Вам также может понравиться
- IST BugSeverityPredictionДокумент51 страницаIST BugSeverityPredictionFortHellОценок пока нет
- Volatiles Are MiscompiledДокумент10 страницVolatiles Are Miscompileddnn38hdОценок пока нет
- Understanding Source Code Evolution Using Abstract Syntax Tree MatchingДокумент5 страницUnderstanding Source Code Evolution Using Abstract Syntax Tree MatchingOlympicMarmotОценок пока нет
- Issta 2016 ZopДокумент12 страницIssta 2016 Zopdonkeys54-1Оценок пока нет
- 4.Eng-Semantic Versioning in Ontologies-AASTHA MAHAJANДокумент12 страниц4.Eng-Semantic Versioning in Ontologies-AASTHA MAHAJANImpact JournalsОценок пока нет
- When Do Changes Induce Fixes?: Jacek Sliwerski Thomas Zimmermann Andreas ZellerДокумент5 страницWhen Do Changes Induce Fixes?: Jacek Sliwerski Thomas Zimmermann Andreas ZellerwweellddeerrОценок пока нет
- A Factor Graph Model For Software Bug Finding: Ted Kremenek Andrew Y. NG Dawson EnglerДокумент7 страницA Factor Graph Model For Software Bug Finding: Ted Kremenek Andrew Y. NG Dawson EnglerPrabhdeep SinghОценок пока нет
- Predicting Concurrency BugsДокумент10 страницPredicting Concurrency BugskyooОценок пока нет
- Bug ReportingДокумент3 страницыBug ReportingwilkerОценок пока нет
- Bug Tracking SystemДокумент37 страницBug Tracking Systembitpatelatul_10067% (3)
- KISS: Keep It Simple and Sequential: Shaz Qadeer Dinghao WuДокумент11 страницKISS: Keep It Simple and Sequential: Shaz Qadeer Dinghao WuVinicius Monteiro AmaralОценок пока нет
- Smu - Mca - Mc0066 Assign 1Документ31 страницаSmu - Mca - Mc0066 Assign 1sayandawОценок пока нет
- Unit 2Документ76 страницUnit 2Yash VoraОценок пока нет
- Mutation TestingДокумент2 страницыMutation TestingamantОценок пока нет
- MIT6 858F14 Lab3Документ7 страницMIT6 858F14 Lab3jarod_kyleОценок пока нет
- CS504 Finalterm Solved PPRZДокумент7 страницCS504 Finalterm Solved PPRZAnonymous L4odTZОценок пока нет
- Module 1 - SVITДокумент17 страницModule 1 - SVITVirat KohliОценок пока нет
- MODULE-01Документ17 страницMODULE-01Vaishnavi G . RaoОценок пока нет
- Ijcet: International Journal of Computer Engineering & Technology (Ijcet)Документ5 страницIjcet: International Journal of Computer Engineering & Technology (Ijcet)IAEME PublicationОценок пока нет
- Ijettcs 2013 10 25 078Документ5 страницIjettcs 2013 10 25 078International Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- Testing Using Log File Analysis: Tools, Methods, and IssuesДокумент10 страницTesting Using Log File Analysis: Tools, Methods, and IssuesAyokunle AjayiОценок пока нет
- Book Information+Security UNIT+IIДокумент30 страницBook Information+Security UNIT+IIHerculesОценок пока нет
- DipДокумент12 страницDipsachin81185Оценок пока нет
- Incremental Compilation of Locally Optimized CodeДокумент12 страницIncremental Compilation of Locally Optimized CodeGladwin TirkeyОценок пока нет
- Bug Fixing Process Analysis Using Program Slicing TechniquesДокумент8 страницBug Fixing Process Analysis Using Program Slicing TechniquesSailuОценок пока нет
- DecompilationДокумент6 страницDecompilationRavi MohanОценок пока нет
- Zhang 10 DetectingДокумент10 страницZhang 10 DetectingMarcin KlodaОценок пока нет
- Lazy-Cseq 2.0: Combining Lazy Sequentialization With Abstract InterpretationДокумент5 страницLazy-Cseq 2.0: Combining Lazy Sequentialization With Abstract InterpretationGeorgeОценок пока нет
- Predicting Fault Incidence Using Software Change History PDFДокумент9 страницPredicting Fault Incidence Using Software Change History PDFDenis Ávila MontiniОценок пока нет
- Measuring Software Development Productivity: A Machine Learning ApproachДокумент6 страницMeasuring Software Development Productivity: A Machine Learning ApproachLucas SantosОценок пока нет
- Automatically Identifying Changes That Impact Code-to-Design TraceabilityДокумент10 страницAutomatically Identifying Changes That Impact Code-to-Design TraceabilityNithin Kumar MОценок пока нет
- SEM - 2 - MC0066 - OOPS Using C++Документ18 страницSEM - 2 - MC0066 - OOPS Using C++Shibu GeorgeОценок пока нет
- HTTP Markphip - BlogspotДокумент8 страницHTTP Markphip - Blogspotganesank123Оценок пока нет
- Software Testing 2nd IAДокумент11 страницSoftware Testing 2nd IACadbury CreationОценок пока нет
- A. Introduction:: Module 1: Overview To System DevelopmentДокумент7 страницA. Introduction:: Module 1: Overview To System DevelopmentClayn Devi AlbaОценок пока нет
- AEG: Automatic Exploit GenerationДокумент18 страницAEG: Automatic Exploit GenerationMario RossiОценок пока нет
- Gromova Et Al The Quality of Bug ReportsДокумент7 страницGromova Et Al The Quality of Bug ReportsKapila KarunaratneОценок пока нет
- ZIDINДокумент21 страницаZIDINiangarvinsОценок пока нет
- Programming in C++Документ66 страницProgramming in C++nin culusОценок пока нет
- DeepJIT - An End-To-End Deep Learning Framework For Just-In-time DДокумент13 страницDeepJIT - An End-To-End Deep Learning Framework For Just-In-time DIsabela NevesОценок пока нет
- Os Unit 3Документ40 страницOs Unit 3zainabsheik.2210Оценок пока нет
- Execution Anomaly Detection in Distributed Systems Through Unstructured Log AnalysisДокумент10 страницExecution Anomaly Detection in Distributed Systems Through Unstructured Log AnalysisredzgnОценок пока нет
- A Toy Model of Distributed TransactionsДокумент6 страницA Toy Model of Distributed TransactionsPLHОценок пока нет
- (1-2) ScribeNotes 3:1:2016Документ6 страниц(1-2) ScribeNotes 3:1:2016S VrnsОценок пока нет
- Ian MicroelectronicsДокумент20 страницIan MicroelectronicsiangarvinsОценок пока нет
- Software Testing, Software Quality AssuranceДокумент127 страницSoftware Testing, Software Quality AssuranceSeun -nuga DanielОценок пока нет
- 1-Program Design and AnalysisДокумент6 страниц1-Program Design and AnalysisUmer AftabОценок пока нет
- Integrated Multiple Predictive Algorithm Control ToolДокумент31 страницаIntegrated Multiple Predictive Algorithm Control ToolLinoArayaОценок пока нет
- Lab 1: Introduction To C Programming: Upon Completion of This Lab Session, Students Will Be Able ToДокумент7 страницLab 1: Introduction To C Programming: Upon Completion of This Lab Session, Students Will Be Able ToMuhd AkmalОценок пока нет
- Next Pathway Hack Backpackers Problem StatementДокумент11 страницNext Pathway Hack Backpackers Problem Statementsonali PradhanОценок пока нет
- (Notes) DESIGN FOR TESTABILITYДокумент34 страницы(Notes) DESIGN FOR TESTABILITYsarathkumarОценок пока нет
- Assignment-1: 1) A. Explain The Principles of Test Case Desin? A)Документ7 страницAssignment-1: 1) A. Explain The Principles of Test Case Desin? A)Saiprabhakar DevineniОценок пока нет
- Cse Viii Software Testing (10cs842) SolutionДокумент39 страницCse Viii Software Testing (10cs842) SolutionRanjeetSingh71% (7)
- SCSA1604Документ133 страницыSCSA1604anubhavbarik307Оценок пока нет
- Ul 17 Lec 03 Se MДокумент26 страницUl 17 Lec 03 Se MNG BEI SHENGОценок пока нет
- CritiqueДокумент14 страницCritiqueAlex WilliamsОценок пока нет
- Oakland 10Документ15 страницOakland 10metatron13Оценок пока нет
- Types of TestingДокумент47 страницTypes of Testingpoornima_deviОценок пока нет
- Overview of Software Defect Prediction Using Machine Learning AlgorithmsДокумент12 страницOverview of Software Defect Prediction Using Machine Learning Algorithmszohar oshratОценок пока нет
- DeepBugs TR Nov2017 PDFДокумент15 страницDeepBugs TR Nov2017 PDFzohar oshratОценок пока нет
- MergedFile - Emma DewarДокумент39 страницMergedFile - Emma Dewarzohar oshratОценок пока нет
- EdBuild EdDigger Instructions - Kat KennewellДокумент17 страницEdBuild EdDigger Instructions - Kat Kennewellzohar oshratОценок пока нет
- EdBuild EdCrane Instructions - Kat KennewellДокумент21 страницаEdBuild EdCrane Instructions - Kat Kennewellzohar oshratОценок пока нет
- End Points SubrogadosДокумент3 страницыEnd Points SubrogadosAgustina AndradeОценок пока нет
- Research Design: An Overview: Multiple Choice QuestionsДокумент28 страницResearch Design: An Overview: Multiple Choice QuestionsBashayerhmmОценок пока нет
- Module 1 Dynamics of Rigid BodiesДокумент11 страницModule 1 Dynamics of Rigid BodiesBilly Joel DasmariñasОценок пока нет
- 1207 - RTC-8065 II InglesДокумент224 страницы1207 - RTC-8065 II InglesGUILHERME SANTOSОценок пока нет
- Form 1 1 MicroscopeДокумент46 страницForm 1 1 MicroscopeHarshil PatelОценок пока нет
- Tripura 04092012Документ48 страницTripura 04092012ARTHARSHI GARGОценок пока нет
- IELTS Letter Writing TipsДокумент7 страницIELTS Letter Writing Tipsarif salmanОценок пока нет
- Sample TRM All Series 2020v1 - ShortseДокумент40 страницSample TRM All Series 2020v1 - ShortseSuhail AhmadОценок пока нет
- 1013CCJ - T3 2019 - Assessment 2 - CompleteДокумент5 страниц1013CCJ - T3 2019 - Assessment 2 - CompleteGeorgie FriedrichsОценок пока нет
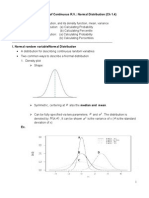
- Distribution of Continuous R.V.: Normal Distribution (CH 1.4) TopicsДокумент7 страницDistribution of Continuous R.V.: Normal Distribution (CH 1.4) TopicsPhạm Ngọc HòaОценок пока нет
- Tournament Rules and MechanicsДокумент2 страницыTournament Rules and MechanicsMarkAllenPascualОценок пока нет
- RMC No. 122 2022 9.6.2022Документ6 страницRMC No. 122 2022 9.6.2022RUFO BULILANОценок пока нет
- Auditing Multiple Choice Questions and Answers MCQs Auditing MCQ For CA, CS and CMA Exams Principle of Auditing MCQsДокумент30 страницAuditing Multiple Choice Questions and Answers MCQs Auditing MCQ For CA, CS and CMA Exams Principle of Auditing MCQsmirjapur0% (1)
- Prof Ed 3 Module 1Документ9 страницProf Ed 3 Module 1alexa dawatОценок пока нет
- Ccie R&s Expanded-BlueprintДокумент12 страницCcie R&s Expanded-BlueprintAftab AlamОценок пока нет
- Projected Costs of Generating Electricity (EGC) 2005Документ233 страницыProjected Costs of Generating Electricity (EGC) 2005susantojdОценок пока нет
- Detailed Lesson Plan (Lit)Документ19 страницDetailed Lesson Plan (Lit)Shan QueentalОценок пока нет
- Résumé Emily Martin FullДокумент3 страницыRésumé Emily Martin FullEmily MartinОценок пока нет
- L Rexx PDFДокумент9 страницL Rexx PDFborisg3Оценок пока нет
- The Ins and Outs Indirect OrvinuДокумент8 страницThe Ins and Outs Indirect OrvinusatishОценок пока нет
- Real Options BV Lec 14Документ49 страницReal Options BV Lec 14Anuranjan TirkeyОценок пока нет
- 3D Tetris Cake Evening 2Документ13 страниц3D Tetris Cake Evening 2Subham KarmakarОценок пока нет
- Advocating For Appropriate Educational ServicesДокумент32 страницыAdvocating For Appropriate Educational ServicesTransverse Myelitis AssociationОценок пока нет
- Some Solutions To Enderton LogicДокумент16 страницSome Solutions To Enderton LogicJason100% (1)
- ShopDrawings - Part 1Документ51 страницаShopDrawings - Part 1YapОценок пока нет
- IJISRT23JUL645Документ11 страницIJISRT23JUL645International Journal of Innovative Science and Research TechnologyОценок пока нет
- Digital Speed Control of DC Motor For Industrial Automation Using Pulse Width Modulation TechniqueДокумент6 страницDigital Speed Control of DC Motor For Industrial Automation Using Pulse Width Modulation TechniquevendiОценок пока нет
- Cot Observation ToolДокумент14 страницCot Observation ToolArnoldBaladjayОценок пока нет
- Diffrent Types of MapДокумент3 страницыDiffrent Types of MapIan GamitОценок пока нет
- Concise Beam DemoДокумент33 страницыConcise Beam DemoluciafmОценок пока нет