Вам также может понравиться
- Zen and The Art of Power Play Cube BuildingДокумент84 страницыZen and The Art of Power Play Cube BuildingshyamsuchakОценок пока нет
- CON10850 - Potapov-CON10850-Real-Time Analytics For Oracle Business Intelligence With Intel TechnologiesДокумент31 страницаCON10850 - Potapov-CON10850-Real-Time Analytics For Oracle Business Intelligence With Intel TechnologiessbabuindОценок пока нет
- SciNet TutorialДокумент22 страницыSciNet Tutorialddsk86Оценок пока нет
- IBM® System Storage™ DS5300 Performance Results in IBM I™ Power Systems EnvironmentДокумент13 страницIBM® System Storage™ DS5300 Performance Results in IBM I™ Power Systems EnvironmentJorgita SdsОценок пока нет
- CUDA, Supercomputing For The Masses: Part 4: Understanding and Using Shared MemoryДокумент3 страницыCUDA, Supercomputing For The Masses: Part 4: Understanding and Using Shared MemorythatupisoОценок пока нет
- EE5902R Chapter 1 SlidesДокумент46 страницEE5902R Chapter 1 SlidesShyamSundarОценок пока нет
- Small College SupercomputingДокумент5 страницSmall College SupercomputingsriniefsОценок пока нет
- Percona XtraDB 集群文档Документ37 страницPercona XtraDB 集群文档HoneyMooseОценок пока нет
- CS553 Homework #3: Benchmarking StorageДокумент5 страницCS553 Homework #3: Benchmarking StorageHariharan ShankarОценок пока нет
- Jerasure: A Library in C Facilitating Erasure Coding For Storage ApplicationsДокумент37 страницJerasure: A Library in C Facilitating Erasure Coding For Storage ApplicationsherrwieseОценок пока нет
- Microsoft Storage Spaces Direct (S2D) Deployment Guide: Front CoverДокумент36 страницMicrosoft Storage Spaces Direct (S2D) Deployment Guide: Front CoverСергей КовалевОценок пока нет
- Lecture 4 Spring 2024Документ26 страницLecture 4 Spring 2024LAEVO LifeОценок пока нет
- RES2 DINVquickДокумент11 страницRES2 DINVquickENG.YONIS HUSSAINОценок пока нет
- Manual For Using Super Computing ResourcesДокумент22 страницыManual For Using Super Computing ResourcesusmanОценок пока нет
- BuddyBland Titan SC12Документ12 страницBuddyBland Titan SC12bernasekОценок пока нет
- Computer Systems: CS553 Homework #2Документ2 страницыComputer Systems: CS553 Homework #2Hariharan ShankarОценок пока нет
- Multicore vs Multi Cpu 성능비교Документ10 страницMulticore vs Multi Cpu 성능비교howanОценок пока нет
- OpenSER RTPproxy Benchmark TestДокумент42 страницыOpenSER RTPproxy Benchmark TestAsit SwainОценок пока нет
- Challenge QuestionsДокумент2 страницыChallenge Questionsnhat minh truongОценок пока нет
- CopperCube Application GuideДокумент69 страницCopperCube Application GuideChristoffer MadureiraОценок пока нет
- OCI 2023 Architect Associate 1Z0-1072-23Документ89 страницOCI 2023 Architect Associate 1Z0-1072-23RAJA SEKHAR REDDY REDDEM0% (2)
- 15 - Sun - OuwensДокумент31 страница15 - Sun - OuwensLara SalinasОценок пока нет
- OCI 2023 Architect Associate 1Z0 1072 23Документ89 страницOCI 2023 Architect Associate 1Z0 1072 23saw andrewОценок пока нет
- Roofline: An Insightful Visual Performance Model For Floating-Point Programs and Multicore ArchitecturesДокумент10 страницRoofline: An Insightful Visual Performance Model For Floating-Point Programs and Multicore ArchitecturesSimon linОценок пока нет
- Beowulf SetupДокумент46 страницBeowulf SetupBiswa DuttaОценок пока нет
- Cisco UCS Common Platform Architecture Version 2 For Big DataДокумент2 страницыCisco UCS Common Platform Architecture Version 2 For Big DataHotnCrispy CrispyОценок пока нет
- Ceph Reference ArchitectureДокумент12 страницCeph Reference ArchitectureGermgmaan100% (1)
- CommVault Building Block Configuration V9 White PaperДокумент35 страницCommVault Building Block Configuration V9 White PaperHarish GuptaОценок пока нет
- Understanding Processor Utilization With Ibm PowervmДокумент15 страницUnderstanding Processor Utilization With Ibm PowervmOleksandr DenysenkoОценок пока нет
- AWS NotesДокумент81 страницаAWS NotesHUGUES ADDIH100% (1)
- Tata HPC AmanДокумент34 страницыTata HPC Amantemp mailОценок пока нет
- Intergraph Smartplant Review 64 Bit WhitepapersДокумент12 страницIntergraph Smartplant Review 64 Bit WhitepapersSomnath LahaОценок пока нет
- Ansys Mechanical Performance On OciДокумент16 страницAnsys Mechanical Performance On OciAndrea Paola Hernandez M.Оценок пока нет
- Performance Evaluation of The KVM Hypervisor Running On Arm-Based Single-Board ComputersДокумент18 страницPerformance Evaluation of The KVM Hypervisor Running On Arm-Based Single-Board ComputersAIRCC - IJCNCОценок пока нет
- Building A Columnar Database On RAMCloud - Database Design For The Low-Latency Enabled Data CenterДокумент139 страницBuilding A Columnar Database On RAMCloud - Database Design For The Low-Latency Enabled Data CenterSebastian laierОценок пока нет
- Dbrac 19c Ovm2 ConfigДокумент41 страницаDbrac 19c Ovm2 ConfigakbezawadaОценок пока нет
- Icl Utk 1570 2022Документ26 страницIcl Utk 1570 2022taldayyeniОценок пока нет
- Synthetic Data GenДокумент29 страницSynthetic Data GenOwen MantzОценок пока нет
- 64-Bit Versus 32-Bit Virtual Machines For Java: Kris Venstermans, Lieven Eeckhout and Koen de BosschereДокумент26 страниц64-Bit Versus 32-Bit Virtual Machines For Java: Kris Venstermans, Lieven Eeckhout and Koen de BosschereAbirami SenthilkumarОценок пока нет
- Tuning Linux For Big Firebird Database: 693GB AND 1000+ USERSДокумент35 страницTuning Linux For Big Firebird Database: 693GB AND 1000+ USERSOscar MartinezОценок пока нет
- Java Performance On POWER7 - Best Practice: June 28, 2011Документ25 страницJava Performance On POWER7 - Best Practice: June 28, 2011boggo1Оценок пока нет
- Beowulf ClusterДокумент60 страницBeowulf ClusterAmandeep SinghОценок пока нет
- Nec S6XДокумент22 страницыNec S6XLéia de SousaОценок пока нет
- Socunit 1Документ65 страницSocunit 1Sooraj SattirajuОценок пока нет
- Auto-Vectorization With The Intel Compilers: Is Your Code Ready For Sandy Bridge and Knights Corner?Документ12 страницAuto-Vectorization With The Intel Compilers: Is Your Code Ready For Sandy Bridge and Knights Corner?Stephen PattersonОценок пока нет
- Comparing Databases For An Industrial IoT Use-Case: MongoDB, TimescaleDB, InfluxDB and CrateDBДокумент6 страницComparing Databases For An Industrial IoT Use-Case: MongoDB, TimescaleDB, InfluxDB and CrateDBSananeОценок пока нет
- Cray XC Scalability Advantage White PaperДокумент16 страницCray XC Scalability Advantage White PaperadwausОценок пока нет
- Performance Analysis of High Performance Computing Applications On The Amazon Web Services CloudДокумент10 страницPerformance Analysis of High Performance Computing Applications On The Amazon Web Services CloudAdem AlikadićОценок пока нет
- Designing High-Performance DELLДокумент4 страницыDesigning High-Performance DELLsooryatheja4721Оценок пока нет
- POWER - POWER9 AC922 DatasheetДокумент5 страницPOWER - POWER9 AC922 DatasheetpipatlОценок пока нет
- Dynamic Voltage and Frequency Scaling The Laws ofДокумент6 страницDynamic Voltage and Frequency Scaling The Laws ofQurat AnnieОценок пока нет
- Yi: Open Foundation Models by 01.AIДокумент26 страницYi: Open Foundation Models by 01.AIstephane.vicentОценок пока нет
- SPDK 19.04 NVMeOF RDMA Benchmark Report-2Документ54 страницыSPDK 19.04 NVMeOF RDMA Benchmark Report-2thanh liêm lêОценок пока нет
- Aristos WinHECwhitepaper2003Документ13 страницAristos WinHECwhitepaper2003Fenil DesaiОценок пока нет
- PracticeProblems COA8eДокумент40 страницPracticeProblems COA8eAnousith PhompidaОценок пока нет
- LinuxCluster PDFДокумент21 страницаLinuxCluster PDFVittorio GrassoОценок пока нет
- NXP - PHGL S A0002809956 1 1750376Документ238 страницNXP - PHGL S A0002809956 1 1750376german daniel vasquez andradeОценок пока нет
- Nintendo 64 Architecture: Architecture of Consoles: A Practical Analysis, #8От EverandNintendo 64 Architecture: Architecture of Consoles: A Practical Analysis, #8Оценок пока нет
- Bba103 MQP KeysДокумент15 страницBba103 MQP KeysDr. Smita ChoudharyОценок пока нет
- CodeДокумент1 672 страницыCodejazz440Оценок пока нет
- Unit 6finalДокумент20 страницUnit 6finalAnonymous bTh744z7E6Оценок пока нет
- JavaДокумент1 страницаJavaNajib AbdillahОценок пока нет
- ETL Design and Code Guidelines V1Документ18 страницETL Design and Code Guidelines V1jazz440100% (1)
- Unit 9final 1Документ21 страницаUnit 9final 1jazz440Оценок пока нет
- BDE IPConfigOutputДокумент1 страницаBDE IPConfigOutputjazz440Оценок пока нет
- Unit 7 Legal Environment: StructureДокумент17 страницUnit 7 Legal Environment: Structurejazz440Оценок пока нет
- Unit 2 Collection, Classification, and Presentation of Data: StructureДокумент20 страницUnit 2 Collection, Classification, and Presentation of Data: Structurejazz440Оценок пока нет
- Unit 6finalДокумент24 страницыUnit 6finaljazz440Оценок пока нет
- Unit 5final 1Документ17 страницUnit 5final 1jazz440Оценок пока нет
- Unit 7 Index Numbers: StructureДокумент27 страницUnit 7 Index Numbers: Structurejazz440Оценок пока нет
- Unit 2final 1Документ19 страницUnit 2final 1jazz440Оценок пока нет
- Research Method Test1-AugДокумент2 страницыResearch Method Test1-Augjazz440Оценок пока нет
- Canada MigrationДокумент14 страницCanada Migrationjazz440Оценок пока нет
- Unit 2 Collection, Classification, and Presentation of Data: StructureДокумент20 страницUnit 2 Collection, Classification, and Presentation of Data: Structurejazz440Оценок пока нет
- Ewr Terminal BДокумент1 страницаEwr Terminal Bjazz440Оценок пока нет
- FDA Forms For Medicines Shipments Only To USAДокумент2 страницыFDA Forms For Medicines Shipments Only To USAjazz440Оценок пока нет
- 32 Ielts Essay Samples Band 9Документ34 страницы32 Ielts Essay Samples Band 9mh73% (26)
- Schedule Week4 Nov 2014 For StudentsДокумент6 страницSchedule Week4 Nov 2014 For Studentsjazz440Оценок пока нет
- Listening Answer SheetДокумент1 страницаListening Answer Sheetjazz440Оценок пока нет
- Gotham Deep Square Pan CookbookДокумент38 страницGotham Deep Square Pan Cookbookjazz440Оценок пока нет
- (IELTS-Fighter) - IELTS Speaking Part 2 by Simon PDFДокумент26 страниц(IELTS-Fighter) - IELTS Speaking Part 2 by Simon PDFblackbacОценок пока нет
- January 2017: Sunday Monday Tuesday Wednesday Thursday Friday SaturdayДокумент12 страницJanuary 2017: Sunday Monday Tuesday Wednesday Thursday Friday Saturdayjazz440Оценок пока нет
- Linux CommndДокумент26 страницLinux CommnddhivyaОценок пока нет
- Bigtable: A Distributed Storage System For Structured DataДокумент14 страницBigtable: A Distributed Storage System For Structured DataMax ChiuОценок пока нет
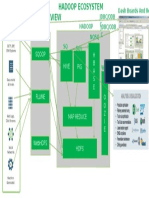
- Hadoop Ecosystem PresentationДокумент1 страницаHadoop Ecosystem Presentationjazz440Оценок пока нет
- Express Entry System: Information For Skilled Foreign WorkersДокумент16 страницExpress Entry System: Information For Skilled Foreign WorkersTitoFernandezОценок пока нет
- Hadoop SetupДокумент43 страницыHadoop Setupjazz440Оценок пока нет
- Big Data Analytics For Dynamic Energy Management in Smart GridsДокумент9 страницBig Data Analytics For Dynamic Energy Management in Smart Gridsakshansh chandravanshiОценок пока нет
- Lec 1-Intro To ComputerДокумент18 страницLec 1-Intro To ComputerJoshua BrownОценок пока нет
- Bios TajimaДокумент1 страницаBios TajimaMyra Buendia0% (1)
- RabbitMQ IntroductionДокумент33 страницыRabbitMQ IntroductionCraig LinОценок пока нет
- Win Shuttle Transaction Required SAP AuthorizationsДокумент2 страницыWin Shuttle Transaction Required SAP Authorizationsb092840Оценок пока нет
- Thread in JavaДокумент41 страницаThread in JavaRushikesh KadamОценок пока нет
- WMB WMQ WAS MQ Interview QuestionsДокумент6 страницWMB WMQ WAS MQ Interview QuestionsRajОценок пока нет
- CSC Unit - 4Документ31 страницаCSC Unit - 4Smita AgarwalОценок пока нет
- ServletДокумент40 страницServletkaviarasuОценок пока нет
- Qualcomm & Leadcore & Intel & Pinecone Platform Series Devices Flash Instruction V23Документ62 страницыQualcomm & Leadcore & Intel & Pinecone Platform Series Devices Flash Instruction V23Jeisson Forero.Оценок пока нет
- Fast Geo Efficient Geometric Range Queries OnДокумент3 страницыFast Geo Efficient Geometric Range Queries OnIJARTETОценок пока нет
- Soc Linux CheatsheetДокумент2 страницыSoc Linux CheatsheetFestilaCatalinGeorgeОценок пока нет
- CCNAquestions Feb 2019 PDFДокумент238 страницCCNAquestions Feb 2019 PDFSunda100% (1)
- Webgl TutorialДокумент31 страницаWebgl TutorialAnusha ReddyОценок пока нет
- Oracle Service Bus Migration (ESB To OSB)Документ9 страницOracle Service Bus Migration (ESB To OSB)SOA TrainingОценок пока нет
- Telenet Web Manual InstalacionДокумент32 страницыTelenet Web Manual InstalacionpedropcОценок пока нет
- Data Mining in HealthcareДокумент26 страницData Mining in HealthcareThuy TienОценок пока нет
- Mechanical 3day M01 IntroductionДокумент72 страницыMechanical 3day M01 IntroductionSiyavash QahremaniОценок пока нет
- DCOM Configuration GuideДокумент53 страницыDCOM Configuration Guidediegos109Оценок пока нет
- Arduino LED Matrix DisplayДокумент8 страницArduino LED Matrix Displayyugie88Оценок пока нет
- HP Imp Msa Storage Sol StudentguideДокумент304 страницыHP Imp Msa Storage Sol StudentguidePavan KamishettiОценок пока нет
- Chapter 9 - Counter-TimerДокумент24 страницыChapter 9 - Counter-TimerAaron Lewis DinkinОценок пока нет
- 1 Artificial IntelligenceДокумент17 страниц1 Artificial IntelligenceRohit RawatОценок пока нет
- DBA Cockpit For SAP HANAДокумент8 страницDBA Cockpit For SAP HANADinakar Babu JangaОценок пока нет
- Holger Wendland - Numerical Linear Algebra - An Introduction (2017, Cambridge University Press) PDFДокумент419 страницHolger Wendland - Numerical Linear Algebra - An Introduction (2017, Cambridge University Press) PDFAkash MandalОценок пока нет
- ABB FOX Firewall AFF650 PDFДокумент2 страницыABB FOX Firewall AFF650 PDFOscar Mercado GarcíaОценок пока нет
- Automata Theory and Computability PDFДокумент189 страницAutomata Theory and Computability PDFshakti priyaОценок пока нет
- Impl Timing 4 MaxДокумент2 страницыImpl Timing 4 MaxDlishaОценок пока нет
- Unit IV - MCQs (Bank 1)Документ2 страницыUnit IV - MCQs (Bank 1)AbhijeetОценок пока нет
- Experiment 7Документ13 страницExperiment 7Sheraz HassanОценок пока нет