Вам также может понравиться
- notesForCalc2 Curves 20221202Документ36 страницnotesForCalc2 Curves 20221202Vinicius BrunoОценок пока нет
- Demodulation and beamforming in ultrasound imagingДокумент8 страницDemodulation and beamforming in ultrasound imagingManjunath RamachandraОценок пока нет
- Mathematics of Seismic Imaging Part IДокумент54 страницыMathematics of Seismic Imaging Part IRahmat HidayatОценок пока нет
- Convergence of Prob MeasuresДокумент14 страницConvergence of Prob MeasureshollowkenshinОценок пока нет
- Convergent Inversion Approximations For Polynomials in Bernstein FormДокумент18 страницConvergent Inversion Approximations For Polynomials in Bernstein FormMaiah DinglasanОценок пока нет
- Frequency Domain StatisticsДокумент12 страницFrequency Domain StatisticsThiago LechnerОценок пока нет
- ExamДокумент3 страницыExamMohan BistaОценок пока нет
- Note 1 - Approximations and ErrorsДокумент3 страницыNote 1 - Approximations and ErrorsPrimali PereraОценок пока нет
- 31 Meet 5988Документ6 страниц31 Meet 5988Drazen JurisicОценок пока нет
- 3 Sampling PDFДокумент20 страниц3 Sampling PDFWaqas QammarОценок пока нет
- Numerical Methods For Travel TimesДокумент94 страницыNumerical Methods For Travel Timesforscribd1981Оценок пока нет
- Space Curve GeometryДокумент20 страницSpace Curve GeometryMANIRAGUHA Jean PaulОценок пока нет
- "Chirps" Everywhere: Patrick Flandrin Cnrs - Ecole Normale Sup Erieure de LyonДокумент50 страниц"Chirps" Everywhere: Patrick Flandrin Cnrs - Ecole Normale Sup Erieure de LyonSoha MohamedОценок пока нет
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)От EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)Оценок пока нет
- Communication System MatlabДокумент21 страницаCommunication System MatlabEysha qureshiОценок пока нет
- EE210 S22 LecSlides 02 2ppДокумент14 страницEE210 S22 LecSlides 02 2ppMarcel HuberОценок пока нет
- KalmanДокумент34 страницыKalmanbilal309Оценок пока нет
- Calculus II Cheat SheetДокумент4 страницыCalculus II Cheat SheetajznelsonОценок пока нет
- ArticleДокумент14 страницArticlealipirkhedriОценок пока нет
- AP BC ReviewДокумент7 страницAP BC ReviewchowmeinnoodleОценок пока нет
- S-Domain Analysis and Bode PlotsДокумент9 страницS-Domain Analysis and Bode Plotsfaisal140Оценок пока нет
- 18.950 Differential Geometry: Mit OpencoursewareДокумент12 страниц18.950 Differential Geometry: Mit OpencoursewarePhi Tien CuongОценок пока нет
- MCE693/793: Analysis and Control of Nonlinear Systems: Introduction To Describing FunctionsДокумент31 страницаMCE693/793: Analysis and Control of Nonlinear Systems: Introduction To Describing FunctionsAbdesselem BoulkrouneОценок пока нет
- Calc 2 SpringstudyguideДокумент5 страницCalc 2 SpringstudyguideDefault AccountОценок пока нет
- Assignment 1 SolutionДокумент9 страницAssignment 1 SolutiongowthamkurriОценок пока нет
- Multiple Time Series: X y X T T N X y N T R T TДокумент11 страницMultiple Time Series: X y X T T N X y N T R T TAntonio EleuteriОценок пока нет
- Presentation Draft FMEFMДокумент27 страницPresentation Draft FMEFMDavid SaccoОценок пока нет
- Notes On Chebyshev Filters PDFДокумент12 страницNotes On Chebyshev Filters PDFArchit JainОценок пока нет
- Paper02 - JFAДокумент30 страницPaper02 - JFAMauricio DuarteОценок пока нет
- Lecture 5: Wavefront Reconstruction and Prediction: P.r.fraanje@tudelft - NLДокумент136 страницLecture 5: Wavefront Reconstruction and Prediction: P.r.fraanje@tudelft - NLPhuc PhanОценок пока нет
- 50 Years of FFT Algorithms and Applications.Документ34 страницы50 Years of FFT Algorithms and Applications.Alvaro CotaquispeОценок пока нет
- Powerpoint FinallllllllllpdfДокумент32 страницыPowerpoint FinallllllllllpdfPrincess Morales TyОценок пока нет
- Tomo Nauter - PsДокумент35 страницTomo Nauter - PsRodrigoОценок пока нет
- Spectral Methods in CFD: Fourier and Chebyshev MethodsДокумент12 страницSpectral Methods in CFD: Fourier and Chebyshev MethodsMarc Rovira SacieОценок пока нет
- Dsip Lab Manual Latest UpdatedДокумент39 страницDsip Lab Manual Latest Updatedmanas dhumalОценок пока нет
- Understanding and Applying Kalman FilteringДокумент37 страницUnderstanding and Applying Kalman FilteringosamazimОценок пока нет
- Understanding and Applying Kalman FilteringДокумент37 страницUnderstanding and Applying Kalman FilteringKoustuvGaraiОценок пока нет
- Lab#1 Sampling and Quantization Objectives:: Communication II Lab (EELE 4170)Документ6 страницLab#1 Sampling and Quantization Objectives:: Communication II Lab (EELE 4170)MarteОценок пока нет
- Analog and Digital Signal Processing by Ambardar (400 821)Документ422 страницыAnalog and Digital Signal Processing by Ambardar (400 821)William's Limonchi Sandoval100% (1)
- Article Title 1Документ12 страницArticle Title 1alipirkhedriОценок пока нет
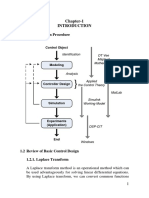
- Chapter-1: 1.1 Control Design ProcedureДокумент23 страницыChapter-1: 1.1 Control Design ProcedureWildan MumtazОценок пока нет
- Final 09Документ2 страницыFinal 09Sutirtha SenguptaОценок пока нет
- 2 PDFДокумент25 страниц2 PDFAbdelhamed SakrОценок пока нет
- PHYS 381 W23 Assignment 4Документ8 страницPHYS 381 W23 Assignment 4Nathan NgoОценок пока нет
- 02 Finite DifferencesДокумент27 страниц02 Finite DifferencesCham AmirruddinОценок пока нет
- SLE AT2003preprintДокумент12 страницSLE AT2003preprintHuong Cam ThuyОценок пока нет
- CH 02Документ30 страницCH 02KavunОценок пока нет
- Moving Along a Curve with Specified Speed Using ReparameterizationДокумент13 страницMoving Along a Curve with Specified Speed Using Reparameterizationzhaodong.liangОценок пока нет
- Transmission Line Write UpДокумент10 страницTransmission Line Write UpAbhishek AgrawalОценок пока нет
- 13.1 Analog and Digital Lowpass Butterworth FilterДокумент7 страниц13.1 Analog and Digital Lowpass Butterworth FiltertempОценок пока нет
- Numerical Solution of Bagley-Torvik Equation Using Chebyshev Wavelet Operational Matrix of Fractional DerivativeДокумент9 страницNumerical Solution of Bagley-Torvik Equation Using Chebyshev Wavelet Operational Matrix of Fractional DerivativeVe LopiОценок пока нет
- Lec01 1Документ63 страницыLec01 1awabnasirahmednasirОценок пока нет
- Mat ManualДокумент35 страницMat ManualskandanitteОценок пока нет
- Test 123Документ7 страницTest 123Shah KhanОценок пока нет
- Iterative Methods of Richardson-Lucy-type For Image DeblurringДокумент15 страницIterative Methods of Richardson-Lucy-type For Image DeblurringhilmanmuntahaОценок пока нет
- Final Exam Formula SheetДокумент3 страницыFinal Exam Formula SheetYuhao ChenОценок пока нет
- Light DiffractionДокумент6 страницLight DiffractionMagnet AlОценок пока нет
- ECE 380 Problem Set 1 Review of Complex Numbers and Laplace TransformsДокумент2 страницыECE 380 Problem Set 1 Review of Complex Numbers and Laplace TransformsJoe NguyenОценок пока нет
- On the Tangent Space to the Space of Algebraic Cycles on a Smooth Algebraic Variety. (AM-157)От EverandOn the Tangent Space to the Space of Algebraic Cycles on a Smooth Algebraic Variety. (AM-157)Оценок пока нет
- Unsteady Aerodynamics Modeling For Aircraft Maneuvers - A New ApprДокумент22 страницыUnsteady Aerodynamics Modeling For Aircraft Maneuvers - A New ApprAshwani SinghОценок пока нет
- Energy Harvesting Wireless Sensors and Networked Timing Synchronization For Aircraft Structural Health MonitoringДокумент5 страницEnergy Harvesting Wireless Sensors and Networked Timing Synchronization For Aircraft Structural Health MonitoringAshwani SinghОценок пока нет
- Research On The Application of Digital Twin in Aerospace Manufacturing Based On 3D Point CloudДокумент6 страницResearch On The Application of Digital Twin in Aerospace Manufacturing Based On 3D Point CloudAshwani SinghОценок пока нет
- Decision Tree and Random Forest Based Novel Unsteady Aerodynamics Modeling Using Flight DataДокумент7 страницDecision Tree and Random Forest Based Novel Unsteady Aerodynamics Modeling Using Flight DataAshwani SinghОценок пока нет
- Unsteady Aerodynamic Identification Based On Recurrent Neural NetworksДокумент10 страницUnsteady Aerodynamic Identification Based On Recurrent Neural Networksshakeel6787Оценок пока нет
- Analysis of Wireless System Design For Aircraft Indoor Wireless Sensor CommunicationДокумент5 страницAnalysis of Wireless System Design For Aircraft Indoor Wireless Sensor CommunicationAshwani SinghОценок пока нет
- Aircraft Strain WSN Powered by Heat Storage HarvestingДокумент9 страницAircraft Strain WSN Powered by Heat Storage HarvestingAshwani SinghОценок пока нет
- F3.5 CRT and AMLCD ComparisonДокумент9 страницF3.5 CRT and AMLCD ComparisonAshwani SinghОценок пока нет
- Channel Hardening Receiver Achieves Near-Optimal MIMO PerformanceДокумент16 страницChannel Hardening Receiver Achieves Near-Optimal MIMO PerformanceAshwani SinghОценок пока нет
- Study On Scattering Characteristics of Chaff For RadarДокумент4 страницыStudy On Scattering Characteristics of Chaff For RadarAshwani SinghОценок пока нет
- A Self-Adaptive 1D Convolutional Neural NetworkДокумент19 страницA Self-Adaptive 1D Convolutional Neural NetworkAshwani SinghОценок пока нет
- Theoretical Results On Sparse Representations of Multiple Measurement VectorsДокумент10 страницTheoretical Results On Sparse Representations of Multiple Measurement VectorsAshwani SinghОценок пока нет
- AD IntroductionToFlightTestEngineering PDFДокумент431 страницаAD IntroductionToFlightTestEngineering PDFashwa100% (1)
- A Chaff Cloud ModelisationДокумент4 страницыA Chaff Cloud ModelisationAshwani Singh100% (1)
- Probability and Random ProcessДокумент1 страницаProbability and Random ProcessAshwani SinghОценок пока нет
- Dynamic ' Reconstruction: Justin Romberg Georgia Tech, ECE Collaborators: M. Salman Asif Aur' Ele Balavoine Chris RozellДокумент53 страницыDynamic ' Reconstruction: Justin Romberg Georgia Tech, ECE Collaborators: M. Salman Asif Aur' Ele Balavoine Chris RozellAshwani SinghОценок пока нет
- Dynamic ' Reconstruction: Justin Romberg Georgia Tech, ECE Collaborators: M. Salman Asif Aur' Ele Balavoine Chris RozellДокумент53 страницыDynamic ' Reconstruction: Justin Romberg Georgia Tech, ECE Collaborators: M. Salman Asif Aur' Ele Balavoine Chris RozellAshwani SinghОценок пока нет
- Theoretical Results On Sparse Representations of Multiple Measurement VectorsДокумент10 страницTheoretical Results On Sparse Representations of Multiple Measurement VectorsAshwani SinghОценок пока нет
- 08 L1stable PDFДокумент18 страниц08 L1stable PDFAshwani SinghОценок пока нет
- Compressive Sensing: Sample Smarter, Not FasterДокумент87 страницCompressive Sensing: Sample Smarter, Not FasterAshwani SinghОценок пока нет
- 04 Spikes Sines PDFДокумент15 страниц04 Spikes Sines PDFAshwani SinghОценок пока нет
- Basis Representation Fundamentals: Notes by J. RombergДокумент28 страницBasis Representation Fundamentals: Notes by J. RombergAshwani SinghОценок пока нет
- 09 Gaussrip PDFДокумент43 страницы09 Gaussrip PDFAshwani SinghОценок пока нет
- Mathematics of Compressive Sensing: Sparse recovery using `1 minimizationДокумент25 страницMathematics of Compressive Sensing: Sparse recovery using `1 minimizationAshwani SinghОценок пока нет
- ' Minimization: Resolution/ Bandwidth # SamplesДокумент11 страниц' Minimization: Resolution/ Bandwidth # SamplesAshwani SinghОценок пока нет
- 03 Sparse Approx Algs PDFДокумент12 страниц03 Sparse Approx Algs PDFAshwani SinghОценок пока нет
- For Digital Image WatermarkingДокумент16 страницFor Digital Image WatermarkingNithin KumarОценок пока нет
- ISOupdate August 2019Документ25 страницISOupdate August 2019ABC100% (1)
- A Face Morphing Detection ConceptДокумент6 страницA Face Morphing Detection ConceptThomas SchindzielorzОценок пока нет
- Age and Gender Using OPENCVДокумент49 страницAge and Gender Using OPENCVShapnaОценок пока нет
- Image CompressionДокумент9 страницImage Compressionnam_picОценок пока нет
- Sentinel - Sen2Cor Guide PDFДокумент49 страницSentinel - Sen2Cor Guide PDFBAPbayu Fake AccountОценок пока нет
- Digital Image CompressionДокумент19 страницDigital Image CompressionRitu PareekОценок пока нет
- List of Malaysian StandardДокумент49 страницList of Malaysian StandardPaklong Itm Perlis33% (3)
- Digital Image Processing (Image Compression)Документ38 страницDigital Image Processing (Image Compression)MATHANKUMAR.S100% (2)
- Cardiff University exam paper solutions for Multimedia Systems courseДокумент15 страницCardiff University exam paper solutions for Multimedia Systems courseKhan Muhammad ZaidОценок пока нет
- Technologies and lesson planning in Art EducationДокумент5 страницTechnologies and lesson planning in Art EducationLeonna Dail SintiaОценок пока нет
- Deep Exploration Supported File Formats GuideДокумент5 страницDeep Exploration Supported File Formats GuideTankfulОценок пока нет
- Image Compression IДокумент32 страницыImage Compression IKritiJais100% (2)
- DIP Question BankДокумент6 страницDIP Question BankdeepuОценок пока нет
- FMNДокумент21 страницаFMNmrsneculaОценок пока нет
- STANAG - 4609 - Ed3 NATO DIGITAL MOTION IMAGERY STANDARDДокумент73 страницыSTANAG - 4609 - Ed3 NATO DIGITAL MOTION IMAGERY STANDARDRicardo CamargoОценок пока нет
- Handbook of Research On Chang Tsun Li Chang Tsun Li Handbook of Research On Computational Forensics Digital Crime and Investigation Methods A PDFДокумент620 страницHandbook of Research On Chang Tsun Li Chang Tsun Li Handbook of Research On Computational Forensics Digital Crime and Investigation Methods A PDFJuan TenorioОценок пока нет
- Fundamentals of Multimedia PDFДокумент296 страницFundamentals of Multimedia PDFJulio PlensОценок пока нет
- 13 Tirupathiraju Kanumuri Final Paper101-109Документ9 страниц13 Tirupathiraju Kanumuri Final Paper101-109iisteОценок пока нет
- VHDL Implementation of Wavelet Packet Transforms Using SIMULINK ToolsДокумент10 страницVHDL Implementation of Wavelet Packet Transforms Using SIMULINK ToolszhiwaОценок пока нет
- TG VideoДокумент11 страницTG VideoTheoОценок пока нет
- Datasheet LuciadFusion Server V2018Документ12 страницDatasheet LuciadFusion Server V2018Jyotishalok SaxenaОценок пока нет
- Ecognition®: TrimbleДокумент19 страницEcognition®: Trimblenuel pasaribuОценок пока нет
- NIST Fingerprint Testing StandardsДокумент75 страницNIST Fingerprint Testing StandardsCash Cash CashОценок пока нет
- Updated - MT390 - Tutorial 6 - Spring 2020 - 21Документ65 страницUpdated - MT390 - Tutorial 6 - Spring 2020 - 21Yousef AboamaraОценок пока нет
- 79 Deep Exploration 6.0 Supported File FormatsДокумент5 страниц79 Deep Exploration 6.0 Supported File Formatselfwyn_46Оценок пока нет
- Supplement To ISO FocusДокумент16 страницSupplement To ISO FocushoseinОценок пока нет
- Fundamentals of Multimedia PDFДокумент296 страницFundamentals of Multimedia PDFManuel Brásio100% (1)
- Normas Iso PublicadasДокумент104 страницыNormas Iso Publicadasflorin_nite2750100% (1)