Академический Документы
Профессиональный Документы
Культура Документы
SEPARATA-Estadística Descriptiva
Загружено:
Gladys Esperanza Godines SanchezОригинальное название
Авторское право
Доступные форматы
Поделиться этим документом
Поделиться или встроить документ
Этот документ был вам полезен?
Это неприемлемый материал?
Пожаловаться на этот документАвторское право:
Доступные форматы
SEPARATA-Estadística Descriptiva
Загружено:
Gladys Esperanza Godines SanchezАвторское право:
Доступные форматы
Estadística Descriptiva(*)
Conceptos Generales
Origen, Avance y Desarrollo Histórico
“Surgimiento de la Estadística en la Antigüedad”
La estadística surgió en épocas muy remotas; como todas las ciencias, no se creó de
improviso, sino mediante un proceso largo de desarrollo y evolución, desde hechos de
simple recolección de datos hasta la diversidad y rigurosa interpretación de los datos que
se dan hoy en día.
Desde los comienzos de la civilización han existido formas sencillas de estadística, pues
ya se utilizaban representaciones gráficas y otros símbolos en pieles, rocas, palos de
madera y paredes de cuevas para contar el número de personas, animales o cosas. Es una
ciencia con tanta antigüedad como la escritura, y es por sí misma auxiliar de todas
las demás ciencias.
El nacimiento de la Estadística se puede situar en el año 3050 A.C., en el Antiguo
Egipto.
Los mercados, la medicina, la ingeniería, los gobiernos, etc. se nombran entre los más
destacados clientes de esta ciencia.
Los comienzos de la estadística pueden ser hallados en el antiguo Egipto, cuyos faraones
lograron recopilar, hacia el año 3050 a. C., prolijos datos relativos a la población y la
riqueza del país.
De acuerdo al historiador griego Heródoto, dicho registro de riqueza y población se hizo
con el objetivo de preparar la construcción de las pirámides. En el mismo Egipto, Ramsés
II hizo un censo de las tierras con el objeto de verificar un nuevo reparto.
(*) BIBLIOTECA DE INVESTIGACIONES-MÉXICO 1
Hacia el año 3000 a.C. los babilonios usaban pequeñas tablillas de arcilla para recopilar
datos sobre la producción agrícola y sobre los géneros vendidos o cambiados mediante
trueque. En el antiguo Israel la Biblia da referencia del uso estadístico, principalmente en
los libros de Números y Crónicas que incluyen, en algunas partes, trabajos de esta índole.
El primero contiene dos censos de la población de Israel y el segundo describe el
bienestar material de las diversas tribus judías.
En China se efectuaron censos de población, pues varios registros numéricos con
anterioridad al año 2000 a.C. dan fe de ello. Los griegos efectuaron censos
periódicamente hacia 594 a. C., con fines tributarios, sociales (división de tierras) y
militares (cálculo de recursos y hombres disponibles). La investigación histórica revela
que se realizaron 69 censos para calcular los impuestos, determinar los derechos de voto
y ponderar la potencia guerrera.
El Imperio Romano, fue el primer gobierno en emplear los recursos estadísticos para
calcular su población, su superficie territorial y renta de sus territorios.
El Imperio romano, maestro de la organización política, fue el primer gobierno que
supo emplear los recursos de la estadística, mediante la recopilación de una gran cantidad
de datos sobre la población, superficie y renta de todos los territorios bajo su control: cada
cinco años realizaban un censo de la población y sus funcionarios públicos tenían la
obligación de anotar nacimientos, defunciones y matrimonios, sin olvidar los recuentos
periódicos del ganado y de las riquezas contenidas en las tierras conquistadas. Para el
nacimiento de Cristo sucedía uno de estos empadronamientos de la población bajo la
autoridad del imperio.
Durante los mil años siguientes a la caída del imperio Romano realizaron operaciones
sobre las relaciones de tierras pertenecientes a la Iglesia; en la edad media sólo se
realizaron algunos censos exhaustivos en Europa. Los reyes caloringios Pipino el Breve
y Carlomagno ordenaron hacer estudios minuciosos de las propiedades de la Iglesia en
los años 758 y 762 respectivamente.
“Desarrollo y avances en la Estadística”
Durante el siglo IX se realizaron en Francia algunos censos parciales de siervos. En
Inglaterra, después de la conquista normanda en 1066, Guillermo el Conquistador
(*) BIBLIOTECA DE INVESTIGACIONES-MÉXICO 2
encargó la realización de un censo. La información obtenida fue recopilada en el
Domesday Book o libro del Gran Catastro para el año 1086, un documento de la
propiedad, extensión y valor de las tierras de Inglaterra. Esa obra fue el primer compendio
estadístico de Inglaterra.
Guillermo el Conquistador ordenó en 1066 un censo, recopilado en el “Libro del Gran
Castro”, considerado el primer compendio estadístico de Inglaterra.
Aunque Carlomagno, en Francia; y Guillermo el Conquistador, en Inglaterra, trataron de
revivir la técnica romana, los métodos estadísticos permanecieron casi olvidados durante
la Edad Media.
Durante los siglos XV, XVI, y XVII, hombres como Leonardo de Vinci, Nicolás
Copérnico, Galileo, Neper, William Harvey, Sir Francis Bacon y René Descartes,
hicieron grandes operaciones al método científico, de tal forma que cuando se crearon los
Estados Nacionales y surgió como fuerza el comercio internacional existía ya un método
capaz de aplicarse a los datos económicos.
Por el año 1540 el alemán Sebastián Muster realizó una compilación estadística de los
recursos nacionales, comprensiva de datos sobre organización política, instrucciones
sociales, comercio y poderío militar. Durante el siglo XVII aportó indicaciones más
concretas de métodos de observación y análisis cuantitativo y amplió los campos de la
inferencia y la teoría Estadística.
Los eruditos del siglo XVII demostraron especial interés por la Estadística Demográfica
como resultado de la especulación sobre si la población aumentaba, decrecía o
permanecía estática. En los tiempos modernos tales métodos fueron resucitados por
algunos reyes que necesitaban conocer las riquezas monetarias y el potencial humano de
sus respectivos países.
El primer empleo de los datos estadísticos para fines ajenos a la política tuvo lugar en
1691 y estuvo a cargo de Gaspar Neumann, un profesor alemán que vivía en Breslau.
(*) BIBLIOTECA DE INVESTIGACIONES-MÉXICO 3
Este investigador se propuso destruir la antigua creencia popular de que en los años
terminados en siete moría más gente que en los restantes, y para lograrlo hurgó
pacientemente en los archivos parroquiales de la ciudad. Después de revisar miles de
partidas de defunción pudo demostrar que en tales años no fallecían más personas que
en los demás. Los procedimientos de Neumann fueron conocidos por el astrónomo inglés
Halley, descubridor del cometa que lleva su nombre, quien los aplicó al estudio de la
vida humana. Sus cálculos sirvieron de base para las tablas de mortalidad que hoy
utilizan todas las compañías de seguros.
Durante el siglo XVII y principios del XVIII, matemáticos como Bernoulli, Francis
Maseres, Lagrange y Laplace desarrollaron la teoría de probabilidades. No obstante
durante cierto tiempo, la teoría de las probabilidades limitó su aplicación a los juegos de
azar y hasta el siglo XVIII no comenzó a aplicarse a los grandes problemas científicos.
científicos.
En 1760, Godofredo Achenwall, acuñó la palabra “Estadística”.
Godofredo Achenwall, profesor de la Universidad de Gotinga, acuñó en 1760 la palabra
estadística, que extrajo del término italiano statista (estadista). Creía, y con sobrada
razón, que los datos de la nueva ciencia serían el aliado más eficaz del gobernante
consciente. La raíz remota de la palabra se halla, por otra parte, en el término latino status,
que significa estado o situación; Esta etimología aumenta el valor intrínseco de la
palabra, por cuanto la estadística revela el sentido cuantitativo de las más variadas
situaciones.
Jacques Quételect es quien aplica las Estadísticas a las ciencias sociales. Este interpretó
la teoría de la probabilidad para su uso en las ciencias sociales y resolver la aplicación del
principio de promedios y de la variabilidad a los fenómenos sociales. Quételect fue el
primero en realizar la aplicación práctica de todo el método Estadístico, entonces
conocido, a las diversas ramas de la ciencia.
Entretanto, en el período del 1800 al 1820 se desarrollaron dos conceptos matemáticos
fundamentales para la teoría Estadística; la teoría de los errores de observación,
(*) BIBLIOTECA DE INVESTIGACIONES-MÉXICO 4
aportada por Laplace y Gauss; y la teoría de los mínimos cuadrados desarrollada por
Laplace, Gauss y Legendre.
A finales del siglo XIX, Sir Francis Gaston ideó el método conocido por Correlación,
que tenía por objeto medir la influencia relativa de los factores sobre las variables. De
aquí partió el desarrollo del coeficiente de correlación creado por Karl Pearson y otros
cultivadores de la ciencia biométrica como J. Pease Norton, R. H. Hooker y G. Udny
Yule, que efectuaron amplios estudios sobre la medida de las relaciones.
“Nacimiento de la Estadística Moderna”
Ronald Arnold Fisher, figura más influyente de la Estadística.
Una vez sentadas las bases de la teoría de probabilidades, podemos situar el nacimiento
de la estadística moderna y su empleo en el análisis de experimentos en los trabajos de
Francis Galton y Kurt Pearson. Este último publicó en 1892 el libro The Grammar of
Science (La gramática de la ciencia), un clásico en la filosofía de la ciencia, y fue él quien
ideó el conocido test de Chi -cuadrado. El hijo de Pearson, Egon, y el matemático nacido
en Polonia Jerzy Neyman pueden considerarse los fundadores de las pruebas modernas
de contraste de hipótesis.
Pero es sin lugar a dudas Ronald Arnold Fisher la figura más influyente de la
estadística, pues la situó como una poderosa herramienta para la planeación y análisis
de experimentos. Contemporáneo de Pearson, desarrolló el análisis de varianza y fue
pionero en el desarrollo de numerosas técnicas de análisis multivariante y en la
introducción del método de máxima verosimilitud para la estimación de parámetros. Su
libro Statistical Methods for Research Workers (Métodos estadísticos para los
investigadores), publicado en 1925, ha sido probablemente el libro de estadística más
utilizado a lo largo de muchos años.
Mientras tanto, en Rusia, una activa y fructífera escuela de matemáticas y estadística
aportó asimismo –como no podía ser de otro modo– su considerable influencia. Desde
finales del siglo XVIII y comienzos del XIX cabe destacar las figuras de Pafnuty
(*) BIBLIOTECA DE INVESTIGACIONES-MÉXICO 5
Chebichev y Andrei Harkov, y posteriormente las de Alexander Khinchin y Andrey
Kolmogorov.
Sucesos de interés en el desarrollo de la estadística
En el siglo XIX, con la generalización del método científico para estudiar todos los
fenómenos de las ciencias naturales y sociales, los investigadores vieron la necesidad de
reducir la información a valores numéricos para evitar la ambigüedad de las descripciones
verbales.
Los progresos más recientes en el campo de la Estadística se refieren al ulterior desarrollo
del cálculo de probabilidades, particularmente en la rama denominada indeterminismo
o relatividad, se ha demostrado que el determinismo fue reconocido en la Física como
resultado de las investigaciones atómicas y que este principio se juzga aplicable tanto a
las ciencias sociales como a las físicas. [1], [2], [3], [4], [5], [6] y [7]
Influencia y Aplicaciones de la Estadística en la Sociedad Actual
(*) BIBLIOTECA DE INVESTIGACIONES-MÉXICO 6
En nuestros días, la estadística se ha convertido en un método efectivo para describir con
exactitud los valores de datos económicos, políticos, sociales, psicológicos, biológicos
o físicos, y sirve como herramienta para relacionar y analizar dichos datos. El trabajo del
experto estadístico no consiste ya sólo en reunir y tabular los datos, sino sobre todo en el
proceso de “interpretación” de esa información.
La Estadística es ampliamente utilizada para la exactitud de datos económicos,
políticos...
La estadística que conocemos hoy día debe gran parte de sus logros a los trabajos
matemáticos de aquellos hombres que desarrollaron la teoría de las probabilidades, con
la cual se adhirió la estadística a las ciencias formales. El desarrollo de la teoría de la
probabilidad ha aumentado el alcance de las aplicaciones de la estadística.
De esta manera, la estadística ocupa un lugar de gran importancia en la investigación
y en la práctica médica. En los estudios de medicina de cualquier país se incluyen varias
asignaturas dedicadas a la estadística; es difícil, por no decir imposible, que un trabajo de
investigación sea aceptado por una revista médica sin que sus autores hayan utilizado
técnicas y conceptos estadísticos en su planteamiento y en el análisis de los datos.
Muchos conjuntos de datos se pueden aproximar, con gran exactitud, utilizando
determinadas distribuciones probabilísticas; los resultados de éstas se pueden utilizar
para analizar datos estadísticos.
La Estadística es de suma importancia en la Investigación y la práctica médica.
Es una herramienta indispensable para la toma de decisiones; se ha convertido en un
método efectivo para describir con exactitud los valores de los datos económicos,
(*) BIBLIOTECA DE INVESTIGACIONES-MÉXICO 7
políticos, sociales, psicológicos, biológicos y físicos, y sirve como herramienta para
relacionar y analizar dichos datos. El trabajo del experto estadístico no consiste ya sólo
en reunir y tabular los datos, sino sobre todo en interpretar esa información.
También es ampliamente empleada para mostrar los aspectos cuantitativos de una
situación. La estadística está relacionada con el estudio de proceso cuyo resultado es más
o menos imprescindible y con la finalidad de obtener conclusiones para tomar decisiones
razonables de acuerdo con tales observaciones.
El resultado de estudio de dichos procesos, denominados procesos aleatorios, puede
ser de naturaleza cualitativa o cuantitativa y, en este último caso, discreto o continúa.
Son muchas las predicciones de tipo sociólogo, o económico, que pueden hacerse a partir
de la aplicación exclusiva de razonamientos probabilísticos a conjuntos de
datos objetivos como son, por ejemplo, los de naturaleza demográfica.
La estadística es un potente auxiliar de muchas ciencias y actividades
humanas: sociología, psicología, geografía humana, economía, etc. Las predicciones
estadísticas, difícilmente hacen referencia a sucesos concretos, pero describen con
considerable precisión en el comportamiento global de grandes conjuntos de sucesos
particulares.
De manera más específica, sirve para saber quien, de entre los miembros de una población
importante, va a encontrar trabajo o a quedarse sin él; o en cuales miembros va a verse
aumentada o disminuida una familia concreta en los próximos meses. Sin
embargo, puede proporcionar estimaciones fiables del próximo aumento o disminución
de la tasa de desempleo referido al conjunto de la población; o de la posible variación de
os índices de natalidad o mortalidad.
La aplicación de la Estadística en la Contabilidad
En el caso específico de la contabilidad, la estadística es muy importante, pues se aplica
para seleccionar muestras, cuando se pretende hacer una auditoria; también funciona para
medir la variación de costos de producción.
(*) BIBLIOTECA DE INVESTIGACIONES-MÉXICO 8
En la Contabilidad, es una herramienta rápida y eficiente para la solución de problemas
de costos y auditorías
La estadística matemática y en particular los métodos de muestreo, juegan un papel
de gran importancia y utilidad en el desarrollo de una auditoría, esto gracias a
su carácter de rapidez y economía. Cómo seleccionar la muestra, cómo realizar la
inferencia (extrapolación de las conclusiones obtenidas sobre la muestra, al resto de
la población), y qué grado de confianza se tiene en ello, son los principales problemas a
los cuáles de una solución efectiva.
El muestreo, es un procedimiento por el que se infieren los valores verdaderos de una
población, a través de la experiencia obtenida con una muestra de esta. El uso de
muestras para estimar valores de una población ofrece diversas ventajas. En términos
generales se puede afirmar que el muestreo permite una reducción considerable de
los costos materiales del estudio, una mayor rapidez en la obtención de
la información y el logro de resultados con máxima calidad.
Hoy las técnicas de muestreo asistidas por computadoras, son herramientas básicas,
pues la rápida toma de decisiones que hay que ejecutar en la dinámica de
los procesos económicos, demanda el uso de nuevas tecnologías que le impriman una
rapidez, confiabilidad, disponibilidad y capacidad, entre otras facilidades, que se han
ido buscando a través de los recursos informáticos.
Con el avance de la Informática y la vinculación de esta a la Estadística, se maneja de
manera rápida, fiable y relativamente sencilla grandes volúmenes de información, y
obtener conclusiones que después el profesional interpreta, mediante el uso de paquetes
de programas, tales como el estatistics, el SPSS, el statgraphics, que facilitan el empleo
de procedimientos estadísticos usados por algunos auditores, contadores e investigadores
en general. [6], [7], [8], [9], [10] y [11]
Definiciones de la Estadística
¿Qué es la Estadística?
(*) BIBLIOTECA DE INVESTIGACIONES-MÉXICO 9
Sir John Sinclair, introdujo la recolección y clasificación de datos a la Estadística.
Después de haber conocido el origen y desarrollo de la Estadística como ciencia así como
su influencia y aplicaciones en la sociedad actual, toca turno de definir y comprender qué
es la Estadística.
Si bien, existen diversas definiciones acerca de esta ciencia, considero preciso el
comenzar por aclarar el origen etimológico, a pesar de que como ya vimos, fue
Godofredo Achenwall quien en 1760, acuñó la palabra Estadística.
Así pues, Estadística proviene del término alemán Statistik que se traduce como “La
ciencia del Estado”, por lo que designaba originalmente el análisis de datos del Estado.
En el siglo XIX cuando el militar británico Sir John Sinclair (1754-1835) introdujo al
término estadística el significado de recolectar y clasificar datos. También se sabe
proviene del latín statisticum collegium (“consejo de Estado”) y su derivado
italiano statista (“hombre de Estado o político”).
Ahora bien, después de haber dado a conocer el significado etimológico, es preciso el
saber cuál es la definición conceptual del término en cuestión. Para ello, he decidido
tomar la definición que el autor Ignacio M. Lizárraga Gaudry hace respecto a esta
ciencia, pues la considero una respuesta completa y concreta para definirla de manera
generalizada. Entonces, el señor Lizárraga considera la Estadística como:
“La rama de las matemáticas que recopila, organiza, analiza e interpreta los datos
obtenidos de un problema estadístico, para obtener conocimiento de los hechos pasados,
para prever situaciones futuras y tomar decisiones en base a las experiencias”.
Ahora, a pesar de ser la anterior una respuesta entendible y completa, es necesario el
exponer otras interesantes definiciones acerca del tema, tales como las siguientes:
1. Es una rama de las matemáticas que se ocupa de reunir, organizar y analizar datos
numéricos y que ayuda a resolver problemas como el diseño de experimentos y la
toma de decisiones. [6]
2. Es el recuento, ordenación y clasificación de los datos obtenidos por las
observaciones, para poder hacer comparaciones y sacar conclusiones. [12]
3. Es un conjunto de métodos científicos ligados a la toma, organización,
recopilación, presentación y análisis de datos, tanto para la deducción de
conclusiones como para tomar decisiones razonables de acuerdo con tales análisis.
[13]
4. Es la ciencia cuyo objetivo es reunir una información cuantitativa concerniente a
individuos, grupos, series de hechos, etc. y deducir de ello gracias al análisis de
estos datos unos significados precisos o unas previsiones para el futuro. [14]
5. En general, es la ciencia que trata de la recopilación, organización presentación,
análisis e interpretación de datos numéricos con el fin de realizar una toma de
decisión más efectiva. [14]
6. Es la ciencia que tiene por objeto el estudio cuantitativo de los colectivos. Enrique
Chacón [14]
(*) BIBLIOTECA DE INVESTIGACIONES-MÉXICO 10
7. La ciencia que tiene por objeto aplicar las leyes de la cantidad a los hechos sociales
para medir su intensidad, deducir las leyes que los rigen y hacer su predicción
próxima.
Óscar Vázquez Mínguez [14]
Ahora bien, en cuanto a la Estadística Descriptiva, específicamente hablando, podemos
definirla como la ciencia que analiza, estudia y describe a la totalidad de individuos de
una población. Su finalidad es obtener información, analizarla, elaborarla y
simplificarla lo necesario para que pueda ser interpretada cómoda y rápidamente y, por
tanto, pueda utilizarse eficazmente para el fin que se desee. [6]
División de la Estadística y su Objeto de Estudio
La Estadística se puede clasificar en función de su etapa o función, del tiempo
considerado o del número de variables estudiadas.
La Estadística es una disciplina que utiliza recursos matemáticos para organizar y
resumir una gran cantidad de datos obtenidos de la realidad, e inferir conclusiones
respecto de ellos. Tiene como propósito la descripción del conjunto de datos
colectados, así como la generalización y/o toma de decisiones acerca de las
características de todas las observaciones potenciales
bajo consideración. En consecuencia nos permite organizar y resumir datos para
poder realizar inferencias (conclusiones) relativas a los mismos. Para su mejor estudio se
han creado varias formas de clasificar los estudios estadísticos. Algunas de las más
comunes son las siguientes:
“Clasificación de la Estadística según la etapa o función”
Generalmente se considera que la estadística tiene dos funciones (divisiones). Hay
una estadística descriptiva y una estadística inferencial. La primera etapa se ocupa de
describir la muestra, y la segunda etapa infiere conclusiones a partir de los datos que
describen la muestra (por ejemplo con respecto a la población). A continuación, se dará
paso a describir brevemente, cada etapa.
(*) BIBLIOTECA DE INVESTIGACIONES-MÉXICO 11
Estadística Descriptiva o Deductiva
Se refiere a la recolección, presentación, descripción, análisis e interpretación de una
colección de datos, esencialmente consiste en resumir éstos con uno o dos elementos de
información (medidas descriptivas) que caracterizan la totalidad de los mismos.
La Estadística Descriptiva recolecta, describe, analiza, interpreta y presenta los datos de
una población en forma de tablas y gráficas
Consiste sobre todo en la presentación de datos en forma de tablas y gráficas; así que
se emplea simplemente para resumir de forma numérica o gráfica un conjunto de datos.
Esta comprende cualquier actividad relacionada con los datos y está diseñada para
resumir o describir los mismos sin factores pertinentes adicionales; esto es, sin intentar
inferir nada que vaya más allá de los datos, como tales.
La estadística Descriptiva es el método de obtener de un conjunto de datos
conclusiones sobre sí mismos y no sobrepasan el conocimiento proporcionado por
éstos. Puede utilizarse para resumir o describir cualquier conjunto ya sea que se trate
de una población o de una muestra, cuando en la etapa preliminar de la Inferencia
Estadística se conocen los elementos de una muestra.
Así pues, si aplicamos las herramientas ofrecidas por la estadística descriptiva a una
muestra, solo nos limitaremos a describir los datos encontrados en dicha muestra, por lo
que no se podrá generalizar la información hacia la población.
(*) BIBLIOTECA DE INVESTIGACIONES-MÉXICO 12
Estadística Inferencial o Inductiva
La Estadística Inferencial trabaja a base de muestras para inferir aspectos de la
población.
La estadística descriptiva trabaja con todos los individuos de la población. La estadística
inferencial, sin embargo, trabaja con muestras, subconjuntos formados por algunos
individuos de la población. A partir del estudio de la muestra se pretende inferir
aspectos relevantes de toda la población. Cómo se selecciona la muestra, cómo se
realiza la inferencia, y qué grado de confianza se puede tener en ella son aspectos
fundamentales de la estadística inferencial, para cuyo estudio se requiere un alto nivel de
conocimientos de estadística, probabilidad y matemáticas.
Para que éstas generalizaciones sean válidas la muestra deben ser representativa de la
población y la calidad de la información debe ser controlada, además puesto que las
conclusiones así extraídas están sujetas a errores, se tendrá que especificar el riesgo o
probabilidad que con que se pueden cometer esos errores.
La Estadística Inferencial investiga o analiza una población partiendo de una
muestra tomada. Es así que permite realizar conclusiones o inferencias, basándose en
los datos simplificados y analizados de una muestra hacia la población o universo.
Por ejemplo, a partir de una muestra representativa tomada a los habitantes de una
ciudad, se podrá inferir la votación de todos los ciudadanos que cumplan los requisitos
con un error de aproximación.
En sus particularidades la Inferencia distingue la Estimación (cuando se usan las
características de la muestra para hacer inferencias sobre las características de la
población) y la Contrastación de Hipótesis (cuando se usa la información de la muestra
para responder a interrogantes sobre la población).
“Clasificación de la Estadística según el tiempo considerado”
(*) BIBLIOTECA DE INVESTIGACIONES-MÉXICO 13
Si se clasifica la Estadística en base al tiempo considerado, tenemos la Estadística
Estática (datos de la actualidad) y la Estadística Evolutiva (datos del pasado).
Dentro de la estadística descriptiva se distinguen los datos en función al tiempo en que
se encuentra analizada la población; de esta manera, tenemos 2 clasificaciones:
Estadística Estática o Estructural
La estadística estática o estructural, que describe la población en un momento dado
empleando datos de la actualidad (por ejemplo la tasa de nacimientos en determinado
censo)
Estadística Dinámica o Evolutiva
La estadística dinámica o evolutiva, que describe como va cambiando la población en
el tiempo empleando datos del pasado (por ejemplo el aumento anual en la tasa de
nacimientos).
“Clasificación de la Estadística según la cantidad de variables estudiada”
También, se puede clasificar a la Estadística en función de la cantidad de variables que
están siendo estudiadas en determinado problema estadístico. Desde este punto de vista
hay una estadística univariada (estudia una sola variable, como por ejemplo la
inteligencia, en una muestra), una estadística bivariada (estudia cómo están
relacionadas dos variables, como por ejemplo inteligencia y alimentación), y una
estadística multivariada (que estudia tres o más variables, como por ejemplo como
están relacionados el sexo, la edad y la alimentación con la inteligencia).
(*) BIBLIOTECA DE INVESTIGACIONES-MÉXICO 14
Estadística Univariada
Un ejemplo perfecto del análisis estadístico univariado, es la utilización del promedio o
media aritmética, pues sólo se mide una variable.
Cuando el análisis presenta característica por característica, aisladamente, estaremos
en presencia de un análisis estadístico univariado. Esto quiere decir, que se está
estudiando una sola variable.
El análisis univariado es el análisis básico, primario. Las características o propiedades
de las personas o cosas han de medirse una a una, de modo univariado y si se presentan
de esa manera decimos que es análisis univariado.
Los estadísticos básicos que conocemos, como la media, la mediana, la moda, la
varianza, los porcentajes, entre otros, miden una variable. Es decir, fueron hechos
univariados.
Ahora bien este tipo de análisis ha sido muy criticado ya que la realidad se presenta
interconectada, relacionada. Por ejemplo existe una relación entre el peso y la talla de las
personas o entre la el interés y el rendimiento escolar, etc.
Como la realidad se presenta relacionada necesitamos métodos más rigurosos para
evaluarla. Esto lo podemos hacer de dos modos; El primero es medir las variables de
modo univariado (analizarlas) y relacionarlas luego en la interpretación.
Estadística Bivariada
(*) BIBLIOTECA DE INVESTIGACIONES-MÉXICO 15
La Estadística bivariada, busca la relación entre 2 variables, mediante la elaboración de
índices y resultados estadísticos
La estadística univariada se aplica, por lo general, en explotaciones estadísticas básicas
de la fuente de datos (frecuencias, porcentajes, promedios, tasas…). La estadística
bivariada trata de ir más allá elaborando índices y resultados estadísticos en términos de
relaciones entre dos variables de interés, así como de establecer inferencias sobre una
población a partir de datos que provienen de una muestra (como, por ejemplo, en los
estudios mediante encuesta).
El conjunto de técnicas estadísticas bivariadas difiere en función del tipo de datos de
los que se dispone (niveles de medida: nominal, ordinal, intervalo, razón), adaptándose
en todo momento al contexto de análisis aplicado en el que nos encontremos.
Estadística Multivariada
La Estadística multivariada tiene diversas aplicaciones en una enorme cantidad de áreas,
como los son: la agricultura, el deporte, la psicología, la economía, etc.
Los métodos estadísticos multivariantes y el análisis multivariante son
herramientas estadísticas que estudian el comportamiento de tres o más variables al
mismo tiempo. Se usan principalmente para buscar las variables menos
representativas para poder eliminarlas, simplificando así modelos estadísticos en los
que el número de variables sea un problema y para comprender la relación entre varios
grupos de variables. Algunos de los métodos más conocidos y utilizados son
la Regresión lineal y el Análisis discriminante.
Se pueden sintetizar dos objetivos claros:
1. Proporcionar métodos cuya finalidad es el estudio conjunto de datos multivariantes que
el análisis estadístico uni y bidimensional es incapaz de conseguir.
2. Ayudar al analista o investigador a tomar decisiones óptimas en el contexto en el que se
encuentre teniendo en cuenta la información disponible por el conjunto de datos
analizado.
Los datos multivariados surgen cuando a un mismo individuo se le mide más de una
característica de interés. Un individuo puede ser un objeto o concepto que se puede
(*) BIBLIOTECA DE INVESTIGACIONES-MÉXICO 16
medir. Más generalmente, los individuos son llamados unidades experimentales.
Ejemplos de objetos: personas, animales, terrenos, compañías, países, etc. Ejemplos de
conceptos: amor, amistad, noviazgo, etc. Una variable es una característica o atributo que
se le mide a un individuo.
Las aplicaciones de la estadística multivariada están presentes en distintas áreas o
ramas de la ciencias, como por ejemplo en: Investigación de mercados (para identificar
características de los individuos con el propósito de determinar qué tipo de personas
compran determinado producto); en el sistema de educación de cualquier tipo de
especialidad (para conocer los estudiantes que tendrán éxito y concluirán
satisfactoriamente sus estudios); en la agricultura (al estudiar la resistencia de
determinado tipo de cosechas a daños por plagas y sequías); en el deporte (para conocer
a partir de medidas antropométricas las posibilidades de obtener buenos resultados en un
deporte específico); en la psicología (al estudiar la relación entre el comportamiento de
adolescentes y actitudes de los padres); en la economía (para conocer el nivel de
desarrollo de un territorio en relación con otros y realizar inferencias a partir de variables
económicas fundamentales, entre otros).
[6], [15], [16], [17], [18], [19], [20] y [21]
Elementos básicos de la Estadística
Concepto de Población
En estadística, población es el conjunto de datos de un problema estadístico
determinado.
Población estadística, también llamada universo o colectivo, es el conjunto de
elementos de referencia sobre el que se realizan las observaciones.
El concepto de población en estadística va más allá de lo que comúnmente se conoce
como tal. Una población se precisa como un conjunto finito o infinito de personas u
objetos que presentan características comunes. Algunas de las definiciones más
aceptadas son:
“Una población es un conjunto de todos los elementos que estamos estudiando, acerca de los
cuales intentamos sacar conclusiones”.
(*) BIBLIOTECA DE INVESTIGACIONES-MÉXICO 17
Levin & Rubin (1996).
“Una población es un conjunto de elementos que presentan una característica común”.
Cadenas (1974).
Es entonces que cuando tenemos un conjunto muy grande de datos numéricos para
analizar decimos que tenemos un Universo o Población de observaciones; tiene como
objetivo final descubrir las características y propiedades de aquello que generó los
datos. En estadística es representado con N.
Existen distintos tipos de poblaciones que son:
Población base: es el grupo de personas designadas por las siguientes
características: personales, geográficas o temporales, que son elegibles para
participar en el estudio.
Población muestreada: es la población base con criterios de viabilidad o
posibilidad de realizarse el muestreo.
Muestra estudiada: es el grupo de sujetos en el que se recogen los datos y se
realizan las observaciones, siendo realmente un subgrupo de la población
muestreada y accesible. El número de muestras que se puede obtener de una
población es una o mayor de una.
Población diana: es el grupo de personas a la que va proyectado dicho estudio,
la clasificación característica de los mismos, lo cual lo hace modelo de estudio
para el proyecto establecido.
Concepto de Muestra
Una muestra de población, en estadística, es un conjunto de datos representativos del
total de una población o universo.
Muestra de población, selección de un conjunto de individuos representativos de la
totalidad del universo objeto de estudio, reunidos como una representación válida y de
interés para la investigación de su comportamiento.
(*) BIBLIOTECA DE INVESTIGACIONES-MÉXICO 18
Los criterios que se utilizan para la selección de muestras pretenden garantizar que el
conjunto seleccionado represente con la máxima fidelidad a la totalidad de la que se ha
extraído, así como hacer posible la medición de su grado de probabilidad.
Otras definiciones altamente aceptadas, son:
“Se llama muestra a una parte de la población a estudiar qué sirve para representarla”.
Murria R. Spiegel (1991).
“Una muestra es una colección de algunos elementos de la población, pero no de todos”.
Levin & Rubin (1996).
“Una muestra debe ser definida en base de la población determinada, y las conclusiones que
se obtengan de dicha muestra solo podrán referirse a la población en referencia”
Cadenas (1974).
La muestra tiene que estar protegida contra el riesgo de resultar sesgada, manipulada u
orientada durante el proceso de selección, con la finalidad de proporcionar una base válida
a la que se pueda aplicar la teoría de la distribución estadística. A la muestra de una
población se le representa en estadística con la letra n.
Es así muestreo probabilístico, consiste en elegir una muestra de una población al
azar. Podemos distinguir varios tipos de muestreo.
Muestreo aleatorio simple:
El procedimiento empleado es el siguiente: 1) se asigna un número a cada individuo de
la población y 2) a través de algún medio mecánico (bolas dentro de una bolsa, tablas de
números aleatorios, números aleatorios generados con una calculadora u ordenador, etc.)
se eligen tantos sujetos como sea necesario para completar el tamaño de muestra
requerido.
Este procedimiento, atractivo por su simpleza, tiene poca o nula utilidad práctica cuando
la población que estamos manejando es muy grande.
Muestreo aleatorio sistemático:
Este procedimiento exige, como el anterior, numerar todos los elementos de la población,
pero en lugar de extraer n números aleatorios sólo se extrae uno. Se parte de ese número
aleatorio i, que es un número elegido al azar, y los elementos que integran la muestra son
los que ocupa los lugares i, i+k, i+2k, i+3k,…, i+(n-1) k, es decir se toman los individuos
de k en k, siendo k el resultado de dividir el tamaño de la población entre el tamaño de la
muestra: k= N/n. El número i que empleamos como punto de partida será un número al
azar entre 1 y k.
(*) BIBLIOTECA DE INVESTIGACIONES-MÉXICO 19
El riesgo este tipo de muestreo está en los casos en que se dan periodicidades en la
población ya que al elegir a los miembros de la muestra con una periodicidad constante
(k) podemos introducir una homogeneidad que no se da en la población.
Muestreo aleatorio estratificado:
Consiste en considerar categorías típicas diferentes entre sí (estratos) que poseen gran
homogeneidad respecto a alguna característica. Lo que se pretende con este tipo de
muestreo es asegurarse de que todos los estratos de interés estarán representados
adecuadamente en la muestra.
Cada estrato funciona independientemente, pudiendo aplicarse dentro de ellos el
muestreo aleatorio simple o el estratificado para elegir los elementos concretos que
formarán parte de la muestra. La distribución de la muestra en función de los diferentes
estratos se denomina afijación, y puede ser de diferentes tipos:
Afijación Simple: A cada estrato le corresponde igual número de elementos muéstrales.
Afijación Proporcional: La distribución se hace de acuerdo con el peso (tamaño) de la
población en cada estrato.
Afijación Óptima: Se tiene en cuenta la previsible dispersión de los resultados, de modo
que se considera la proporción y la desviación típica.
Muestreo aleatorio por conglomerados:
El muestreo por conglomerados consiste en seleccionar aleatoriamente un cierto número
de conglomerados (el necesario para alcanzar el tamaño muestral establecido) y en
investigar después todos los elementos pertenecientes a los conglomerados elegidos.
En el muestreo por conglomerados la unidad muestral es un grupo de elementos de la
población que forman una unidad, a la que llamamos conglomerado. Las unidades
hospitalarias, los departamentos universitarios, una caja de determinado producto, etc.,
son conglomerados naturales. En otras ocasiones se pueden utilizar conglomerados no
naturales como, por ejemplo, las urnas electorales. Cuando los conglomerados son áreas
geográficas suele hablarse de “muestreo por áreas“.
Las razones para estudiar muestras en lugar de poblaciones son diversas y entre ellas
podemos señalar:
1. Ahorrar tiempo. Estudiar a menos individuos es evidente que lleva menos tiempo.
2. Como consecuencia del punto anterior ahorraremos costes.
3. Estudiar la totalidad de los pacientes o personas con una característica
determinada en muchas ocasiones puede ser una tarea inaccesible o imposible de
realizar.
4. Aumentar la calidad del estudio. Al disponer de más tiempo y recursos, las
observaciones y mediciones realizadas a un reducido número de individuos
pueden ser más exactas y plurales que si las tuviésemos que realizar a una
población.
5. La selección de muestras específicas nos permitirá reducir la heterogeneidad de
una población al indicar los criterios de inclusión y/o exclusión.
(*) BIBLIOTECA DE INVESTIGACIONES-MÉXICO 20
Tipos y clasificación de Datos Estadísticos
Los Datos Estadísticos, son aquellos que se estudian en cada elemento de la muestra y
son variables que tomaran valores dependiendo del problema.
Los datos estadísticos son lo que estudiamos en cada individuo de la muestra son las
variables (edad, sexo, peso, talla, tensión arterial sistólica, etcétera). Los datos son los
valores que toma la variable en cada caso. Lo que vamos a realizar es medir, es decir,
asignar valores a las variables incluidas en el estudio. Deberemos además concretar la
escala de medida que aplicaremos a cada variable.
La naturaleza de las observaciones será de gran importancia a la hora de elegir el método
estadístico más apropiado para abordar su
análisis. Con este fin, clasificaremos a estos datos estadísticos, a grandes rasgos, en dos
tipos: datos cuantitativos o datos cualitativos.
Datos cuantitativos
Las Datos Cuantitativos son aquellos que se pueden expresar mediante valores
numéricos, y se dividen en continuos (enteros y decimales) y discretos (sólo enteros):
Son las variables que pueden medirse, cuantificarse o expresarse numéricamente y
pueden ser manipulados estadísticamente. Incluyen tabulaciones de frecuencia,
(*) BIBLIOTECA DE INVESTIGACIONES-MÉXICO 21
porcentajes, medias y promedios. Si entre cada dos datos puede haber una infinidad de
ellos, se llaman continuos, y si entre un dato y otro siempre hay un hueco o salto, se
llaman discretos.
Datos cuantitativos continuos: si admiten tomar cualquier valor dentro de un rango
numérico determinado, es decir, que pueden expresarse con números decimales o
fraccionarios. (Densidad de un líquido, la fuerza de un muelle, edad, peso, talla).
Datos cuantitativos discretos: si no admiten todos los valores intermedios en un
rango. Suelen tomar solamente valores enteros (Nota de un examen, número de hijos,
número de partos, número de hermanos, etc.).
Datos cualitativos.
Son datos que no se pueden expresar numéricamente, debido a que suponen cualidades,
opiniones, sentimientos entre otros, y se dividen en nominales (categorías que no
mantiene relación de orden) y los jerarquizados (escalas utilizadas bajo un orden).
Datos que expresan cualidades, como opiniones, sentimientos, observaciones y
cambios en el comportamiento que clasifica a cada caso en una de varias categorías
(Domroese & Sterling 1999). La situación más sencilla es aquella en la que se clasifica
cada caso en uno de dos grupos (hombre/mujer, enfermo/sano, fumador/no fumador).
Son datos dicotómicos o binarios. Como resulta obvio, en muchas ocasiones este tipo
de clasificación no es suficiente y se requiere de un mayor número de categorías (color
de los ojos, grupo sanguíneo, profesión, etcétera).
En el proceso de medición de estas variables, se pueden utilizar dos escalas:
Escalas nominales: ésta es una forma de observar o medir en la que los datos se
ajustan por categorías que no mantienen una relación de orden entre sí (color de los
ojos, sexo, profesión, presencia o ausencia de un factor de riesgo o enfermedad,
etcétera).
Escalas ordinales o jerarquizados: en las escalas utilizadas, existe un cierto orden o
jerarquía entre las categorías (grados de disnea, estadiaje de un tumor, etcétera).
Tipos y clasificación de Variables Estadísticas
(*) BIBLIOTECA DE INVESTIGACIONES-MÉXICO 22
Una variable estadística es cada una de las características o cualidades que poseen los
individuos de la población que estamos interesados en estudiar. Se pueden clasificar en
función a la Medición o a la influencia.
VARIABLES EN FUNCIÓN DE SU MEDICIÓN
Existen dos tipos: las variables cualitativas y las variables cuantitativas.
Variable cualitativa
Las variables cualitativas se refieren a características o cualidades que no pueden ser
medidas con números. Podemos distinguir dos tipos:
Variable cualitativa nominal: presenta modalidades no numéricas que no admiten
un criterio de orden.
Por ejemplo: El estado civil, con las siguientes modalidades: soltero, casado, separado,
divorciado y viudo.
Variable cualitativa ordinal o variable cuasicuantitativa: presenta modalidades no
numéricas, en las que existe un orden.
Por ejemplo: La nota en un examen: suspenso, aprobado, notable, sobresaliente.
Puesto conseguido en una prueba deportiva: 1º, 2º, 3º,…
Medallas de una prueba deportiva: oro, plata, bronce.
La variable que tiene resultados o valores que tienden a variar de observación en
observación debido a los factores relacionados con el azar recibe el nombre de variable
aleatoria. Las variables aleatorias pueden ser discretas y continuas.
Variable cuantitativa
Una variable cuantitativa es la que se expresa mediante un número, por tanto se
pueden realizar operaciones aritméticas con ella. Podemos distinguir dos tipos:
Variable discreta: Una variable discreta es aquella que toma valores aislados, es
decir no admite valores intermedios entre dos valores específicos. Es decir, sólo puede
ser expresado con números enteros.
Por ejemplo: El número de hermanos de 5 amigos: 2, 1, 0, 1, 3.
Variable continua: Una variable continua es aquella que puede tomar valores
comprendidos entre dos números por lo cual tiene un número infinito de valores
posibles. Es decir, puede ser expresada con números decimales o fraccionarios.
Por ejemplo: La altura de los 5 amigos: 1.73, 1.82, 1.77, 1.69, 1.75.
(*) BIBLIOTECA DE INVESTIGACIONES-MÉXICO 23
En la práctica medimos la altura con dos decimales, pero también se podría dar con tres
decimales.
VARIABLES EN FUNCIÓN DE SU INFLUENCIA
Variables independientes
Son las que el investigador escoge para establecer agrupaciones en el estudio,
clasificando intrínsecamente a los casos del mismo. Un tipo especial son las variables de
control, que modifican al resto de las variables independientes y que de no tenerse en
cuenta adecuadamente pueden alterar los resultados por medio de un sesgo.
Es aquella característica o propiedad que se supone ser la causa del fenómeno
estudiado. En investigación experimental se llama así a la variable que el investigador
manipula.
Variables dependientes
Son las variables de respuesta que se observan en el estudio y que podrían estar
influenciadas por los valores de las variables independientes. Hayman la define como
propiedad o característica que se trata de cambiar mediante la manipulación de la
variable independiente. La variable dependiente es el factor que es observado y medido
para determinar el efecto de la variable independiente.
Fuentes del subtema 1.5 [22], [23], [24], [25], [25], [27], [28], [29] y [30],
Cuadros Estadísticos
¿Qué es un cuadro o tabla estadística?
Un cuadro estadístico es una representación grafica de las diversas situaciones que se
nos presentan diariamente; sirve para presentar de forma ordenada las distribuciones
de frecuencias. Es la forma esquemática de comprender las tendencias de nuestra forma
de ser y de vivir. En un cuadro estadístico puedes identificar tantas variables como
quieras; se realiza como un resumen del conjunto de datos que se poseen, distribuidos
según las variables que se estudian.
Su forma general es la siguiente:
Modalidad Frec. Abs. Frec. Rel. Frec. Abs. Acumu. Frec. Rel. Acumu.
C ni fi Ni Fi
c1 n1 N1 = n1
… … … … …
cj nj
… … … … …
ck nk Nk = n Fk = 1
n 1
(*) BIBLIOTECA DE INVESTIGACIONES-MÉXICO 24
Es un instrumento que permite sintetizar y/o presentar la información de un hecho
investigado, y consta de cinco elementos principales:
Cabeza: parte inicial donde se registra el título.
Columna principal: Aquí anotamos las categorías ordenadas obtenidas.
Encabezado de columnas: Símbolos que explican el objeto en estudio, o las
características fundamentales que dan lugar al ingreso de la información (vaciado de
datos).
Cuerpo: Conjunto de datos estadísticos realmente observados y distribuidos de acuerdo
a las características predeterminadas.
Fuente: Referencia donde se adquiere la información.
¿Cómo construir tablas o cuadros estadísticos?
Si tenemos datos estadísticos que los podemos manejar también los podemos ordenar. Si
luego de la recopilación, obtenemos un conjunto de datos estadísticos demasiado
numeroso, poco o nada se puede hacer con ellos. Pero si los organizamos y los
clasificamos se nos va a facilitar la información incluso la interpretación.
La forma más correcta es en una tabla de distribución de frecuencias, y su elaboración no
requiere ningún artificio especial, basta con anotar los datos en fila o en columna.
Cuando elaboramos estas tablas se debe tener presente lo siguiente:
Si se trabaja con variables discretas las clases pueden ser sin agrupamiento,
siempre y cuando su recorrido sea menor a 20.
Cuando estamos encontrando estadísticas de variables continuas y por lo general
numerosa, debemos agrupar, o por lo general cuando su rango sea mayor a 20.
Por consiguiente podemos obtener 3 tipos de series:
1. Serie simple o tipo I, también llamada ordinaria (cuando las estadísticas representan
un rango menor a 10.
2. Serie de frecuencia, o tipo II (cuando las estadísticas observadas se repiten y su rango
está entre mayor a 10 y menor que 20).
3. Serie de intervalos de clase o tipo III, o de datos agrupados (cuando los datos
observados son numerosos o su rango es mayor que 20).
“Tipos de Tablas o Cuadros Estadísticos”
(*) BIBLIOTECA DE INVESTIGACIONES-MÉXICO 25
Las tablas o cuadros estadísticos no tienen modelo único, están sujetos a las exigencias
de la información y del investigador (revise, estudie y analice los cuadros de la
guía didáctica y texto básico.
Las tablas estadísticas según el número de observaciones y según el recorrido de la
variable estadística, así tenemos los siguientes tipos de tablas estadísticas:
1. Tablas Tipo I
2. Tablas Tipo II
3. Tablas Tipo III
Tablas tipo I: Cuadro Simple
Cuando el tamaño de la muestra y el recorrido de la variable son pequeños, por ejemplo
si tenemos una muestra de las edades de 5 personas, por lo que no hay que hacer nada
especial simplemente anotarlas de manera ordenada en filas o columnas.
Edad de los 5 miembros de una familia:
5 11 22 40 65 80
Tablas tipo II: Cuadro de Frecuencias
Cuando el tamaño de la muestra es grande y el recorrido de la variable es pequeño, por lo
que hay valores de la variable que se repiten. Por ejemplo, si preguntamos el número de
personas activas que hay en 50 familias obtenemos la siguiente tabla:
Personas Activas en 50 familias
2122124211
2321113422
2212111322
3231242141
1343222133
Podemos observar que la variable toma valores comprendidos entre 1 y 4, por lo que
precisaremos una tabla en la que resumamos estos datos quedando la siguiente tabla:
Personas Activas Número de Familias
1 16
2 20
3 9
4 5
Total 50
Tablas tipo III: Cuadro de Intervalos
Cuando el tamaño de la muestra y el recorrido de la variable son grandes, por lo que será
necesario agrupar en intervalos los valores de la variable. Por ejemplo, si a un grupo de
(*) BIBLIOTECA DE INVESTIGACIONES-MÉXICO 26
30 alumnos les preguntamos el dinero que en ese momento llevan encima, nos
encontramos con los siguientes datos:
450 1152 250 300 175 80 25 2680
5 180 200 675 500 375 1500 205
605 785 1595 2300 5000 1200 100 985
185 125 315 425 560 1100
Evidentemente, la variable estadística tiene un recorrido muy grande, 4998 pesetas, por
lo que sí queremos hacer una tabla con estos datos tendremos que tomar intervalos. Para
decidir la amplitud de los intervalos, necesitaremos decidir ¿cuántos intervalos
queremos?
Normalmente se suele trabajar con no más de 10 o 12 intervalos.
Amplitud =4998/10 = 499,8 Por lo que tomaremos intervalos de amplitud 500
Debemos tener en cuenta las siguientes consideraciones:
Tomar pocos intervalos implica que la “pérdida de información” sea mayor.
Los intervalos serán siempre Cerrados por la izquierda y Abiertos por la Derecha
[ Li-1 , Li )
Procuraremos que en la decisión de intervalos los valores observados no coincidan
con los valores de los extremos del intervalo y si esto ocurre que no sea en más
de un 5% del total de observaciones.
Con estas recomendaciones tendremos la siguiente tabla:
[ Li-1 , Li ) Frecuencia
[ 0,500) 16
[ 500, 1000) 6
[ 1000,1500) 3
[ 1500, 2000) 2
[ 2000, 2500) 1
[ 2500, 3000) 1
[ 3000, 3500) 0
[ 3500, 4000) 0
[ 4000, 4500) 0
[ 4500, 5000) 0
[ 5000,5500) 1
Fuentes del subtema 1.8 [31], [32], y [33]
Representación Gráfica de los Datos de una Tabla de Distribución de
Frecuencias
“¿Qué son las Gráficas Estadísticas?”
(*) BIBLIOTECA DE INVESTIGACIONES-MÉXICO 27
La Representación Gráfica de un conjunto de datos recopilados, es una manera rápida y
eficiente de presentar estadísticamente la información.
Cuando se hace un estudio estadístico se obtiene una gran cantidad de datos numéricos.
Para tener una información clara y rápida de lo obtenido en el estudio se han creado
las gráficas estadísticas.
Gran parte de la utilidad que tiene la Estadística Descriptiva es la de proporcionar un
medio para informar basado en los datos recopilados. La eficacia con que se pueda
realizar tal proceso de información dependerá de la presentación de los datos, siendo la
forma gráfica uno de los más rápidos y eficientes, aunque también uno de los que más
pueden ser manipulados o ser malinterpretados si no se tienen algunas precauciones
básicas al realizar las gráficas.
Existen también varios tipos de gráficas, o representaciones gráficas, utilizándose
cada uno de ellos de acuerdo al tipo de información que se está usando y los objetivos
que se persiguen al presentar la información.
Entonces, algunas consideraciones que conviene tomar en cuenta al momento de
realizar cualquier gráfica a fin de que la información sea transmitida de la manera más
eficaz posible y sin distorsiones son:
1. El eje que represente a las frecuencias de las observaciones (comúnmente el
vertical o de las ordenadas) debe comenzar en cero (0), de otra manera podría dar
impresiones erróneas al comparar la altura, longitud o posición de las columnas,
barras o líneas que representan las frecuencias.
2. La longitud de los espacios que representan a cada dato o intervalo (clase) en la
gráfica deben ser iguales.
3. El tipo de gráfico debe coincidir por sus características con el tipo de información
o el objetivo que se persigue al representarla, de otra manera la representación
gráfica se convierte en un instrumento ineficaz, que produce más confusión que
otra cosa, innecesario o productor de malinterpretaciones.
(*) BIBLIOTECA DE INVESTIGACIONES-MÉXICO 28
Existen decenas de tipos de gráficas, a continuación te presento los más usuales e
importantes.
Por ejemplo, si se desea representar la proporción de población masculina en un país
conviene más usar una gráfica de pastel o circular que una gráfica de barras al compararla
contra la población femenina; por un lado se puede apreciar dicha proporción, por el otro
se aprecia cuál de las dos poblaciones es mayor.
Hay un punto que conviene remarcar: existe software que permite la construcción rápida
y eficiente de gráficas a partir de bases de datos o hojas de cálculos, pero no importa cuán
bonita, bien delineada, bien coloreada o bien presentada esté una gráfica, si no se han
tomado en cuenta consideraciones de este tipo que tienen que ver más sobre el objetivo
de estas herramientas y la Estadística: la transmisión eficiente de la información.
Hay muchos tipos de gráficas estadísticas. Cada una de ellas es adecuada para un estudio
determinado, ya que no siempre se puede utilizar la misma para todos los casos. Tienen
una estructura distinta, lo cual les permite ser utilizados para diferentes objetivos, y es
que la mayoría de las veces utilizan datos o variables distintos.
A continuación, se presentarán las gráficas estadísticas más utilizadas:
Histograma
Histograma de Frecuencias
(*) BIBLIOTECA DE INVESTIGACIONES-MÉXICO 29
Un histograma es una representación gráfica de una variable en forma de barras.
Se utilizan para variables continuas o para variables discretas, con un gran número de
datos, y que se han agrupado en clases.
En el eje abscisas se construyen unos rectángulos que tienen por base la amplitud del
intervalo, y por altura, la frecuencia absoluta de cada intervalo. La superficie de
cada barra es proporcional a la frecuencia de los valores representados.
Un ejemplo es el que se presenta abajo y que representa el número de “visitas” que ha
tenido este hipertexto de acuerdo a la hora de la visita. Es importante observar que resulta
difícil utilizar este tipo de representación cuando existen intervalos abiertos o cuando los
intervalos no son iguales entre sí.
Otra observación es la amplitud de los intervalos, que se puede establecer utilizando
la regla de Sturges, pues al cambiarla la presentación visual de un histograma puede
variar. Un applet que muestra cómo el número de clases y su ancho pueden hacer variar
fue desarrollado por Webster West de la Universidad del Sur de Carolina.
Algunos de los usos más comunes del uso de un histograma son: aumentar la calidad de
alguno de nuestros procesos, pues todos sabemos que es necesario reducir al mínimo la
variación que se presente en el mismo. Es por eso, que el histograma nos permite
identificar cuantas veces se repite un mismo valor, así como la frecuencia con la que
se presenta. Siendo base para la toma de decisiones.
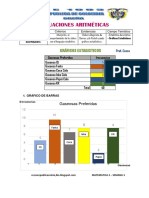
Diagrama de Barras
Diagrama o gráfica de barras
Un tipo de gráfico muy parecido al histograma es la gráfica de columnas.
En este tipo de gráfica, sobre los valores de las variables se levantan barras estrechas
de longitudes proporcionales a las frecuencias correspondientes. Se utilizan para
representar variables cualitativas y cuantitativas discretas.
Para este tipo de gráfica, elaboradas con rectángulos también, se pide que sus bases sean
del mismo ancho y sus alturas equivalentes con las frecuencias. A diferencia
(*) BIBLIOTECA DE INVESTIGACIONES-MÉXICO 30
del histograma, no es necesario tener una escala horizontal continua, por lo que los
rectángulos (o barras) no tienen que aparecer juntas entre sí. Otra observación pertinente
es que se pueden representar en la misma gráfica, utilizando las mismas escalas
horizontales y verticales, varios datos correspondientes a las mismas variables producto
de varias observaciones. Esto produce una gráfica con varias series, correspondiendo
cada una de ellas a cada observación de la muestra (o población), y teniéndose una
gráfica compuesta. Es conveniente que cada serie de datos (u observaciones) sean
ilustrados o iluminados de igual manera entre sí, pero distinta de las demás.
En el eje horizontal, o eje de abscisas, se representan los datos o modalidades; en el eje
vertical o de ordenadas, se representan las frecuencias de cada dato o modalidad. Las
frecuencias pueden ser absolutas, acumuladas relativas y relativas acumuladas.
El ejemplo de la ilustración de arriba pertenece al comportamiento de las calificaciones
parciales de tres alumnos de preparatoria. Las series (cada una de las calificaciones
parciales) están coloreadas con diferente color para mostrar el comportamiento tanto
individual, como comparativo.
TIPOS DE GRÁFICOS DE BARRAS
Gráfica de barras compuestas
Barra simple: se emplean para graficar hechos únicos.
Barras múltiples: es muy recomendable para comparar una serie estadística con otra,
para ello emplea barras simples de distinto color o tramado en un mismo plano
cartesiano, una al lado de la otra.
Barras compuestas: en este método de graficación las barras de la segunda serie se
colocan encima de las barras de la primera serie en forma respectiva.
El diagrama de barras proporciona información comparativa principalmente y este es su
uso fundamental.
Gráficas de Barras Horizontales
También es posible realizar gráficas de barras horizontales, los cuales se parecen
mucho a las gráficas de columnas, con la salvedad importante de que la función de los
ejes se intercambia y el eje horizontal queda destinado a las frecuencias y el eje vertical
a las clases.
(*) BIBLIOTECA DE INVESTIGACIONES-MÉXICO 31
Es muy común que este tipo de gráficos se utilicen para ilustrar el tamaño de una
población dividida en estratos como, por ejemplo, son sus edades.
El ejemplo que se presenta es la población de un país ficticio llamado “Timbuctulandia”:
A este tipo de gráficos en particular se le llama pirámide de edades por su forma.
Incluso, cuando se compara la población masculina y femenina por estratos de edades, se
estila utiliza el lado izquierdo para la población de un sexo y el lado derecho para el otro,
el resultado es una “pirámide” casi simétrica (dependerá de la población en particular).
Pirámides de población.
La pirámide de población es la representación gráfica de la distribución por edad y sexo
de la población. Gráficamente se trata de un doble histograma de frecuencias.
La pirámide de edades es un histograma doble en el que se representa en la derecha la
población masculina y en la izquierda la población femenina. En el eje de abscisas se
representa los efectivos de población, normalmente en porcentajes, y en el eje de
ordenadas las edades. Toma el nombre de la forma que debe adoptar en las sociedades
con una población equilibrada, con una amplia base debido al gran número de
nacimientos que se estrecha paulatinamente por la mortalidad creciente a medida que
aumenta el intervalo de edades considerado.
La pirámide de población, dependiendo de su forma, puede dar una visión general de la
juventud, madurez o vejez de una población, y por lo tanto obtener consecuencias sociales
de ello.
Según su perfil podemos distinguir tres tipos básicos de pirámides:
De población expansiva: con una base ancha y una rápida reducción a medida que
ascendemos. Es propia de los países del Tercer Mundo en plena transición demográfica
con altas tasas de natalidad y mortalidad, y con un crecimiento natural alto.
De población regresiva: con una base más estrecha que el cuerpo central y un
porcentaje de ancianos relativamente grande. Se trata de una población envejecida con
bajas tasas de natalidad y de mortalidad, y con un crecimiento natural reducido.
De población estacionaria: con una notable igualdad entre las generaciones jóvenes y
adultas, y una reducción importante en las ancianas. El crecimiento natural es bajo. Este
tipo de pirámide es propia de las poblaciones que no presentan cohortes de la transición
demográfica.
Gráficas de Líneas
Cuando los datos se relacionan entre sí, es decir, cuando podemos decir que existe cierta
continuidad entre las observaciones se pueden utilizar las gráficas de líneas, que
consisten en una serie de puntos trazados en las intersecciones de las marcas de clase y
las frecuencias de cada una, uniéndose consecutivamente con líneas.
(*) BIBLIOTECA DE INVESTIGACIONES-MÉXICO 32
Este ejemplo muestra el comportamiento del peso corporal (en kilogramos) de dos
individuos a lo largo de cinco observaciones anuales. Al igual que en el caso de
las gráficas de columnas (y de otras más) es posible presentar varias series de
observaciones (en este caso cada serie de observaciones son los pesos de un individuo).
Polígono de Frecuencias
Otra forma de representación de un uso menos común, y muy parecida a las gráficas de
líneas, es el polígono de frecuencias.
Éste, es un gráfico que se realiza a través de la unión de los puntos más altos de las
columnas en un histograma de frecuencia (que utiliza columnas verticales para mostrar
las frecuencias). La diferencia fundamental entre ambas es que en el polígono de
frecuencias se añaden dos clases con frecuencias cero: una antes de la primera clase
con datos y otra después de la última.
El resultado es que se “sujeta” la línea por ambos extremos al eje horizontal y lo que
podría ser una línea separada del eje se convierte, junto con éste, en un
polígono. Los polígonos de frecuencia para datos agrupados, por su parte, se
construyen a partir de la marca de clase que coincide con el punto medio de cada
columna del histograma.
Cuando se representan las frecuencias acumuladas de una tabla de datos agrupados, se
obtiene un histograma de frecuencias acumuladas, que permite diagramar su
correspondiente polígono.
Se suelen utilizar cuando se desea mostrar más de una distribución o la clasificación
cruzada de una variable cuantitativa continua con una cualitativa o cuantitativa
discreta en un mismo gráfico.
El punto con mayor altura de un polígono de frecuencia representa la mayor frecuencia,
mientras que el área bajo la curva incluye la totalidad de los datos existentes.
El ejemplo de arriba corresponde al porcentaje del PIB gastado en docencia e
investigación durante el año de 1990 en cinco países (fuente: Revista “Ciencia y
Desarrollo”, 1994, XIX (114):12))
Cabe recordar que la frecuencia es la repetición menor o mayor de un suceso, o
la cantidad de veces que un proceso periódico se repite por unidad de tiempo.
Pictograma
Son gráficos con dibujos alusivos al carácter que se está estudiando y cuyo tamaño es
proporcional a las frecuencias que representan.La mayor frecuencia se identifica por la
mayor acumulación de símbolos. Los pictogramas se emplean sobre todo, para hacer más
amigables y entendibles los informes estadísticos. Se utilizan en estadística, en muchas
ocasiones como parte de una tabla.
(*) BIBLIOTECA DE INVESTIGACIONES-MÉXICO 33
Por ejemplo, si se quiere representar la producción de troncos de un aserradero, se utilizan
el dibujo de un tronco ancho para señalar mil troncos y un tronco pequeño para representar
500 troncos.
Diagrama de Sectores
También conocido como gráfica de pastel o gráfico circular. Un diagrama de
sectores se puede utilizar para todo tipo de variables, pero se usa frecuentemente para
las variables cualitativas.
Si el estudio estadístico tiene pocos valores distintos, suele ocurrir con los caracteres
cualitativos, se puede usar un diagrama en forma de círculo dividido en tantos sectores
como datos distintos haya, de modo que la frecuencia de cada valor viene dada por un
trozo de área del círculo. Así, el círculo queda dividido en sectores cuya amplitud es
proporcional a las frecuencias de los valores.
Para obtener esta característica fundamental del diagrama de sectores, en que el ángulo de
cada sector es proporcional a la frecuencia absoluta correspondiente, tenemos que el
ángulo se calcula de la siguiente forma:
El diagrama circular se construye con la ayuda de un transportador de ángulos.
También puede usarse para datos cuantitativos agrupados en clases, y en tales casos, cada
sector corresponde a una clase. Dada la índole de esta representación, sólo se utiliza para
distribuciones de frecuencias relativas usualmente expresadas en porcentajes.
¿Para qué sirve?
Expresa de manera gráfica la distribución proporcional de los eventos o datos en
estudio; sin embargo, éstos no deben ser más de 7 porque el análisis se vuelve
excesivamente complejo. Cuando lo que se desea es resaltar las proporciones que
representan algunos subconjuntos con respecto al total, es decir, cuando se está usando
una escala categórica, conviene utilizarla.
Los datos presentados comienzan a las 12 horas en el círculo y corren en el sentido de
las manecillas del reloj; colocando el porcentaje mayor (la rebanada más amplia del
pastel) junto con la siguiente más importante; y así sucesivamente, hasta la más
pequeña. Apéguese a esta convención a menos que quiera ilustrar contrastes dramáticos
en los porcentajes, colocando los porcentajes mayores junto con los más pequeños.
Los textos necesarios pueden situarse dentro del pastel o fuera de éste (preferiblemente
fuera cuando las secciones representen valores pequeños) y el color debe usarse para dar
énfasis y estética. Su principal inconveniente consiste en que requieren de mucho espacio
en cada página.
Ejemplo
Deporte Alumnos (fi) Ángulo (α)
(*) BIBLIOTECA DE INVESTIGACIONES-MÉXICO 34
Baloncesto 12 144° En una clase de 30 alumnos, 12 juegan
a baloncesto, 3 practican la natación, 4
Natación 3 36° juegan al fútbol y el resto no practica
ningún deporte.
Fútbol 9 108°
Sin deporte Diagrama de Dispersión
6 72°
Total 30 (N) En
360° las distribuciones
bidimensionales a cada individuo le
corresponden los valores de dos variables, las representamos por el par (xi, yi). Si
representamos cada par de valores como las coordenadas de un punto, el conjunto de
todos ellos se llama nube de puntos o diagrama de dispersión. Sobre la nube de puntos
puede trazarse una recta que se ajuste a ellos lo mejor posible, llamada recta de
regresión.
Un gráfico de dispersión tiene dos ejes de valores y muestra un conjunto de datos
numéricos en el eje horizontal (eje X) y otro en el eje vertical (eje Y). Combina estos
valores en puntos de datos únicos y los muestra en intervalos irregulares o
agrupaciones. Los gráficos de dispersión se utilizan por lo general para mostrar y
comparar valores numéricos, por ejemplo datos científicos, estadísticos y de ingeniería.
Se usa cuando:
Desea convertir dicho eje en una escala logarítmica.
Los espacios entre los valores del eje horizontal no son uniformes.
Hay muchos puntos de datos en el eje horizontal.
Desea mostrar similitudes entre grandes conjuntos de datos.
Desea comparar muchos puntos de datos sin tener en cuenta el tiempo.
CLASIFICACIÓN SEGÚN TIPO DE CORRELACIÓN
1. Correlación directa: La recta correspondiente a la nube de puntos de la distribución es
una recta creciente.
2. Correlación inversa: La recta correspondiente a la nube de puntos de la distribución es
una recta decreciente.
3. Correlación nula: En este caso se dice que las variables son incorreladas y la nube de
puntos tiene una forma redondeada.
CLASIFICACIÓN SEGÚN GRADO DE CORRELACIÓN
El grado de correlación indica la proximidad que hay entre los puntos de la nube de
puntos. Se pueden dar tres tipos:
1. Correlación fuerte: La correlación será fuerte cuanto más cerca estén los puntos de la
recta.
2. Correlación débil: La correlación será débil cuanto más separados estén los puntos de
la recta.
3. Correlación nula: No existe el más mínimo grado de correlación entre los puntos.
(*) BIBLIOTECA DE INVESTIGACIONES-MÉXICO 35
Gráficas de área
Los gráficos de área destacan la magnitud del cambio en el tiempo y se pueden utilizar
para llamar la atención hacia el valor total en una tendencia. Por ejemplo, se pueden trazar
los datos que representan el beneficio en el tiempo en un gráfico de área para destacar el
beneficio total. Al mostrar la suma de los valores trazados, un gráfico de área también
muestra la relación de las partes con un todo.
Los gráficos de área tienen los siguientes subtipos de gráfico:
Áreas en 2D y 3D Tanto si se presentan en 2D como en 3D, los gráficos de áreas
muestran la tendencia de los valores en el tiempo u otros datos de categoría. Como
norma, considere la posibilidad de utilizar un gráfico de líneas en lugar de un gráfico de
áreas no apilado, ya que los datos de una serie pueden quedar ocultos por los de otra.
Áreas apiladas y áreas 100% apiladas: Los gráficos de áreas apiladas muestran la
tendencia de la contribución de cada valor a lo largo del tiempo u otros datos de
categoría. Las gráficas se pueden proyectar en perspectiva 3D.
Otros gráficos
Existen muchos otros gráficos, que en este trabajo no abordaremos de manera profunda
debido a que son poco comunes; principalmente, se trata de gráficas estadísticas utilizadas
en ciencias o actividades muy específicas y muchas veces se requiere de un conocimiento
avanzado para su realización. Como ejemplo, vale la pena mencionar:
Gráficos de superficie
Un gráfico de superficie es útil cuando busca combinaciones óptimas entre dos conjuntos
de datos. Como en un mapa topográfico, los colores y las tramas indican áreas que están
en el mismo rango de valores.
Puede utilizar un gráfico de superficie cuando ambas categorías y series de datos sean
valores numéricos.
Gráficos de anillos
En un gráfico de anillos se pueden representar datos organizados únicamente en columnas
o en filas de una tabla de datos estadísticos. Un gráfico de anillos muestra la relación de
las partes con un todo pero puede contener más de una serie de datos; no son fáciles de
leer. Es conveniente utilizar un gráfico de columnas apiladas o un gráfico de barras
apiladas en su lugar.
Gráficas Radiales
Los datos organizados en columnas o filas en una hoja de cálculo se pueden representar
en un gráfico radial. Los gráficos radiales comparan los valores agregados de varias series
de datos y muestran cambios en valores relativos a un punto central.
(*) BIBLIOTECA DE INVESTIGACIONES-MÉXICO 36
Fuentes del subtema 1.9 [34 – 50]
Glosario
Al Azar o Aleatorio: Son todos aquellos eventos fortuitos o productos de la suerte.
Aleatoriamente: Actividades o métodos producidos o llevados a cabo simulando un
comportamiento al azar.
Clase: Subdivisión de escala de datos.
Correlación: Cuando dos fenómenos sociales, físicos o biológicos crecen o decrecen de
forma simultánea y proporcional debido a factores externos, se dice que los fenómenos
están positivamente correlacionados. Si uno crece en la misma proporción que el otro
decrece, los dos fenómenos están negativamente correlacionados. El grado de
correlación se calcula aplicando un coeficiente de correlación a los datos de ambos
fenómenos.
Datos: Son los valores cualitativos o cuantitativos mediante los cuales se miden las
características de los objetos, o fenómenos a estudiar.
Dispersión: La extensión o variabilidad de un conjunto de datos.
Estadística: Rama de las matemáticas que se ocupa de reunir, organizar y analizar datos
numéricos y que ayuda a resolver problemas como el diseño de experimentos y la toma
de decisiones.
Evento: Uno o más de los resultados posibles de hacer algo, o uno de los resultados
posibles de realizar un experimento
Frecuencia: Número de veces en que se repite un dato.
Frecuencia Acumulada: Es el número de estudiantes con calificaciones iguales o
menores que el rango de cada intervalo sucesivo.
Frecuencia absoluta: Es el número de veces que ocurre un cierto suceso, en la
proporción de veces que ocurre dicho suceso con relación al número de veces que
podría haber ocurrido.
Frecuencia Relativa: Es la proporción entre la frecuencia de un intervalo y el número
total de datos.
Intervalo de Clase: Pequeña sección de la escala según la cual se agrupan las
puntuaciones de una distribución de frecuencia. Tamaño o rango de la Clase.
Límites del Intervalo: Son los valores extremos que tiene el intervalo de clase, inferior
y superior, entre los cuales van a estar los valores de los datos agrupados en
ese intervalo de clase.
(*) BIBLIOTECA DE INVESTIGACIONES-MÉXICO 37
Muestra estadística: es un subconjunto de casos o individuos de una población
estadística.
Muestreo aleatorio simple: Métodos de selección de muestras que permiten a cada
muestra posible una probabilidad igual de ser elegida y a cada elemento de la población
una oportunidad igual de ser incluidos en la muestra.
Muestreo aleatorio: Las técnicas de muestreo aleatorio aseguran que cada elemento
en la población de interés tenga una probabilidad (no nula) de ser incluido en la
muestra.
Porcentaje: Es la proporción de una cantidad de datos específicos, con respecto al total
de esos datos.
Población estadística: también llamada universo o colectivo, es el conjunto de
elementos de referencia sobre el que se realizan las observaciones.
Rango: Situación de un dato respecto de una distribución.
Regresión: Proceso general que consiste en predecir una variable a partir de otra
mediante medios estadísticos, utilizando datos anteriores.
Tablas de Frecuencias: Tabla que muestra el número de veces que en un conjunto de
datos aparece cada una de las clases de interés especificadas en el recorrido de los datos
Tamaño de la Muestra: Es la cantidad de datos que serán extraídos de
la población para formar parte de la muestra.
Variable: Propiedad o rasgo de un hecho u objeto (no constante) por la que puede ser
caracterizado o clasificado. Representación de una característica, de un tributo, que
posee alguna realidad.
Variable dependiente: La variable que tratamos de predecir en el análisis de regresión.
Variables independientes: Variables (s) conocida(s) en el análisis de regresión.
Varianza: Desviación cuadrada media de todos los valores de la media.
Fuentes del Glosario [51] y [52]
Fuentes de Información
[1] http://www.gestiopolis.com/recursos/experto/catsexp/pagans/eco/21/estadistica.ht
m
[2] http://www.eumed.net/cursecon/libreria/drm/ped-drm-est.htm
[3] http://www.eumed.net/cursecon/libreria/drm/1a.htm
(*) BIBLIOTECA DE INVESTIGACIONES-MÉXICO 38
[4] http://es.wikipedia.org/wiki/Estadística#Origen
[5] http://www.galeon.com/estadisticautil/quees.htm
[6] “Estadística.” Microsoft® Encarta® 2009 [DVD]. Microsoft Corporation, 2008.
[7] http://www.uv.mx/cienciahombre/revistae/vol18num2/articulos/historia/index.ht
m
[8] http://www.monografias.com/trabajos10/esta/esta.shtml#apli
[9] http://web.cortland.edu/flteach/stats/stat-sp.html
[10] http://html.rincondelvago.com/estadistica_38.html
[11] http://www.monografias.com/trabajos27/muestreo-estadistico/muestreo-
estadistico.shtml
[12] http://www.vitutor.com/estadistica/descriptiva/a_1.html
[13] http://www.hrc.es/bioest/estadis_1.html
[14] http://www.eumed.net/cursecon/libreria/drm/0.htm
[15] http://www.monografias.com/trabajos19/la-estadistica/la-estadistica.shtml
[16] http://estadisticadescriptiva1.blogspot.com/2009/09/division-de-la-
estadistica.html
[17] http://sitios.ingenieria-
usac.edu.gt/estadistica/estadistica2/estadisticadescriptiva.html
[18] http://www.estadisticaparatodos.com/index_archivos/page0003.htm
[19] http://www.noparametricas.com/archivos/servicios/analisise.html
[20] http://es.wikipedia.org/wiki/Estadística_multivariante
[21] http://www.gestiopolis.com/canales7/fin/matematicas-aplicacion-de-estadisticas-
multivariables-e-indicadores-financieros.htm
[22] http://www.mitecnologico.com/Main/PoblacionEnEstadistica
[23] http://es.wikipedia.org/wiki/Población_estadística
[24] http://www.vitutor.com/estadistica/inferencia/inferenciaContenidos.html
[25] “Muestra de población.” Microsoft® Encarta® 2009 [DVD]. Microsoft
Corporation, 2008.
(*) BIBLIOTECA DE INVESTIGACIONES-MÉXICO 39
[26] http://html.rincondelvago.com/conceptos-y-muestreo.html
[27] http://www.fisterra.com/mbe/investiga/10descriptiva/10descriptiva.asp
[28] http://www.vitutor.com/estadistica/descriptiva/a_2.html
[29] http://recursostic.educacion.es/descartes/web/materiales_didacticos/iniciacion_est
adististica_fjgarcia/01VariablesEstadisticas.htm
[30] http://es.wikipedia.org/wiki/Variable_estadística
[31] http://www.monografias.com/trabajos73/estadistica-descriptiva/estadistica-
descriptiva2.shtml
[32] http://www.bioestadistica.uma.es/libro/node7.htm
[33] http://thales.cica.es/rd/Recursos/rd97/UnidadesDidacticas/53-1-u-
punt12.html#seccion2
[34] http://www.ceibal.edu.uy/contenidos/areas_conocimiento/mat/estadistica/grficas_
estadsticas.html
[35] http://www.uaq.mx/matematicas/estadisticas/xu3.html
[36] http://www.vitutor.net/2/11/graficas_estadistica.html
[37] http://www.vitutor.com/estadistica/descriptiva/a_6.html
[38] “Gráficas estadísticas.” Microsoft® Encarta® 2009 [DVD]. Microsoft
Corporation, 2008.
[39] http://mx.kalipedia.com/glosario/diagrama-barras.html?x=1487
[40] http://www.monografias.com/trabajos11/estadi/estadi.shtml
[41] http://definicion.de/poligono-de-frecuencia/
[42] http://www.vitutor.com/estadistica/descriptiva/a_5.html
[43] http://www.ceibal.edu.uy/contenidos/areas_conocimiento/mat/estadistica/diagra
ma_de_sectores.html
[44] http://www.ematematicas.net/estadistica/graficas/index.php?tipo=sectores
[45] http://dieumsnh.qfb.umich.mx/estadistica/graficas.htm
[46] http://www.ematematicas.net/estadistica/graficas/index.php?tipo=picto
[47] http://www.conevyt.org.mx/cursos/enciclope/prob_inf_graf.html#pictograma
(*) BIBLIOTECA DE INVESTIGACIONES-MÉXICO 40
[48] http://www.dgplades.salud.gob.mx/descargas/dhg/GRAFICA_PASTEL.pdf
[49] http://office.microsoft.com/es-es/excel-help/tipos-de-graficos-disponibles-
HA001233737.aspx#BMareacharts
[50] http://enciclopedia.us.es/index.php/Pir%C3%A1mide_de_poblaci%C3%B3n
[51] http://web.cortland.edu/flteach/stats/glos-sp.html
[52] http://es.scribd.com/doc/8050872/GLOSARIO-ESTADISTICO
(*) BIBLIOTECA DE INVESTIGACIONES-MÉXICO 41
Вам также может понравиться
- E.A 5 MAT 2º SecДокумент5 страницE.A 5 MAT 2º SecJavier A Piscoya Sánchez100% (1)
- Problemario de ProgramacionfinalДокумент19 страницProblemario de Programacionfinalwilmer javid davila rodriguezОценок пока нет
- Escuela ContableДокумент20 страницEscuela ContableJoseph BazánОценок пока нет
- Serie Numismatica Fauna Silvestre Amenazada Del PeruДокумент1 страницаSerie Numismatica Fauna Silvestre Amenazada Del PeruELVIS TRUJILLO BENIGNOОценок пока нет
- Taller No. 3Документ2 страницыTaller No. 3marcelangel100% (2)
- Guía 7 - Números RacionalesДокумент7 страницGuía 7 - Números RacionalesAnonymous 7za15o00% (1)
- 4to de Secundaria-Exp 1 - 4Документ19 страниц4to de Secundaria-Exp 1 - 4papel piedraОценок пока нет
- Mate 4º Sesión 3-Unidad3 - Trim3Документ5 страницMate 4º Sesión 3-Unidad3 - Trim3Luis ZarzosaОценок пока нет
- Visita Al MuseoДокумент15 страницVisita Al MuseoJESSENIA100% (1)
- Trabajo Final MAT210Документ16 страницTrabajo Final MAT210Noemy100% (1)
- Semana 22 - Actividad BДокумент6 страницSemana 22 - Actividad BLesly Sánchez0% (1)
- Cantalloc y Los Acueductos Mas Antiguos de La Cultura NazcaДокумент3 страницыCantalloc y Los Acueductos Mas Antiguos de La Cultura NazcaAlberto Cerna100% (1)
- Medidas de Tendencia Central para Datos AgrupadosДокумент4 страницыMedidas de Tendencia Central para Datos AgrupadosJoel Acosta santamariaОценок пока нет
- U1. Comprensión LectoraДокумент2 страницыU1. Comprensión LectoraCristian W. NegrónОценок пока нет
- Taller Numero 2 de Estadística y ProbabilidadДокумент33 страницыTaller Numero 2 de Estadística y ProbabilidadGermán A Fernández PérezОценок пока нет
- Ficha de TrabajoДокумент3 страницыFicha de TrabajoCarla ChupillónОценок пока нет
- RP - MAT4-K06 - FichaДокумент11 страницRP - MAT4-K06 - FichaLucho H. G.43% (7)
- Tomo 6.1Документ53 страницыTomo 6.1Juan Alberto Alvarez GarciaОценок пока нет
- Ecuaciones Parte 2Документ17 страницEcuaciones Parte 2nelson vargasОценок пока нет
- Triang UlosДокумент1 страницаTriang Uloselasso50% (1)
- N° 18 - Elena La CiclistaДокумент7 страницN° 18 - Elena La CiclistaconsueloОценок пока нет
- Ficha de Inecuaciones CensalДокумент9 страницFicha de Inecuaciones CensalMichell Sanchez ArbañilОценок пока нет
- Estadística Investigacion de ConceptosДокумент8 страницEstadística Investigacion de ConceptosMaria LuciaОценок пока нет
- Módulo CepreДокумент384 страницыMódulo CepreJulio César Díaz CastroОценок пока нет
- Importaciones y Exportaciones de La Región LoretoДокумент24 страницыImportaciones y Exportaciones de La Región LoretoPriscilla Querebalú Supo0% (1)
- Métodos Cuantitativos para Los NegociosДокумент1 страницаMétodos Cuantitativos para Los NegociosADRIAN SAÚL HUAMANI EGUSQUIZAОценок пока нет
- PUB Pomacanchi PDFДокумент94 страницыPUB Pomacanchi PDFManuel AltamiranoОценок пока нет
- Matematic2 Sem3 Experiencia1 Actividad6 Elaboramos Graficos EG23 Ccesa007Документ5 страницMatematic2 Sem3 Experiencia1 Actividad6 Elaboramos Graficos EG23 Ccesa007Demetrio Ccesa RaymeОценок пока нет
- Guia 5 de Calculo PDFДокумент3 страницыGuia 5 de Calculo PDFMauro Sebastian Zambrano AlemanОценок пока нет
- Mat2 U6 Sesion 05Документ5 страницMat2 U6 Sesion 05Rey Farfan Esteves100% (1)
- Dokumen - Tips - Solucionario Manuel Cordova Zamora Ejercicios de ProbabilidadДокумент90 страницDokumen - Tips - Solucionario Manuel Cordova Zamora Ejercicios de ProbabilidadCamila VilelaОценок пока нет
- Informe Prueba de HipotesisДокумент5 страницInforme Prueba de HipotesisMARIA ALEJANDRA DUARTE DIAZОценок пока нет
- Sistema de Los Números NaturalesДокумент12 страницSistema de Los Números NaturalesUber Antonio Tito FloresОценок пока нет
- Practica 2 - Grupo 1Документ18 страницPractica 2 - Grupo 1James Gabriel AntonioОценок пока нет
- Taller Icfes Pensamiento CriticoДокумент7 страницTaller Icfes Pensamiento CriticoJaime RuizОценок пока нет
- Estadistica EjerciciosДокумент26 страницEstadistica EjerciciosarielОценок пока нет
- DETERMINANTESДокумент13 страницDETERMINANTESNahuel Domingo AybarОценок пока нет
- Ejercicios de Programación Lineal PruebaДокумент25 страницEjercicios de Programación Lineal PruebaEsthela MontoyaОценок пока нет
- Actividad #05 - GráficosДокумент6 страницActividad #05 - GráficosJonathan Lozada CarrascoОценок пока нет
- Guía # 5 Estadística I CCEEДокумент3 страницыGuía # 5 Estadística I CCEELuis Ernesto Aquino Salazar100% (1)
- Función Generatriz de MomentosДокумент16 страницFunción Generatriz de MomentosAlizée jenn0% (1)
- Grupo Genuino de EstadisticaДокумент20 страницGrupo Genuino de EstadisticajoanОценок пока нет
- GERENCIALДокумент86 страницGERENCIALCMMartinОценок пока нет
- Tarea 03 Prueba T para Una Muestra y Muestras IndependientesДокумент6 страницTarea 03 Prueba T para Una Muestra y Muestras IndependientesBayron AndresОценок пока нет
- Miguel Valverde TorresДокумент8 страницMiguel Valverde Torrespapuchitos100% (2)
- Trabajo Práctico. Distribución de FrecuenciasДокумент16 страницTrabajo Práctico. Distribución de Frecuenciascamm_10007806Оценок пока нет
- Ejercicios Estadística BasicaДокумент7 страницEjercicios Estadística BasicaMathew Sanchez ValeraОценок пока нет
- GatoandinoДокумент11 страницGatoandinoJhon AlexОценок пока нет
- Distribuciones de Probabilidad de Variables Aleatorias ContinuasДокумент2 страницыDistribuciones de Probabilidad de Variables Aleatorias ContinuasLENIN VLADIMIR MONTENEGRO DIAZОценок пока нет
- T5 AlgebraДокумент8 страницT5 AlgebraAlejandro García NaranjoОценок пока нет
- Primer ParcialДокумент5 страницPrimer ParcialAlvaro GonzalesОценок пока нет
- TAREA-N-08 - Estadística AplicadaДокумент9 страницTAREA-N-08 - Estadística AplicadaMiguel Meléndez0% (1)
- Instituto Tecnologico EuroamericanoДокумент16 страницInstituto Tecnologico EuroamericanoJuan RiosОценок пока нет
- Ejercicios Propuestos - EstadisticaДокумент6 страницEjercicios Propuestos - EstadisticaWilfredo Torres PacherresОценок пока нет
- Los-Peroles-De-Palmeras-Yaranche 1Документ3 страницыLos-Peroles-De-Palmeras-Yaranche 1JuanCarlos Campos GonzalesОценок пока нет
- Estadística Descriptiva - Conceptos Generales - Biblioteca de Investigaciones PDFДокумент34 страницыEstadística Descriptiva - Conceptos Generales - Biblioteca de Investigaciones PDFtiple81Оценок пока нет
- Universidad Michoacana de San Nicolás de HidalgoДокумент21 страницаUniversidad Michoacana de San Nicolás de HidalgoCarlos Fernando Pahua AndradeОценок пока нет
- INTRODUCCION E HISTORIA DE LA ESTADISTICA Doc2Документ5 страницINTRODUCCION E HISTORIA DE LA ESTADISTICA Doc2Luis Antonio Romero CaceresОценок пока нет
- Historia de La Estadisticas y Sus Principales ExponenentesДокумент13 страницHistoria de La Estadisticas y Sus Principales ExponenentesMaryori AndinoОценок пока нет
- Bio ClasesДокумент42 страницыBio ClasesValeria RodelaОценок пока нет
- Regulación Del Monopolio NaturalДокумент16 страницRegulación Del Monopolio NaturalGladys Esperanza Godines SanchezОценок пока нет
- Facultad de Ciencias Empresariales Tesis para Optar El Título Profesional de Licenciado en AdministraciónДокумент211 страницFacultad de Ciencias Empresariales Tesis para Optar El Título Profesional de Licenciado en AdministraciónGladys Esperanza Godines SanchezОценок пока нет
- 2 PB PDFДокумент28 страниц2 PB PDFEmilia MillonОценок пока нет
- 4002-Texto Del Artículo-15926-1-10-20141216Документ12 страниц4002-Texto Del Artículo-15926-1-10-20141216Gladys Esperanza Godines SanchezОценок пока нет
- 17427-Texto Del Artículo-69159-1-10-20170503 PDFДокумент13 страниц17427-Texto Del Artículo-69159-1-10-20170503 PDFGIUSEPPE IVÁN BARRETO RICALDIОценок пока нет
- Repaso Teoría AritméticaДокумент9 страницRepaso Teoría AritméticaGladys Esperanza Godines SanchezОценок пока нет
- Semana 7. Estimacion Por Mínimos Cuadrados RestringidosДокумент35 страницSemana 7. Estimacion Por Mínimos Cuadrados RestringidosGladys Esperanza Godines SanchezОценок пока нет
- PC2 DC 2020 2 Enunciado PDFДокумент3 страницыPC2 DC 2020 2 Enunciado PDFGladys Esperanza Godines SanchezОценок пока нет
- Fallas de Mercado - Externalidades y Bienes PúblicosДокумент8 страницFallas de Mercado - Externalidades y Bienes PúblicosGladys Esperanza Godines SanchezОценок пока нет
- PC2 DC 2020 2 Enunciado PDFДокумент3 страницыPC2 DC 2020 2 Enunciado PDFGladys Esperanza Godines SanchezОценок пока нет
- Desaparicion ForzadaДокумент9 страницDesaparicion ForzadaThalia LanazcaОценок пока нет
- Teoría de La Regulación Económica - Regulación Del Monopolio Natural Con Información SimétricaДокумент35 страницTeoría de La Regulación Económica - Regulación Del Monopolio Natural Con Información SimétricaGladys Esperanza Godines SanchezОценок пока нет
- TEORIA DE LA ProduccionДокумент31 страницаTEORIA DE LA ProduccionGladys Esperanza Godines SanchezОценок пока нет
- Administración y Gestión de Empresas Sesion 1 PDFДокумент32 страницыAdministración y Gestión de Empresas Sesion 1 PDFGladys Esperanza Godines SanchezОценок пока нет
- G - Tarea PDFДокумент3 страницыG - Tarea PDFGladys Esperanza Godines SanchezОценок пока нет
- G - Tarea PDFДокумент3 страницыG - Tarea PDFGladys Esperanza Godines SanchezОценок пока нет
- Semana 7. Estimacion Por Mínimos Cuadrados RestringidosДокумент35 страницSemana 7. Estimacion Por Mínimos Cuadrados RestringidosGladys Esperanza Godines SanchezОценок пока нет
- Semana 7. Estimacion Por Mínimos Cuadrados RestringidosДокумент35 страницSemana 7. Estimacion Por Mínimos Cuadrados RestringidosGladys Esperanza Godines SanchezОценок пока нет
- G - Tarea PDFДокумент3 страницыG - Tarea PDFGladys Esperanza Godines SanchezОценок пока нет
- Semana 7. Estimacion Por Mínimos Cuadrados RestringidosДокумент35 страницSemana 7. Estimacion Por Mínimos Cuadrados RestringidosGladys Esperanza Godines SanchezОценок пока нет
- Crenshaw, Kimberly. Raza, Reforma y ReducciónДокумент27 страницCrenshaw, Kimberly. Raza, Reforma y ReducciónGladys Esperanza Godines SanchezОценок пока нет
- 6161 23864 1 PB PDFДокумент17 страниц6161 23864 1 PB PDFmicnousОценок пока нет
- Teoría de La Regulación Económica - Tarifas No LinealesДокумент29 страницTeoría de La Regulación Económica - Tarifas No LinealesGladys Esperanza Godines SanchezОценок пока нет
- Semana 7. Estimacion Por Mínimos Cuadrados RestringidosДокумент35 страницSemana 7. Estimacion Por Mínimos Cuadrados RestringidosGladys Esperanza Godines SanchezОценок пока нет
- Semana 7. Estimacion Por Mínimos Cuadrados RestringidosДокумент35 страницSemana 7. Estimacion Por Mínimos Cuadrados RestringidosGladys Esperanza Godines SanchezОценок пока нет
- Teoría de La Regulación Económica - Monopolio Natural MultiproductoДокумент21 страницаTeoría de La Regulación Económica - Monopolio Natural MultiproductoGladys Esperanza Godines SanchezОценок пока нет
- Teoría de La Regulación Económica - Monopolio Natural MultiproductoДокумент21 страницаTeoría de La Regulación Económica - Monopolio Natural MultiproductoGladys Esperanza Godines SanchezОценок пока нет
- Desarrollo de La Fich4Документ2 страницыDesarrollo de La Fich4Gladys Esperanza Godines SanchezОценок пока нет
- Semana 7. Estimacion Por Mínimos Cuadrados RestringidosДокумент35 страницSemana 7. Estimacion Por Mínimos Cuadrados RestringidosGladys Esperanza Godines SanchezОценок пока нет
- Desarrollo de La Fich3Документ7 страницDesarrollo de La Fich3Gladys Esperanza Godines SanchezОценок пока нет
- Semiologiaabdominalclase 121028171811 Phpapp02Документ56 страницSemiologiaabdominalclase 121028171811 Phpapp02Cristian AltunaОценок пока нет
- Trabajos 5toДокумент4 страницыTrabajos 5toDayma SantamariaОценок пока нет
- Motivación Del PersonalДокумент30 страницMotivación Del PersonalAngélica MincholaОценок пока нет
- VenezuelaДокумент14 страницVenezuelaAstridMarquezОценок пока нет
- Modelo 1 MOMENTO IДокумент4 страницыModelo 1 MOMENTO IJOSLIBETHОценок пока нет
- Taller 1 Analisis VectorialДокумент14 страницTaller 1 Analisis VectorialVioleta Ruiz0% (1)
- Sem1-Tarea1-Diana Anariba-61811168-309Документ6 страницSem1-Tarea1-Diana Anariba-61811168-309Karen JulisaОценок пока нет
- Resultados Encuesta Códigos de VestimentaДокумент3 страницыResultados Encuesta Códigos de VestimentaGuillermo DavidОценок пока нет
- Ejercicio COSO I ComponentesДокумент9 страницEjercicio COSO I ComponentesMarcos Gomez67% (3)
- Entrevista A Una FiologaДокумент2 страницыEntrevista A Una Fiologamaidertejero100% (1)
- TOPOGRAFÍAДокумент20 страницTOPOGRAFÍAAnderson MenesesОценок пока нет
- Gráficas de Datos y TransformacionesДокумент3 страницыGráficas de Datos y TransformacionesRogerio Chicoma MalcaОценок пока нет
- Ignace LeppДокумент2 страницыIgnace LeppindustriapampaОценок пока нет
- Actividades para Trabajar en Casa Grado QuintoДокумент7 страницActividades para Trabajar en Casa Grado QuintoBLADMIRОценок пока нет
- Organización de Los Tribunales en República DominicanaДокумент15 страницOrganización de Los Tribunales en República DominicanamarioОценок пока нет
- 9 Pràctica No. 9Документ9 страниц9 Pràctica No. 9Gisel Molina MorèОценок пока нет
- El Estado de Las Cosas Resumen GENERALДокумент3 страницыEl Estado de Las Cosas Resumen GENERALJazmin Paz Olivares QuijadaОценок пока нет
- Sociedades de Jovenes CreativasДокумент6 страницSociedades de Jovenes CreativasWaleska MaldonadoОценок пока нет
- Origen Del Alfabeto y Los Acontecimientos Que Se DieronДокумент8 страницOrigen Del Alfabeto y Los Acontecimientos Que Se DieronMaury LopezОценок пока нет
- Diapos de RuterfordДокумент9 страницDiapos de RuterfordDiana Alicia Sifuentes RodriguezОценок пока нет
- Estructura OrganizacionalДокумент17 страницEstructura Organizacionalanon-501650100% (4)
- Pre EclampsiaДокумент46 страницPre EclampsiaUrgencias HGR 200Оценок пока нет
- D1 Arquitectura PC1Документ39 страницD1 Arquitectura PC1Thyami Castillo Montes100% (1)
- Ejercicios Espirituales OruroДокумент99 страницEjercicios Espirituales OruroGabriela Flavia Valda AguilarОценок пока нет
- PérezÁlvarez Fernando M12S1AI1Документ3 страницыPérezÁlvarez Fernando M12S1AI1Fernando PérezОценок пока нет
- 7° Historia 2022 Est-78-79Документ2 страницы7° Historia 2022 Est-78-79CarlosОценок пока нет
- Actividad Del Martes 15 de Junio - Cómo Debes Actuar Frente A ExtrañosДокумент2 страницыActividad Del Martes 15 de Junio - Cómo Debes Actuar Frente A ExtrañosOlga PalaciosОценок пока нет
- Cuestionarios Oferta Demanda Segmentación ElasticidadДокумент15 страницCuestionarios Oferta Demanda Segmentación ElasticidadRocio CentenoОценок пока нет
- Capitulo 9 Contacto VisualДокумент7 страницCapitulo 9 Contacto VisualfrankОценок пока нет
- Cuadro Comparativo Modelos Atomicos.Документ3 страницыCuadro Comparativo Modelos Atomicos.Andres CanoОценок пока нет