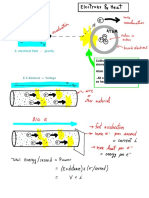
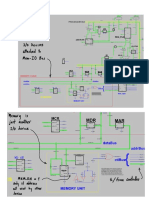
Вам также может понравиться
- A Preliminary Architecture For A Basic Data-Flow ProcessorДокумент7 страницA Preliminary Architecture For A Basic Data-Flow ProcessorjackienessОценок пока нет
- A Dataflow Mechanism For High Speed Radar Signal ProcessingДокумент4 страницыA Dataflow Mechanism For High Speed Radar Signal ProcessingphithucОценок пока нет
- Practical Reverse Engineering: x86, x64, ARM, Windows Kernel, Reversing Tools, and ObfuscationОт EverandPractical Reverse Engineering: x86, x64, ARM, Windows Kernel, Reversing Tools, and ObfuscationОценок пока нет
- HLS AllocationДокумент19 страницHLS AllocationmohanraomamdikarОценок пока нет
- Very High-Level Synthesis of Datapath and Control Structures For Reconfigurable Logic DevicesДокумент5 страницVery High-Level Synthesis of Datapath and Control Structures For Reconfigurable Logic Devices8148593856Оценок пока нет
- Star 100 and TI-ASCДокумент5 страницStar 100 and TI-ASCRajitha PrashanОценок пока нет
- Foundations of Data Intensive Applications: Large Scale Data Analytics under the HoodОт EverandFoundations of Data Intensive Applications: Large Scale Data Analytics under the HoodОценок пока нет
- DC AssignmentДокумент3 страницыDC AssignmentChandra SinghОценок пока нет
- Lecture - 16 Data Flow and Systolic Array ArchitecturesДокумент15 страницLecture - 16 Data Flow and Systolic Array ArchitecturesmohsinmanzoorОценок пока нет
- Automated Modeling and Practical Applications of Systems Described by The AggregatesДокумент6 страницAutomated Modeling and Practical Applications of Systems Described by The AggregatesoveiskntuОценок пока нет
- Unit - IiiДокумент41 страницаUnit - IiiJit Agg0% (1)
- Machine Learning in the AWS Cloud: Add Intelligence to Applications with Amazon SageMaker and Amazon RekognitionОт EverandMachine Learning in the AWS Cloud: Add Intelligence to Applications with Amazon SageMaker and Amazon RekognitionОценок пока нет
- Design of An 8-Bit Bus-Oriented ComputerДокумент13 страницDesign of An 8-Bit Bus-Oriented ComputerSuresh KothalaОценок пока нет
- Jorge L. Silva, Joelmir J. Lopes Valentin O. Roda, Kelton P. CostaДокумент4 страницыJorge L. Silva, Joelmir J. Lopes Valentin O. Roda, Kelton P. CostaSimranjeet SinghОценок пока нет
- Preliminary Specifications: Programmed Data Processor Model Three (PDP-3) October, 1960От EverandPreliminary Specifications: Programmed Data Processor Model Three (PDP-3) October, 1960Оценок пока нет
- An Efficient Multimode Multiplier Supporting AES and Fundamental Operations of Public-Key CryptosystemsДокумент11 страницAn Efficient Multimode Multiplier Supporting AES and Fundamental Operations of Public-Key CryptosystemsVimala PriyaОценок пока нет
- Real-Time Analytics: Techniques to Analyze and Visualize Streaming DataОт EverandReal-Time Analytics: Techniques to Analyze and Visualize Streaming DataОценок пока нет
- Modeling 101Документ15 страницModeling 101สหายดิว ลูกพระอาทิตย์Оценок пока нет
- Digital Spectral Analysis MATLAB® Software User GuideОт EverandDigital Spectral Analysis MATLAB® Software User GuideОценок пока нет
- Register FileДокумент6 страницRegister FilejayaprasadkalluriОценок пока нет
- SAP interface programming with RFC and VBA: Edit SAP data with MS AccessОт EverandSAP interface programming with RFC and VBA: Edit SAP data with MS AccessОценок пока нет
- MATLABДокумент12 страницMATLABSiva SivaОценок пока нет
- The Informed Company: How to Build Modern Agile Data Stacks that Drive Winning InsightsОт EverandThe Informed Company: How to Build Modern Agile Data Stacks that Drive Winning InsightsОценок пока нет
- PC333Документ1 страницаPC333supertraderОценок пока нет
- Assignment: Application of Graphs in Computer ProgrammingДокумент11 страницAssignment: Application of Graphs in Computer ProgrammingSaran AgarwalОценок пока нет
- Final-Assignment CoverДокумент12 страницFinal-Assignment CoverHứa Đăng KhoaОценок пока нет
- Chapter 2 Textbook 8086Документ31 страницаChapter 2 Textbook 8086Madan R Honnalagere100% (1)
- Multithreaded Algorithms For The Fast Fourier TransformДокумент10 страницMultithreaded Algorithms For The Fast Fourier Transformiv727Оценок пока нет
- MS Excel Basics for Business ToolsДокумент3 страницыMS Excel Basics for Business ToolsJohn Boski JavellanaОценок пока нет
- Backpropagation: Fundamentals and Applications for Preparing Data for Training in Deep LearningОт EverandBackpropagation: Fundamentals and Applications for Preparing Data for Training in Deep LearningОценок пока нет
- Computation of Storage Requirements For Multi-Dimensional Signal Processing ApplicationsДокумент14 страницComputation of Storage Requirements For Multi-Dimensional Signal Processing ApplicationsSudhakar SpartanОценок пока нет
- ECSE 548 - Electronic Design and Implementation of The Sine Function On 8-Bit MIPS Processor - ReportДокумент4 страницыECSE 548 - Electronic Design and Implementation of The Sine Function On 8-Bit MIPS Processor - Reportpiohm100% (1)
- Data Flow Graph Mapping Techniques of Computer Architecture With Data Driven Computation ModelДокумент5 страницData Flow Graph Mapping Techniques of Computer Architecture With Data Driven Computation ModelVenu Gopal G MattakkaraОценок пока нет
- WE Project Report Moiz, AliДокумент17 страницWE Project Report Moiz, AliMoiz HussainОценок пока нет
- Cyber SecurityДокумент6 страницCyber SecuritySugam GiriОценок пока нет
- Simulation of Dynamic Grid Replication Strategies in OptorsimДокумент15 страницSimulation of Dynamic Grid Replication Strategies in OptorsimmcemceОценок пока нет
- Aurora Cidr03Документ12 страницAurora Cidr03CobWangОценок пока нет
- Cluster: Clustering Hard Disk Operating SystemДокумент6 страницCluster: Clustering Hard Disk Operating Systeminayat1234Оценок пока нет
- Simulation of Dynamic Grid Replication Strategies in OptorsimДокумент8 страницSimulation of Dynamic Grid Replication Strategies in OptorsimmcemceОценок пока нет
- Optimized Scan Primitives for Irregular Data StructuresДокумент10 страницOptimized Scan Primitives for Irregular Data StructuresAnonymous RrGVQjОценок пока нет
- Coprocessor AlteredДокумент42 страницыCoprocessor Alteredchandanayadav8490Оценок пока нет
- Curs 902 uCE 2013 2014 StudДокумент48 страницCurs 902 uCE 2013 2014 StudNicolae MorarОценок пока нет
- Message-passing vs shared memory, bitonic sort algorithm, SMP architecturesДокумент6 страницMessage-passing vs shared memory, bitonic sort algorithm, SMP architecturesarya_himanshiОценок пока нет
- SlamДокумент6 страницSlamAmna TurkiОценок пока нет
- vi điều khiểnДокумент4 страницыvi điều khiểnDAO THANH MAIОценок пока нет
- 8085 MicroprocessorДокумент23 страницы8085 Microprocessorauromaaroot196% (55)
- Algorithmic Game Theory and Scheduling: Eric Angel, Evripidis Bampis, Fanny Pascual IBISC, University of Evry, FranceДокумент40 страницAlgorithmic Game Theory and Scheduling: Eric Angel, Evripidis Bampis, Fanny Pascual IBISC, University of Evry, FranceAnonymous zN7CjfgnEОценок пока нет
- 0 Notes2 MemoryCPUДокумент186 страниц0 Notes2 MemoryCPUAnonymous zN7CjfgnEОценок пока нет
- Week 04, Linking and LoadingДокумент23 страницыWeek 04, Linking and LoadingAnonymous zN7CjfgnEОценок пока нет
- DCT From NptelДокумент17 страницDCT From NptelFarooq BhatОценок пока нет
- CSL TN 99 1Документ20 страницCSL TN 99 1Anonymous zN7CjfgnEОценок пока нет
- Asynchronous Design MethodologiesДокумент90 страницAsynchronous Design MethodologiesAnonymous zN7CjfgnEОценок пока нет
- Mod251 Castro Fernandeza HM PDFДокумент16 страницMod251 Castro Fernandeza HM PDFAnonymous zN7CjfgnEОценок пока нет
- 11 MachineCodeДокумент32 страницы11 MachineCodeAnonymous zN7CjfgnEОценок пока нет
- Data and Computer Communications Chapter Comparing Circuit Switching and Packet SwitchingДокумент41 страницаData and Computer Communications Chapter Comparing Circuit Switching and Packet SwitchingAnonymous zN7CjfgnEОценок пока нет
- DataflowДокумент119 страницDataflowAnonymous zN7CjfgnEОценок пока нет
- Programmable ASIC I/O Cells: Application-Specific Integrated CircuitsДокумент39 страницProgrammable ASIC I/O Cells: Application-Specific Integrated CircuitsAnonymous zN7CjfgnEОценок пока нет
- 07 SequentialVerilogДокумент6 страниц07 SequentialVerilogAshokkumar GanesanОценок пока нет
- DrFuzz SecDev 2016Документ121 страницаDrFuzz SecDev 2016Anonymous zN7CjfgnEОценок пока нет
- Synchronous & Asynchronous Data Transfer MethodsДокумент18 страницSynchronous & Asynchronous Data Transfer MethodsAnonymous zN7CjfgnEОценок пока нет
- Instruction Level ParallelismДокумент11 страницInstruction Level ParallelismZarnigar Altaf95% (21)
- Number (0-9) + %% (/ Skip Blanks /) (Number) (Sscanf (Yytext,"%lf",&yylval) Return INTEGER ) - (Return Yytext (0) ) /N (Return Yytext (0) )Документ2 страницыNumber (0-9) + %% (/ Skip Blanks /) (Number) (Sscanf (Yytext,"%lf",&yylval) Return INTEGER ) - (Return Yytext (0) ) /N (Return Yytext (0) )Anonymous zN7CjfgnEОценок пока нет
- 2 Slides MemoryOrganisationДокумент11 страниц2 Slides MemoryOrganisationAnonymous zN7CjfgnEОценок пока нет
- Wallace Tree MultiplierДокумент11 страницWallace Tree MultiplierdinuarslanОценок пока нет
- Residue Number Systems: Fast Illgorithms For Multiple Errors Detection and Correction in RedundantДокумент5 страницResidue Number Systems: Fast Illgorithms For Multiple Errors Detection and Correction in RedundantAnonymous zN7CjfgnEОценок пока нет
- Gridpix-Presenting Large Image Files Over The Internet: Satoshi Asami and David A. PattersonДокумент11 страницGridpix-Presenting Large Image Files Over The Internet: Satoshi Asami and David A. PattersonAnonymous zN7CjfgnEОценок пока нет
- 0 Notes2 MemoryCPUДокумент28 страниц0 Notes2 MemoryCPUBasharat AliОценок пока нет
- Dataflow Languages: Prof. Stephen A. EdwardsДокумент54 страницыDataflow Languages: Prof. Stephen A. EdwardsAnonymous zN7CjfgnEОценок пока нет
- E, Electrical Field Gravity: E X Distance VoltageДокумент8 страницE, Electrical Field Gravity: E X Distance VoltageAnonymous zN7CjfgnEОценок пока нет
- Lec 1e ElectricEDAДокумент9 страницLec 1e ElectricEDAAnonymous zN7CjfgnEОценок пока нет
- Lec 0b ReadingListДокумент2 страницыLec 0b ReadingListAnonymous zN7CjfgnEОценок пока нет
- Bit masking and TRAP functions in LC3 assemblyДокумент5 страницBit masking and TRAP functions in LC3 assemblyAnonymous zN7CjfgnEОценок пока нет
- Lec 7c ProgrammingIOДокумент7 страницLec 7c ProgrammingIOAnonymous zN7CjfgnEОценок пока нет
- Verilog Breakdown PDFДокумент1 страницаVerilog Breakdown PDFAnonymous zN7CjfgnEОценок пока нет
- DDDDDDДокумент7 страницDDDDDDAnonymous zN7CjfgnEОценок пока нет
- IBM I 7.1 System MGMT - Performance Ref InfoДокумент278 страницIBM I 7.1 System MGMT - Performance Ref Infosathis_nskОценок пока нет
- MPI Lab Manual FinalДокумент176 страницMPI Lab Manual FinalSadanala GopikrishnaОценок пока нет
- Arm Instruction ProgramДокумент121 страницаArm Instruction ProgramErmin KatardzicОценок пока нет
- Lec08 - Instruction Sets - Characteristics and FunctionsДокумент44 страницыLec08 - Instruction Sets - Characteristics and FunctionsTAN SOO CHIN0% (1)
- COA - Chapter # 9Документ74 страницыCOA - Chapter # 9Set EmpОценок пока нет
- The Kcachegrind HandbookДокумент20 страницThe Kcachegrind HandbookAtul KhariОценок пока нет
- Automated Car parking system using Microprocessor and MicrocontrollerДокумент23 страницыAutomated Car parking system using Microprocessor and MicrocontrollerKamalesh RjОценок пока нет
- 2 Introduction To Assembly v21Документ42 страницы2 Introduction To Assembly v21vokhacnam2k1Оценок пока нет
- DTSP Unit 5Документ12 страницDTSP Unit 5GurunathanОценок пока нет
- Embedded Design TradeoffsДокумент88 страницEmbedded Design Tradeoffsabbazh rakhondeОценок пока нет
- H8/500 Series Programming Manual: Catalog No. ADE-602-021Документ187 страницH8/500 Series Programming Manual: Catalog No. ADE-602-021JuniorTОценок пока нет
- Microprocessor ComponentsДокумент2 страницыMicroprocessor ComponentsBryan YaranonОценок пока нет
- Exception HandlingДокумент78 страницException Handlingmohamed khaled shaban abd elmonem100% (1)
- Fast Software AES EncryptionДокумент20 страницFast Software AES EncryptionvinodhaОценок пока нет
- CoE 421 - Lecture 1Документ16 страницCoE 421 - Lecture 1Alain JimeneaОценок пока нет
- Chapter 4: Data Movement InstructionsДокумент39 страницChapter 4: Data Movement InstructionsTaqsim RajonОценок пока нет
- Computer Architecture and Organization Course DocumentДокумент49 страницComputer Architecture and Organization Course DocumentnedunilavanОценок пока нет
- Subject Code Subject Name Credits: Overview of Computer Architecture & OrganizationДокумент4 страницыSubject Code Subject Name Credits: Overview of Computer Architecture & Organizationanon_71491248Оценок пока нет
- Microprocessor System and Interfacing Week2-Class1Документ21 страницаMicroprocessor System and Interfacing Week2-Class1Qasim shahОценок пока нет
- ECSS E ST 70 41C (15april2016)Документ656 страницECSS E ST 70 41C (15april2016)jsadachiОценок пока нет
- Chapter 01Документ34 страницыChapter 01Umar ShahОценок пока нет
- Mic 3Документ18 страницMic 3Gopinathan MОценок пока нет
- IoT Sensors Enable Smart AgricultureДокумент14 страницIoT Sensors Enable Smart AgricultureShrОценок пока нет
- CY7C63723C-PXC Datasheet (PDF) - Cypress SemiconductorДокумент53 страницыCY7C63723C-PXC Datasheet (PDF) - Cypress SemiconductornoneОценок пока нет
- Cheat Sheet - Iot: Acronym Name DescriptionДокумент3 страницыCheat Sheet - Iot: Acronym Name DescriptionBruno BallemОценок пока нет
- Ai & DS Iii-Viii Sem Syllabus EditedДокумент65 страницAi & DS Iii-Viii Sem Syllabus EditedshobanaОценок пока нет
- Computer Organization and Assembly Language: Lecture 19 & 20 Instruction Formats PDP-8, PDP-10, PDP-11 & VAXДокумент24 страницыComputer Organization and Assembly Language: Lecture 19 & 20 Instruction Formats PDP-8, PDP-10, PDP-11 & VAXDarwin VargasОценок пока нет
- EC303 - Chapter 1 Computer Architecture OrganizationДокумент61 страницаEC303 - Chapter 1 Computer Architecture OrganizationChinОценок пока нет
- Instruction SetДокумент5 страницInstruction SetSaad SaeedОценок пока нет
- MP Module 2 - Modified - CorrectДокумент24 страницыMP Module 2 - Modified - Correctakhil krishnanОценок пока нет
- Mastering Autodesk Inventor 2014 and Autodesk Inventor LT 2014: Autodesk Official PressОт EverandMastering Autodesk Inventor 2014 and Autodesk Inventor LT 2014: Autodesk Official PressРейтинг: 5 из 5 звезд5/5 (1)
- Autodesk Fusion 360: A Power Guide for Beginners and Intermediate Users (3rd Edition)От EverandAutodesk Fusion 360: A Power Guide for Beginners and Intermediate Users (3rd Edition)Рейтинг: 5 из 5 звезд5/5 (2)
- From Vision to Version - Step by step guide for crafting and aligning your product vision, strategy and roadmap: Strategy Framework for Digital Product Management RockstarsОт EverandFrom Vision to Version - Step by step guide for crafting and aligning your product vision, strategy and roadmap: Strategy Framework for Digital Product Management RockstarsОценок пока нет
- SolidWorks 2015 Learn by doing-Part 2 (Surface Design, Mold Tools, and Weldments)От EverandSolidWorks 2015 Learn by doing-Part 2 (Surface Design, Mold Tools, and Weldments)Рейтинг: 4.5 из 5 звезд4.5/5 (5)
- Fusion 360 | Step by Step: CAD Design, FEM Simulation & CAM for Beginners.От EverandFusion 360 | Step by Step: CAD Design, FEM Simulation & CAM for Beginners.Оценок пока нет
- Autodesk Inventor 2020: A Power Guide for Beginners and Intermediate UsersОт EverandAutodesk Inventor 2020: A Power Guide for Beginners and Intermediate UsersОценок пока нет
- FreeCAD | Step by Step: Learn how to easily create 3D objects, assemblies, and technical drawingsОт EverandFreeCAD | Step by Step: Learn how to easily create 3D objects, assemblies, and technical drawingsРейтинг: 5 из 5 звезд5/5 (1)