Академический Документы
Профессиональный Документы
Культура Документы
Tinoco 2018
Загружено:
Tita Kartika DewiАвторское право
Доступные форматы
Поделиться этим документом
Поделиться или встроить документ
Этот документ был вам полезен?
Это неприемлемый материал?
Пожаловаться на этот документАвторское право:
Доступные форматы
Tinoco 2018
Загружено:
Tita Kartika DewiАвторское право:
Доступные форматы
Stability Condition Identification of Rock and
Soil Cutting Slopes Based on Soft Computing
Joaquim Tinoco, Ph.D. 1; A. Gomes Correia 2; Paulo Cortez 3; and David G. Toll 4
Abstract: For transportation infrastructure, one of the greatest challenges today is to keep large-scale transportation networks, such as
railway networks, operational under all conditions. This task becomes even more difficult to accomplish if one takes into account budget
Downloaded from ascelibrary.org by Arizona State Univ on 12/25/17. Copyright ASCE. For personal use only; all rights reserved.
limitations for maintenance and repair works. This paper presents a tool aimed at helping in management tasks related to maintenance and
repair work for a particular element of this infrastructure, the slopes. The highly flexible learning capabilities of artificial neural networks
(ANNs) and support vector machines (SVMs) were applied in the development of a tool able to identify the stability condition of rock and soil
cutting slopes, keeping in mind the use of information usually collected during routine inspection activities (visual information) to feed the
models. This task was addressed following two different strategies: nominal classification and regression. Moreover, to overcome the problem
of imbalanced data, three training sampling approaches were explored: no resampling, synthetic minority oversampling technique (SMOTE),
and oversampling. The achieved results are presented and discussed, comparing the performance of ANN and SVM algorithms as well as the
effect of the sampling approaches. A comparison between nominal classification and regression strategies for both rock and soil cutting slopes
is also carried out, highlighting the different performance observed in the study of the two different types of slope. DOI: 10.1061/(ASCE)
CP.1943-5487.0000739. © 2017 American Society of Civil Engineers.
Introduction and Background systems were developed based on particular case studies or using
small databases. Furthermore, another aspect that can limit their
A key element in modern society is its transportation system. Every applicability is related with the information required to feed them,
developed country undergoing development has invested and keeps such as data taken from complex tests or from expensive monitor-
investing to build a safe and functional transportation network. ing systems.
Nowadays, the main concern, particularly for developed countries Some approaches found in the literature for slope failure detec-
that already have a very complete transportation network, is to keep tion are identified later. Pourkhosravani and Kalantari (2011) sum-
such networks operational under all conditions. However, because marize the current methods for slope stability evaluation, which
of network extension and increased budget constraints, such a task were grouped into limit equilibrium (LE) methods, numerical
is often difficult to accomplish. analysis methods, artificial neural networks, and limit analysis
In order to optimize the available budget it is important to have a methods. There are also approaches based on finite-element meth-
set of tools to help decision makers to take the best decisions. In the ods (Suchomel et al. 2010), reliability analysis (Sivakumar Babu
framework of transportation networks, in particular for a railway, and Murthy 2005; Husein Malkawi et al. 2000), as well as some
slopes are perhaps the element for which their failure can have the methods making use of soft computing algorithms (Gavin and Xue
strongest impact at several levels. Therefore, it is important to de- 2009; Cheng and Hoang 2016; Ahangar-Asr et al. 2010; Lu and
velop ways to identify potential problems before they result in Rosenbaum 2003; Sakellariou and Ferentinou 2005; Cheng
failures. et al. 2012b; Yao et al. 2008; Kang et al. 2015, 2016a, b, 2017;
Although there are some models and systems to detect slope Kang and Li 2016; Das et al. 2011; Suman et al. 2016). More re-
failures, most of them were developed for natural slopes, presenting cently, a new flexible statistical system was proposed by Pinheiro
some constraints when applied to engineered (human-made) et al. (2015), based on the assessment of different factors that affect
slopes. They have limited applicability because most of the existing the behavior of a given slope. By weighting the different factors, a
1
final indicator of the slope stability condition is calculated. For a
Researcher, Institute for Sustainability and Innovation in Structural En- complete and full understanding of the slope quality index (SQI)
gineering, ALGORITMI Research Center, School of Engineering, Univ. of
system, readers are advised to read Pinheiro et al. (2015).
Minho, 4800-058 Guimarães, Portugal (corresponding author). ORCID:
https://orcid.org/0000-0001-6824-5221. E-mail: jtinoco@civil.uminho.pt
As already mentioned, the main limitations of most approaches
2
Associate Professor, ALGORITMI Research Centre, School of so far proposed are related with their applicability domain or
Engineering, Univ. of Minho, 4800-058 Guimarães, Portugal. E-mail: dependency on information that is difficult to obtain. Indeed, the
pcortez@dsi.uminho.pt prediction of whether a slope will fail or not is a multivariable prob-
3
Associate Professor, Dept. of Information Systems, ALGORITMI lem characterized by high dimensionality.
Research Center, Univ. of Minho, 4800-058 Guimarães, Portugal. E-mail: Aiming to overcome this limitation, in this work the authors take
pcortez@dsi.uminho.pt advantage of the learning capabilities of flexible soft computing
4
Full Professor, School of Engineering and Computing Sciences, Univ. algorithms, such as artificial neural networks (ANNs) and support
of Durham, Durham DH1 3LE, U.K. E-mail: d.g.toll@durham.ac.uk
vector machines (SVMs), which can model complex nonlinear
Note. This manuscript was submitted on December 16, 2016; approved
on August 18, 2017; published online on December 22, 2017. Discussion mappings. These soft computing algorithms were used to fit a large
period open until May 22, 2018; separate discussions must be submitted for database of rock and soil cutting slopes in order to predict the sta-
individual papers. This paper is part of the Journal of Computing in Civil bility condition of a given slope according to a predefined classi-
Engineering, © ASCE, ISSN 0887-3801. fication scale based on four levels (classes). One of the underlying
© ASCE 04017088-1 J. Comput. Civ. Eng.
J. Comput. Civ. Eng., 2018, 32(2): 04017088
premises of this work is to identify the real stability condition of a • Area;
given slope based on information that can be easily obtained • Cess Distance To Fence;
through routine visual inspections. For that, more than 50 variables • Cess Ditch Width;
related with data collected during routine inspections as well as • Cess Safe;
geometric, geological, and geographic data were used to feed the • Cess Stand Off;
models. This type of visual information is sufficient from the point • Class;
of view of the network management, allowing the identification of • Cess Vegetation (CV) Ground Cover;
critical zones for which more detailed information can then be ob- • CV Shrubs;
tained in order to perform more detailed stability analysis, which is • CV Trees;
out of the scope of this study. In summary, our proposal will allow • Disc Average Dilation;
identification of the stability condition level of a given rock or soil • Drainage Problems;
cutting slope based on visual information that, in most cases, can be • Easting;
easily obtained during routine inspections. Such novel approach is • Engineer’s Line References (ELR);
intended to support railway network management companies to al- • End Easting;
Downloaded from ascelibrary.org by Arizona State Univ on 12/25/17. Copyright ASCE. For personal use only; all rights reserved.
locate the available funds to assets in the priority according to its • End Mileage;
stability condition. • End Northing;
This paper is organized as follows. The “Data Characterization” • Exp Above Slope;
section characterizes the databases used to train the models. Then, • Exp Toe Slope;
after a brief description of the methodologies applied to identify • Groundwater Seepage;
the stability condition of rock and soil cutting slopes in the • Lower Slope (LS);
“Methodology” section, the main results are summarized and dis- • LS Actual Angle;
cussed in section “Results.” Finally, some final observations are • LS Actual Height;
presented in the “Discussion” section, comparing the achieved re- • LS Actual Hyp (Hyp = Hypotenuse);
sults for both rock and soil cutting slope studies. • LS Angle;
• LS Length;
• Material Cess;
Data Characterization • Northing;
• Operational Route;
As previously mentioned, in this work two models are proposed to • Pot Failure On Slope;
identify the stability condition, from this point referred to as the • Previous Failure On Face;
earthwork hazard category [EHC (Power et al. 2016)], of rock • Remedial Work Present;
and soil cutting slopes respectively using data modeling tools. • Rock Mass lt Moderate Strength;
The EHC system comprises four classes (A, B, C, and D) in • Rock Strength;
which A represents a good stability condition and D a bad stability • Rock Type;
condition. In other words, the expected probability of failure is • Rock Weathering;
higher for Class D and lower for Class A. To fit the models for • Rock Slope (RS) Actual Angle;
EHC prediction, two databases were compiled containing informa- • RS Actual Height;
tion collected during routine inspections and complemented with • RS Actual Hyp;
geometric, geological, and geographic data of each slope. Both da-
tabases were gathered by Network Rail workers and are concerned
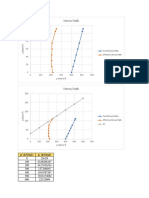
with the railway network of the United Kingdom. For each slope a 6297
class of the EHC system was defined by the Network Rail engi- Slope type:
6000 Rock Cuttings
neers based on their experience/algorithm (Power et al. 2016),
Soil Cuttings
which will be assumed as a proxy for the real stability condition
5124
of the slope for the year 2015.
Both databases contain a significant number of records. The
rock slopes database comprises 5,945 records, whereas the soil cut-
Number of records
ting slopes database is bigger, having 10,928 records available. 4000
Fig. 1 depicts the distribution of EHC classes for each database.
From this analysis, it is possible to observe a high asymmetric dis- 3076
tribution (imbalanced data), in particular for the rock slopes data-
base. Indeed, more than 86% of the rock slopes are classified as
Class A. Although this type of asymmetric distribution, in which
most of the slopes present a low probability of failure (Class A), is 2000
normal and desirable from the safety point of view and slope net- 1426
work management, it can represent an important challenge for data-
driven models learning, as detailed in next section. 569
The proposed models for identification of EHC for rock and soil 215 129
cutting slopes were fed with more than 50 variables normally col- 0
37
lected during routine inspections and complemented with geomet-
ric, geographic, and geological information. To be precise, 65 A B C D
variables were used in the rock slopes study and 51 variables in Earthworks Hazard Category (EHC)
the soil cutting slopes. All variables used in rock cutting slopes
Fig. 1. Rock and soil cutting slopes data distribution by EHC classes
study are listed in the following:
© ASCE 04017088-2 J. Comput. Civ. Eng.
J. Comput. Civ. Eng., 2018, 32(2): 04017088
• RS Angle; • Operational Route;
• RS Azimuth; • Slope Angle Adjacent;
• RS Berms; • Slope Angle Height;
• RS Dangerous Trees; • Slope To Track Separation;
• RS Dangerous Trees Number; • SR;
• RS Detremental Vegetation; • Start Height;
• RS Height; • Start Mileage;
• RS Length; • Tree Cover;
• RS Local Overhangs; • Up Down;
• RS Profile; • Validate Cracking;
• RS Root Balls; • Validate Instability;
• RS Root Balls Number; • Validate Mass Movement;
• RS Slope Obscured; • Validate Retaining Walls;
• RS Type; • Validate Slope Form; and
Downloaded from ascelibrary.org by Arizona State Univ on 12/25/17. Copyright ASCE. For personal use only; all rights reserved.
• Rock Slope Vegetation (RSV) Ground Cover; • Validate Track Movement.
• RSV Shrubs;
• RSV Trees;
• Strategic Route (SR); Methodology
• Start Mileage;
• Surface Water Flows;
Modeling Approaches and Learning Models
• Up Down;
• Upper Slope (US); To model EHC prediction of rock and soil cutting slopes, two of the
• US Actual Angle; most flexible data mining (DM) algorithms, namely ANNs and
• US Actual Height; SVMs, were applied. Both algorithms had already been successfully
• US Actual Hyp; applied in different knowledge domains (Liao et al. 2012; Javadi
• US Angle; and et al. 2012) including in civil engineering (Tinoco et al. 2014a, b;
• US Height. Chou et al. 2016; Gomes Correia et al. 2013). There are also some
Concerning to soil cutting slopes study, all variables considered examples of ANN and SVM applications in slope stability analysis
are listed in the following: (Wang et al. 2005; Yao et al. 2008; Cheng et al. 2012a).
• Actual Angle1; ANNs are learning machines that were initially inspired by the
• Actual Angle2; functions of the human brain (Kenig et al. 2001). The information
• Actual Angle3; is processed using iteration among several neurons. This technique
• Actual Crest Width; is capable of modeling complex nonlinear mappings and is robust
• Actual Height1; in exploration of data with noise. In this study the multilayer
• Actual Height2; perceptron that contains only feedforward connections, with one
• Actual Height3; hidden layer containing H processing units, was adopted. Because
• Actual Hyp1; the network’s performance is sensitive to H (a trade-off between
• Actual Hyp2; fitting accuracy and generalization capability), a grid search of
• Actual Hyp3; f0; 2; 4; 6; 8g was adopted under an internal (i.e., applied over
• Actual Slope to Track; training data) threefold cross-validation during the learning phase
• Adjacent Catch Area; to find the best H value. Under this grid search, the H value that
• Adjacent Catch Gradient; produced the lowest mean absolute error (MAE) was selected, and
• Adjacent Land Drainage; then the ANN was retrained with all of the training data. The neural
• Animal Activity; function of the hidden nodes was set to the popular logistic function
• Area; 1=ð1 þ e−x Þ. Hence, the general model of the ANN is given by
• Attitude Of Trees; Hastie et al. (2009):
• Boulders Present; !
X
o−1 XI
• Catchment Surface; ŷ ¼ wo;0 þ f xi · wj;i þ wj;0 · wo;i ð1Þ
• Class; j¼Iþ1 i¼1
• Composition Crest;
• Composition Toe; where wj;i = weight of the connection from neuron j to unit i (if
• Construction Activity Toe; j ¼ 0, then it is a bias connection); o = output unit; f = logistic
• Cutting Cess Drainage; function; and i = number of input neurons. ANN optimization
• Cutting Crest Width; was done via the BFGS method (Venables and Ripley 2003).
• Easting; The BFGS method is a quasi-Newton method (also known as a
• ELR; variable metric algorithm specifically) that was published simulta-
• End Easting; neously in 1970 by Broyden, Fletcher, Goldfarb, and Shanno. This
• End Height; uses function values and gradients to build up a picture of the
• End Mileage; surface to be optimized (Cortez 2010).
• End Northing; SVMs were initially proposed for classification tasks (Cortes
• Max Height; and Vapnik 1995). Then it became possible to apply SVM to re-
• Min Height; gression tasks after the introduction of the ϵ-insensitive loss func-
• Mining; tion (Smola and Schölkopf 2004). The main purpose of the SVM is
• Northing; to transform input data into a high-dimensional feature space using
© ASCE 04017088-3 J. Comput. Civ. Eng.
J. Comput. Civ. Eng., 2018, 32(2): 04017088
nonlinear mapping. The SVM then finds the best linear separating Table 1. Cost-Benefit Matrix Adopted for Both Rock and Soil Cutting
hyperplane, related to a set of support vector points, in the feature Slopes Studies
space. This transformation depends on a kernel function. In this work Observed/predicted A B C D
the popular Gaussian kernel was adopted. In this context, its perfor-
A 1 −4 −8 −16
mance is affected by three parameters: γ, the parameter of the kernel; B −2 1 −4 −8
C, a penalty parameter; and ϵ (only for regression), the width of an C −4 −2 1 −4
ϵ-insensitive zone (Safarzadegan Gilan et al. 2012). The heuristics D −8 −4 −2 1
proposed by Cherkassky and Ma (2004) were used to define the first
two parameter
pffiffiffiffi values, C ¼ 3 P (for a standardized output) and
ϵ ¼ σ̂= N , where σ̂ ¼ 1.5=N · Ni¼1 ðyi − ŷi Þ2 , yi is the measured Class D. It should also be noted that the adopted CBM is not sym-
value, ŷi is the value predicted by a three-nearest neighbor algorithm, metrical. For example, predicting Class D for a true observation of
and N is the number of examples. A grid search of 2f−1;−3;−7;−9g was Class A leads to a cost of −8, which is half the cost when predicting
adopted to optimize the kernel parameter, γ, under the same internal Class A for a true Class D slope condition.
threefold cross-validation scheme adopted for ANN. The recall measures the ratio of how many cases of a certain
Downloaded from ascelibrary.org by Arizona State Univ on 12/25/17. Copyright ASCE. For personal use only; all rights reserved.
The problem of EHC prediction of rock and soil cutting slopes class were properly captured by the model. In other words,
was initially approached following a nominal classification strat- the recall of a certain class is given by
egy. However, aiming to improve the model’s performance, the TruePositives
problem was also addressed following a regression strategy, adopt- ð2Þ
TruePositives þ FalseNegatives
ing a regression scale in which A ¼ 1, B ¼ 2, C ¼ 4, and D ¼ 10.
Moreover, in order to minimize the effect of the imbalanced data On the other hand, the precision measures the correctness of the
(Fig. 1), oversampling (Ling and Li 1998) and SMOTE (Chawla model when it predicts a certain class. More specifically, the pre-
et al. 2002) approaches were applied over the training data before cision of a certain class is given by
fitting the models. When approaching imbalanced classification TruePositives
tasks, in which there is at least one target class label with a smaller ð3Þ
TruePositives þ FalsePositives
number of training samples when compared with other target class
labels, the simple use of a soft computing training algorithm will The F1-score was also calculated, which represents a trade-off
lead to data-driven models with better prediction accuracies for the between the recall and precision of a class. The F1-score corre-
majority classes and worse classification accuracies for the minor- sponds to the harmonic mean of precision and recall, according
ity classes. Thus, techniques that adjust the training data in order to to the following expression:
balance the output class labels, such as oversampling and SMOTE, precision · recall
are commonly used with imbalanced data sets. In particular, over- 2· ð4Þ
precision þ recall
sampling is a simple technique that randomly adds samples (with
repetition) of the minority classes to the training data, such that the For all four metrics, the higher the value, the better are the
final training set is balanced. SMOTE is a more sophisticated tech- predictions. The AUS values can be negative (if on average, the
nique that creates “new data” by looking at nearest neighbors to predictions lead to a cost), and the ideal predictor will have an
establish a neighborhood and then sampling from within that neigh- AUS of 1. The other metrics, recall, precision, and F1-score,
borhood. It operates on the assumption that the original data is sim- can range from 0 to 100%.
ilar because of proximity. More recently, Torgo et al. (2015) The generalization capacity of the models was accessed through a
adapted the SMOTE method for regression tasks. fivefold cross-validation approach under 20 runs (Hastie et al. 2009).
All experiments were conducted using the R statistical environ- This means that each modeling setup is trained 5 × 20 ¼ 100 times.
ment (R Core Team 2009) and supported through the rminer pack- Also, the four prediction metrics are always computed on test unseen
age (Cortez 2010), which facilitates the implementation of ANN data (as provided by the fivefold validation procedure).
and SVM algorithms, as well as different validation approaches
such as cross-validation.
Results
Models Evaluation This section summarizes the main results achieved in EHC predic-
tion of rock and soil cutting slopes through the application of soft
The distinct data-driven models will be evaluated and compared computing techniques. As described earlier, two different soft com-
using four classification metrics: average utility core (AUS), recall, puting algorithms (ANN and SVM) were applied for EHC predic-
precision, and F1-score. tion under two distinct modeling strategies: nominal classification
A cost-benefit matrix (CBM) is used to compute the AUS (Baía and regression. Moreover, in order to overcome the problem of im-
and Torgo 2015), which averages all individual predictions in terms balanced data, three training sampling approaches were explored:
of their expected cost or benefit, thus leading to a metric that is Normal (no resampling), OVERed (oversampling) and SMOTEd
more directly related to a particular real-world domain. In this (SMOTE). In case of regression, two sampling approaches were
work, it was set a CBM that reflects the EHC classification system compared: Normal (no resampling) and SMOTEd (SMOTE for re-
and the characteristics of its slope identification tasks (Table 1). gression). The authors note that the different sampling approaches
The assumption behind the adopted CBM was to penalize every were applied only to training data, used to fit the data-driven mod-
misclassification but using different weights according to the els, and the test data (as provided by the fivefold procedure) were
“distance” of the misclassification and putting larger penalties to kept without any change.
bad stability conditions (the ones that are more important to be cor-
rectly classified). For example, if a particular soil slope was iden-
Rock Slopes: EHC Prediction
tified as Class A (true condition), then the benefit is þ1 if the model
predicts the same class. For the same sample, the cost is −4 if the Concerning the study of rock slopes, Table 2 summarizes AUS,
model predicts a Class C, and it doubles to −8 if the prediction is recall, precision, and F1-score of all fitted models for EHC
© ASCE 04017088-4 J. Comput. Civ. Eng.
J. Comput. Civ. Eng., 2018, 32(2): 04017088
Table 2. Metrics in EHC Prediction of Rock Slopes
Recall Precision F1-score
Strategy Model Approach AUS A B C D A B C D A B C D
Classification ANN Normal 0.46 96.23 52.95 20.40 3.65 94.66 49.06 39.22 13.71 95.44 50.93 26.84 5.77
SMOTEd 0.37 88.10 67.60 36.58 17.3 98.50 38.36 26.14 10.89 93.01 48.95 30.49 13.37
OVERed 0.44 90.21 67.96 39.58 12.84 98.01 41.27 33.47 12.70 93.95 51.35 36.27 12.77
SVM Normal 0.33 97.39 39.79 6.44 0.41 91.63 48.57 42.95 18.75 94.42 43.74 11.20 0.80
SMOTEd 0.29 85.53 82.64 2.07 1.49 97.24 33.08 34.36 17.19 91.01 47.25 3.90 2.74
OVERed 0.13 99.78 7.14 0.00 0.00 86.95 62.83 N/A 0.00 92.92 12.82 N/A N/A
Regression ANN Normal 0.43 93.7 48.3 41.77 3.38 95.01 41.38 40.19 30.49 94.35 44.57 40.96 6.09
SMOTEd 0.35 85.97 68.37 45.84 4.32 98.07 33.85 32.95 35.56 91.62 45.28 38.34 7.70
SVM Normal 0.34 96.32 49.83 0.30 0.00 92.56 46.33 54.17 N/A 94.40 48.02 0.60 N/A
SMOTEd 0.16 77.13 93.15 11.12 0.00 99.40 27.61 48.33 N/A 86.86 42.59 18.08 N/A
Note: Best values are in bold.
Downloaded from ascelibrary.org by Arizona State Univ on 12/25/17. Copyright ASCE. For personal use only; all rights reserved.
prediction of rock slopes, according to a nominal classification present a high performance in Class A identification of rock
and regression strategies as well as using SMOTE and oversam- slopes (F1-score higher than 93%). However, for Class C
pling approaches. For a better analysis and model comparison, and particularly for Class D, the models have great difficulty
Fig. 2 compares recall, precision, and F1-score metrics of all in predicting these classes correctly. Indeed, and using F1-score
models in EHC prediction following a nominal classification as reference, the best performance in identification of slopes of
strategy. From its analysis it was observed that all models Class D is lower than 14%, which was achieved by the ANN
Approach: Normal SMOTEd OVERed
ANN SVM
100 98.5 98.01 97.39 99.78 97.24
96.23 94.66 95.44 93.01 93.95 94.42
88.1 90.21 91.63 91.01 92.92
85.53 86.95
75
50
A
25
0
100
82.64
75 67.6 67.96
62.83
52.95 50.93 48.95 51.35
B
50 49.06 48.57
43.74
47.25
38.36 41.27 39.79
33.08
25
12.82
Metric value
7.14
0
100
75
50
C
42.95
36.58 39.58 39.22
33.47 36.27 34.36
26.14 26.84 30.49
25 20.4
11.2
6.44 3.9
2.07 0
0
100
75
50
D
25 17.3 18.75 17.19
12.84 13.71 10.89 12.7 13.37 12.77
3.65 5.77 2.74
0.41 1.49 0 0 0.8
0
Recall Precision F1-score Recall Precision F1-score
Metric
Fig. 2. Models comparison based on recall, precision, and F1-score, according to a nominal classification strategy in EHC prediction of rock slopes
© ASCE 04017088-5 J. Comput. Civ. Eng.
J. Comput. Civ. Eng., 2018, 32(2): 04017088
Approach: Normal SMOTEd
ANN SVM
100 95.01 98.07 96.32 99.4
93.7 94.35 91.62 92.56 94.4
85.97 86.86
77.13
75
A
50
25
0
100 93.15
75 68.37
49.83
B
50 48.3 45.28 46.33 48.02
44.57
Downloaded from ascelibrary.org by Arizona State Univ on 12/25/17. Copyright ASCE. For personal use only; all rights reserved.
41.38 42.59
33.85
27.61
25
Metric value
0
100
75
54.17
50 48.33
C
45.84
41.77 40.19 40.96 38.34
32.95
25 18.08
11.12
0.3 0.6
0
100
75
D
50
35.56
30.49
25
4.32 6.09 7.7
3.38 0 0
0
Recall Precision F1-score Recall Precision F1-score
Metric
Fig. 3. Models comparison based on recall, precision, and F1-score, according to a regression strategy in EHC prediction of rock slopes
algorithm after balancing the database through the SMOTE Approach: Normal SMOTEd OVERed
approach.
Analyzing the influence of the SMOTE and oversampling ap- Classification Regression
proaches, a slight increase of model performance is observed for 0.4 0.4
0.4 0.38
Class C and D predictions. In other words, the use of a balancing
approach allows an improvement of the model performance for the
minority classes. 0.32
Fig. 3 compares model performance based on recall, precision, 0.3 0.3
and F1-score metrics following a regression strategy. Also here, a 0.27
0.26
high performance was achieved for Classes A and B identification
0.23
of rock slopes, but a very low response is observed for Class D.
AUS
When following a regression strategy, the application of a balanc- 0.2
ing approach, i.e., SMOTE sampling, had almost no effect on the
model’s performance.
Comparing both nominal classification and regression strategies 0.12
based on the AUS metric, Fig. 4 shows that approaching the prob- 0.1
lem as a nominal classification is slightly more effective than fol-
lowing a regression strategy. However, keeping in mind that in a 0.03
perfect model the AUS is 1, the highest value of 0.46 achieved
by ANN algorithm without balancing the database shows that 0.0
the model’s performance is still far away from being perfect. Fig. 4 ANN SVM ANN SVM
also shows that the ANN algorithm works better than SVM in EHC Algorithm
prediction of rock slopes.
Fig. 4. Comparison of model performance in EHC prediction of rock
Figs. 5 and 6 show the relation between observed and predicted
slopes, according to AUS metric
EHC values according to the best fits, following a nominal
© ASCE 04017088-6 J. Comput. Civ. Eng.
J. Comput. Civ. Eng., 2018, 32(2): 04017088
ANN :: OVERed - Nominal Classification SVM :: SMOTEd - Nominal Classification
1.00 1.00
0.75 0.75
EHC predicted EHC predicted
Frequency
Frequency
A A
0.50 B 0.50 B
C C
D D
Downloaded from ascelibrary.org by Arizona State Univ on 12/25/17. Copyright ASCE. For personal use only; all rights reserved.
0.25 0.25
0.00 0.00
A B C D A B C D
(a) EHC Experimental (b) EHC Experimental
Fig. 5. Models performance comparison according to a nominal classification strategy in EHC prediction of rock slopes: (a) ANN model following an
OVERed approach; (b) SVM model following a SMOTEd approach
classification and regression strategies, respectively. From its These results show that a deeper data analysis is required. For
analysis, we can observe that rock slopes of Class A are almost example, the number of variables taken as model attributes might
correctly identified. However, for Classes C and D, for which be too high. To check if a better generalization could be achieved
the expected probability of failure is higher, models show very using the most relevant inputs, the authors performed additional
great difficulty in identifying these classes accurately. From experimentation using a fast feature selection method that is based
the analysis in Fig. 5(a), only 25% of rock slopes classified on a sensitive analysis (Cortez and Embrechts 2013), which allows
as Class D were correctly identified, which represents a poor measurement of the relative importance of each input of a classi-
performance. fication or regression method. Taken as reference the ANN model
ANN :: Normal - Regression [1-2-4-10] SVM :: SMOTEd - Regression [1-2-4-10]
1.00 1.00
0.75 0.75
EHC Predicted
Frequency
Frequency
EHC Predicted
A
A
0.50 B 0.50
B
C
C
D
0.25 0.25
0.00 0.00
A B C D A B C D
(a) EHC Experimental (b) EHC Experimental
Fig. 6. Models performance comparison according to a regression strategy in EHC prediction of rock slopes: (a) ANN model with no resampling;
(b) SVM model following a SMOTEd approach
© ASCE 04017088-7 J. Comput. Civ. Eng.
J. Comput. Civ. Eng., 2018, 32(2): 04017088
ANN :: OVERed - Nominal Classification
with an OVERed approach and nominal classification, which
RS Actual Height 17.5
achieved the overall best performance in EHC prediction of rock
US Actual Height 15.4
slopes, a sensitivity analysis was applied to measure the rel-
US Actual Angle 10.1
evance of each input variable in EHC prediction of rock slopes.
RS Dangerous Trees Number 8.7
Fig. 7 shows the relative importance of the 20 most relevant var-
RS Actual Hyp 7.2
iables. Such sensitivity analysis shows that 16 (25% when com-
LS Actual Height 5.6
pared with the full 65-input model) of the most relevant inputs
US Actual Hyp 5.4
RS Azimuth
are responsible for 90% of the total input influence. Following
4.2
these results, the authors tested a new feature selection method in
Input Variable
Cess Safe 3.9
RS Root Balls Number 3.4
which all prediction models (including both strategies and the
LS Actual Angle 3.2
three resampling approaches) were retrained applying the same
LS Actual Hyp 1.9
sensitivity analysis procedure. Using F1-score as the comparison
Pot Failure On Slope 1.7
metric, Table 3 shows the difference between the full models
RS Height 1.5
(with 65 inputs) and feature selection ones (with the 16 most
Downloaded from ascelibrary.org by Arizona State Univ on 12/25/17. Copyright ASCE. For personal use only; all rights reserved.
Upper Slope 1.2 relevant inputs). The results from Table 3 show that the feature
RS Length 1 selection tends to present a lower performance, with lower
End Northing 0.8 F1-score values.
Drainage Problems 0.6
Cess Stand Off 0.6
LS Angle
Soil Cutting Slopes: EHC Prediction
0.6
0 5 10 15 For the study of soil cutting slopes, Table 4 shows and compares
Relative Importance (%) models performance in EHC prediction based on the metrics AUS,
recall, precision, and F1-score, following the nominal classification
Fig. 7. Relative importance bar plot of the 20 most relevant vari- and regression strategies as well as the SMOTE and oversampling
ables according to ANN model with OVERed and following approaches. Figs. 8 and 9 allow a better assessment of all models
a nominal classification strategy in EHC prediction of rock for EHC prediction of soil cutting slopes, comparing their perfor-
slopes mance based on recall, precision, and F1-score for each EHC class.
Following a nominal classification strategy, Fig. 8 shows that soil
Table 3. Difference between F1-Score Values of the Full Input Model (with 65 or 51 Variables, Respectively) with a Feature Selection Model That Included
the Most Relevant Inputs according to a Sensitivity Analysis Procedure
Rock slopes Soil cutting slopes
Strategy Model Approach A B C D A B C D
Classification ANN Normal 1.53 13.9 19.27 3.72 7.11 16.00 18.81 15.09
SMOTEd 2.38 7.51 3.15 5.26 9.15 12.25 23.60 19.04
OVERed 3.28 12.96 10.31 6.30 8.82 20.31 16.31 21.00
SVM Normal 0.90 13.34 7.31 N/A 7.44 15.26 28.56 3.49
SMOTEd 90.87 29.78 N/A N/A 6.23 13.78 −1.12 13.17
OVERed 0.91 −25.02 N/A N/A −0.49 −17.01 −8.51 −2.21
Regression ANN Normal 1.23 −2.20 14.46 5.81 10.00 9.40 17.25 25.82
SMOTEd 1.24 1.47 9.66 N/A 10.38 10.90 17.44 28.29
SVM Normal 0.74 3.65 0.18 N/A 6.49 14.74 1.69 N/A
SMOTEd −1.70 −0.56 2.34 N/A 0.72 11.79 17.27 N/A
Table 4. Metrics in EHC Prediction of Soil Cutting Slopes
Recall Precision F1-score
Strategy Model Approach AUS A B C D A B C D A B C D
Classification ANN Normal −0.05 90.36 64.01 45.61 14.53 87.23 60.36 59.21 42.57 88.77 62.13 51.53 21.67
SMOTEd −0.08 80.87 66.59 46.07 56.78 91.68 54.49 51.48 21.63 85.94 59.94 48.62 31.33
OVERed −0.04 82.05 58.75 63.77 38.41 91.13 55.02 49.77 33.71 86.35 56.82 55.91 35.91
SVM Normal −0.12 90.33 66.82 34.11 2.25 86.85 58.34 57.71 22.31 88.56 62.29 42.88 4.09
SMOTEd −0.27 73.65 79.27 24.96 24.88 91.50 47.90 53.53 30.81 81.61 59.72 34.05 27.53
OVERed −1.35 94.79 24.74 1.54 1.32 63.25 52.35 62.98 62.96 75.87 33.60 3.01 2.59
Regression ANN Normal −0.05 87.41 64.47 47.94 25.62 87.74 57.88 59.2 44.87 87.57 61.00 52.98 32.62
SMOTEd −0.03 85.34 68.68 48.53 23.64 89.32 57.00 60.23 54.08 87.28 62.30 53.75 32.90
SVM Normal −0.16 83.66 82.02 15.7 0.00 91.07 52.89 60.00 N/A 87.21 64.31 24.89 N/A
SMOTEd −0.27 66.30 85.38 33.77 0.62 93.43 45.81 66.37 66.67 77.56 59.63 44.76 1.23
Note: Best values are in bold.
© ASCE 04017088-8 J. Comput. Civ. Eng.
J. Comput. Civ. Eng., 2018, 32(2): 04017088
Approach: Normal SMOTEd OVERed
ANN SVM
91.68 91.13 94.79 91.5
90.36 87.23 88.77 85.94 90.33 86.85 88.56
86.35
80.87 82.05 81.61
75.87
75 73.65
63.25
50
A
25
79.27
75
64.01 66.59 66.82
Downloaded from ascelibrary.org by Arizona State Univ on 12/25/17. Copyright ASCE. For personal use only; all rights reserved.
60.36 62.13 59.94 62.29 59.72
58.75 56.82 58.34
54.49 55.02 52.35
50 47.9
B
33.6
25 24.74
Metric value
75
63.77 62.98
59.21 57.71
55.91 53.53
51.48 49.77 51.53 48.62
50 45.61 46.07
C
42.88
34.11 34.05
25 24.96
1.54 3.01
0
75
62.96
56.78
50
D
42.57
38.41 35.91
33.71 31.33 30.81
24.88 27.53
25 21.63 21.67 22.31
14.53
2.25 1.32 4.09 2.59
0
Recall Precision F1-score Recall Precision F1-score
Metric
Fig. 8. Model comparison based on recall, precision, and F1-score, according to a nominal classification strategy in EHC prediction of soil cutting
slopes
cutting slopes of Class A can be correctly identified, particularly regression strategies, it can be seen that the models’ perfor-
by the ANN model, with or without sampling. Also for Classes mances are indeed very interesting. Following a nominal classi-
B and C a promising performance is observed, with an F1-score fication strategy and sampling the database with the SMOTE
around 55%, in particular by the ANN algorithm. Concerning approach, the ANN algorithm is able to predict correctly approx-
Class D, although an F1-score lower than 36% was achieved, imately 57% of soil cutting slopes of Class D, which represents a
the obtained value for recall metric of approximately 57% shows very interesting performance if taken into account that this is the
a promising performance for Class D prediction according to minority class. For Class C, approximately 40% of the records
ANN algorithm. are correctly predicted. Moreover, when not predicted as Class C,
Following a regression strategy, the achieved results are they are classified as belonging to the closest class, that is, Classes
very similar to those obtained from a nominal classification B or D. This type of misclassification is also observed for Classes
strategy. The main differences are related with the effect of the A, B, and D, which can be interpreted as an advantage. Concern-
sampling approaches, which is not so relevant following a re- ing Classes A and B, the ANN model was also able to identify it
gression strategy, particularly for the minority classes. Compar- very accurately.
ing ANN and SVM algorithms, ANN works better (as observed Similarly to what has been done for rock slopes, also for soil
previously), particularly in the prediction of Classes C and D cutting slopes all models were retrained considering only 25%
slopes. of the most relevant variables (12 inputs) taken as reference the
Comparing both strategies (nominal classification and regres- ANN model following a SMOTEd approach and according to
sion), as illustrated in Fig. 10 which uses AUS as a comparison nominal classification strategy, which achieved the overall best
metric, the SVM algorithm was not able to learn properly EHC performance in EHC prediction of soil cutting slopes (Fig. 12).
prediction of soil cutting slopes. However, when looking to Fig. 11, As shown in Table 3, better performance is also achieved when
which shows the relation between observed and predicted EHC val- considering all 51 inputs when compared with the usage of the
ues according to the best fits, following nominal classification and 12 most relevant inputs.
© ASCE 04017088-9 J. Comput. Civ. Eng.
J. Comput. Civ. Eng., 2018, 32(2): 04017088
Approach: Normal SMOTEd
ANN SVM
89.32 91.07 93.43
87.41 85.34 87.74 87.57 87.28 83.66 87.21
77.56
75 66.3
50
A
25
82.02 85.38
75 64.47 68.68
61 62.3 64.31
57.88 57 59.63
52.89
50
B
45.81
Downloaded from ascelibrary.org by Arizona State Univ on 12/25/17. Copyright ASCE. For personal use only; all rights reserved.
25
Metric value
75 66.37
59.2 60.23 60
52.98 53.75
50 47.94 48.53
C
44.76
33.77
24.89
25 15.7
75 66.67
54.08
50
D
44.87
32.62 32.9
25.62 23.64
25
0 0.62 1.23
0
Recall Precision F1-score Recall Precision F1-score
Metric
Fig. 9. Models comparison based on recall, precision, and F1-score, according to a regression strategy in EHC prediction of soil cutting
slopes
Discussion
Approach: Normal SMOTEd OVERed
Classification Regression An attempt to predict EHC of both rock and soil cutting slopes
through the application of soft computing techniques, based on
0.0 -0.05 -0.04 -0.05
-0.03 information usually collected during routine inspections (visual in-
-0.08
-0.12
-0.16
formation) was presented. Unfortunately, so far the authors have
not found a model able to do such task with high efficiency.
-0.27 -0.27
Although for rock slopes the achieved performance is somewhat
far away from the expectation, some interesting results were ob-
served for soil cutting slopes, suggesting opportunities for pursuing
-0.5
further developments. Moreover, comparing what has been done so
far, namely the different strategies/approaches applied in order to
AUS
overcome the different particularities of the problem at hand, can
also give a good contribution toward further developments.
Comparing the results of rock and soil cutting slopes, for exam-
-1.0 ple based on the ANN model and using AUS as a comparison met-
ric (Figs. 4 and 10), better results were observed for rock slopes.
However, when taking into account the models’ capability of cor-
rectly identifying Class C and mainly Class D (higher probability of
-1.35 failure), the proposed models for soil cutting slopes were more ef-
fective (Figs. 5 and 11).
ANN SVM ANN SVM For both type of slopes analyzed in this study (rock and soil
Algorithm cuttings), high performance was achieved for Classes A and B.
Moreover, for Classes C and D of soil cutting slopes a very prom-
Fig. 10. Comparison of model performance in EHC prediction of soil
ising response was observed also. Concerning Classes C and D of
cutting slopes, according to AUS metric
rock slopes, poor performance was achieved. A possible explanation
© ASCE 04017088-10 J. Comput. Civ. Eng.
J. Comput. Civ. Eng., 2018, 32(2): 04017088
ANN :: SMOTEd - Nominal Classification ANN :: Normal - Regression [1-2-4-10]
1.00 1.00
0.75 0.75
EHC predicted EHC Predicted
Frequency
Frequency
A A
0.50 B 0.50 B
C C
D D
Downloaded from ascelibrary.org by Arizona State Univ on 12/25/17. Copyright ASCE. For personal use only; all rights reserved.
0.25 0.25
0.00 0.00
A B C D A B C D
(a) EHC Experimental (b) EHC Experimental
Fig. 11. ANN models performance comparison in EHC prediction of soil cutting slopes: (a) according to a nominal classification strategy and
following a SMOTEd approach; (b) according to a regression strategy and with no resampling
for this low performance only in the case of Classes C and D pre- this study the authors merged Classes D and E into a single class
diction of rock slopes could be related to the EHC class being as- named D because of modeling concerns). It would be expected that
sumed as representative of the real stability condition of each slope. most of the failures would occur in slopes of Classes C and mainly
Indeed, in analyzing the number of slope failures by EHC class for D. However, for rock slopes such behavior is not observed as shown
rock slopes, there are some indications that the classification attrib- in Fig. 13, which shows the annual probability of failure (normalized
uted to each rock slope could lack some accuracy as reported in the to the value in EHC Class A) for each EHC class. In fact, the number
work of Power et al. (2016), which used the same source of infor- of failures for each EHC class is almost constant from Classes A to
mation, but instead of four classes, they considered five classes (in D, particularly when compared with soil cuttings. For example, the
ANN :: SMOTEd - Nominal Classification 109
Slope type:
End Height 5.5 Soil Cuttings
Actual Height1 5.3 Rock Cuttings
Start Height 5.1
90
Actual Hyp3 4.3
Cutting Cess Drainage 4.2
Anual probability of failure
Max Height 3.9
Validate Cracking 3.7
Actual Height2 3.7
Input Variable
Composition Crest 3.6 60
Adjacent Catch Area 3.5 51
Actual Height3 3.3
Boulders Present 2.9
Min Height 2.6
Tree Cover 2.6
30
Validate Instability 2.5
Actual Crest Width 2.4
15
Actual Hyp2 2.4
Actual Slope To Track 2.3
4 3 3
Actual Hyp1 2.3 1 1 2 2
Catchment Surface 2.1
0
0 2 4 A B C D E
Relative Importance (%) Earthworks Hazard Category (EHC)
Fig. 12. Relative importance bar plot of the 20 most relevant variables Fig. 13. Annual probability of failure (normalized to the lowest EHC
according to ANN model with SMOTEd approach and following a category) for each EHC and each earthwork asset type (adapted from
nominal classification strategy in EHC prediction of soil cutting slopes Power et al. 2016)
© ASCE 04017088-11 J. Comput. Civ. Eng.
J. Comput. Civ. Eng., 2018, 32(2): 04017088
number of failures observed in Class C rock slopes is only twice as Applications and Theoretical Aspects, 10th Industrial Conf. on Data
high when compared to Class A. This identifies that the identified Mining, P. Perner, ed., Springer, Berlin, 572–583.
classes for rock slopes show a poor correlation with actual failures. Cortez, P., and Embrechts, M. (2013). “Using sensitivity analysis and visu-
Considering the high number of variables taken as model inputs, alization techniques to open black box data mining models.” Inf. Sci.,
225(Mar), 1–17.
which may be influencing the generalization performance of the
Das, S. K., Biswal, R. K., Sivakugan, N., and Das, B. (2011). “Classifica-
models, as well as the achieved results after applying a feature se-
tion of slopes and prediction of factor of safety using differential evo-
lection method based on an input sensitivity analysis, the authors lution neural networks.” Environ. Earth Sci., 64(1), 201–210.
intend to apply in future work a more sophisticated feature selection Gavin, K., and Xue, J. (2009). “Use of a genetic algorithm to perform
method. For instance, such a method could use a multiobjective reliability analysis of unsaturated soil slopes.” Geotechnique, 59(6),
evolutionary computation method that simultaneously maximizes 545–549.
prediction performance and minimizes the number of inputs used. Gomes Correia, A., Cortez, P., Tinoco, J., and Marques, R. (2013).
As a final observation, and considering the overall performance of “Artificial intelligence applications in transportation geotechnics.”
all models, it can be highlighted that soft computing algorithms, Geotech. Geol. Eng., 31(3), 861–879.
particularly ANN, present a better response for EHC prediction Hastie, T., Tibshirani, R., and Friedman, J. (2009). The elements of stat-
Downloaded from ascelibrary.org by Arizona State Univ on 12/25/17. Copyright ASCE. For personal use only; all rights reserved.
of soil cutting slopes than in rock slopes. istical learning: Data mining, inference, and prediction, 2nd Ed.,
Springer, New York.
Husein Malkawi, A. I., Hassan, W. F., and Abdulla, F. A. (2000). “Uncer-
tainty and reliability analysis applied to slope stability.” Struct. Saf.,
Acknowledgments 22(2), 161–187.
Javadi, A. A., Ahangar-Asr, A., Johari, A., Faramarzi, A., and Toll, D.
This work was supported by FCT, Fundação para a Ciência e a (2012). “Modelling stress-strain and volume change behaviour of
Tecnologia, within Institute for Sustainability and Innovation in unsaturated soils using an evolutionary based data mining technique,
Structural Engineering (ISISE), project UID/ECI/04029/2013 as an incremental approach.” Eng. Appl. Artif. Intell., 25(5), 926–933.
well Project Scope: UID/CEC/00319/2013 and through the post- Kang, F., Han, S., Salgado, R., and Li, J. (2015). “System probabilistic
doctoral grant fellowship with reference SFRH/BPD/94792/2013. stability analysis of soil slopes using Gaussian process regression with
This work was also partly financed by Fundo Europeu de Desen- Latin hypercube sampling.” Comput. Geotech., 63(Jan), 13–25.
volvimento Regional (FEDER) funds through the Competitivity Kang, F., and Li, J. (2016). “Artificial bee colony algorithm optimized sup-
Factors Operational Programme—COMPETE and by national port vector regression for system reliability analysis of slopes.” J. Com-
put. Civ. Eng., 10.1061/(ASCE)CP.1943-5487.0000514, 04015040.
funds through FCT within the scope of the project POCI-01-
Kang, F., Li, J.-S., and Li, J.-J. (2016a). “System reliability analysis of
0145-FEDER-007633. This work has been also supported by slopes using least squares support vector machines with particle swarm
COMPETE: POCI-01-0145-FEDER-007043. A special thanks optimization.” Neurocomputing, 209(Oct), 46–56.
goes to Network Rail that kindly make available the data (basic Kang, F., Li, J.-S., Wang, Y., and Li, J. (2017). “Extreme learning machine-
earthworks examination data and the Earthworks Hazard Condition based surrogate model for analyzing system reliability of soil slopes.”
scores) used in this work. Eur. J. Environ. Civ. Eng., 21(11), 1341–1362.
Kang, F., Xu, Q., and Li, J. (2016b). “Slope reliability analysis using sur-
rogate models via new support vector machines with swarm intelli-
References gence.” Appl. Math. Modell., 40(11), 6105–6120.
Kenig, S., Ben-David, A., Omer, M., and Sadeh, A. (2001). “Control of
Ahangar-Asr, A., Faramarzi, A., and Javadi, A. A. (2010). “A new approach properties in injection molding by neural networks.” Eng. Appl. Artif.
for prediction of the stability of soil and rock slopes.” Eng. Comput., Intell., 14(6), 819–823.
27(7), 878–893. Liao, S., Chu, P., and Hsiao, P. (2012). “Data mining techniques
Baía, L., and Torgo, L. (2015). “Forecasting the correct trading actions.” and applications. A decade review from 2000 to 2011.” Expert
Portuguese Conf. on Artificial Intelligence, Springer, Cham, Syst. Appl., 39(12), 11303–11311.
Switzerland, 560–571. Ling, C. X., and Li, C. (1998). “Data mining for direct marketing: Problems
Chawla, N. V., Bowyer, K. W., Hall, L. O., and Kegelmeyer, W. P. (2002). and solutions.” KDD’98 Proc., Fourth Int. Conf. on Knowledge Discov-
“SMOTE: Synthetic minority over-sampling technique.” J. Artif. Intel- ery and Data Mining, AAAI Press, New York, 73–79.
ligence Res., 16(1), 321–357. Lu, P., and Rosenbaum, M. (2003). “Artificial neural networks and grey
Cheng, M.-Y., and Hoang, N.-D. (2016). “Slope collapse prediction using systems for the prediction of slope stability.” Nat. Hazard., 30(3),
Bayesian framework with k-nearest neighbor density estimation: Case 383–398.
study in Taiwan.” J. Comput. Civ. Eng., 10.1061/(ASCE)CP.1943-5487 Pinheiro, M., et al. (2015). “A new empirical system for rock slope stability
.0000456, 04014116. analysis in exploitation stage.” Int. J. Rock Mech. Min. Sci., 76(Jun),
Cheng, M.-Y., Roy, A. F., and Chen, K.-L. (2012a). “Evolutionary risk 182–191.
preference inference model using fuzzy support vector machine for road Pourkhosravani, A., and Kalantari, B. (2011). “A review of current methods
slope collapse prediction.” Expert Syst. Appl., 39(2), 1737–1746. for slope stability evaluation.” Electr. J. Geotech. Eng., 16(Jan),
Cheng, M.-Y., Wu, Y.-W., and Chen, K.-L. (2012b). “Risk preference based 1245–1254.
support vector machine inference model for slope collapse prediction.” Power, C., Mian, J., Spink, T., Abbott, S., and Edwards, M. (2016).
Autom. Constr., 22(Mar), 175–181. “Development of an evidence-based geotechnical asset management
Cherkassky, V., and Ma, Y. (2004). “Practical selection of SVM parameters policy for Network Rail, Great Britain.” Procedia Eng., 143(Sep),
and noise estimation for SVM regression.” Neural Networks, 17(1), 726–733.
113–126. Safarzadegan Gilan, S., Bahrami Jovein, H., and Ramezanianpour, A.
Chou, J.-S., Yang, K.-H., and Lin, J.-Y. (2016). “Peak shear strength of (2012). “Hybrid support vector regression—Particle swarm optimiza-
discrete fiber-reinforced soils computed by machine learning and meta- tion for prediction of compressive strength and RCPT of concretes con-
ensemble methods.” J. Comput. Civ. Eng., 10.1061/(ASCE)CP.1943- taining metakaolin.” Constr. Build. Mater., 34(Sep), 321–329.
5487.0000595, 04016036. Sakellariou, M., and Ferentinou, M. (2005). “A study of slope stability pre-
Cortes, C., and Vapnik, V. (1995). “Support-vector networks.” Mach. diction using neural networks.” Geotech. Geol. Eng., 23(4), 419–445.
Learn., 20(3), 273–297. Sivakumar Babu, G., and Murthy, D. (2005). “Reliability analysis of
Cortez, P. (2010). “Data mining with neural networks and support vector unsaturated soil slopes.” J. Geotech. Geoenviron. Eng., 10.1061
machines using the r/rminer tool.” Advances in Data Mining: /(ASCE)1090-0241(2005)131:11(1423), 1423–1428.
© ASCE 04017088-12 J. Comput. Civ. Eng.
J. Comput. Civ. Eng., 2018, 32(2): 04017088
Smola, A., and Schölkopf, B. (2004). “A tutorial on support vector Tinoco, J., Gomes Correia, A., and Cortez, P. (2014b). “Support vector
regression.” Stat. Comput., 14(3), 199–222. machines applied to uniaxial compressive strength prediction of jet
Suchomel, R., et al. (2010). “Comparison of different probabilistic methods grouting columns.” Comput. Geotech., 55(Jan), 132–140.
for predicting stability of a slope in spatially variable c–φ soil.” Comput. Torgo, L., Branco, P., Ribeiro, R., and Pfahringer, B. (2015). “Resampling
Geotech., 37(1), 132–140. strategies for regression.” Expert Syst., 32(3), 465–476.
Suman, S., Khan, S., Das, S., and Chand, S. (2016). “Slope stability analysis Venables, W., and Ripley, B. (2003). Modern applied statistics with S, 2nd
using artificial intelligence techniques.” Nat. Hazard., 84(2), 727–748. Ed., Springer, Heidelberg.
R Core Team. (2009). R: A language and environment for statistical Wang, H., Xu, W., and Xu, R. (2005). “Slope stability evaluation using
computing, R Foundation for Statistical Computing, Vienna, Austria. back propagation neural networks.” Eng. Geol., 80(3), 302–315.
Tinoco, J., Gomes Correia, A., and Cortez, P. (2014a). “A novel approach to Yao, X., Tham, L., and Dai, F. (2008). “Landslide susceptibility mapping
predicting young’s modulus of jet grouting laboratory formulations over based on support vector machine: A case study on natural slopes of
time using data mining techniques.” Eng. Geol., 169(Feb), 50–60. Hong Kong, China.” Geomorphology, 101(4), 572–582.
Downloaded from ascelibrary.org by Arizona State Univ on 12/25/17. Copyright ASCE. For personal use only; all rights reserved.
© ASCE 04017088-13 J. Comput. Civ. Eng.
J. Comput. Civ. Eng., 2018, 32(2): 04017088
Вам также может понравиться
- Deterioration Prediction of Building ComponentsДокумент9 страницDeterioration Prediction of Building ComponentsAhmad AndiОценок пока нет
- Unsupervised Lane-Change Identification For On-RamДокумент8 страницUnsupervised Lane-Change Identification For On-RamErickson OngОценок пока нет
- Pavement Health Monitoring System Based On An Embedded Sensing NetworkДокумент8 страницPavement Health Monitoring System Based On An Embedded Sensing NetworkdeepaОценок пока нет
- Field Monitoring of RC-Structures Under Dynamic Loading Using Distributed Fiber-Optic SensorsДокумент10 страницField Monitoring of RC-Structures Under Dynamic Loading Using Distributed Fiber-Optic SensorsFaseen ibnu Ameer AhasenОценок пока нет
- Buildings 12 00833Документ24 страницыBuildings 12 00833vincenzo.gattulliОценок пока нет
- Zhan 2020Документ17 страницZhan 2020ac.castro18Оценок пока нет
- Network-Level Pavement Structural EvaluationДокумент7 страницNetwork-Level Pavement Structural Evaluationsaksham dixitОценок пока нет
- Wu 2013Документ10 страницWu 2013Syed MubashirhussainОценок пока нет
- Application of Neural Network For Selection of Airport Rigid Pavement Maintenance StrategiesДокумент8 страницApplication of Neural Network For Selection of Airport Rigid Pavement Maintenance Strategieschirag dumaniyaОценок пока нет
- Paper 13Документ9 страницPaper 13Ali Asghar Pourhaji KazemОценок пока нет
- Urban Change Detection Using CNNsДокумент4 страницыUrban Change Detection Using CNNsNegar TavasoliОценок пока нет
- 2306.04288v3Документ22 страницы2306.04288v3AbdulazizОценок пока нет
- Are They Going To Cross? A Benchmark Dataset and Baseline For Pedestrian Crosswalk BehaviorДокумент8 страницAre They Going To Cross? A Benchmark Dataset and Baseline For Pedestrian Crosswalk BehaviorSoulayma GazzehОценок пока нет
- vehicle detection 1Документ15 страницvehicle detection 1vinasingh6200Оценок пока нет
- Oz Aslan 2017Документ8 страницOz Aslan 2017Cevallos RamirezОценок пока нет
- 1 20 20effects 20of 20dataset 20characteristics 20on 20the 20performance 20of 20fatigue 20detectionДокумент18 страниц1 20 20effects 20of 20dataset 20characteristics 20on 20the 20performance 20of 20fatigue 20detectioncstoajfuОценок пока нет
- A Location-Velocity-Temp SYLLДокумент14 страницA Location-Velocity-Temp SYLLNguyễn Thái HọcОценок пока нет
- Survey FaziletДокумент24 страницыSurvey FaziletNabila LabraouiОценок пока нет
- Traffic Data Collection Under Mixed Traffic Conditions Using Video Image ProcessingДокумент9 страницTraffic Data Collection Under Mixed Traffic Conditions Using Video Image ProcessingDamon SОценок пока нет
- Vijayalakshmi.G-AI Based Rush Collision Prevention in RailwaysДокумент9 страницVijayalakshmi.G-AI Based Rush Collision Prevention in RailwaysAnil KumarОценок пока нет
- 1 s2.0 S1568494620308450 MainДокумент10 страниц1 s2.0 S1568494620308450 MainNazrul HaqemОценок пока нет
- LANE Detection - 2Документ15 страницLANE Detection - 2Getz23Оценок пока нет
- Application of Neural Networks in Evaluation of Railway Track Quality ConditionДокумент10 страницApplication of Neural Networks in Evaluation of Railway Track Quality Conditionnikhil pillaiОценок пока нет
- A machine-learning benchmark for facies classificationДокумент13 страницA machine-learning benchmark for facies classificationtempforapps2023Оценок пока нет
- Remotesensing 13 00089 v2Документ23 страницыRemotesensing 13 00089 v2Varun GoradiaОценок пока нет
- Convex Optimization for Efficiently Generating Dynamically Feasible TrajectoriesДокумент68 страницConvex Optimization for Efficiently Generating Dynamically Feasible TrajectoriessubmarinoaguadulceОценок пока нет
- Reliability Engineering and System Safety: Andre D. Orcesi, Christian F. CremonaДокумент14 страницReliability Engineering and System Safety: Andre D. Orcesi, Christian F. CremonaSai RamОценок пока нет
- 2017 An Incremental Framework For Video-Based Traffic Sign Detection Tracking and RecognitionДокумент12 страниц2017 An Incremental Framework For Video-Based Traffic Sign Detection Tracking and RecognitionFilip Antonio PavlinićОценок пока нет
- Traffic Congestion Detection Using Deep LearningДокумент3 страницыTraffic Congestion Detection Using Deep LearningEditor IJTSRDОценок пока нет
- MappingДокумент16 страницMappingz2412952949Оценок пока нет
- Autonomous CarДокумент14 страницAutonomous CarJaya KumarОценок пока нет
- Robotics and Autonomous Systems: Borja Bovcon Rok Mandeljc Janez Perš Matej KristanДокумент13 страницRobotics and Autonomous Systems: Borja Bovcon Rok Mandeljc Janez Perš Matej KristanavatorОценок пока нет
- Fawaz TITS12Документ16 страницFawaz TITS12Mauricio José Il-PanaderoОценок пока нет
- A Comparison of Deep Learning Architectures For Spacecraft Anomaly DetectionДокумент11 страницA Comparison of Deep Learning Architectures For Spacecraft Anomaly DetectionlarrylynnmailОценок пока нет
- Ocean Engineering: Demetrious T. Kutzke, James B. Carter, Benjamin T. HartmanДокумент15 страницOcean Engineering: Demetrious T. Kutzke, James B. Carter, Benjamin T. Hartmanyanbiao liОценок пока нет
- Application of An Artificial Neural Network in Pavement Management Sistem Ö4Документ9 страницApplication of An Artificial Neural Network in Pavement Management Sistem Ö4Fatih KarataşОценок пока нет
- Liu Zhang 2019 Deep Learning Based Brace Damage Detection For Concentrically Braced Frame Structures Under SeismicДокумент14 страницLiu Zhang 2019 Deep Learning Based Brace Damage Detection For Concentrically Braced Frame Structures Under SeismicMOHAMAD ALHASANОценок пока нет
- Efficient Infrastructure Restoration Strategies Using The Recovery OperatorДокумент16 страницEfficient Infrastructure Restoration Strategies Using The Recovery OperatorHimadri Sen GuptaОценок пока нет
- Using Artificial Neural Network-Self-Organising Map For Data Clustering of Marine Engine Condition Monitoring ApplicationsДокумент9 страницUsing Artificial Neural Network-Self-Organising Map For Data Clustering of Marine Engine Condition Monitoring Applicationshideki hidekiОценок пока нет
- Automatic Yield-Line Analysis of Practical Slab Configurations Via Discontinuity Layout OptimizationДокумент17 страницAutomatic Yield-Line Analysis of Practical Slab Configurations Via Discontinuity Layout OptimizationSolomon AhimbisibweОценок пока нет
- Artificial Intelligence Algorithms For Power Allocation in High Throughput Satellites A ComparisonДокумент15 страницArtificial Intelligence Algorithms For Power Allocation in High Throughput Satellites A ComparisonWhiteRiverОценок пока нет
- 11 (2020) Yuan Li - Visual Object Tracking With Adaptive Structural Convolutional NetworkДокумент11 страниц11 (2020) Yuan Li - Visual Object Tracking With Adaptive Structural Convolutional Networkmat felОценок пока нет
- Dimitrakopoulos 2010Документ8 страницDimitrakopoulos 2010BiniОценок пока нет
- Traffic Sign BaseДокумент13 страницTraffic Sign BaseMadhanDhonianОценок пока нет
- Data Driven Integrated Sensing and Communication Recent Advances Challenges and Future ProspectsДокумент14 страницData Driven Integrated Sensing and Communication Recent Advances Challenges and Future ProspectsDr-Mohammed RihanОценок пока нет
- Ge Et Al 2023 A Benchmark Data Set For Vision Based Traffic Load Monitoring in A Cable Stayed BridgeДокумент7 страницGe Et Al 2023 A Benchmark Data Set For Vision Based Traffic Load Monitoring in A Cable Stayed BridgeTONY VILCHEZ YARIHUAMANОценок пока нет
- Al Sheikh 2014Документ24 страницыAl Sheikh 2014Siwar LachihebОценок пока нет
- Simplified Probabilistic Model For Maximum Traffic Load From Weigh-In-Motion DataДокумент15 страницSimplified Probabilistic Model For Maximum Traffic Load From Weigh-In-Motion DataFrancesco GinesiОценок пока нет
- Multiobjective Stochastic Inoperability Decision Tree For Infrastructure PreparednessДокумент12 страницMultiobjective Stochastic Inoperability Decision Tree For Infrastructure PreparednesstaharОценок пока нет
- 2021 A Review of Image Based Pavement Crack Detection AlgorithmsДокумент7 страниц2021 A Review of Image Based Pavement Crack Detection Algorithmsgandhara11Оценок пока нет
- Research PaperДокумент21 страницаResearch PaperSyed SafwanОценок пока нет
- Matecconf Tran-Set2019 08003Документ5 страницMatecconf Tran-Set2019 08003saksham dixitОценок пока нет
- Automatic Yield-Line Analysis of Practical Slab Configurations Via Discontinuity Layout OptimizationДокумент17 страницAutomatic Yield-Line Analysis of Practical Slab Configurations Via Discontinuity Layout OptimizationRobertson ArthurОценок пока нет
- Analysis of Machine Foundation Vibrations State of The Art by G. Gazetas (1983)Документ41 страницаAnalysis of Machine Foundation Vibrations State of The Art by G. Gazetas (1983)thanhtrung87Оценок пока нет
- Wang - Robust Multi-Feature Learning For Skeleton-Based Action RecognitionДокумент13 страницWang - Robust Multi-Feature Learning For Skeleton-Based Action Recognitionmasoud kiaОценок пока нет
- Cite 256 Action Recognition Based On Joint Trajectory Maps Using Convolutional Neural Networks ACM M 2017Документ5 страницCite 256 Action Recognition Based On Joint Trajectory Maps Using Convolutional Neural Networks ACM M 2017姜华为Оценок пока нет
- (Asce) 0733-9445 (2005) 131 4Документ11 страниц(Asce) 0733-9445 (2005) 131 4Sohini MishraОценок пока нет
- Tracking with Particle Filter for High-dimensional Observation and State SpacesОт EverandTracking with Particle Filter for High-dimensional Observation and State SpacesОценок пока нет
- A Study of The Correlation Potential of The Optimum Moisture ContДокумент174 страницыA Study of The Correlation Potential of The Optimum Moisture ContzeekoОценок пока нет
- 10 - Simple Mathematical Approach For Granular FillДокумент9 страниц10 - Simple Mathematical Approach For Granular Fillahmed-12345Оценок пока нет
- Happiness Is An Emotion and Something You Decided For YourselfДокумент1 страницаHappiness Is An Emotion and Something You Decided For YourselfTita Kartika DewiОценок пока нет
- Sieve Analysis of Fine and Coarse Aggregates: Standard Test Method ForДокумент5 страницSieve Analysis of Fine and Coarse Aggregates: Standard Test Method ForAkkshay ChadhaОценок пока нет
- Astm D 7263 09 PDFДокумент7 страницAstm D 7263 09 PDFMuhammad AsifОценок пока нет
- Print Tugas 4Документ1 страницаPrint Tugas 4Tita Kartika DewiОценок пока нет
- MSE WallДокумент69 страницMSE WallTita Kartika DewiОценок пока нет
- Terzaghi1958 PDFДокумент30 страницTerzaghi1958 PDFTita Kartika DewiОценок пока нет
- ASTM.D2850-03.Triaxial UU PDFДокумент6 страницASTM.D2850-03.Triaxial UU PDFFernando Navarro100% (1)
- Desain Sump It PDFДокумент1 страницаDesain Sump It PDFTita Kartika DewiОценок пока нет
- Peat Samples by Laboratory Testing: Standard Classification ofДокумент3 страницыPeat Samples by Laboratory Testing: Standard Classification ofJohnCarlosGilОценок пока нет
- Comparison of 2D and 3D Seepage Model Results For Excavation Near Levee ToeДокумент4 страницыComparison of 2D and 3D Seepage Model Results For Excavation Near Levee ToeTita Kartika DewiОценок пока нет
- Compaction 1Документ9 страницCompaction 1Tita Kartika DewiОценок пока нет
- The Physics of A Stove-Top Espresso Machine: Meluca Crescent, Hornsby Heights, NSW, Australia 2077Документ8 страницThe Physics of A Stove-Top Espresso Machine: Meluca Crescent, Hornsby Heights, NSW, Australia 2077Tita Kartika DewiОценок пока нет
- 1462 001 PDFДокумент7 страниц1462 001 PDFTita Kartika DewiОценок пока нет
- The Effects of Different Compaction Energy On Geotechnical Properties of Kaolin and LateriteДокумент8 страницThe Effects of Different Compaction Energy On Geotechnical Properties of Kaolin and LateriteTita Kartika DewiОценок пока нет
- Image Processing CLO - Segmentation ThresholdingДокумент2 страницыImage Processing CLO - Segmentation ThresholdingShridhar DoddamaniОценок пока нет
- 20l 爆炸鋼球Документ56 страниц20l 爆炸鋼球Cao Chen-RuiОценок пока нет
- Quotations Are Commonly Printed As A Means of Inspiration and To Invoke Philosophical Thoughts From The ReaderДокумент24 страницыQuotations Are Commonly Printed As A Means of Inspiration and To Invoke Philosophical Thoughts From The ReaderC SОценок пока нет
- An Online Mobile Shopping Application For Uchumi Supermarket in UgandaДокумент9 страницAn Online Mobile Shopping Application For Uchumi Supermarket in UgandaKIU PUBLICATION AND EXTENSIONОценок пока нет
- AxiomV Custom Report DesignerДокумент33 страницыAxiomV Custom Report DesignerDiego Velarde LaraОценок пока нет
- RTC Device DriverДокумент3 страницыRTC Device Driverapi-3802111Оценок пока нет
- Sitecore Experience Platform 8.0Документ456 страницSitecore Experience Platform 8.0Pushpaganan NОценок пока нет
- NWDISystemДокумент16 страницNWDISystemYvette CamposОценок пока нет
- Canteen Management SystemДокумент13 страницCanteen Management SystemKay KaraychayОценок пока нет
- Bcs 031Документ25 страницBcs 031rsadgaОценок пока нет
- Programming Languages ERDДокумент1 страницаProgramming Languages ERDkosaialbonniОценок пока нет
- Compiler Design: Hoor FatimaДокумент19 страницCompiler Design: Hoor FatimaHoor FatimaОценок пока нет
- 01 SIRIUS-SENTRON-SIVACON LV1 Complete English 2010 PDFДокумент1 517 страниц01 SIRIUS-SENTRON-SIVACON LV1 Complete English 2010 PDFRoderich Alexander Deneken PalmaОценок пока нет
- How To Create Composite WallsДокумент7 страницHow To Create Composite WallsfloragevaraОценок пока нет
- CSTP BrochureДокумент5 страницCSTP Brochureapi-3738664Оценок пока нет
- Business: Powerpoint Template Designed by Mr. Cai With Microsoft Office 2016Документ20 страницBusiness: Powerpoint Template Designed by Mr. Cai With Microsoft Office 2016daisyОценок пока нет
- CV Software Tester Nguyen Thi Ngoc ThuyДокумент5 страницCV Software Tester Nguyen Thi Ngoc ThuyNguyễn ThiệnОценок пока нет
- 4b Zakia Mufida A1g021064 Uji T TestДокумент1 страница4b Zakia Mufida A1g021064 Uji T TestZakia MufidaОценок пока нет
- JESS Functions and I/O TutorialДокумент5 страницJESS Functions and I/O TutorialolivukovicОценок пока нет
- CSE-101 3 Assignment 2010 Foundation of Computting Submitted ToДокумент3 страницыCSE-101 3 Assignment 2010 Foundation of Computting Submitted ToVardhan MahendruОценок пока нет
- Nemo Handy and Walker Air 3.40Документ16 страницNemo Handy and Walker Air 3.40miro1964Оценок пока нет
- FxExtractor OperationДокумент6 страницFxExtractor OperationMirevStefanОценок пока нет
- CIS552 Indexing and Hashing 1Документ56 страницCIS552 Indexing and Hashing 1Vinay VarmaОценок пока нет
- DSP Unit 5Документ34 страницыDSP Unit 5Maggi FelixОценок пока нет
- Man Gm4300navi PMP enДокумент31 страницаMan Gm4300navi PMP enPatrick KiritescuОценок пока нет
- William Fleming V LVMPD (2023)Документ65 страницWilliam Fleming V LVMPD (2023)BuskLVОценок пока нет
- Frequent CHECK TIMED OUT Status of Listener and DB Resources (Doc ID 1608197.1)Документ2 страницыFrequent CHECK TIMED OUT Status of Listener and DB Resources (Doc ID 1608197.1)elcaso34Оценок пока нет
- Vita Template PDFДокумент2 страницыVita Template PDFMoath AlhajiriОценок пока нет
- Java Lab AssignmentsДокумент12 страницJava Lab AssignmentsPradeep Tiwari0% (1)
- Chapter 6 - Implementing Public Key Infrastructure Flashcards - QuizletДокумент14 страницChapter 6 - Implementing Public Key Infrastructure Flashcards - QuizletRapholo LU FU NOОценок пока нет