Вам также может понравиться
- 2006-CHM6108 - L5L6 SlidesДокумент52 страницы2006-CHM6108 - L5L6 Slidesaidar.seralinОценок пока нет
- Molecular Facts and FiguresДокумент9 страницMolecular Facts and FiguresLuc JeronОценок пока нет
- Asam Lemak Sebagai Agen Antimalaria-1Документ69 страницAsam Lemak Sebagai Agen Antimalaria-1robby gus mahardikaОценок пока нет
- BIOC 200 Lec # 5 - LIPIDSДокумент44 страницыBIOC 200 Lec # 5 - LIPIDSEslam NassarОценок пока нет
- Docking AnalysisДокумент7 страницDocking AnalysisDIPANGKAR DUWARAHОценок пока нет
- Nucleotide MetabolismДокумент89 страницNucleotide Metabolismfeby ary annasОценок пока нет
- Enzyme Inhibition Why Inhibit Enzymes? Physiological ReasonsДокумент7 страницEnzyme Inhibition Why Inhibit Enzymes? Physiological Reasonsbiagio castronovoОценок пока нет
- 2006 CHM6108 L7L8 HandoutДокумент17 страниц2006 CHM6108 L7L8 Handoutaidar.seralinОценок пока нет
- West Heimer 1987Документ6 страницWest Heimer 1987Rebek EscutiaОценок пока нет
- Quino LoneДокумент28 страницQuino LoneanggaririnОценок пока нет
- 2006 CHM6108 L7L8 SlidesДокумент46 страниц2006 CHM6108 L7L8 Slidesaidar.seralinОценок пока нет
- Antiulcer PPI MechanismДокумент42 страницыAntiulcer PPI MechanismAhmed FouadОценок пока нет
- Why Nature Chose Phosphates - F H Westheimer - 1987Документ7 страницWhy Nature Chose Phosphates - F H Westheimer - 1987Antonio Vázquez MotaОценок пока нет
- Yushchenko Et Al - 2021 - Glyphosate, Methods of SynthesisДокумент11 страницYushchenko Et Al - 2021 - Glyphosate, Methods of SynthesisJoana AlvesОценок пока нет
- Curs 12 GlycogenДокумент37 страницCurs 12 GlycogenStanescuRozicaОценок пока нет
- DipanGkar Project Seminar1Документ8 страницDipanGkar Project Seminar1DIPANGKAR DUWARAHОценок пока нет
- On The Electrophilic Reactivities of Acarbonyl Heterocylces and ArenesДокумент7 страницOn The Electrophilic Reactivities of Acarbonyl Heterocylces and ArenesFinn NelsonОценок пока нет
- Review of Pyrazole Compounds and their Pharmacological InterestДокумент100 страницReview of Pyrazole Compounds and their Pharmacological InterestSaima KhanОценок пока нет
- Kher 2014Документ4 страницыKher 2014Chinar PatelОценок пока нет
- 9 GlycogenДокумент36 страниц9 GlycogenSneha Sagar SharmaОценок пока нет
- Transcription Transcription - Translation Information Flow in Biological Systems - DNA Replication PDFДокумент90 страницTranscription Transcription - Translation Information Flow in Biological Systems - DNA Replication PDFAveen ShabanОценок пока нет
- Lec 5Документ20 страницLec 5Sreemanti DeyОценок пока нет
- Further reading provides more contextДокумент1 страницаFurther reading provides more contextAmir ali WalizadehОценок пока нет
- Glycogen MetabolismДокумент37 страницGlycogen MetabolismERIAS TENYWAОценок пока нет
- Materials: Natural Melanogenesis Inhibitors Acting Through The Down-Regulation of Tyrosinase ActivityДокумент26 страницMaterials: Natural Melanogenesis Inhibitors Acting Through The Down-Regulation of Tyrosinase ActivityRiefka Ananda ZulfaОценок пока нет
- DM pp1-20Документ20 страницDM pp1-20MLUNGISI MkhwanaziОценок пока нет
- A Novel Route Towards Cycle-Tail Peptides Using Oxime Resin: Teaching An Old Dog A New TrickДокумент13 страницA Novel Route Towards Cycle-Tail Peptides Using Oxime Resin: Teaching An Old Dog A New Tricksyed aftab hussainОценок пока нет
- Butyrophenone Analog As A Potential Atypical Antipsychotic Agent (J) .Bioorganic & Medicinal Chemistry, 2008, 16 (15) .7291-7301Документ11 страницButyrophenone Analog As A Potential Atypical Antipsychotic Agent (J) .Bioorganic & Medicinal Chemistry, 2008, 16 (15) .7291-7301Qi JacksonОценок пока нет
- GLYCOGEN METABOLISMДокумент63 страницыGLYCOGEN METABOLISMyixecix709Оценок пока нет
- Chapter 4 ContiuedДокумент24 страницыChapter 4 ContiuedumarОценок пока нет
- Biosynthesis of Alkaloid Natural Products 5.1. Alkaloids Are Derived From Amino AcidsДокумент14 страницBiosynthesis of Alkaloid Natural Products 5.1. Alkaloids Are Derived From Amino Acidsharishkumar kakrani100% (2)
- (Shin Etsu) HPMCP (Eng)Документ12 страниц(Shin Etsu) HPMCP (Eng)vinay100% (2)
- OC-V p5Документ14 страницOC-V p5Derek Ross0% (1)
- Bioflavonoids Therapeutic PotentialДокумент15 страницBioflavonoids Therapeutic PotentialCăplescu LucianОценок пока нет
- Addition To C N Bonds: Scheme 1 Pictet-Spengler CyclizationДокумент18 страницAddition To C N Bonds: Scheme 1 Pictet-Spengler Cyclizationbluedolphin7Оценок пока нет
- The β - D Glucose Scaffold as a β- Turn Mimetic: Saidulu DaraДокумент19 страницThe β - D Glucose Scaffold as a β- Turn Mimetic: Saidulu Daraglreddy09Оценок пока нет
- Glycogen Synthesis 2Документ39 страницGlycogen Synthesis 2CLEMENTОценок пока нет
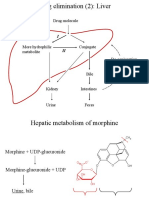
- Drug elimination (2): Liver metabolismДокумент26 страницDrug elimination (2): Liver metabolismSylvia AngelinaОценок пока нет
- Purine Metabolism II: Osama YousefДокумент14 страницPurine Metabolism II: Osama YousefWan NurfazliyanaОценок пока нет
- Lipid BiosynthesisДокумент60 страницLipid BiosynthesisNdy AgustaviaОценок пока нет
- Synthesis and evaluation of benzoxazole derivatives as 5-lipoxygenase inhibitorsДокумент6 страницSynthesis and evaluation of benzoxazole derivatives as 5-lipoxygenase inhibitorsSindhu PriyaОценок пока нет
- Chapter 9 PDFДокумент41 страницаChapter 9 PDFIziz De La CruzОценок пока нет
- New photochromic cyclopentenone-fused naphthopyranДокумент1 страницаNew photochromic cyclopentenone-fused naphthopyranSky SousaОценок пока нет
- Antiepileptics Medicinal ChemistryДокумент30 страницAntiepileptics Medicinal ChemistryDaniel WangОценок пока нет
- Hallucinogens: Effects and Mechanisms of ActionДокумент9 страницHallucinogens: Effects and Mechanisms of ActionMada madalinaОценок пока нет
- Favorskii R ClaydenДокумент3 страницыFavorskii R Claydenarchi KumarОценок пока нет
- Prodrug (D.ashowq)Документ4 страницыProdrug (D.ashowq)علي الطياريОценок пока нет
- nucleic acid part 1 - Before Lecture 9Документ10 страницnucleic acid part 1 - Before Lecture 9ReggieОценок пока нет
- Hydrophobicity: Physicochemical Properties of Drugs (CH 18)Документ35 страницHydrophobicity: Physicochemical Properties of Drugs (CH 18)afafОценок пока нет
- Novabiochem: Derivatives For Enhancing Peptide SynthesisДокумент4 страницыNovabiochem: Derivatives For Enhancing Peptide SynthesisValentina D BrunaОценок пока нет
- Intro To Med Chem - Lecture 2Документ43 страницыIntro To Med Chem - Lecture 2lukehongОценок пока нет
- Nucleic Acid Structure & DNA ReplicationДокумент51 страницаNucleic Acid Structure & DNA ReplicationJMCDUFFIEОценок пока нет
- Chapter - IДокумент22 страницыChapter - IVINOTH RAJОценок пока нет
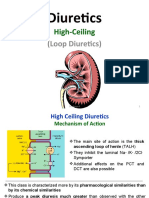
- Diuretics IIIДокумент21 страницаDiuretics IIIأمجد محمدОценок пока нет
- Pyrimidine and PurinesДокумент6 страницPyrimidine and PurinesSuraj SainiОценок пока нет
- Carbohydrates I: Common Reactions 3: Laboratory ManualДокумент10 страницCarbohydrates I: Common Reactions 3: Laboratory ManualJhet Ardian CoritanaОценок пока нет
- Patrick Ch22 p3Документ12 страницPatrick Ch22 p3Oxy GenОценок пока нет
- P, S, C C C o Nptel PDFДокумент56 страницP, S, C C C o Nptel PDFRathinОценок пока нет
- Recent Developments in the Chemistry of Natural Phenolic Compounds: Proceedings of the Plant Phenolics Group SymposiumОт EverandRecent Developments in the Chemistry of Natural Phenolic Compounds: Proceedings of the Plant Phenolics Group SymposiumW. D. OllisОценок пока нет
- XXIVth International Congress of Pure and Applied Chemistry: Plenary and Main Section Lectures Presented at Hamburg, Federal Republic of Germany, 2–8 September 1973От EverandXXIVth International Congress of Pure and Applied Chemistry: Plenary and Main Section Lectures Presented at Hamburg, Federal Republic of Germany, 2–8 September 1973Оценок пока нет
- تحليل البول بالصور والشرحДокумент72 страницыتحليل البول بالصور والشرحDaouai TaaouanouОценок пока нет
- Pnp-MemorandumДокумент9 страницPnp-MemorandumraalphОценок пока нет
- 01 Basic Design Structure FeaturesДокумент8 страниц01 Basic Design Structure FeaturesAndri AjaОценок пока нет
- Effects of Climate ChangeДокумент10 страницEffects of Climate ChangeJan100% (1)
- Food Salt: By: Saad, Rehan, Asad, Hasan, Adil, Abdur Rehman, AzharДокумент10 страницFood Salt: By: Saad, Rehan, Asad, Hasan, Adil, Abdur Rehman, AzharsaadОценок пока нет
- Here's Your Water Bill: LitresДокумент4 страницыHere's Your Water Bill: Litrestvnm2ymmkdОценок пока нет
- CKD EsrdДокумент83 страницыCKD EsrdRita Lakhani100% (1)
- Rtaa SB 4 - 10011991Документ6 страницRtaa SB 4 - 10011991alcomech100% (3)
- English Based On Latest PatternДокумент13 страницEnglish Based On Latest PatternAtish ToppoОценок пока нет
- 10893259-PIB 背钳弹簧保持架垫片落物事件Документ2 страницы10893259-PIB 背钳弹簧保持架垫片落物事件xlzyydf2015Оценок пока нет
- Schematic 1280 - So Do Nokia 1 PDFДокумент18 страницSchematic 1280 - So Do Nokia 1 PDFanh3saigon0% (1)
- Soap Making: Borax (NaДокумент15 страницSoap Making: Borax (Naa aОценок пока нет
- CAP - 5 - 54. Billions and Billions of Demons - by Richard C. Lewontin - The New York Review of BooksДокумент11 страницCAP - 5 - 54. Billions and Billions of Demons - by Richard C. Lewontin - The New York Review of BooksRaimundo Filho100% (1)
- The Positive and Negative Syndrome Scale PANSS ForДокумент5 страницThe Positive and Negative Syndrome Scale PANSS ForditeABCОценок пока нет
- Antox Pickling Paste MSDSДокумент10 страницAntox Pickling Paste MSDSKrishna Vacha0% (1)
- Welder Training in SMAW, GTAW & GMAW Welding Engineering & NDT Consultancy Welding Engineering Related TrainingДокумент4 страницыWelder Training in SMAW, GTAW & GMAW Welding Engineering & NDT Consultancy Welding Engineering Related TrainingKavin PrakashОценок пока нет
- Work Procedure For CCB Installation of Raised Floor 2Документ13 страницWork Procedure For CCB Installation of Raised Floor 2ResearcherОценок пока нет
- Explorations in PersonalityДокумент802 страницыExplorations in Personalitypolz2007100% (8)
- Red Velvet Cake RecipeДокумент6 страницRed Velvet Cake RecipeRuminto SubektiОценок пока нет
- B25 Pompe de Peinture PDFДокумент98 страницB25 Pompe de Peinture PDFchahineОценок пока нет
- 004 VSL Datasheets US-AДокумент22 страницы004 VSL Datasheets US-Akmabd100% (1)
- Motor Doosan DV11Документ220 страницMotor Doosan DV11David Catari100% (4)
- Proposed Rule: Airworthiness Directives: Bell Helicopter Textron CanadaДокумент3 страницыProposed Rule: Airworthiness Directives: Bell Helicopter Textron CanadaJustia.comОценок пока нет
- ECD KEBVF5 Installation ManualДокумент32 страницыECD KEBVF5 Installation Manualashish gautamОценок пока нет
- Redraw Rod For Multiwire DrawingДокумент6 страницRedraw Rod For Multiwire DrawingWajeeh BitarОценок пока нет
- Evonik Copi BrochureДокумент5 страницEvonik Copi BrochureRovshan HasanzadeОценок пока нет
- Best WiFi Adapter For Kali Linux - Monitor Mode & Packet InjectionДокумент14 страницBest WiFi Adapter For Kali Linux - Monitor Mode & Packet InjectionKoushikОценок пока нет
- Geoheritage of Labuan Island: Bulletin of The Geological Society of Malaysia December 2016Документ14 страницGeoheritage of Labuan Island: Bulletin of The Geological Society of Malaysia December 2016songkkОценок пока нет
- Deutz-Fahr Workshop Manual for AGROTRON MK3 ModelsДокумент50 страницDeutz-Fahr Workshop Manual for AGROTRON MK3 Modelstukasai100% (1)
- Genie Z45.25 J Internal Combustion - Service Manual - Part No. 219418Документ331 страницаGenie Z45.25 J Internal Combustion - Service Manual - Part No. 219418marciogianottiОценок пока нет