Вам также может понравиться
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- Apache Flume - Data Transfer in Hadoop - TutorialspointДокумент2 страницыApache Flume - Data Transfer in Hadoop - TutorialspointMario SoaresОценок пока нет
- Apache Kafka TutorialДокумент3 страницыApache Kafka TutorialMario SoaresОценок пока нет
- Integrating Apache Nifi With External API'sДокумент4 страницыIntegrating Apache Nifi With External API'sMario SoaresОценок пока нет
- Gentle Introduction To Apache Nifi For Data Flow. and Some ClojureДокумент7 страницGentle Introduction To Apache Nifi For Data Flow. and Some ClojureMario SoaresОценок пока нет
- Integrating Apache Nifi and Apache KafkaДокумент5 страницIntegrating Apache Nifi and Apache KafkaMario SoaresОценок пока нет
- Dataflow Management From Edge To Core With Apache NiFiДокумент1 страницаDataflow Management From Edge To Core With Apache NiFiMario SoaresОценок пока нет
- Apache NiFi Vs StreamsetsДокумент6 страницApache NiFi Vs StreamsetsMario SoaresОценок пока нет
- Apache Flume Tutorial - What Is - ArchitectureДокумент8 страницApache Flume Tutorial - What Is - ArchitectureMario SoaresОценок пока нет
- Getting Started With Apache NifiДокумент10 страницGetting Started With Apache NifiMario SoaresОценок пока нет
- What Is Hadoop Distributed File System (HDFS) PDFДокумент3 страницыWhat Is Hadoop Distributed File System (HDFS) PDFMario SoaresОценок пока нет
- Zhow To Store Output of Shell Script in Hdfs - HortonworksДокумент2 страницыZhow To Store Output of Shell Script in Hdfs - HortonworksMario SoaresОценок пока нет
- What Is Ambari - Introduction To Apache Ambari ArchitectureДокумент5 страницWhat Is Ambari - Introduction To Apache Ambari ArchitectureMario SoaresОценок пока нет
- Oozie - Apache Oozie Workflow Scheduler For HadoopДокумент1 страницаOozie - Apache Oozie Workflow Scheduler For HadoopMario SoaresОценок пока нет
- How To Query Hbase Data Using SolrДокумент1 страницаHow To Query Hbase Data Using SolrMario SoaresОценок пока нет
- Timeline Service v2.0 Reader Not Starting - HortonworksДокумент3 страницыTimeline Service v2.0 Reader Not Starting - HortonworksMario SoaresОценок пока нет
- Solr Installation and Management From AmbariДокумент1 страницаSolr Installation and Management From AmbariMario SoaresОценок пока нет
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (400)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (345)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (121)
- Agnes de MilleДокумент3 страницыAgnes de MilleMarie-Maxence De RouckОценок пока нет
- Sba 2Документ29 страницSba 2api-377332228Оценок пока нет
- PED003Документ1 страницаPED003ely mae dag-umanОценок пока нет
- Arnold Ventures Letter To Congressional Social Determinants of Health CaucusДокумент7 страницArnold Ventures Letter To Congressional Social Determinants of Health CaucusArnold VenturesОценок пока нет
- 5c3f1a8b262ec7a Ek PDFДокумент5 страниц5c3f1a8b262ec7a Ek PDFIsmet HizyoluОценок пока нет
- The Doshas in A Nutshell - : Vata Pitta KaphaДокумент1 страницаThe Doshas in A Nutshell - : Vata Pitta KaphaCheryl LynnОценок пока нет
- SMR 13 Math 201 SyllabusДокумент2 страницыSMR 13 Math 201 SyllabusFurkan ErisОценок пока нет
- Regions of Alaska PresentationДокумент15 страницRegions of Alaska Presentationapi-260890532Оценок пока нет
- in Strategic Management What Are The Problems With Maintaining A High Inventory As Experienced Previously With Apple?Документ5 страницin Strategic Management What Are The Problems With Maintaining A High Inventory As Experienced Previously With Apple?Priyanka MurthyОценок пока нет
- Role of Losses in Design of DC Cable For Solar PV ApplicationsДокумент5 страницRole of Losses in Design of DC Cable For Solar PV ApplicationsMaulidia HidayahОценок пока нет
- Outdoor Air Pollution: Sources, Health Effects and SolutionsДокумент20 страницOutdoor Air Pollution: Sources, Health Effects and SolutionsCamelia RadulescuОценок пока нет
- Ozone Therapy - A Clinical Review A. M. Elvis and J. S. EktaДокумент5 страницOzone Therapy - A Clinical Review A. M. Elvis and J. S. Ektatahuti696Оценок пока нет
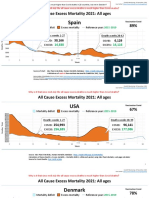
- Countries EXCESS DEATHS All Ages - 15nov2021Документ21 страницаCountries EXCESS DEATHS All Ages - 15nov2021robaksОценок пока нет
- Read While Being Blind.. Braille's Alphabet: Be Aware and Active !Документ3 страницыRead While Being Blind.. Braille's Alphabet: Be Aware and Active !bitermanОценок пока нет
- Unit 7: Anthropology: Q2e Listening & Speaking 4: Audio ScriptДокумент6 страницUnit 7: Anthropology: Q2e Listening & Speaking 4: Audio ScriptĐại học Bạc Liêu Truyền thông100% (1)
- PhraseologyДокумент14 страницPhraseologyiasminakhtar100% (1)
- 2SB817 - 2SD1047 PDFДокумент4 страницы2SB817 - 2SD1047 PDFisaiasvaОценок пока нет
- Fss Presentation Slide GoДокумент13 страницFss Presentation Slide GoReinoso GreiskaОценок пока нет
- Nutrition and CKDДокумент20 страницNutrition and CKDElisa SalakayОценок пока нет
- Azimuth Steueung - EngДокумент13 страницAzimuth Steueung - EnglacothОценок пока нет
- Rule 113 114Документ7 страницRule 113 114Shaila GonzalesОценок пока нет
- What Is TranslationДокумент3 страницыWhat Is TranslationSanskriti MehtaОценок пока нет
- Spesifikasi PM710Документ73 страницыSpesifikasi PM710Phan'iphan'Оценок пока нет
- AnticyclonesДокумент5 страницAnticyclonescicileanaОценок пока нет
- Android Developer PDFДокумент2 страницыAndroid Developer PDFDarshan ChakrasaliОценок пока нет
- Grade 7 ExamДокумент3 страницыGrade 7 ExamMikko GomezОценок пока нет
- Ricoh IM C2000 IM C2500: Full Colour Multi Function PrinterДокумент4 страницыRicoh IM C2000 IM C2500: Full Colour Multi Function PrinterKothapalli ChiranjeeviОценок пока нет
- OZO Player SDK User Guide 1.2.1Документ16 страницOZO Player SDK User Guide 1.2.1aryan9411Оценок пока нет
- Electro Fashion Sewable LED Kits WebДокумент10 страницElectro Fashion Sewable LED Kits WebAndrei VasileОценок пока нет
- Guidelines For SKPMG2 TSSP - Draft For Consultation 10.10.17Документ5 страницGuidelines For SKPMG2 TSSP - Draft For Consultation 10.10.17zqhnazОценок пока нет