovpeОценок пока нет
- Evaluación - Egm08 - Egm96Документ10 страницEvaluación - Egm08 - Egm96Mary Isabel PelaezОценок пока нет
- Planeacion de Vuelos FotogrametricosДокумент18 страницPlaneacion de Vuelos FotogrametricosYerzyd AlconОценок пока нет
- Los Drones y Sus Aplicaciones A La Ingenieria Civil Fenercom 2015 PDFДокумент242 страницыLos Drones y Sus Aplicaciones A La Ingenieria Civil Fenercom 2015 PDFDayver Agustin Lopez100% (2)
- Manual Topografía Con Drones (Fotogrametria)Документ14 страницManual Topografía Con Drones (Fotogrametria)JGG CIMAQ TUTORIALES100% (3)
- Ebee X ESДокумент5 страницEbee X ESMiguel Mota100% (1)
- Drones de Exploracion PetroleraДокумент20 страницDrones de Exploracion PetroleraEmanuel Rosales Copa100% (1)
- Lista de Software 3d para Captura de Geometria Por Fotos o SimilarДокумент1 страницаLista de Software 3d para Captura de Geometria Por Fotos o SimilarYerzyd AlconОценок пока нет
- Deslizamiento en El Volcán IrazúДокумент10 страницDeslizamiento en El Volcán IrazúFloribeth Betty Vega-SolanoОценок пока нет
- Drones La Tecnologia Ventajas y Sus Posibles Aplicaciones PDFДокумент20 страницDrones La Tecnologia Ventajas y Sus Posibles Aplicaciones PDFTrabajosОценок пока нет
- EBeeX Finalversion A4 ES Compressed CompressedДокумент8 страницEBeeX Finalversion A4 ES Compressed CompressedYerzyd AlconОценок пока нет
- DronesДокумент10 страницDronesYerzyd AlconОценок пока нет
- Drones UavДокумент3 страницыDrones Uavlaszlo_ficОценок пока нет
- Drones CámarasДокумент10 страницDrones CámarasPira Einte CesúsОценок пока нет
- Fotogrametría Con DronesДокумент7 страницFotogrametría Con DronesAledj MartinezОценок пока нет
- Fotogrametria 1 ParteДокумент47 страницFotogrametria 1 ParteHenry QmОценок пока нет
- Fotogrametria 2Документ15 страницFotogrametria 2gsr600ibagueОценок пока нет
- Empleo de DronesДокумент430 страницEmpleo de Drones_jorge_aОценок пока нет
- DronesДокумент15 страницDronesCarlosEduardoRivasOchoaОценок пока нет
- Drones Ciencia Al VueloДокумент5 страницDrones Ciencia Al VueloMtro. Jorge E. LomelíОценок пока нет
- Ejemplos de Uso de Drones en GISДокумент7 страницEjemplos de Uso de Drones en GISMiguel Calle RomeroОценок пока нет
- Aplicaciones de Los Sensores Remotos en La Ing Civil Grupo 2Документ43 страницыAplicaciones de Los Sensores Remotos en La Ing Civil Grupo 2Yerzyd AlconОценок пока нет
- Curvas de NivelДокумент8 страницCurvas de NivelYerzyd AlconОценок пока нет
- Calibración de Imágenes en MapirДокумент19 страницCalibración de Imágenes en MapirdayanaОценок пока нет
- 121 PROBLEMATICA DEL DESARROLLO VENEZOLANO - SELECCION DE LECTURAS-minДокумент259 страниц121 PROBLEMATICA DEL DESARROLLO VENEZOLANO - SELECCION DE LECTURAS-minAnya GonzalezОценок пока нет
- Levantamiento Manual de CargasДокумент47 страницLevantamiento Manual de CargasCarlos Mario Agudelo EspañaОценок пока нет
- Cronograma Historia Social y Política Argentina - Lic. en Ciencias Políticas y Gobierno - 2015Документ8 страницCronograma Historia Social y Política Argentina - Lic. en Ciencias Políticas y Gobierno - 2015Inzucare GiorgiosОценок пока нет
- SESION 4 - ONG CanalesДокумент39 страницSESION 4 - ONG CanalespatricioОценок пока нет
- Teoría Psicoanalítica de La PersonalidadДокумент48 страницTeoría Psicoanalítica de La PersonalidadJohn Luis More MenorОценок пока нет
- Vida de Leonardo Da VinciДокумент1 страницаVida de Leonardo Da VinciJerson SebastianОценок пока нет
- Respuestas Evaluar para Avanzar-Cuadernillo 2 Año 2023-Primaria y SecundariaДокумент35 страницRespuestas Evaluar para Avanzar-Cuadernillo 2 Año 2023-Primaria y SecundariaClaudia patricia menoza100% (1)
- Acompañamiento Terapéutico y Vida Cotidiana - M. Laura Frank - Revista Attravesar #15Документ11 страницAcompañamiento Terapéutico y Vida Cotidiana - M. Laura Frank - Revista Attravesar #15mcarolinaceccoliОценок пока нет
- Padre Anselm GrünДокумент81 страницаPadre Anselm GrünMarisa Molto GarciaОценок пока нет
- Guion de NavidadДокумент8 страницGuion de NavidadAllen Van FanelОценок пока нет
- ÉticaДокумент5 страницÉticaKaren MezaОценок пока нет
- Taxonomía de BloomДокумент2 страницыTaxonomía de BloomTris Lopez100% (1)
- 3.1 E Mis Metas Son Significativas y Factibles GenericaДокумент3 страницы3.1 E Mis Metas Son Significativas y Factibles GenericaYamileth UMОценок пока нет
- Valores Inmanentes de La ObraДокумент3 страницыValores Inmanentes de La ObraLuciana RupayОценок пока нет
- Antonio Buero Vallejo, La Fundación (Fragmento)Документ2 страницыAntonio Buero Vallejo, La Fundación (Fragmento)anfigorey100% (1)
- Sintonia TDHДокумент4 страницыSintonia TDHANAОценок пока нет
- Comentarios Presunto InocenteДокумент48 страницComentarios Presunto InocenteLetras LibresОценок пока нет
- Reforma Educativa en La ArgentinaДокумент14 страницReforma Educativa en La ArgentinaMicaela De los AngelesОценок пока нет
- N°208 La Riqueza de Ser AcompañadosДокумент114 страницN°208 La Riqueza de Ser AcompañadosRado GonzalezОценок пока нет
- Autoevaluación. Funciones Específicas de La Supervisión EscolarДокумент2 страницыAutoevaluación. Funciones Específicas de La Supervisión EscolarAnonymous GBHLvrme100% (1)
- Guia Entrevista Conductas TransexualesДокумент5 страницGuia Entrevista Conductas TransexualesDia BlueОценок пока нет
- El Principio de La Instrucción Primaria GratuitaДокумент3 страницыEl Principio de La Instrucción Primaria Gratuitaisaid hernandezОценок пока нет
- Conocimiento Historico MarrouДокумент2 страницыConocimiento Historico MarrouAndres Rodriguez100% (2)
- Administracion Cientifica AtrДокумент9 страницAdministracion Cientifica AtrSteven GavilánОценок пока нет
- APUNTES Accidentología ForenseДокумент3 страницыAPUNTES Accidentología Forensearquijimenezr100% (2)
- Dios Pago Una Deuda Que No DebíaДокумент6 страницDios Pago Una Deuda Que No DebíaDaniela RicoОценок пока нет
- Teoría Social ContemporáneaДокумент9 страницTeoría Social ContemporáneaMiguel Angel ReyesОценок пока нет
- Tarea de Betsy Analisis en Los NiñosДокумент7 страницTarea de Betsy Analisis en Los NiñosrubenОценок пока нет
- La Innovación de La Práctica Educativa Como Lugar de Resistencia Del MaestroДокумент9 страницLa Innovación de La Práctica Educativa Como Lugar de Resistencia Del Maestrogeraldyn perez corredorОценок пока нет
- IFÁIYABLEДокумент3 страницыIFÁIYABLEJefte VillanuevaОценок пока нет