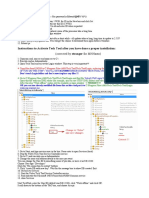
Вам также может понравиться
- Andriy Burkov - The Hundred-Page Machine Learning Book (2019, Andriy Burkov) PDFДокумент152 страницыAndriy Burkov - The Hundred-Page Machine Learning Book (2019, Andriy Burkov) PDFmuradagasiyev100% (2)
- The Art of Doing Science and Engineering Learning To Learn Richard W. Hamming ZДокумент463 страницыThe Art of Doing Science and Engineering Learning To Learn Richard W. Hamming ZRafael ValleОценок пока нет
- Information Theory, Inference and Learning Algorithms - David J. C. MacKayДокумент4 страницыInformation Theory, Inference and Learning Algorithms - David J. C. MacKaypohicyfi100% (1)
- The Cathedral and The BazaarДокумент178 страницThe Cathedral and The Bazaarnileshugale123Оценок пока нет
- Deep Learning with Python: Learn Best Practices of Deep Learning Models with PyTorchОт EverandDeep Learning with Python: Learn Best Practices of Deep Learning Models with PyTorchОценок пока нет
- Losing Lean ReligionДокумент9 страницLosing Lean ReligionDinukaDeshanОценок пока нет
- Trustworthy Online Controlled Experiments: A Practical Guide To A/B TestingДокумент44 страницыTrustworthy Online Controlled Experiments: A Practical Guide To A/B TestingJohnny Telles100% (1)
- Communication Nets: Stochastic Message Flow and DelayОт EverandCommunication Nets: Stochastic Message Flow and DelayРейтинг: 3 из 5 звезд3/5 (1)
- PEARL Etal 2018 The Book of WhyДокумент432 страницыPEARL Etal 2018 The Book of WhyLuis Antonio Tavares100% (1)
- A Leisurely Look at The Bootstrap, The Jackknife, and Cross-Validation (1983 13s) - BRADLEY EFRONДокумент13 страницA Leisurely Look at The Bootstrap, The Jackknife, and Cross-Validation (1983 13s) - BRADLEY EFRONValentin RodriguezОценок пока нет
- AI-Powered Search v14Документ398 страницAI-Powered Search v14NikhilОценок пока нет
- Attention Is All You Need Paper - RemovedДокумент9 страницAttention Is All You Need Paper - RemovedfhghОценок пока нет
- Attention Is All You Need 1hodz0wcqbДокумент11 страницAttention Is All You Need 1hodz0wcqbAbhishek JunghareОценок пока нет
- Attention Is All You NeedДокумент15 страницAttention Is All You NeeddonoglueОценок пока нет
- Attention Is All You NeedДокумент15 страницAttention Is All You NeedShubhamОценок пока нет
- 116cs0213 STW ReportДокумент11 страниц116cs0213 STW ReportAkshay SaraogiОценок пока нет
- It Ain't Much But It's ONNX WorkДокумент9 страницIt Ain't Much But It's ONNX WorkErhannisОценок пока нет
- Chap 6 EmbeddingДокумент44 страницыChap 6 EmbeddingHRITWIK GHOSHОценок пока нет
- Pointer Networks: Equal ContributionДокумент9 страницPointer Networks: Equal ContributionAkshay ChaturvediОценок пока нет
- 134 Faster Cnns With Direct SparseДокумент11 страниц134 Faster Cnns With Direct SparseTampolenОценок пока нет
- Model For Cluster OmputingДокумент10 страницModel For Cluster Omputinghulla_raghОценок пока нет
- Simple, Distributed, and Accelerated Probabilistic ProgrammingДокумент16 страницSimple, Distributed, and Accelerated Probabilistic ProgrammingM Feldy RizaОценок пока нет
- Longformer - The Long-Document Transformer - SUMMARYДокумент4 страницыLongformer - The Long-Document Transformer - SUMMARYĐức ChuОценок пока нет
- DSCCДокумент10 страницDSCCpokemonbeast920Оценок пока нет
- 5 Days InetrnshipДокумент48 страниц5 Days InetrnshipsowmiОценок пока нет
- Lecture 1-4: 1. Design PhilosophyДокумент7 страницLecture 1-4: 1. Design PhilosophyrajawidadiОценок пока нет
- EHaCON - 2019 Paper 8Документ20 страницEHaCON - 2019 Paper 8Himadri Sekhar DuttaОценок пока нет
- Polynomial Expansion PaperДокумент4 страницыPolynomial Expansion PaperSrividyaGanapathiОценок пока нет
- Image To MarkupДокумент16 страницImage To Markupoctoparse8Оценок пока нет
- Two Hardware Implementations For Modular Multip - 2021 - Journal of InformationДокумент12 страницTwo Hardware Implementations For Modular Multip - 2021 - Journal of Informationnosofo4431Оценок пока нет
- Machine Learning (ML) :: Aim: Analysis and Implementation of Deep Neural Network. DefinitionsДокумент6 страницMachine Learning (ML) :: Aim: Analysis and Implementation of Deep Neural Network. DefinitionsVishal LuniaОценок пока нет
- A Simplified Generative Model Based On Gradient Descent and Mean Square ErrorДокумент8 страницA Simplified Generative Model Based On Gradient Descent and Mean Square ErrorOmar Lopez-RinconОценок пока нет
- IJETR021595Документ6 страницIJETR021595erpublicationОценок пока нет
- Unit 3Документ52 страницыUnit 3shruthikagudemОценок пока нет
- CNN and AutoencoderДокумент56 страницCNN and AutoencoderShubham BhaleraoОценок пока нет
- 495 Lecture 10 AttallДокумент18 страниц495 Lecture 10 AttallMohibur NabilОценок пока нет
- Hardware RSA Accelerator: Group 3: Ariel Anders, Timur Balbekov, Neil Forrester May 15, 2013Документ15 страницHardware RSA Accelerator: Group 3: Ariel Anders, Timur Balbekov, Neil Forrester May 15, 2013Rash RashadОценок пока нет
- R: T E T: Eformer HE Fficient RansformerДокумент12 страницR: T E T: Eformer HE Fficient RansformerIslah GsmОценок пока нет
- Neural Enquirer: Learning To Query Tables With Natural LanguageДокумент19 страницNeural Enquirer: Learning To Query Tables With Natural Languagea4104165Оценок пока нет
- IBM CoreletДокумент10 страницIBM CoreletRenjith PillaiОценок пока нет
- Parallel Algorithms For Logic SynthesisДокумент7 страницParallel Algorithms For Logic SynthesisKruthi SubramanyaОценок пока нет
- Modeling A Perceptron Neuron Using Verilog Developed Floating Point Numbering System and Modules For Hardware SynthesisДокумент14 страницModeling A Perceptron Neuron Using Verilog Developed Floating Point Numbering System and Modules For Hardware SynthesisNaveen KumarОценок пока нет
- Digital CommunicationДокумент43 страницыDigital CommunicationRavi kumarОценок пока нет
- Deep Koalarization: Image Colorization Using Cnns and Inception-Resnet-V2Документ12 страницDeep Koalarization: Image Colorization Using Cnns and Inception-Resnet-V2Nitheesh ReddyОценок пока нет
- Deep Learning PDFДокумент55 страницDeep Learning PDFNitesh Kumar SharmaОценок пока нет
- (Alt, Tobias, Et Al.), Translating Numerical Concepts For Pdes Into Neural Architectures, Arxiv Preprint Arxiv-2103.15419 (2021) .Документ12 страниц(Alt, Tobias, Et Al.), Translating Numerical Concepts For Pdes Into Neural Architectures, Arxiv Preprint Arxiv-2103.15419 (2021) .Aman JalanОценок пока нет
- Major Project Presentation 2 - G6Документ13 страницMajor Project Presentation 2 - G6Hdyo mdmdОценок пока нет
- 4th Unit Aktu Machine LearningДокумент9 страниц4th Unit Aktu Machine LearningANMOL SINGHОценок пока нет
- The Weka Multilayer Perceptron Classifier: Daniel I. MORARIU, Radu G. Creţulescu, Macarie BreazuДокумент9 страницThe Weka Multilayer Perceptron Classifier: Daniel I. MORARIU, Radu G. Creţulescu, Macarie BreazuAliza KhanОценок пока нет
- RKM072A29 - Online Assignment 1 - INT248 - ReportДокумент18 страницRKM072A29 - Online Assignment 1 - INT248 - ReportShahid aliОценок пока нет
- ML Unit-5Документ8 страницML Unit-5Supriya alluriОценок пока нет
- ML Lab 11 Manual - Neural Networks (Ver4)Документ8 страницML Lab 11 Manual - Neural Networks (Ver4)dodela6303Оценок пока нет
- ToДокумент14 страницToyetsedawОценок пока нет
- Neural Network Learning For Analog VLSI Implementations of Support Vector Machines: A SurveyДокумент19 страницNeural Network Learning For Analog VLSI Implementations of Support Vector Machines: A SurveyPurohit Manish RОценок пока нет
- The Comparison of CPU Time Consumption For PDFДокумент4 страницыThe Comparison of CPU Time Consumption For PDFGeison QuevedoОценок пока нет
- XG1.2 BrochureДокумент6 страницXG1.2 BrochureSholl1Оценок пока нет
- Mathematical LogicДокумент15 страницMathematical LogicEfean KimОценок пока нет
- C Cube20S 10-15 ENДокумент2 страницыC Cube20S 10-15 ENGelu BoneaОценок пока нет
- Definition of Conceptual FrameworkДокумент3 страницыDefinition of Conceptual FrameworkryanОценок пока нет
- KUKA Datenblatt FlexFELLOW enДокумент2 страницыKUKA Datenblatt FlexFELLOW enMarincean MihaiОценок пока нет
- Chapter 29Документ4 страницыChapter 29Siraj Ud-DoullaОценок пока нет
- GATE Syllabus - Mathematics: GATE 2009 2010 Syl Labus - Mathemati CsДокумент8 страницGATE Syllabus - Mathematics: GATE 2009 2010 Syl Labus - Mathemati CsAyush MaheshwariОценок пока нет
- eAM DO-070 USER GUIDE KU V1.0 PDFДокумент39 страницeAM DO-070 USER GUIDE KU V1.0 PDFAl Busaidi100% (1)
- Coupled Tanks - Workbook (Student) INGLÉS PDFДокумент34 страницыCoupled Tanks - Workbook (Student) INGLÉS PDFDanielaLópezОценок пока нет
- Adu451604 PDFДокумент2 страницыAdu451604 PDFAnnBlissОценок пока нет
- Symmetrical Cat Products in CatiaV5-20110308Документ12 страницSymmetrical Cat Products in CatiaV5-20110308siegfried_roosОценок пока нет
- Linux QMI SDK Application Developers Guide 1.23Документ55 страницLinux QMI SDK Application Developers Guide 1.23agrothendieckОценок пока нет
- Service Strategy Service Design Service Transition Service Operation Continual Service ImprovementДокумент4 страницыService Strategy Service Design Service Transition Service Operation Continual Service Improvementfranklin_mongeОценок пока нет
- 51841Документ15 страниц51841Hermenegildo LuisОценок пока нет
- Installation Instructions (Corrected)Документ1 страницаInstallation Instructions (Corrected)Sicein SasОценок пока нет
- Communication in The WorkplaceДокумент25 страницCommunication in The WorkplaceApoorv Goel100% (1)
- Using WireShark For Ethernet DiagnosticsДокумент16 страницUsing WireShark For Ethernet DiagnosticsPiotrekBzdręgaОценок пока нет
- 1999-07 The Computer Paper - BC EditionДокумент138 страниц1999-07 The Computer Paper - BC EditionthecomputerpaperОценок пока нет
- Us 14 Forristal Android FakeID Vulnerability WalkthroughДокумент36 страницUs 14 Forristal Android FakeID Vulnerability Walkthroughth3.pil0tОценок пока нет
- General Topics: Related To Food Testing LaboratoriesДокумент9 страницGeneral Topics: Related To Food Testing LaboratoriessampathdtОценок пока нет
- Oracle Database 11g Release 2 (11.2) - E25519-07 - PLSQL Language ReferenceДокумент768 страницOracle Database 11g Release 2 (11.2) - E25519-07 - PLSQL Language ReferenceLuciano Merighetti MarwellОценок пока нет
- Multiple Choice Quiz 8B: CorrectДокумент2 страницыMultiple Choice Quiz 8B: CorrectUsama AshfaqОценок пока нет
- Three-Dimensional Stress Analysis: 3/29/2014 3D Problems 1Документ59 страницThree-Dimensional Stress Analysis: 3/29/2014 3D Problems 1Deepak ChachraОценок пока нет
- Error at FB60 - Toolbox For IT GroupsДокумент2 страницыError at FB60 - Toolbox For IT GroupsSandeep HariОценок пока нет
- Magic Quadrant For Project and Portfolio Management: Strategic Planning AssumptionsДокумент37 страницMagic Quadrant For Project and Portfolio Management: Strategic Planning AssumptionsHashim SmithОценок пока нет
- Mesh Intro 18.0 WS4.1 CFD Workshop Instructions Local Mesh ControlsДокумент33 страницыMesh Intro 18.0 WS4.1 CFD Workshop Instructions Local Mesh Controlsrodrigoq1Оценок пока нет
- AggRAM Op Man D6500094D PDFДокумент108 страницAggRAM Op Man D6500094D PDFDewi ArisandyОценок пока нет
- 2.1 WorkbookДокумент33 страницы2.1 Workbookbaroliy775Оценок пока нет
- Anna University MBA - All Year, Semester Syllabus Ordered Lecture Notes and Study Material For College StudentsДокумент69 страницAnna University MBA - All Year, Semester Syllabus Ordered Lecture Notes and Study Material For College StudentsM.V. TVОценок пока нет
- Activating CheatsДокумент24 страницыActivating CheatsgashobabaОценок пока нет
- ChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveОт EverandChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveОценок пока нет
- ChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindОт EverandChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindОценок пока нет
- Scary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldОт EverandScary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldРейтинг: 4.5 из 5 звезд4.5/5 (55)
- The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldОт EverandThe Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldРейтинг: 4.5 из 5 звезд4.5/5 (107)
- Generative AI: The Insights You Need from Harvard Business ReviewОт EverandGenerative AI: The Insights You Need from Harvard Business ReviewРейтинг: 4.5 из 5 звезд4.5/5 (2)
- Artificial Intelligence: The Insights You Need from Harvard Business ReviewОт EverandArtificial Intelligence: The Insights You Need from Harvard Business ReviewРейтинг: 4.5 из 5 звезд4.5/5 (104)
- ChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessОт EverandChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessОценок пока нет
- Artificial Intelligence: A Guide for Thinking HumansОт EverandArtificial Intelligence: A Guide for Thinking HumansРейтинг: 4.5 из 5 звезд4.5/5 (30)
- Four Battlegrounds: Power in the Age of Artificial IntelligenceОт EverandFour Battlegrounds: Power in the Age of Artificial IntelligenceРейтинг: 5 из 5 звезд5/5 (5)
- 100M Offers Made Easy: Create Your Own Irresistible Offers by Turning ChatGPT into Alex HormoziОт Everand100M Offers Made Easy: Create Your Own Irresistible Offers by Turning ChatGPT into Alex HormoziОценок пока нет
- The Roadmap to AI Mastery: A Guide to Building and Scaling ProjectsОт EverandThe Roadmap to AI Mastery: A Guide to Building and Scaling ProjectsОценок пока нет
- HBR's 10 Must Reads on AI, Analytics, and the New Machine AgeОт EverandHBR's 10 Must Reads on AI, Analytics, and the New Machine AgeРейтинг: 4.5 из 5 звезд4.5/5 (69)
- The AI Advantage: How to Put the Artificial Intelligence Revolution to WorkОт EverandThe AI Advantage: How to Put the Artificial Intelligence Revolution to WorkРейтинг: 4 из 5 звезд4/5 (7)
- Working with AI: Real Stories of Human-Machine Collaboration (Management on the Cutting Edge)От EverandWorking with AI: Real Stories of Human-Machine Collaboration (Management on the Cutting Edge)Рейтинг: 5 из 5 звезд5/5 (5)
- Who's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesОт EverandWho's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesРейтинг: 4.5 из 5 звезд4.5/5 (13)
- T-Minus AI: Humanity's Countdown to Artificial Intelligence and the New Pursuit of Global PowerОт EverandT-Minus AI: Humanity's Countdown to Artificial Intelligence and the New Pursuit of Global PowerРейтинг: 4 из 5 звезд4/5 (4)
- Your AI Survival Guide: Scraped Knees, Bruised Elbows, and Lessons Learned from Real-World AI DeploymentsОт EverandYour AI Survival Guide: Scraped Knees, Bruised Elbows, and Lessons Learned from Real-World AI DeploymentsОценок пока нет
- Power and Prediction: The Disruptive Economics of Artificial IntelligenceОт EverandPower and Prediction: The Disruptive Economics of Artificial IntelligenceРейтинг: 4.5 из 5 звезд4.5/5 (38)
- Competing in the Age of AI: Strategy and Leadership When Algorithms and Networks Run the WorldОт EverandCompeting in the Age of AI: Strategy and Leadership When Algorithms and Networks Run the WorldРейтинг: 4.5 из 5 звезд4.5/5 (21)
- The Digital Mind: How Science is Redefining HumanityОт EverandThe Digital Mind: How Science is Redefining HumanityРейтинг: 4.5 из 5 звезд4.5/5 (2)
- Hands-On System Design: Learn System Design, Scaling Applications, Software Development Design Patterns with Real Use-CasesОт EverandHands-On System Design: Learn System Design, Scaling Applications, Software Development Design Patterns with Real Use-CasesОценок пока нет
- Python Machine Learning - Third Edition: Machine Learning and Deep Learning with Python, scikit-learn, and TensorFlow 2, 3rd EditionОт EverandPython Machine Learning - Third Edition: Machine Learning and Deep Learning with Python, scikit-learn, and TensorFlow 2, 3rd EditionРейтинг: 5 из 5 звезд5/5 (2)
- Architects of Intelligence: The truth about AI from the people building itОт EverandArchitects of Intelligence: The truth about AI from the people building itРейтинг: 4.5 из 5 звезд4.5/5 (21)