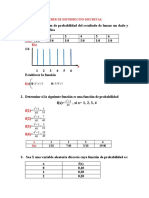
Академический Документы
Профессиональный Документы
Культура Документы
Apuntes de Probabilidad y Muestreo PDF
Загружено:
pedro gilОригинальное название
Авторское право
Доступные форматы
Поделиться этим документом
Поделиться или встроить документ
Этот документ был вам полезен?
Это неприемлемый материал?
Пожаловаться на этот документАвторское право:
Доступные форматы
Apuntes de Probabilidad y Muestreo PDF
Загружено:
pedro gilАвторское право:
Доступные форматы
2
CONTENIDO
Capítulo 0 Distribución de probabilidad Normal
Capítulo 1 Introducción a la Estadística Inferencial
1.1 Tipos de Diseño de Muestreo
1.1.1 Muestreo probabilístico
1.1.2 Muestreo no probabilístico
1.2 Distribuciones muestrales
1.3 Tipos de estimadores
Capítulo 2 Intervalo de Confianza
2.1Para la Media
2.2 Para la proporción
2.3 Para la diferencia de Medias (Muestras independientes)
2.4 Para la Media de las diferencias
2.5 Para la diferencia de proporciones
Capítulo 3 Pruebas de hipótesis
Capítulo 4 Análisis de Varianza
Capítulo 5 Regresión
Capítulo 6 Análisis de Datos categóricos
UJTL_DCB_APUNTES DE ESTADISTICA INFERENCIAL_ MARA
3
CAPITULO 0
Revisemos un concepto aprendido en el curso inmediatamente anterior de estadística descriptiva y
probabilidad, sobre las distribuciones de probabilidad.
Modelo Identificación, Argumentación, Formulación, Resolución e Interpretación para el análisis e
interpretación de un problema de distribuciones de probabilidad
Analizar un problema aplicado relacionado con distribuciones de probabilidad requiere de varias
destrezas que, se supone, los estudiantes deben aprender para poder enfrentar con éxito un curso de
estadística. Estas destrezas no necesariamente se hacen explícitas por los profesores de estadística o
por lo libros de texto, y el hecho de no tener claridad sobre estas puede ser un obstáculo en el
aprendizaje. Pensando en una ayuda para aprender a analizar e interpretar un problema de
distribuciones de probabilidad, se muestra a continuación un método de cinco pasos: Identificación,
Argumentación, Formulación, Resolución e Interpretación ( IAFRI). Lo han propuesto los profesores Miguel
Peralta Blanco y Leandro González Támara para hacer explícitas las habilidades que se requieren al
enfrentar un problema de aplicación de las distribuciones de probabilidad. Esta metodología ha venido
siendo afinada durante los años que los profesores han impartido esta asignatura y ha sido de valiosa
ayuda para aquellos estudiantes con mayores dificultades en el aprendizaje de la estadística. El método
consiste de las siguientes cinco etapas:
Identificación
a. Identifique la variable aleatoria asociada con el contexto del problema.
b. Seleccione la distribución de probabilidad adecuada.
c. Determine los parámetros de la distribución de probabilidad en el contexto del problema.
Argumentación
En el caso binomial En el caso Poisson
a. Explique que se trata de una variable a. Explique que se trata de una variable
aleatoria discreta. aleatoria discreta.
b. Justifique por qué los ensayos son b. Describa por qué el promedio permanece
independientes. constante a largo plazo.
c. Plantee qué significa el éxito y el fracaso c. Argumente por qué los eventos ocurren de
en el contexto del problema. forma independiente.
d. Argumente por qué la probabilidad
permanece constante en cada uno de los
ensayos.
En el caso hipergeométrica En el caso normal
a. Explique que se trata de una variable a. Explique que se trata de una variable
aleatoria discreta. aleatoria continua
b. Justifique por qué los ensayos no son b. Argumente por qué se puede suponer que
independientes. la variable es acampanada
c. Plantee qué significa el éxito y el fracaso
en el contexto del problema
d. Argumente por qué la probabilidad no
permanece constante.
Formulación
Traduzca la situación planteada a los modelos de distribuciones de probabilidad, es decir, utilice un
modelo matemático simplificado para expresar el cuestionamiento dado en el contexto del problema.
Resolución
UJTL_DCB_APUNTES DE ESTADISTICA INFERENCIAL_ MARA
4
Encuente mediante una tabla de percentiles de una distribución de probabilidad o en una aplicación el
resultado numérico de la formulación anterior.
Interpretación
Escriba el significado obtenido en la resolución en los términos asociados con el contexto del problema.
A continuación, se muestra el modelo de cómo abordar un problema de aplicación de las distribuciones
de probabilidad utilizando la metodología IAFRI.
Explicación del método IAFRI para una variable de tipo binomial
Problema: el 94% de los estudiantes de una universidad afirman que ellos nunca han hecho trampa en
un examen. Si dicha universidad tiene un número muy grande de estudiantes y se seleccionan 40 de
ellos aleatoriamente, encuentre e interprete la probabilidad de que el número de estudiantes que han
hecho trampa en un examen sea (a) exactamente la mitad, (b) más de dos, y (c) al menos la mitad.
Identificación
a. La variable aleatoria es X:= “número de estudiantes que han hecho trampa de una muestra de
40”.
b. La distribución de probabilidad adecuada a este problema es la binomial.
c. Los parámetros son n=40, p=0.06.
Argumentación
a. La variable aleatoria es discreta, porque toma un número finito de resultados, números entre 0 y
40.
b. Lo ensayos son independientes, debido a que el enunciado afirma que la muestra se toma de
un número muy grande de estudiantes.
c. En este contexto, el éxito es que el estudiante seleccionado haga trampa, y, el fracaso, que no.
d. La probabilidad permanece constante en cada uno de los ensayos, ya que, aunque si la
selección se hace sin reposición, la probabilidad de éxito no cambia significativamente debido a
que la población muestreada es grande.
Formulación
40
Aquí la probabilidad puede expresarse así: 𝑃(𝑋 = 𝑥) = ( ) 0.06𝑥 0.9440−𝑥 , por lo tanto la probabilidad
𝑥
de que el número de estudiantes que hayan hecho trampa en un examen sea (a) exactamente la mitad
es 𝑃(𝑋 = 20). La probabilidad de que sea (b) más de dos es 𝑃(𝑋 > 2). La probabilidad de que sea (c) al
menos la mitad es 𝑃(𝑋 ≥ 20).
Resolución
𝑃(𝑋 = 20) = 0
𝑃(𝑋 > 2) = 0.43350
𝑃(𝑋 ≥ 20) = 0
Interpretación
La probabilidad de que el número de estudiantes que hayan hecho trampa en un examen sea
exactamente la mitad es cero, esto es, es un evento imposible. La probabilidad de que el número de
estudiantes que hayan hecho trampa en un examen sea más de dos es 0,43350. La probabilidad de que
el número de estudiantes que hayan hecho trampa en un examen sea al menos la mitad es cero.
UJTL_DCB_APUNTES DE ESTADISTICA INFERENCIAL_ MARA
5
Explicación del método IAFRI para una variable de tipo Poisson
Problema: si una gota de agua se pone en una platina y se examina bajo un microscopio, el número 𝑋
de bacterias coliformes presentes se ha encontrado que tiene una distribución de probabilidad de
Poisson. Suponga que la cantidad máxima permisible por muestra de agua para este tipo de bacteria es
cinco. Si la cantidad promedio en su suministro de agua es de 3,8 coliformes por muestra y usted prueba
una sola muestra, ¿es probable que la cantidad exceda la cantidad máxima permisible? Explique.
Identificación
a. La variable aleatoria es: X:= “número de bacterias coliformes presentes en una muestra de
agua”.
b. La distribución de probabilidad adecuada a este problema es Poisson porque el enunciado lo
afirma.
c. El parámetro de la distribución es 𝜆 = 3.8
Argumentación
a. Es una variable aleatoria discreta, ya que, aunque toma infinitos valores enteros entre 0 e
infinito, estos son contables.
b. El promedio de bacterias por muestra se supone constante porque se puede asumir que las
bacterias se distribuyen uniformemente en el agua examinada.
c. Los eventos ocurren de forma independiente, debido a que el número de bacterias en una
muestra no tiene efecto en los de las demás.
Formulación
ℯ −3.8
Aquí la probabilidad puede expresarse así: 𝑃(𝑋 = 𝑥) = . Por lo tanto, la probabilidad de que el
𝑥!
número de bacterias en una muestra exceda la máxima permisible es 𝑃(𝑋 > 5).
Resolución
𝑃(𝑋 > 5) = 0.18444
Interpretación
La probabilidad de que el número de bacterias en una muestra exceda la máxima permisible es 0,18444.
Explicación del método IAFRI para una variable de tipo hipergeométrica
Problema: en un grupo de 10 personas hay cuatro mujeres. Si se seleccionan al azar tres personas,
determine la probabilidad de no escoger mujeres.
Identificación
a. La variable aleatoria asociada a esta situación es X:= “el número de mujeres seleccionadas en la
muestra de tres personas”.
b. Esta es una variable aleatoria hipergeométrica.
c. Los parámetros de la distribución son N=10, n=3, C=4
Argumentación
a. Esta es una variable aleatoria discretea porque toma un número finito de valores: 0, 1, 2 y 3.
b. Los ensayos no son independientes porque lo natural es seleccionar a las personas sin hacer
reposición.
c. Para esta variable, un éxito significa seleccionar una mujer, y un fracaso, a un hombre.
d. La probabilidad de seleccionar a una mujer no permanece constante porque tras la elección de
cada elemento de la muestra se modifica el número de personas restantes y posiblemente el
número de mujeres.
Formulación
𝑃(𝑋 = 0)
UJTL_DCB_APUNTES DE ESTADISTICA INFERENCIAL_ MARA
6
Resolución
𝑃(𝑋 = 0) = 0.16667
Interpretación
Cuando se toma una muestra de tres personas de un grupo de 10, siendo cuatro de ellas mujeres, la
probabilidad de no elegir mujeres es de 0.16667.
Explicación del método IAFRI para una variable de tipo normal
Problema: el peso de paquetes de zanahorias está normalmente distribuido con una media de 500
gramos y una desviación estándar de 8 gramos. El 8,5% de los paquetes son demasiado pesados y
deben ser reempacados. ¿Cuál es el paquete más pesado de zanahorias que no debe ser reempacado?
Interprete.
Identificación
a. La variable aleatoria es X:= “peso de un paquete de zanahorias de 500 gr”.
b. La variable aleatoria adecuada para este problema es la normal.
c. Los parámetros de la distribución son 𝜇 = 500 y 𝜎 = 8.
Argumentación
a. El peso es una variable aleatoria continua porque puede tomar un número infinito de valores en
cualquier intervalo razonable para la variable.
b. Los pesos de los paquetes de zanahoria pueden ser acampanados, debido a que la mayoría
tendrá un peso cercano a su media y se puede suponer que con muy poca frecuencia se
encontrarán paquetes con un peso muy por debajo o muy por encima de los 500 gr.
Formulación
Del enunciado se sabe que Z= 1,37 y es necesario encontrar X
Resolución
𝑋−500
Al estandarizar la variable aleatoria se tiene = 1,37 y por lo tanto X= 510,96.
8
Interpretación
En conclusión, el paquete más pesado de zanahorias que no debe ser reempacado pesa 510,96 libras.
Los paquetes con un peso superior deben ser reempacados.
Multitud de variables aleatorias continuas siguen una distribución normal o aproximadamente normal. Una
de sus características más importantes es que casi cualquier distribución de probabilidad, tanto discreta
como continua, se puede aproximar por una normal bajo ciertas condiciones. La distribución de
probabilidad normal y la curva normal que la representa, tienen las siguientes características:
• La curva normal tiene forma de campana y un solo pico en el centro de la distribución. De esta manera, la
media aritmética, la mediana y la moda de la Distribución Normal son iguales y se localizan en el pico. Así,
UJTL_DCB_APUNTES DE ESTADISTICA INFERENCIAL_ MARA
7
la mitad del área bajo la curva se encuentra a la derecha de este punto central y la otra mitad está a la
izquierda de dicho punto.
• La distribución de probabilidad normal es simétrica alrededor de su media.
• La curva normal desciende suavemente en ambas direcciones a partir del valor central. Es asintótica, lo
que quiere decir que la curva se acerca cada vez más al eje X pero jamás llega a tocarlo. Las “colas” de la
curva se extienden de manera indefinida en ambas direcciones. Para indicar que una variable aleatoria
(v.a.) sigue una distribución normal de media µ y desviación estándar σ usaremos la expresión: X ~ N (µ,
σ).
(𝑋−𝜇)
Si se efectúa la transformación z= , la función anterior quedaría:
𝜎
La cual tiene media “0” y varianza 1, es decir Z~N (0, 1)
Para el cálculo de probabilidades siempre se usa la N (0,1).
EJEMPLO 1
Para un auto que corre a 30 millas por hora (mph), la distancia necesaria de frenado hasta detenerse por
completo está normalmente distribuida con media de 50 pies y desviación estándar de 8 pies. Suponga que
usted está viajando a 30 mph en una zona residencial y un auto se mueve en forma abrupta en el camino
de usted, a una distancia de 60 pies. X: distancia de frenado (pies) hasta detenerse para un auto que corre
a 30 millas por hora (mph). µ = 50 𝜎 = 8
a. Si usted aplica los frenos, ¿cuál es la probabilidad de que frene hasta detenerse en no más de 40 pies o
menos?
40 − 50
𝑃(𝑋 ≤ 40) = 𝑃(𝑍 ≤ ) = 𝑃(𝑍 ≤ −1.25) = 0.1056
8
¿Y en no más de 50 pies o menos?
50 − 50
𝑃(𝑋 ≤ 50) = 𝑃(𝑍 ≤ ) = 𝑃(𝑍 ≤ 0) = 0.5
8
b. Si la única forma de evitar una colisión es frenar hasta detenerse por completo, ¿cuál es la probabilidad
de que evite la colisión?
60 − 50
𝑃(𝑋 ≤ 60) = 𝑃(𝑍 ≤ ) = 𝑃(𝑍 ≤ 1.25) = 0.8944
8
UJTL_DCB_APUNTES DE ESTADISTICA INFERENCIAL_ MARA
8
EJEMPLO 2
Un método para llegar a pronósticos económicos es usar una propuesta de consensos. Se obtiene un
pronóstico de cada uno de un número grande de analistas y el promedio de estos pronósticos individuales
es el pronóstico de consenso. Suponga que los pronósticos individuales de la tasa de interés preferente de
enero de 2008, hechos por analistas económicos, están normalmente distribuidos en forma aproximada con
la media igual a 8.5% y una desviación estándar igual a 0.02%. Si al azar se selecciona un solo analista de
entre este grupo, ¿cuál es la probabilidad de que el pronóstico del analista de la tasa preferente tome estos
valores?
a. Rebase de 8.75%.
X: pronósticos individuales de la tasa de interés (%) preferente de enero de 2008 por analistas económicos.
µ = 8.5 𝜎 = 0.02
8.75 − 8.5
𝑃(𝑋 > 8.75) = 𝑃(𝑍 > ) = 𝑃(𝑍 > 12.5) ≅ 0
0.02
b. Sea menor a 8.375%.
8.375 − 8.5
𝑃(𝑋 < 8.375) = 𝑃(𝑍 < ) = 𝑃(𝑍 < −6.25) ≅ 0
0.02
EJEMPLO 3
El Servicio de Impuestos Internos (Internal Revenue Service IRS) es la agencia federal del Gobierno de los
Estados Unidos, encargada de la recaudación fiscal y de los cumplimientos de las leyes tributarias. ¿En
qué forma determina el IRS (Hacienda) el porcentaje de devoluciones de impuesto al ingreso para auditar a
cada estado? Suponga que lo hacen al azar, seleccionando 50 valores de entre una distribución normal con
una media igual a 1.55% y una desviación estándar igual a 0.45%.
a. ¿Cuál es la probabilidad de que un estado particular tenga más de 2.5% de sus devoluciones de
impuesto al ingreso auditadas?
X: porcentaje de devoluciones de impuesto al ingreso. µ = 1.55 𝜎 = 0.45
2.5 − 1.55
𝑃(𝑋 > 2.5) = 𝑃(𝑍 > ) ≅ 𝑃(𝑍 > 2.11) = 1 − 𝑃(𝑍 < 2.11) = 1 − 0.9826 = 0.0174
0.45
b. ¿Cuál es la probabilidad de que un estado tenga menos de 1% de sus devoluciones de impuesto al
ingreso auditadas?
1 − 1.55
𝑃(𝑋 < 1) = 𝑃(𝑍 < ) ≅ 𝑃(< −1.22) = 0.1112
0.45
UJTL_DCB_APUNTES DE ESTADISTICA INFERENCIAL_ MARA
9
EJEMPLO 4
El total de las ventas diarias (excepto sábados) en un pequeño restaurante tiene una distribución de
probabilidad que es aproximadamente normal, con una media µ igual a $1230 por día y una desviación
estándar 𝜎 igual a $120.
a. ¿Cuál es la probabilidad de que las ventas excedan de $1400 para un día determinado?
X: total de las ventas diarias (excepto sábados) en un pequeño restaurante. µ = 1230 𝜎 = 120
1400 − 1230
𝑃(𝑋 > 1400) = 𝑃(𝑍 > ) ≅ 𝑃(𝑍 > 1.42) = 1 − 𝑃(𝑍 < 1.42) = 1 − 0.9222 = 0.0778
120
b. El restaurante debe tener al menos $1000 en ventas por día para salir sin pérdidas ni ganancias. ¿Cuál
es la probabilidad de que en un día determinado el restaurante no salga sin pérdidas ni ganancias?
1000 − 1230
𝑃(𝑋 > 1000) = 𝑃(𝑍 > ) ≅ 𝑃(𝑍 > −1.92) = 1 − 𝑃(𝑍 < −1.92) = 1 − 0.0274 = 0.9726
120
EJEMPLO 5
La vida útil de un tipo de lavadoras automáticas está distribuida normalmente en forma aproximada, con
media y desviación estándar igual a 10.5 y 3.0 años, respectivamente. Si este tipo de lavadora está
garantizada durante un periodo de 5 años, ¿qué fracción necesitará ser reparada y/o repuesta?
X: La vida útil (años) de un tipo de lavadoras automáticas. µ = 10.5 𝜎 = 3.0
5−10.5
𝑃(𝑋 < 5) = 𝑃(𝑍 < ) ≅ (𝑍 < −1.83) = 0.0336
3.0
UJTL_DCB_APUNTES DE ESTADISTICA INFERENCIAL_ MARA
10
El 3.36% de las lavadoras tendrá que ser reparada y/o repuesta, pues su tiempo de vida útil es de máximo
cinco años.
EJEMPLO 6
Una estación de radio con programación de Rock, descubre que el tiempo que una persona sintoniza la
estación tiene distribución normal, con un tiempo promedio 15 minutos y una desviación estándar de 3.5
minutos. ¿Cuál es la probabilidad de que un radioescucha sintonice entre 10 y 14 minutos?
X: tiempo (min) que permanece sintonizado µ = 15 σ = 3.5
10 − 15 14 − 15
𝑃(10 ≤ 𝑋 ≤ 14) = 𝑃 ( ≤𝑍≤ )=
3.5 3.5
𝑃(−1.43 ≤ 𝑍 ≤ −0.29) = 𝑃(𝑍 ≤ −0.29) − 𝑃(𝑍 ≤ −1.43)
= 0.3859 − 0.0764 = 0.3095
La probabilidad de que un radioescucha sintonice entre 10 y 14
minutos
es de 0.3095
EJEMPLO 7
La vida promedio de cierto tipo de motor pequeño tiene una distribución normal con promedio de 10 años y
desviación estándar de dos años. El fabricante reemplaza gratis todos los motores que fallen dentro del
tiempo de garantía. Si está dispuesto a reemplazar solo 3% de los motores que fallan, ¿Qué tan larga debe
ser la garantía que otorgue?
X: vida útil (años) de un motor µ = 10 σ = 2
Hallar x0 tal que P (X < X0 )=0.03
𝑋0 −10
Luego = −1.88 x0 =10 − (2 * 1.88) = 6.24
2
La garantía que otorgue para reemplazar solo el 3% de los motores
es
de máximo 6.24 años
EJEMPLO 8
Se puede ajustar una máquina de refrescos de tal manera que llene los vasos con un promedio de µ onzas
por vaso. Si el número de onzas por vaso tiene una distribución normal con una desviación estándar de 0.3
UJTL_DCB_APUNTES DE ESTADISTICA INFERENCIAL_ MARA
11
onzas, encuentre el valor de µ de tal manera que los vasos de 8 onzas se rebosen solamente en el 1% de
las veces.
X: cantidad (onzas) de refresco dispensada por la maquina µ =? σ = 0.3
Hallar µ tal que P (X > 8 )=0.01 entonces P (X ≤ 8 )=0.99
8−µ
𝑃(𝑋 ≤ 8) = 𝑃(𝑍 ≤ ) = 0.99 = 𝑃(𝑍 ≤ 2.33)
0.3
8−µ
Luego = 2.33
0.3
µ=8-(2.33*0.3)=7.301
Para que los vasos de 8 onzas se rebosen solamente en el 1% de
las veces, se debe ajustar la máquina para que dispense en
promedio 7.301 onzas por vaso
EJEMPLO 9
Se sabe que el tiempo que demora el viaje en autobús desde la ciudad A hasta la ciudad B tiene una
distribución normal. Además, se sabe que la probabilidad de que el viaje exceda 4 horas es de 0.9772 y la
probabilidad de que exceda cinco horas es de 0.9332. ¿Cuál es el promedio y la desviación estándar del
tiempo de traslado entre estas dos ciudades?
X: tiempo (horas) traslado entre la ciudad A y B
0.9772 0.9332
4 X 5 X
P (X >4 )=0.9772 entonces P (X ≤ 4 )=0.0228 P (X 5 )=0.9332 entonces P (X ≤ 5 )=0.0668
(1) (2)
De (1) se tiene que (3) Reemplazando (3) en (2):
Luego de donde entonces µ= 8
Finalmente reemplazando el valor de µ= 8 en la ecuación (3) se logra la desviación estándar, así:
EJEMPLO 10
Se ha encontrado que la duración promedio, requerida para completar un examen de conocimientos en una
universidad, es igual a 70 minutos con una desviación estándar de 12 minutos. ¿Cuándo debe terminarse el
UJTL_DCB_APUNTES DE ESTADISTICA INFERENCIAL_ MARA
12
examen si se desea permitir tiempo suficiente para que 90% de los estudiantes lo completen? (Suponga
que el tiempo necesario para completar el examen está normalmente distribuido.)
X: tiempo (min) necesario para completar un examen de conocimientos en una universidad. µ = 70 𝜎 = 12
Hallar 𝑥 tal que 𝑃(𝑋 ≤ 𝑥) = 0.90
𝑥−70 𝑥−70
𝑃(𝑋 ≤ 𝑥) = 0.90 = 𝑃(𝑍 ≤ ) ≅ 𝑃(𝑍 ≤ 1.28) Entonces, = 1.28 Luego x= 70 + 1.28 ∗ 12 = 85.36
12 12
El examen debe terminarse a los 85.36 minutos si se desea permitir tiempo suficiente para que 90% de los
estudiantes lo completen.
EJEMPLO 11
Una máquina que envasa refrescos puede ser regulada para descargar un promedio de 𝜇 onzas por vaso.
Si las onzas de líquido están normalmente distribuidas, con desviación estándar igual a 0.3 de onza, dé el
ajuste para 𝜇 de modo que vasos de 8 onzas (¼ de litro) se rebosen sólo 1% del tiempo.
X: cantidad (onzas) de líquido dispensada por la máquina. µ =? 𝜎 = 0.3
Hallar µ tal que 𝑃(𝑋 > 8) = 0.01 entonces 𝑃(𝑋 ≤ 8) = 0.99
8−µ 8−µ
𝑃(𝑋 ≤ 𝑥) = 0.99 = 𝑃(𝑍 ≤ ) ≅ 𝑃(𝑍 ≤ 2.33) Entonces, ≅ 2.33
0.3 0.3
Luego µ ≅ 8 − 2.33 ∗ 0.3 = 7.301
Se debe ajustar la máquina para que dispense en promedio 7.301 onzas para que los vasos de 8 onzas (¼
de litro) se rebosen sólo 1% del tiempo
EJERCICIOS
1. Investigaciones hechas por la Federal Deposit Insurance Corporation muestran que el tiempo de vida de
una cuenta de ahorros regular que se tiene en uno de los bancos de la Corporación sigue una
distribución normal con una media de 22 meses y una desviación estándar de 5.5 meses. Si un
depositante abre una cuenta en un banco miembro de la Corporación. Cuál es la probabilidad de que:
a. Haya dinero después de 28 meses?
b. Haya dinero en más de 14 meses.
c. Cuál es el tiempo mínimo que habría en el 8% de las cuentas que perduran más como clientes.
2. El dueño de un expendio de embutidos sabe por experiencia que la demanda diaria de
“salami fresco” se distribuye normalmente, con media 25 kilos y desviación estándar de 7 kilos. Cuál es
la probabilidad de que la demanda en un día de salami fresco sea:
a. Superior a 30 kilos
b. Inferior a 11 kilos
c. Entre 20 y 40 libras.
3. Una empresa de contabilidad descubre que el tiempo que toma para realizar un proceso de auditoría
sigue una distribución normal con tiempo promedio de 17.2 días y una desviación estándar 3.7 días.
Cuál es la probabilidad de que un auditor haga su trabajo entre 15 y 20 días. En más de 12 días. En
menos de 40 días. ¿Cuál es el tiempo máximo del 9% de las auditorías que menos demoran?
4. Un propietario de un restaurante ha determinado que la demanda diaria de carne molida en su negocio
tiene una distribución normal con una media de 240 Kg. y una desviación estándar de 23 Kg.
a. ¿Cuál es la probabilidad de que en un día cualquiera esa demanda sea superior a 180
b. ¿Inferior a 320?
c. Entre 150 y 310.
UJTL_DCB_APUNTES DE ESTADISTICA INFERENCIAL_ MARA
13
d. ¿Qué cantidad de carne molida debe estar disponible diariamente para que la probabilidad de que
se agote la carne molida no sea mayor al 1%?
5. La edad promedio que tiene una persona al casarse por primera vez es de 26 años. Suponga que la
edad en el primer casamiento tiene una distribución Normal, con una desviación estándar de 4 años.
a. ¿Cuál es la probabilidad de que una persona que se casa por primera vez tenga menos de 23 años?
a) 0.2734 b) 0.2266 c) 0.7734 d) 0.6220 e) 0.5734
b. ¿Cuál es la probabilidad de que una persona que se casa por primera vez tenga entre 20 y 30 años?
a) 0.3412 b) 0.4332 c) 0.2745 d) 0.7745 e) 0.2255
c. El 90% de las personas que se casan por primera vez, ¿a qué edad máxima lo hacen?
a) 20.880 b) 31.120 c) 32.560 d) 19.440 e) 17.280
6. Un profesor conoce que la nota final de sus estudiantes sigue una distribución aproximadamente normal
y además sabe que en general el 2.28% de sus estudiantes sacan menos de uno y que el 15.87% sacan
más de cuatro. ¿Cuál es el promedio y la desviación de la nota final de los estudiantes del profesor en
mención?.
7. Es conocido que el ingreso/semana (en miles de pesos) de vendedores de seguros esta normalmente
distribuido. Además, se sabe que el 13.79% de los vendedores gana máximo 300 y que el 2.28% gana
más de 900.
a. ¿Cuál es el ingreso promedio de los trabajadores?
a) 600 b) 450 c) 150 d) 8.035 e) 511.65
b. La desviación estándar del ingreso semanal es:
a) 8.035 b) 194.175 c) 600 d) 61.89 e) 150
8. Se conoce que el salario semanal de los empleados del sector agropecuario sigue una distribución
normal. Si en general el 10% de los empleados gana más de $120000 y que el 2.5% gana máximo
$70000, ¿cuál es el promedio y la desviación estándar del salario semanal de los mencionados
empleados?
9. La duración media de los anuncios de televisión en una red dada es de 75 segundos, con una
desviación estándar de 20 segundos. Suponga que los tiempos de duración son normales. ¿Cuál es la
probabilidad de que un anuncio dure?:
a. Menos de 35 segundos
a) 0.4772 b) 0.9772 c) 0.0228 d) 0.4713
b. Más de un minuto
a) 0.2734 b) 0.2266 c) 0.2640 d) 0.7734
10. El número de veces, x, que un humano adulto respira por minuto cuando está en reposo depende de la
edad y varía mucho de una persona a otra. Suponga que la distribución de probabilidad para X es
aproximadamente normal, con media igual a 16 y una desviación estándar igual a 4. Si se elige una
persona al azar en estado de reposo cual es la probabilidad de que el número de respiraciones por
minuto sea:
a. Mayor a 22
a) 0.4332 b) 0.9332 c) 0.0668 d) 0.5668
b. ¿Cuál es el número de respiraciones mínimo del 7% de las personas que por diferentes motivos
tienen un número mayor de respiraciones por minuto?
a) 21.9200 b) 10.0800 c) 5.9200 d) 12.0007
11. La cantidad de gaseosa depositada por una máquina en una botella es una variable aleatoria normal.
UJTL_DCB_APUNTES DE ESTADISTICA INFERENCIAL_ MARA
14
Se sabe que el 25% de las botellas sobrepasa los 310 ml y el 5% no alcanza los 290 ml. Determine la
media y la desviación estándar de la cantidad de gaseosa depositada en cada botella por esta máquina.
12. En experimentos hechos con pilotos de aviación, se encontró que los umbrales de desmayo frente a
aceleraciones se distribuyen normalmente con media de 4.5 g y desviación estándar de 0.7 g. . Qué
proporción de pilotos de aviación tienen sus umbrales de desmayo:
a. ¿Por encima de 5 g?
b. ¿Entre 3.7 g y 5.2 g?
c. Si solamente a los pilotos cuyos umbrales se encuentran en el 25% más alto se les permite ser
candidato a astronauta, ¿cuál es el punto de corte para ser astronauta?
13. De acuerdo con la Sleep Foundation, en promedio de duermen 6.8 horas por noche. Suponga que la
desviación estándar es 0.6 horas y que la distribución de probabilidad es normal. Cuál es la probabilidad de
que una persona seleccionada al azar duerma
a. ¿Más de 8 horas?
b. ¿Seis horas o menos?
c. Los médicos aconsejan dormir entre siete y nueve horas por noche. ¿Qué porcentaje de la población
duerme esta cantidad?
14. Una persona con una buena historia crediticia tiene una deuda promedio de 14.5 millones de pesos.
Suponga que la desviación estándar es de 3.5 millones y que los montos de las deudas están distribuidos
normalmente. Cuál es la probabilidad de que la deuda de una persona con buena historia crediticia:
a. ¿Sea mayor a $18 millones?
b. ¿Sea menos de $10 millones?
c. ¿Este entre $12 y $18 millones?
15. Un investigador científico informa que unos ratones vivirán un promedio de 40 meses cuando sus dietas
se registren drásticamente y después se enriquecen con vitaminas y proteínas. Suponiendo que las vidas
de tales ratones se distribuyen normalmente con una desviación estándar de 6.3 meses, encuentre la
probabilidad de que un ratón dado vivirá
a. más de 32 meses
b. menos de 28 meses
c. entre 37 y 49 meses
UJTL_DCB_APUNTES DE ESTADISTICA INFERENCIAL_ MARA
15
CAPITULO 1
INTRODUCCION A LA ESTADISTICA INFERENCIAL
Uno de los propósitos de la estadística es usar la información contenida en una muestra para hacer
inferencias acerca de la población de la cual se toma la muestra. La estadística inferencial está formada por
procedimientos empleados para hacer inferencias acerca de características poblacionales, a partir de
información contenida en una muestra sacada de esta población.
Debido a que las poblaciones están caracterizadas por medidas descriptivas numéricas llamadas
parámetros, el objetivo de muchas investigaciones estadísticas es calcular el valor de uno o más
parámetros relevantes.
La estimación tiene muchas aplicaciones prácticas. Por ejemplo, un fabricante de máquinas lavadoras
podría estar interesado en estimar la proporción (π) de lavadoras que esperaría que fallen antes de la
expiración de la garantía de un año. Otros parámetros poblacionales importantes son la media poblacional,
la varianza y la desviación estándar. Por ejemplo, podríamos estimar la media del tiempo de espera en una
caja registradora del supermercado o la desviación estándar del error de medición de un instrumento
electrónico.
Para simplificar nuestra terminología, al parámetro de interés le llamaremos parámetro objetivo en el
experimento. Suponga que deseamos estimar la cantidad promedio de mercurio que un proceso recién
inventado puede eliminar de 1 onza de mineral obtenido de un lugar geográfico determinado.
Podríamos dar nuestra estimación o cálculo en dos formas distintas. Primero, podríamos usar un solo
número, por ejemplo 0.13 onzas, que consideramos es cercano a la media poblacional desconocida µ. Este
tipo de estimación se llama estimación puntual porque un solo valor o punto constituye la estimación de µ.
En segundo término, podríamos decir que µ está entre dos números, por ejemplo entre 0.07 y 0.19 onzas,
en este segundo procedimiento de estimación los dos valores se pueden utilizar para construir un intervalo
(0.07; 0.19) que tiene la intención de encerrar el parámetro de interés; entonces, la estimación se denomina
estimación por intervalo. La información de la muestra se puede emplear para calcular el valor de una
estimación puntual, una estimación de intervalo o ambas. En cualquier caso, la estimación real se logra con
el uso de un estimador del parámetro objetivo.
Usted ha encontrado numerosas estadísticas, la media muestral, la varianza muestral, el rango, etc. Se
usan estadísticos para hacer inferencias (estimaciones o decisiones) acerca de parámetros de población
desconocidos. Como todos los estadísticos son funciones de las variables aleatorias observadas en una
muestra, también son variables aleatorias. En consecuencia, todos los estadísticos tienen distribuciones de
probabilidad, que llamaremos sus distribuciones muestrales. Desde un punto de vista práctico, la
distribución muestral de un estadístico proporciona un modelo teórico para el histograma de frecuencia
relativa de los posibles valores del estadístico que observaríamos por medio de muestreo repetido.
A menudo necesitamos estudiar las propiedades de una determinada población, pero nos encontramos con
el inconveniente de que ésta es demasiado numerosa como para analizar a todos los individuos que la
componen. Por tal motivo, recurrimos a extraer una muestra de la misma y a utilizar la información obtenida
para hacer inferencias sobre toda la población. Estas estimaciones serán válidas sólo si la muestra tomada
es “representativa” de la población.
El muestreo es por lo tanto una herramienta de la investigación científica, cuya función básica es
determinar qué parte de una población debe examinarse, con la finalidad de hacer inferencias sobre dicha
población.
La muestra debe lograr una representación adecuada de la población, en la que se reproduzca de la mejor
manera los rasgos esenciales de dicha población que son importantes para la investigación. Para que una
UJTL_DCB_APUNTES DE ESTADISTICA INFERENCIAL_ MARA
16
muestra sea representativa, y por lo tanto útil, debe reflejar las similitudes y diferencias encontradas en la
población, es decir ejemplificar las características de ésta.
Los errores más comunes que se pueden cometer al tomar una muestra son:
1.- Hacer conclusiones muy generales a partir de la observación de sólo una parte de la Población, a esto
se le denomina error de muestreo.
2.- Hacer conclusiones hacia una Población mucho más grandes de la que originalmente se tomó la
muestra, se le denomina: error de Inferencia.
En la estadística se usa la palabra población para referirse no sólo a personas sino a todos los elementos
que han sido escogidos para su estudio y el término muestra se usa para describir una porción escogida de
la población
Así, el muestreo es una técnica que utilizaremos para inferir algo respecto de una población mediante la
selección de una muestra de esa población. En muchos casos, el muestreo es la única manera de poder
obtener alguna conclusión de una población, entre otras causas, por el coste económico y el tiempo
empleado que supondría estudiar a todos los miembros de una población.
1.1 TIPOS DE DISEÑO DE MUESTREO
En principio, podríamos distinguir dos tipos de muestra: la probabilística y la no probabilística, en el sentido
en que una muestra probabilística es una muestra seleccionada de tal forma que cada elemento de la
población tiene la misma probabilidad de formar parte de la muestra. De esta manera, si se utilizan
métodos no probabilísticos, no todos los elementos de la población tienen la misma probabilidad de ser
incluidos. En este caso, diríamos que los resultados están sesgados, lo cual quiere decir que tal vez los
resultados de la muestra no sean representativos de la población.
Los métodos de muestreo probabilísticos son aquellos que se basan en el principio de equiprobabilidad. Es
decir, aquellos en los que todos los individuos tienen la misma probabilidad de ser elegidos para formar
parte de una muestra y, consiguientemente, todas las posibles muestras de tamaño n tienen la misma
probabilidad de ser seleccionadas. Sólo estos métodos de muestreo probabilísticos nos aseguran la
representatividad de la muestra extraída y son, por tanto, los más recomendables. Dentro de los métodos
de muestreo probabilísticos encontramos los siguientes tipos:
1.1.1 Muestreos probabilísticos
Muestreo aleatorio simple (MAS)
El MAS se debe emplear en aquellos casos donde las características de la población son homogéneas. El
procedimiento empleado es el siguiente: 1) se asigna un número a cada individuo de la población y 2) a
través de algún medio mecánico (bolas dentro de una bolsa, tablas de números aleatorios, números
aleatorios generados con una calculadora u ordenador, etc.) se eligen tantos sujetos como sea necesario
para completar el tamaño de muestra requerido.
Este procedimiento, atractivo por su simpleza, tiene poca o nula utilidad práctica cuando la población que
estamos manejando es muy grande.
El tamaño de muestra está estrechamente ligado a los objetivos de investigación, y pueden suceder varias
situaciones, entre otras, que la investigación tenga varios objetivos, entonces se determina el tamaño de
muestra para cada objetivo y se toma como tamaño de muestra el mayor de ellos, o puede suceder que el
investigador considere que el objetivo que gobierna la muestra sea uno solo y para él se determina el
tamaño de la muestra. Entonces primero se debe expresar el objetivo de investigación en una medida
estadística, tal como la media, la proporción, etc... Posteriormente se calcula el tamaño de muestra para los
objetivos pertinentes. Para la media y la proporción, se utilizan las siguientes fórmulas:
UJTL_DCB_APUNTES DE ESTADISTICA INFERENCIAL_ MARA
17
𝑆2 𝑃.𝑄
Para la media (µ): n0 = Para la proporción (𝜋) : n0 = 𝐸2
𝐸2 ( 2)
( 2) 𝑍
𝑍
cuando se conoce el tamaño de la población: cuando se conoce el tamaño de la población:
𝑛 𝑛
n= 0𝑛0 n= 0𝑛0
1+ 1+
𝑁 𝑁
El valor de S2 se conoce como varianza “semilla”, porque si se desea estimar la media sería ilógico que se
conozca la varianza. Se debe tener una idea inicial de la dispersión, entre más cerca esté del verdadero
valor de la dispersión de la población, el tamaño de la muestra será más adecuado. Se utilizan varias
formas para ello:
1. Seleccionar una muestra piloto pequeña arbitraria con buen criterio y con ella calcular la varianza.
2. Consultar un experto que nos informe sobre la dispersión de la variable, puede ser preguntándole
𝑅𝑎𝑛𝑔𝑜 2 (𝑋 −𝑋 )2
la varianza o en su defecto usar la siguiente aproximación 𝜎 2 ≅ 𝑆 2 = ≈ 𝑚𝑎𝑥 2 𝑚𝑖𝑛 .
42 4
3. Consultar la bibliografía existente sobre las variables de estudio, para ver si de pronto existe
información sobre la dispersión de la variable.
Cuando se trata de estimar la proporción, pueden suceder varias situaciones:
1. Que se tenga una idea del valor de la proporción.
2. Que no se conozca ningún valor acerca de la proporción, en este caso se utiliza P=0.5.
3. Que tenga una idea de la proporción no tan puntual, por ejemplo, superior o igual al 70%, en este
caso la proporción se encontrará entre 70% y 100%, se tomará el porcentaje más cercano al 50%
del intervalo conocido, es decir el 70%. Inferior o igual al 40%, entonces se tomaría el 40%. En los
casos donde el conocimiento que se tenga sea un intervalo que contenga el 50%, por ejemplo,
entre el 25% y 62%, se tomará el 50%.
Las fórmulas para los otros parámetros como la diferencia de medias, diferencia de proporciones, la media
de las diferencias, la varianza, la razón de varianzas, se deja como investigación para el lector.
EJEMPLO 1
Una compañía publicitaria está interesada en analizar el número de horas por semana (X-horas) que las
familias (F) de una comunidad ven televisión y si ven el noticiero NTC (A-los que lo ven), para ello desean
seleccionar una muestra aleatoria de las 150 familias que conforman dicha comunidad con una probabilidad
del 95%, se cuenta con la siguiente información:
Variables: X: Número de horas por semana que ven televisión (Parámetro de análisis: Media)
Se cuenta con la siguiente información: Varianza=25, Error= 2,
A: Ven el noticiero NTC (parámetro de análisis: Proporción)
Se cuenta con la siguiente información: p=0.85, Error=0.10
a. Determine el tamaño de muestra.
En este caso el estudio pretende dos objetivos, uno seria estimar el promedio de horas por
semana que ven televisión las familias y el otro es estimar la proporción de familias que ven el
noticiero NTC.
𝑆2
n0 = 𝐸2 =25/(2/1.96)2=24.01 n=24.01/(1+24.01/150)=20.697121≅21
( 2)
𝑍
𝑃.𝑄
n0 = 𝐸2
=(0.85x0.15)/(0.1/1.96)2= 48.9804 n=48.9804/(1+48.9804/150)=36.9235≅37
( 2)
𝑍
Se deben seleccionar 37 familias de las 150 que viven en la comunidad. Es decir se escoge el
mayor tamaño calculado de los objetivos propuestos.
b. Seleccione los elementos
La selección de los elementos se puede hacer de varias formas, usando una
calculadora, Excel (ALEATORIO.ENTRE(1,150)), o con la tabla de números aleatorios (libro
UJTL_DCB_APUNTES DE ESTADISTICA INFERENCIAL_ MARA
18
Introducción a la probabilidad y estadística de Mendenhall Tabla 10 página 706-707)
entre otros procedimientos.
El procedimiento de la tabla de números aleatorios es el siguiente:
● Debe asignar a cada elemento de la población los números de 001 a 150.
● Seleccione de la tabla varias columnas y filas (ejemplo c3f4, c6f8, c2f12, c1f1, C2f2 en
teoría deben elegirse aleatoriamente tanto fila como columna).
● Dependiendo del tamaño de la población escoja el número de dígitos en la tabla
(Ejemplo N=150, tres dígitos), como criterio se deben escoger el mismo número de
dígitos de la población al inicio de la columna y la fila de la tabla.
● En la tabla, en la columna 3 fila 4, se encuentra:
Columna 3 Se escogen números de tres cifras que estén dentro del intervalo 001 a 150 al inicio de
cada fila dentro de la columna hasta terminar en la fila 100, y posteriormente se escogerá
Fila 4 06243completar el tamaño de la
la siguiente columna y fila c6f8 y así sucesivamente hasta
muestra. No se deben repetir elementos.
81837
Entonces los elementos elegidos serán: 062, 110,054,……
11008
# # # # # # # #
56420
1 062 6 069 11 074 16 002 21 086 26 127 31 104 36 012
05463 2 110 7 041 12 035 17 045 22 119 27 042 32 009 37 064
63661 3 054 8 143 13 059 18 130 23 128 28 047 33 1240
53342 4 055 9 020 14 139 19 025 24 027 29 075 34 080
5 048 10 066 15 145 20 095 25 141 30 003 35 052
88231
48235
UJTL_DCB_APUNTES DE ESTADISTICA INFERENCIAL_ MARA
19
Marco muestral (F=Residencia de cada una de las familias). Los elementos resaltados son la muestra
aleatoria.
F 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
X 12 14 8 5 14 25 12 18 17 40 12 8 12 13 35 26 20 14 18 19
A SI SI SI SI NO NO NO SI SI SI SI NO NO NO NO SI SI NO NO SI
F 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40
X 12 11 10 9 8 5 4 7 8 11 4 22 21 20 23 25 41 15 16 8
A SI SI SI NO NO NO NO SI SI NO NO NO SI SI SI NO NO SI SI NO
F 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60
X 15 16 19 19 14 15 15 15 16 14 17 20 20 21 23 24 28 25 26 35
A SI SI SI SI SI SI SI SI SI SI SI SI NO NO NO SI SI SI NO NO
F 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80
X 8 15 9 12 14 18 21 9 10 17 16 23 20 25 24 8 4 3 3 4
A NO NO NO SI SI SI SI SI SI SI NO NO SI NO SI SI NO NO SI SI
F 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100
X 15 14 18 19 26 25 24 24 24 24 23 22 21 20 19 18 14 14 15 26
A SI SI SI SI SI SI SI SI SI SI SI SI SI NO NO NO NO NO NO NO
F 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120
X 12 14 15 16 24 25 25 28 29 27 30 35 32 31 32 20 8 9 10 21
A SI SI SI SI SI SI SI SI SI SI SI SI SI SI SI SI NO NO SI SI
F 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140
X 12 10 9 5 12 14 17 2 3 4 5 6 11 4 7 18 29 22 10 12
A SI SI SI SI SI SI SI SI NO NO NO SI SI SI SI SI NO SI NO SI
F 141 142 143 144 145 146 147 148 149 150
X 12 10 9 8 12 25 20 22 23 24
A SI SI NO NO NO SI SI SI NO NO
Después de la selección de los elementos se pueden calcular las medidas que se requieran con la muestra
seleccionada.
Promedio aritmético o media aritmética=14.6486
Desviación típica o desviación estándar=6.87272
Coeficiente de variación=46.9171%
P(si)=24/37=0.6486
Se estima que la proporción de familias que ven el noticiero NTC es del aproximadamente el 65%, en
promedio las familias ven televisión semanalmente 14.6486 horas. En promedio, el tiempo que cada familia
ve televisión varía con respecto al promedio 6.87272 horas. Es importante recordar que este tipo de
muestreo se debe emplear cuando los datos son homogéneos. El coeficiente de variación indica el grado
de precisión con el cual se está reportando un resultado. De tal forma que entre menor sea el coeficiente de
variación, menor incertidumbre se tiene de la estimación y advierte que ésta es más precisa. El uso de esta
medida depende directamente de las condiciones del estudio, por lo cual no hay reglas universales; sin
embargo, se propone tener en cuenta los siguientes criterios para hacer uso del coeficiente de variación
estimado:
Criterios de precisión: Estimaciones de las medidas
Menor del 3% Excelente
Entre el 3% y el 5% De buena calidad
Entre 5% y el 15% De uso restringido
Mayor de 15% Deben usarse con precaución
En este caso las estimaciones se deben usar con precaución y el uso del muestreo aleatorio no es el más
indicado dada la alta variabilidad de la variable analizada. (Guía para la Interpretación del Error Muestral en
UJTL_DCB_APUNTES DE ESTADISTICA INFERENCIAL_ MARA
20
Términos del Coeficiente de Variación e Intervalo de Confianza Estimado Encuesta de Sacrificio de Ganado
– ESAG, Enero 2014-DANE)
Muestreo aleatorio sistemático de elementos
(MSE O MES).
Este procedimiento exige, como el anterior, numerar todos los elementos de la población, pero en lugar de
extraer n números aleatorios sólo se extrae uno. Se parte de ese número aleatorio r, que es un número
elegido al azar, y los elementos que integran la muestra son los que ocupa los lugares r, r+F, r+2F,
r+3F,...,r+(n-1)F, es decir se toman los individuos de F en F, siendo F el resultado de dividir el tamaño de la
población entre el tamaño de la muestra: F= N/n. El número r que empleamos como punto de partida será
un número al azar entre 1 y F.
En el ejemplo 1, F=150/37=4.0541≈4. generalmente a este valor se le llama intervalo de muestreo, debido a
que la población se debe dividir en 37 segmentos de tamaño 4, el primero de 001-004, el segundo de 005-
008,…..el segmento 37 irá desde 145-148, quedaría un segmento de dos elementos desde 149-150.
Se debe elegir un número aleatorio entre 001 a 004, debido a que la población es 150 y existen tres dígitos.
Suponga que se eligen las mismas filas y columnas elegidas en el MAS, y se sigue el mismo procedimiento
de MAS para la selección de los elementos, en la c3f4 no se encuentra ningún número entre 001 y 004, se
sigue con la c6f8 donde se encuentra un elemento que se encuentra entre el intervalo 001al 004, el número
002.Este elemento será el elemento de inicio, es decir que el primer elemento elegido será el número 002.
Este elemento indica que se debe elegir el segundo elemento de cada segmento.
El elemento elegido marca algunos aspectos muy importantes, en nuestro ejemplo, se tienen 37 segmentos
de 4 y un segmento de dos elementos, si solo se tiene en cuenta los segmentos de tamaño 4, no se tiene la
cobertura de la población y si se tiene en cuenta todos los segmentos en que se ha dividido la población, en
este caso una de las diferentes alternativas sería continuar con la estructura, elegir el segundo elemento de
ese segmento y la muestra se incrementa a 38 elementos.
Luego los elementos seleccionados mediante el muestreo sistemático de elementos serían:
1 2 3 4 5 6 7 8 9 10
002 006 010 014 018 022 026 030 034 038
11 12 13 14 15 16 17 18 19 20
042 046 050 054 058 062 066 070 074 078
21 22 23 24 25 26 27 28 29 30
082 086 090 094 098 102 106 110 114 118
31 32 33 34 35 36 37 38
122 126 130 134 138 142 146 150
De lo anterior, se desprenden varias situaciones, dado que queda el último segmento con dos elementos:
Primero, que el elemento seleccionado aleatoriamente inicialmente este entre 001 y 002 sea 002,
no habría ningún problema porque se sigue con la estructura del muestreo, y se mantiene la
probabilidad de selección de cada elemento.
Segundo que el elemento inicialmente elegido estuviera entre 003-004, no existen elementos en el
último segmento que ocupen esas posiciones, entonces se recomienda, seleccionar un numero
aleatorio entre el 149 y 150, (comenzando con la c3f4, c6f8, c2f12, y terminando con la c1f1, no se
encuentra ni el 149 o 150), si tomamos la c2f2, encontramos el numero 150, quien sería el
elemento elegido del último segmento, en este caso también se mantiene la probabilidad de
selección de cada elemento.
La recomendación práctica es que el intervalo de muestreo (F) sea un múltiplo del tamaño de la
población para que no se presenten inconvenientes de aproximación.
UJTL_DCB_APUNTES DE ESTADISTICA INFERENCIAL_ MARA
21
El riesgo de este tipo de muestreo está en los casos en que se dan periodicidades en la población ya que al
elegir a los miembros de la muestra con una periodicidad constante (F) podemos introducir una
homogeneidad que no se da en la población. Imaginemos que estamos seleccionando una muestra sobre
listas de 10 individuos en los que los 5 primeros son varones y los 5 últimos mujeres, si empleamos un
muestreo aleatorio sistemático con F=10 siempre seleccionaremos o sólo hombres o sólo mujeres, no
podría haber una representación de los dos sexos.
EJERCICIOS
1. Una Compañía desea establecer una mejor política de bienestar para sus 120 empleados, para ello está
interesada en estimar el promedio de hijos por empleados (X-número de hijos) y el ingreso promedio
disponible mensual para actividades recreativas (Y-ingreso disponible para actividades recreativas). Se
cuenta con la siguiente información:
VARIABLE S2 E
X 3 1
Y 800 10
a. Determine el tamaño de muestra con una confianza del 94%.
b. Seleccione los elementos usando MAS y MSE c2f5, c10f4, c5f3
c. Calcule y analice la media, la desviación estándar y el coeficiente de variación.
Empleado X Y Empleado X Y Empleado X Y
1 2 120 41 2 200 81 0 90
2 1 110 42 2 150 82 1 145
3 3 90 43 2 140 83 1 410
4 4 40 44 2 70 84 2 120
5 0 50 45 0 80 85 2 150
6 2 60 46 0 85 86 2 160
7 1 45 47 3 95 87 2 170
8 3 78 48 3 100 88 2 150
9 2 85 49 3 120 89 2 160
10 2 28 50 5 140 90 0 145
11 2 89 51 1 130 91 0 140
12 2 96 52 1 140 92 0 90
13 2 45 53 4 150 93 1 45
14 1 21 54 4 160 94 2 58
15 1 54 55 5 140 95 5 85
16 0 87 56 2 145 96 0 95
17 0 98 57 2 200 97 3 110
18 4 120 58 2 210 98 1 100
19 5 158 59 4 250 99 0 110
20 2 259 60 3 300 100 4 115
21 1 120 61 3 150 101 0 160
22 3 86 62 2 150 102 2 86
23 3 89 63 1 160 103 3 95
24 3 120 64 0 90 104 1 110
25 2 300 65 0 40 105 0 100
26 1 200 66 2 45 106 1 90
27 1 201 67 5 50 107 0 50
28 1 150 68 0 60 108 2 160
29 1 80 69 3 60 109 0 170
30 4 90 70 1 80 110 3 200
UJTL_DCB_APUNTES DE ESTADISTICA INFERENCIAL_ MARA
22
31 5 124 71 1 80 111 3 170
32 2 125 72 1 70 112 5 180
33 0 140 73 2 120 113 0 120
34 0 200 74 2 110 114 2 110
35 0 300 75 2 90 115 2 90
36 1 258 76 2 80 116 2 110
37 3 200 77 3 155 117 2 80
38 2 150 78 3 95 118 1 50
39 3 160 79 2 80 119 2 75
40 3 180 80 1 75 120 0 110
2. Con el objeto de reducir el trabajo de efectuar el inventario de una bodega se desea estimar el Valor (X-
valor artículos en millones de $) de los artículos y la proporción de estantes que no poseen artículos
defectuosos (A-El estante posee artículos defectuosos?)
a. Determine n, conociendo que:
S P E CONFIANZA
Xx X 15 5 90%
A 0.95 0.05 90%
b. Seleccione los elementos mediante el MAS c3f5, c5f7, c8f2, c1f1.
c. Calcule y analice la media, la mediana, la proporción, la desviación estándar y el coeficiente de
variación.
d. Si el tamaño de muestra solo se calculara con el objetivo de la proporción, todas las medidas
permanecen constantes, cuál sería el tamaño de la muestra en las siguientes situaciones: la
proporción es superior al 45%, si la proporción está entre el 67% y el 85%.
Estante 1 2 3 4 5 6 7 8 9 10
X 29 64 38 65 42 65 42 37 67 45
A Si Si No No No No No No No No
Estante 11 12 13 14 15 16 17 18 19 20
X 67 47 38 45 32 38 41 29 32 51
A Si No Si No No No No No Si No
Estante 21 22 23 24 25 26 27 28 29 30
X 33 21 25 37 52 43 40 25 37 41
A No No No No Si No No No Si No
Estante 31 32 33 34 35 36 37 38 39 40
X 38 42 45 45 39 40 55 62 66 45
A No No No No No No No No No Si
Estante 41 42 43 44 45 46 47 48 49 50
X 33 21 25 37 52 43 40 25 37 41
A No No No No Si No No No Si No
Estante 51 52 53 54 55 56 57 58 59 60
X 55 44 41 36 78 45 56 75 45 44
UJTL_DCB_APUNTES DE ESTADISTICA INFERENCIAL_ MARA
23
A Si No No Si Si No No No No No
Estante 61 62 63 64 65 66 67 68 69 70
X 41 36 52 57 65 62 63 62 68 69
A No No No Si Si No No No No Si
3. En un estudio por muestreo se desea estimar el gasto medio mensual que tienen los hogares de Bogotá
en un determinado producto. ¿De qué tamaño se debe seleccionar la muestra si se desea tener una
confianza de 0.95 de que el máximo error en la estimación no exceda de $2500?. Se conoce, por estudios
anteriores, que el gasto mensual de los hogares en ese producto tiene una desviación estándar de $28000.
4. Se quiere realizar un estudio de mercados para estimar cual es el gasto medio anual en camisas que
realizan los hombres en Colombia. De qué tamaño se debería seleccionar la muestra para poder tener una
confianza de 0.95 de que el máximo error en la estimación no exceda de $8000. Por estudios previos,
puede suponerse que la desviación estándar del gasto anual en camisas de los hombres es de $50000.
5. Se tienen 1800 empresas en el sector industrial, de las cuales se desea seleccionar una muestra con el
propósito de estimar el número medio de vendedores que tienen. Se sabe que las empresas tienen no
menos de 3 vendedores y no más de 28 vendedores. ¿De qué tamaño se ha de seleccionar la muestra si
se desea tener una confianza de 0.90 de que al estimar el número medio de vendedores por empresa, el
máximo error en la estimación no sobrepase de dos vendedores?
6. En una empresa que tiene 2500 empleados se desea seleccionar una muestra aleatoria simple con el
propósito de estimar cual es el tiempo medio de experiencia que tienen en su actual ocupación. ¿Cuántos
empleados serán necesarios seleccionar si se desea tener una confianza de 0.90 de que el máximo error
en la estimación no sobrepase de medio año?. Se conoce que el empleado con menos experiencia en su
cargo actual tiene tres meses y el de más experiencia tiene quince años.
7. Se desea investigar el número medio de unidades semanales de un producto que consumen los
compradores. En una prueba piloto se tomaron quince compradores de producto y se encontró que
semanalmente consumían: 4, 9, 12, 8, 15, 3, 7, 5, 12, 10, 8, 12, 11, 15, 6. ¿De qué tamaño ha de
seleccionarse la muestra si se desea tener una confianza de 0.98 de que la estimación se encuentre a más
o menos 0.5 unidades del promedio verdadero?
8. Para el lanzamiento de un nuevo producto industrial al mercado, que en la actualidad se importa, se
desea estimar cual es el valor medio de kilos anuales que compran las empresas de este producto. En una
muestra piloto con 10 empresas se encontró que ellas compraban (en kilos): 220, 110, 850, 340, 320, 410,
750, 80, 290, 350. ¿De qué tamaño se debe seleccionar la muestra si se desea tener un nivel de confianza
de 0.98, de que la estimación se encuentre a más o menos 30 kilos del promedio verdadero que compran
anualmente las empresas?
9. Para un mercado de prueba, se desea establecer el tamaño de muestra que se debe seleccionar para
estimar la proporción real de consumidores satisfechos con un cierto producto, dentro de más o menos 0.03
a un nivel de confianza de 0.90. No se tiene idea de cuál es la proporción de consumidores satisfechos.
10. Una agencia de publicidad desea estimar la proporción de televidentes en una ciudad que observaron
un mensaje publicitario emitido por un canal de televisión en un programa especial. ¿De qué tamaño se ha
de seleccionar la muestra si desea tener una confianza de 0.95 de que el máximo error en la estimación se
encuentre a lo más de 0.05 de la proporción real? Telefónicamente se contactaron 50 televidentes y 15
dijeron haber observado el mensaje publicitario.
11. En una empresa que tiene 1200 trabajadores se va a realizar un estudio por muestreo. Interesa
establecer la proporción de trabajadores que están actualmente realizando algún tipo de estudios. ¿De qué
tamaño habría de seleccionarse la muestra si se desea tener una confianza de 0.95 de que el error máximo
UJTL_DCB_APUNTES DE ESTADISTICA INFERENCIAL_ MARA
24
en la estimación no exceda de 0.035?. Según un estudio realizado hace algún tiempo, el 20% de los
trabajadores seguían algún tipo de estudios.
AYUDA DE MUESTREO
MUESTREO ALEATORIO SIMPLE (MAS)
Se debe utilizar en aquellos casos donde las características de los elementos son
homogéneas.
La probabilidad de selección de cada elemento es la misma P=(n/N).
Se debe determinar el tamaño de muestra para cada objetivo.
El procedimiento de selección debe ser aleatorio.
La empresa de acueducto y alcantarillado de una ciudad está interesada en realizar una
investigación acerca del consumo promedio de agua (X-metros cúbicos) y la proporción de
familias que cuentan con el servicio de energía eléctrica (¿A- Posee el servicio de energía
eléctrica?
Variable S2 E P Ep
Consumo -X 25 3
Energía eléctrica - A 0.96 0.10
a. Determine el tamaño de muestra con un 95%.
𝒏𝟎= 𝟐𝟓
=𝟏𝟎.𝟔𝟕𝟏𝟏
𝒏𝟎=𝟎.𝟗𝟔𝒙𝟎.𝟎𝟒=𝟏𝟒.𝟕𝟓𝟏𝟕 El tamaño de muestra
𝟑 𝟎.𝟏
(𝟏.𝟗𝟔)𝟐 (𝟏.𝟗𝟔)𝟐
definitivo es 12.
𝟏𝟎.𝟔𝟕𝟏𝟏 𝟏𝟒.𝟕𝟓𝟏𝟕
𝒏= 𝟏𝟎.𝟔𝟕𝟏𝟏 = 𝟗. 𝟎𝟓𝟗𝟖 ≈ 𝟗 𝒏= 𝟏𝟒.𝟕𝟓𝟏𝟕 = 𝟏𝟏. 𝟔𝟗𝟔𝟏 ≈ 𝟏𝟐
𝟏+ 𝟏+
𝟔𝟎 𝟔𝟎
b. Seleccione los elementos mediante el uso del MAS, c3f6, c8f2, c5f10, c2f3.
# X A
1 11 22 NO
2 56 18 NO
3 05 11 NO
4 53 19 NO
5 48 24 SI
6 52 21 NO
7 51 27 NO
8 33 24 NO
9 46 12 NO
10 22 11 NO
11 28 16 NO
12 04 9 NO
c. Calcule y analice la media, la desviación estándar, coeficiente de variación, y la proporción de
familias que cuentan con el servicio de energía eléctrica.
Media:17.8333 El consumo promedio de agua por familia es de 17.8333 metros cúbicos
Desviación estándar:6.0126 En promedio el consumo de agua de cada familia varia en 6.0126
metros cubicos con respecto al consumo promedio.
Coeficiente de variación: 33.7255% En este caso las estimaciones se deben usar con precaución
y el uso del muestreo aleatorio no es el más indicado dada la alta variabilidad de la variable
analizada.
Proporción de las familias con el servicio de energía eléctrica: 0.08 el 8% de las familias cuentas
con el servicio de energía eléctrica.
d. Si el tamaño de muestra solo se determinara por la proporción y las demás características
permanecen igual, cuál sería el tamaño de muestra en las siguientes situaciones si la proporción:
UJTL_DCB_APUNTES DE ESTADISTICA INFERENCIAL_ MARA
25
𝟓𝟒.𝟐𝟎𝟓𝟎
es inferior al 17%?𝒏𝟎=𝟎.𝟏𝟕𝒙𝟎.𝟖𝟑=𝟓𝟒.𝟐𝟎𝟓𝟎 𝒏= 𝟓𝟒.𝟐𝟎𝟓𝟎 = 𝟐𝟖. 𝟒𝟕𝟕𝟕 ≈ 𝟐𝟗
𝟎.𝟏 𝟏+
(𝟏.𝟗𝟔)𝟐 𝟔𝟎
𝟎.𝟐𝟖𝒙𝟎.𝟕𝟐 𝟕𝟕.𝟒𝟒𝟔𝟕
se encuentra entre el 15% y el 28%?𝒏𝟎 = 𝟎.𝟏 𝟐 = 𝟕𝟕. 𝟒𝟒𝟔𝟕 𝒏= 𝟕𝟕.𝟒𝟒𝟔𝟕 = 𝟑𝟑. 𝟖𝟎𝟖𝟎 ≈ 𝟑𝟒
( ) 𝟏+
𝟏.𝟗𝟔 𝟔𝟎
𝟎.𝟓𝟎𝒙𝟎.𝟓𝟎 𝟗𝟔.𝟎𝟒
se desconoce?𝒏𝟎 = 𝟎.𝟏 𝟐 = 𝟗𝟔. 𝟎𝟒 𝒏= 𝟗𝟔.𝟎𝟒 = 𝟑𝟔. 𝟗𝟐𝟗𝟎 ≈ 𝟑𝟕
( ) 𝟏+
𝟏.𝟗𝟔 𝟔𝟎
Marco muestral
X A CASA X A CASA X A
1 17 NO 21 12 NO 41 24 NO
2 24 SI 22 11 NO 42 17 SI
3 15 NO 23 18 NO 43 27 NO
4 9 NO 24 24 SI 44 22 NO
5 11 NO 25 27 NO 45 15 NO
6 16 SI 26 24 NO 46 12 NO
7 10 NO 27 19 SI 47 15 NO
8 13 NO 28 16 NO 48 24 SI
9 8 NO 29 27 NO 49 27 NO
10 14 NO 30 22 NO 50 22 SI
11 22 NO 31 19 SI 51 27 NO
12 32 SI 32 34 NO 52 21 NO
13 31 SI 33 24 NO 53 19 NO
14 22 NO 34 14 NO 54 15 NO
15 19 NO 35 17 NO 55 14 SI
16 24 SI 36 16 NO 56 18 NO
17 26 NO 37 21 NO 57 24 NO
18 23 SI 38 17 NO 58 21 SI
19 24 NO 39 23 NO 59 14 NO
20 32 NO 40 21 NO 60 17 SI
5. Se tienen 1800 empresas en el sector industrial, de las cuales se desea seleccionar una muestra con el
propósito de estimar el número medio de vendedores que tienen. Se sabe que las empresas tienen no
menos de 3 vendedores y no más de 28 vendedores. ¿De qué tamaño se ha de seleccionar la muestra si
se desea tener una confianza de 0?90 de que al estimar el número medio de vendedores por empresa, el
máximo error en la estimación no sobrepase de dos vendedores?
(𝟐𝟖−𝟑)𝟐 𝟐𝟔.𝟐𝟔𝟓𝟔
𝑺𝟐 = = 𝟑𝟗. 𝟎𝟔𝟐𝟓 𝒏𝟎=𝟑𝟗.𝟎𝟔𝟐𝟓=𝟐𝟔.𝟐𝟔𝟓𝟔 𝒏= 𝟐𝟔.𝟐𝟔𝟓𝟔 = 𝟐𝟓. 𝟖𝟖𝟕𝟖 ≈ 𝟐𝟔
𝟏𝟔 𝟐 𝟏+
(𝟏.𝟔𝟒)𝟐 𝟏𝟖𝟎𝟎
7. Se desea investigar el número medio de unidades semanales de un producto que consumen los
compradores. En una prueba piloto se tomaron quince compradores de producto y se encontró que
semanalmente consumían: 4, 9, 12, 8, 15, 3, 7, 5, 12, 10, 8, 12, 11, 15, 6. ¿De qué tamaño ha de
seleccionarse la muestra si se desea tener una confianza de 0?98 de que la estimación se encuentre a más
o menos 0.5 unidades del promedio verdadero?
𝑆 2 = 13.9810 𝒏𝟎=𝟏𝟑.𝟗𝟖𝟏𝟎=𝟑𝟎𝟑.𝟔𝟎𝟓𝟖≈𝟑𝟎𝟒
𝟎.𝟓
(𝟐.𝟑𝟑)𝟐
10. Una agencia de publicidad desea estimar la proporción de televidentes en una ciudad que observaron
un mensaje publicitario emitido por un canal de televisión en un programa especial. ¿De qué tamaño se ha
de seleccionar la muestra si desea tener una confianza de 0?95 de que el máximo error en la estimación se
UJTL_DCB_APUNTES DE ESTADISTICA INFERENCIAL_ MARA
26
encuentre a lo más de 0.05 de la proporción real? Telefónicamente se contactaron 50 televidentes y 15
dijeron haber observado el mensaje publicitario.
𝟎. 𝟑𝟎𝒙𝟎. 𝟕𝟎
𝒏𝟎 = = 𝟑𝟐𝟐. 𝟔𝟗𝟒𝟒 ≈ 𝟑𝟐𝟑
𝟎. 𝟎𝟓 𝟐
( )
𝟏. 𝟗𝟔
MUESTREO SISTEMATICO DE ELEMENTOS (MES, Caso cuando el tamaño de muestra es múltiplo
de la población))
Las características de los elementos deben ser homogéneas o heterogéneas.
La probabilidad de selección de cada elemento es la misma. P=(n/N).
El procedimiento sistemático se invalida cuando existe un patrón que destruye la aleatoriedad.
Se usan las mismas formulas del MAS para determinar el tamaño de muestra.
N=60 n=12 F=(60/12)=5
Se debe seleccionar un número aleatorio entre 01 y 05 (c3f6)
# X A
1 05 11 NO
2 10 14 NO
3 15 19 NO
4 20 32 NO
5 25 27 NO
6 30 22 NO
7 35 17 NO
8 40 21 NO
9 45 15 NO
10 50 22 SI
11 55 14 SI
12 60 17 SI
MUESTREO ALEATORIO SIMPLE (MAS)
Se debe utilizar en aquellos casos donde las características de los elementos son
homogéneas.
La probabilidad de selección de cada elemento es la misma P=(n/N).
Se debe determinar el tamaño de muestra para cada objetivo.
El procedimiento de selección debe ser aleatorio.
La empresa de acueducto y alcantarillado de una ciudad está interesada en realizar una
investigación acerca del consumo promedio de agua (X-metros cúbicos) y la proporción de
familias que cuentan con el servicio de energía eléctrica (A- Posee el servicio de energía
eléctrica?
Variable S2 E P Ep
Consumo -X 25 3
Energía eléctrica - A 0.96 0.10
a. Determine el tamaño de muestra con un 90%.
𝒏𝟎= 𝟐𝟓
=𝟕.𝟒𝟕𝟏𝟏
𝒏𝟎=𝟎.𝟗𝟔𝒙𝟎.𝟎𝟒=𝟏𝟎.𝟑𝟐𝟖𝟏 El tamaño de muestra
𝟑 𝟎.𝟏
(𝟏.𝟔𝟒)𝟐 (𝟏.𝟔𝟒)𝟐
definitivo es 9 .
𝟕.𝟒𝟕𝟏𝟏 𝟏𝟎.𝟑𝟐𝟖𝟏
𝒏= 𝟕.𝟒𝟕𝟏𝟏 = 𝟔. 𝟔𝟒𝟑𝟖 ≈ 𝟕 𝒏= 𝟏𝟎.𝟑𝟐𝟖𝟏 = 𝟖. 𝟖𝟏𝟏𝟒 ≈ 𝟗
𝟏+ 𝟏+
𝟔𝟎 𝟔𝟎
b. Seleccione los elementos mediante el uso del MAS, c3f6, c8f2, c5f10, c2f3.
UJTL_DCB_APUNTES DE ESTADISTICA INFERENCIAL_ MARA
27
# X A
1 11 22 NO
2 56 18 NO
3 05 11 NO
4 53 19 NO
5 48 24 SI
6 52 21 NO
7 51 27 NO
8 33 24 NO
9 46 12 NO
Marco muestral
X A CASA X A CASA X A
1 17 NO 21 12 NO 41 24 NO
2 24 SI 22 11 NO 42 17 SI
3 15 NO 23 18 NO 43 27 NO
4 9 NO 24 24 SI 44 22 NO
5 11 NO 25 27 NO 45 15 NO
6 16 SI 26 24 NO 46 12 NO
7 10 NO 27 19 SI 47 15 NO
8 13 NO 28 16 NO 48 24 SI
9 8 NO 29 27 NO 49 27 NO
10 14 NO 30 22 NO 50 22 SI
11 22 NO 31 19 SI 51 27 NO
12 32 SI 32 34 NO 52 21 NO
13 31 SI 33 24 NO 53 19 NO
14 22 NO 34 14 NO 54 15 NO
15 19 NO 35 17 NO 55 14 SI
16 24 SI 36 16 NO 56 18 NO
17 26 NO 37 21 NO 57 24 NO
18 23 SI 38 17 NO 58 21 SI
19 24 NO 39 23 NO 59 14 NO
20 32 NO 40 21 NO 60 17 SI
MUESTREO SISTEMATICO DE ELEMENTOS (MES, caso cuando el tamaño de muestra no es múltiplo de
la población)
Las características de los elementos deben ser homogéneas o heterogéneas.
La probabilidad de selección de cada elemento es la misma. P=(n/N).
El procedimiento sistemático se invalida cuando existe un patrón que destruye la aleatoriedad.
Se usan las mismas formulas del MAS para determinar el tamaño de muestra.
N=60 n=9 F=(60/9)=6.66677
Se debe seleccionar un número aleatorio entre 01 y 07 (c3f6)r=05
Con el procedimiento sistemático se seleccionan, 05, 12, 19, 26, 33, 40, 47,54. Dado que no se puede
seguir seleccionando mediante el procedimiento sistemático porque no está completo el segmento, solo
existen cuatro elementos, el elemento 9 se selecciona aleatoriamente de la c3f6, entre las casas 57,58,59 y
60, entonces el elemento elegido es el 57, el cual se encuentra en la fila de 61 de la tabla de números
aleatorios, luego la muestra sistemática es:.
# X A
1 05 11 NO
2 12 32 SI
3 19 24 NO
4 26 24 NO
5 33 24 NO
UJTL_DCB_APUNTES DE ESTADISTICA INFERENCIAL_ MARA
28
6 40 21 NO
7 47 15 NO
8 54 15 NO
9 57 24 NO
Marco Muestral
X A CASA X A CASA X A
1 17 NO 21 12 NO 41 24 NO
2 24 SI 22 11 NO 42 17 SI
3 15 NO 23 18 NO 43 27 NO
4 9 NO 24 24 SI 44 22 NO
5 11 NO 25 27 NO 45 15 NO
6 16 SI 26 24 NO 46 12 NO
7 10 NO 27 19 SI 47 15 NO
8 13 NO 28 16 NO 48 24 SI
9 8 NO 29 27 NO 49 27 NO
10 14 NO 30 22 NO 50 22 SI
11 22 NO 31 19 SI 51 27 NO
12 32 SI 32 34 NO 52 21 NO
13 31 SI 33 24 NO 53 19 NO
14 22 NO 34 14 NO 54 15 NO
15 19 NO 35 17 NO 55 14 SI
16 24 SI 36 16 NO 56 18 NO
17 26 NO 37 21 NO 57 24 NO
18 23 SI 38 17 NO 58 21 SI
19 24 NO 39 23 NO 59 14 NO
20 32 NO 40 21 NO 60 17 SI
Muestreo aleatorio estratificado
Trata de obviar las dificultades que presentan los anteriores ya que simplifican los procesos y suelen
reducir el error muestral para un tamaño dado de la muestra. Los elementos dentro de un estrato deben ser
tan homogéneos como sea posible, pero los elementos entre los estratos deben ser tan heterogéneos
como sea posible. Las variables de estratificación también deben estar muy relacionadas con las
características de interés. Ejemplo, tipo de cliente (con tarjeta de crédito o sin tarjeta de crédito), producción
de unidades por tipo de máquina (Automática, semiautomática, manual).
Este tipo de muestreo consiste en considerar categorías típicas diferentes entre sí (estratos:h) que poseen
gran homogeneidad respecto a alguna característica (se puede estratificar, por ejemplo, según la profesión,
el municipio de residencia, el sexo, el estado civil, etc.). Lo que se pretende con este tipo de muestreo es
asegurarse de que todos los estratos de interés estarán representados adecuadamente en la muestra.
Cada estrato funciona independientemente, pudiendo aplicarse dentro de ellos el muestreo aleatorio simple
o el sistemático para elegir los elementos concretos que formarán parte de la muestra. En ocasiones las
dificultades que plantean son demasiado grandes, pues exige un conocimiento detallado de la población.
(Tamaño geográfico, sexos, edades,...).
La distribución de la muestra en función de los diferentes estratos se denomina afijación, y puede ser de
diferentes tipos:
1
Afijación Simple o igual: A cada estrato le corresponde igual número de elementos muéstrales. 𝑊𝑖 =
ℎ
donde 𝑊𝑖 es llamado factor de ponderación o de afijación.
Afijación Proporcional: La distribución se hace de acuerdo con el peso (tamaño) de la población en cada
estrato.
𝑁
𝑊𝑖 = 𝑖 , donde 𝑁𝑖 es el tamaño de la población del estrato i y N es el tamaño de la población total.
𝑁
i=1,2,3,4,5,….,h
UJTL_DCB_APUNTES DE ESTADISTICA INFERENCIAL_ MARA
29
Afijación Óptima: Se tiene en cuenta la previsible dispersión de los resultados, de modo que se considera
la proporción y la desviación típica. Tiene poca aplicación ya que no se suele conocer la desviación
estándar de los estratos
Para la media (µ) es : Para la proporción (𝜋)es:
𝑁 .𝑆
𝑊𝑖 = ∑ 𝑖 𝑖 donde 𝑆𝑖 es la desviación estándar del 𝑊𝑖 = ∑
𝑁𝑖 .√𝑃𝑖 .𝑄𝑖
donde 𝑃𝑖 y 𝑄𝑖 son la probabilidad de
𝑁𝑖 .𝑆𝑖 𝑁𝑖 .√𝑃𝑖 .𝑄𝑖
estrato i. éxito y probabilidad de fracaso.
El tamaño de muestra es: El tamaño de muestra es:
𝑁2 .𝑆2
∑ 𝑖 𝑖 𝑁 2. 𝑃 . 𝑄
𝑛=
𝑤𝑖 ∑ 𝑖 𝑖 𝑖
𝐸
𝑁2 ( )2 + ∑ 𝑁𝑖 .𝑆𝑖2
𝑤𝑖
𝑍 𝑛=
𝐸
𝑁 2 ( )2 + ∑ 𝑁𝑖 𝑃𝑖 . 𝑄𝑖
𝑍
Muestreo aleatorio por conglomerados
Los métodos presentados hasta ahora están pensados para seleccionar directamente los elementos de la
población, es decir, que las unidades muestrales son los elementos de la población. En el muestreo por
conglomerados la unidad muestral es un grupo de elementos de la población que forman una unidad, a la
que llamamos conglomerado. Es la selección de grupos de unidades de estudio, en lugar de individuos,
generalmente son unidades geográficas u organizacionales. No requiere marco muestral de las unidades
de estudio.
Las unidades hospitalarias, los departamentos universitarios, una caja de determinado producto, etc., son
conglomerados naturales. En otras ocasiones se pueden utilizar conglomerados no naturales como, por
ejemplo, las urnas electorales.
Cuando los conglomerados son áreas geográficas suele hablarse de "muestreo por áreas", en el que los
conglomerados consisten en áreas geográficas, como barrios, cuadras, calles, etc.. El muestreo por
conglomerados consiste en seleccionar aleatoriamente un cierto número de conglomerados (el necesario
para alcanzar el tamaño muestral establecido) y en investigar después todos los elementos pertenecientes
a los conglomerados elegidos.
1.1.2 Muestreo no probabilístico
A veces, para estudios exploratorios, el muestreo probabilístico resulta excesivamente costoso y se acude
a métodos no probabilísticos, aun siendo conscientes de que no sirven para realizar generalizaciones
(estimaciones inferenciales sobre la población), pues no se tiene certeza de que la muestra extraída sea
representativa, ya que no todos los sujetos de la población tienen la misma probabilidad de ser elegidos. En
general se seleccionan a los sujetos siguiendo determinados criterios procurando, en la medida de lo
posible, que la muestra sea representativa.
En algunas circunstancias los métodos estadísticos permiten resolver los problemas de representatividad
aun en situaciones de muestreo no probabilístico, por ejemplo, los estudios de caso-control, donde los
casos no son seleccionados aleatoriamente de la población.
Entre los métodos de muestreo no probabilísticos más utilizados en investigación encontramos:
Muestreo por cuotas
También denominado en ocasiones "accidental". Se asienta generalmente sobre la base de un buen
conocimiento de los estratos de la población y/o de los individuos más "representativos" o "adecuados" para
los fines de la investigación. Mantiene, por tanto, semejanzas con el muestreo aleatorio estratificado, pero
no tiene el carácter de aleatoriedad de aquél.
En este tipo de muestreo se fijan unas "cuotas" que consisten en un número de individuos que reúnen unas
determinadas condiciones, por ejemplo: 20 individuos de 25 a 40 años, de sexo femenino y residentes en la
ciudad de Armenia (Departamento del Quindío). Una vez determinada la cuota se eligen los primeros que
UJTL_DCB_APUNTES DE ESTADISTICA INFERENCIAL_ MARA
30
se encuentren que cumplan esas características. Este método se utiliza mucho en las encuestas de
opinión. El muestreo de cuota, en el que la composición de la muestra debe reflejar la composición de la
población en alguna característica preseleccionada, con frecuencia tiene un componente no aleatorio en el
proceso de selección. Recuerde que las muestras no aleatorias se pueden describir, pero no se pueden
usar para hacer inferencias.
Muestreo intencional o de conveniencia
Este tipo de muestreo se caracteriza por un esfuerzo deliberado de obtener muestras "representativas"
mediante la inclusión en la muestra de grupos supuestamente típicos. Es muy frecuente su utilización en
sondeos preelectorales de zonas que en anteriores votaciones han marcado tendencias de voto.
También puede ser que el investigador seleccione directa e intencionadamente los individuos de la
población.
El caso más frecuente de este procedimiento es utilizar como muestra los individuos a los que se tiene fácil
acceso (los profesores de universidad emplean con mucha frecuencia a sus propios alumnos). Este tipo de
muestreo se utiliza para etapas iniciales o exploratorias de un proceso de investigación como base de
generación de hipótesis.
No todos los planes muestrales, sin embargo, comprenden una selección aleatoria. Es probable que usted
haya oído de las encuestas telefónicas no aleatorias, en las que las personas que desean expresar apoyo a
una pregunta llaman a un “número 900” y los que se oponen llaman a un segundo “número 900”. Cada
persona debe pagar por su llamada. Es obvio que quienes llaman no representan la población en general.
Este tipo muestral es una forma de una muestra de conveniencia, es decir, una muestra que se puede
obtener de manera fácil y sencilla sin selección aleatoria. Hacer publicidad a personas a quienes se les
pagará una cuota por participar en un experimento produce una muestra de conveniencia.
Bola de nieve
(Caso particular del muestreo de conveniencia). Es útil cuando es difícil localizar a los integrantes de una
población objeto de estudio. Inicia con unos participantes que tienen un atributo determinado; ellos
responden una encuesta y se busca que faciliten la colaboración de otras personas conocidas por ellos
(referidos). Se localiza a algunos individuos, los cuales conducen a otros, y estos a otros, y así hasta
conseguir una muestra suficiente. Este tipo se emplea muy frecuentemente cuando se hacen estudios con
poblaciones "marginales", delincuentes, sectas, determinados tipos de enfermos, etc.
Muestreo Discrecional
A criterio del investigador los elementos son elegidos sobre lo que él cree que pueden aportar al estudio. El
muestreo de juicio permite que la persona que haga el muestreo decida quién estará o no incluido en la
muestra.
A continuación, se presentan las características más sobresalientes y las ventajas y desventajas de los
diseños de muestreo más importantes:
TIPO CARACTERÍSTICAS VENTAJAS DESVENTAJAS
Muestreo Se usa en los casos donde Sencillo y de Requiere que se posea
Aleatorio Simple la característica de estudio es fácil comprensión. de antemano un
(MAS) homogénea. Cálculo rápido listado completo de toda la
Se selecciona una muestra de tamaño de medias población. Cuando se trabaja
n de una población de N unidades, y varianzas. con muestras pequeñas
cada elemento tiene una probabilidad de Se basa en la es posible que no represente
inclusión igual y conocida de n/N. teoría estadística, y a la población adecuadamente.
existen paquetes
informáticos para
analizar los datos
UJTL_DCB_APUNTES DE ESTADISTICA INFERENCIAL_ MARA
31
Muestreo Se usa en aquellos casos donde la Fácil de aplicar. Si el intervalo de muestreo
Sistemático característica de estudio puede No siempre es coincide con el comportamiento
de Elementos (MSE)ser homogénea o heterogénea. necesario tener cíclico del fenómeno de interés,
Conseguir un listado de los N un listado las estimaciones obtenidas a
elementos de la población. de toda la población. partir de la muestra pueden
Determinar tamaño muestral n. Cuando la población contener sesgo
Definir un intervalo F= N/n. Está ordenada de selección.
Elegir un número aleatorio, r, entre 1 y siguiendo
F (r= arranque aleatorio). una tendencia
conocida, asegura
Seleccionar los elementos de la lista. una cobertura de
unidades
de todos los tipos.
Muestreo En ciertas ocasiones resultará Tiende a asegurar que Se ha de conocer la distribución
Estratificado conveniente estratificar la muestra la muestra represente en la población de las variables
según ciertas variables de interés. Para adecuadamente a la utilizadas
ello debemos conocer la composición población en función para la estratificación.
estratificada de la población objetivo. de unas variables
Una vez calculado el tamaño muestral seleccionadas.
apropiado, este se distribuye de Se obtienen
acuerdo a la afijación seleccionada. estimaciones más
precisas
Su objetivo es
conseguir una muestra
lo más semejante
posible a la población
en lo que a las
variables de
estratificación se
refiere.
Muestreo dLa población está conformada por Es muy eficiente El error estándar es mayor
Conglomerados grupos que en teoría son imágenes de cuando la población que en el muestreo
la población (Universidades del país, es muy grande y aleatorio simple o estratificado.
Empresas, y dentro de ellas se pueden dispersa. No es El cálculo del error estándar es
conformar estratos, etc.) Se realizan preciso tener un complejo.
varias fases de muestreo sucesivas listado de toda la
(polietápico) La necesidad de listados población, sólo de
de las unidades de una etapa se limita las unidades primarias
a aquellas unidades de muestreo de muestreo.
seleccionadas en la etapa anterior.
Tenga cuidado al efectuar un estudio muestral y esté atento a estos problemas que se presentan con
frecuencia:
• No respuesta: Usted ha seleccionado su muestra aleatoria y enviado sus cuestionarios, pero sólo 50% de
los entrevistados devolvió sus cuestionarios. ¿Las respuestas que usted recibió son representativas de toda
la población o están sesgadas porque sólo quienes eran particularmente obstinados en el tema fueron
escogidos para responder?
• Cobertura demasiado baja: Usted ha seleccionado su muestra aleatoria usando registros telefónicos
como una base de datos. ¿La base de datos que usó sistemáticamente excluye ciertos segmentos de la
población, quizá aquellos que no tienen teléfono?
UJTL_DCB_APUNTES DE ESTADISTICA INFERENCIAL_ MARA
32
• Sesgo verbal: El cuestionario de usted puede tener preguntas que son demasiado complicadas o tienden
a confundir al lector. Posiblemente las preguntas son sensibles por naturaleza, por ejemplo, “¿Alguna vez
ha consumido usted drogas?” o “¿Alguna vez ha engañado en su declaración de impuestos?” y quienes
responden no contestan con la verdad.
Se han diseñado métodos para resolver algunos de estos problemas, pero sólo si usted sabe que existen.
Si su encuesta está sesgada por cualquiera de estos problemas, entonces sus conclusiones no serán muy
confiables, aunque haya seleccionado una muestra aleatoria.
Error en el muestreo: Tras entender la importancia de escoger una muestra representativa de la
población, veamos que para lograr esto, podemos seleccionar, por ejemplo, una muestra aleatoria simple
de la población, pero es muy improbable que la media de la muestra sea idéntica a la media de la
población. De la misma manera, tal vez la desviación estándar u otra medición que se calcule con base en
la muestra no sea igual al valor correspondiente de la población, Por tanto, es posible que existan ciertas
diferencias entre los estadísticos de la muestra (como la media o la desviación estándar), y los parámetros
de población correspondientes. A dicha diferencia se la conoce como error de muestreo.
1.2 DISTRIBUCIONES MUESTRALES
Las distribuciones muestrales desempeñan un importante papel en el desarrollo de los procedimientos de
estimación. La distribución muestral de una estadística es la distribución de probabilidad para los posibles
valores de la estadística, que resulta cuando muestras aleatorias de tamaño n se sacan repetidamente de
la población.
Teorema del límite central: Si muestras aleatorias de n observaciones se sacan de una población no
normal con media finita µ y desviación estándar σ, entonces, cuando n es grande, la distribución de
muestreo de la media muestral 𝑥̅ está distribuida normalmente en forma aproximada, con media µ y
desviación estándar
σ/√𝑛 . La aproximación se hace más precisa cuando n se hace grande.
Cualquiera que sea su forma, la distribución muestral de 𝑥̅ siempre tiene una media idéntica a la media de
la población muestreada y una desviación estándar igual a la desviación poblacional estándar dividida entre
la raíz de n. En consecuencia, la dispersión de la distribución de medias muestrales es considerablemente
menor que la dispersión de la población muestreada.
El teorema del límite central se puede expresar de otro modo para aplicar a la suma de las mediciones
muestrales ∑ 𝑥𝑖 , que, cuando n se hace grande, también tiene una distribución aproximadamente normal
con media nµ y desviación estándar σ √𝑛 .
Esta es una distribución de tipo probabilístico que indica la probabilidad de que se presentan las medias de
todas las muestras del mismo tamaño en una población dada. Esta distribución se da en función de la
media, la desviación estándar de la población y el tamaño de la muestra. Para cada combinación de estos
valores, habrá una distribución de muestreo única de los valores de la media de la muestra.
EJEMPLO
Se desea analizar el número de horas extras que trabajan los empleados de un hospital en la semana:
Empleado Horas extras
González 2
Brijaldo 3
Vargas 5
Pérez 4
Aguilar 6
Fernández 7
UJTL_DCB_APUNTES DE ESTADISTICA INFERENCIAL_ MARA
33
Este grupo de empleados se considera como una población de fines de dar la idea de una distribución de
muestreo, al calcular la media de la población µ=4.5 y desviación típica σ=1.7078. Se pueden seleccionar
todos los tamaños de muestras posibles, pero para el ejemplo suponemos que la muestra será de tamaño
n=2, se pueden seleccionar 15 muestras de tamaño 2 de una población de tamaño 6 (se puede calcular con
6
la fórmula del número de combinaciones ( )=15, estas muestras son:
2
NÚMERO (𝑖) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
MUESTRAS 2;3 2;4 2;5 2,6 2;7 3;4 3;5 3;6 3;7 4;5 4;6 4;7 5;6 5;7 6;7
Media 𝑥̅𝑖 2.5 3 3.5 4 4.5 3.5 4 4.5 5 4.5 5 5.5 5.5 6 6.5
∑15
𝑖=1 𝑥̅𝑖 2.5 + 3 + 3.5 + 3.5 + 4 + 4 + 4.5 + 4.5 + 4.5 + 5 + 5 + 5.5 + 6 + 6.5 67.5
𝜇= = = = 4.5
6 15 15
( )
2
𝜎 𝑁−𝑛 1.7078 6−2
𝜎𝑥̅𝑖 = ∙√ = ∙√ = 1.08012345 =
√𝑛 𝑁−1 √2 6−1
∑(𝑥̅𝑖 −𝜇)2
√ =√(2.5 − 4.5)2 + (3 − 4.5)2 + (3.5 − 4.5)2 + ⋯ + (6 − .5)2 + (6.5 − .5)2)/15
𝑛
La distribución de frecuencias de las medias muestrales es:
𝒊 𝑥̅𝑖 𝒇 P(𝑥̅𝑖 ) 𝑥̅𝑖 ∙ 𝒇
1 2.5 1 1/15 2.5
2 3 1 1/15 3
3 3.5 2 2/15 7
4 4 2 2/15 8
5 4.5 3 3/15 13.5
6 5 2 2/15 10
7 5.5 2 2/15 11
8 6 1 1/15 6
9 6.5 1 1/15 6.5
Suma 15 1 67.5
∑9
1 𝑥̅𝑖 .𝑓
𝜇= 6 = (2.5+3+7+8+13.5+10+11+6+6.5)/15=67.5/15=4.5
( )
2
Se observa en este caso, que la media muestral más probable sería de 4.5.
EJEMPLO
Los saldos mensuales de 10 cuentas de ahorro en una sucursal bancaria en millones de pesos, se
presentaron de la siguiente manera:
Saldos 2.67 1.67 1.85 1.57 1.59 1.61 1.53 1.4 1.7 1.48
UJTL_DCB_APUNTES DE ESTADISTICA INFERENCIAL_ MARA
34
El promedio poblacional µ=1.707
Mediana poblacional 1.6
Desviación estándar poblacional σ=0.341790871
Usando nuestros conocimientos del curso anterior, no existe evidencia para decir que los datos tienen un
comportamiento Normal, dado que la media es superior a la mediana.
Con la ayuda de las gráficas de box-plot (caja y bigotes) y del histograma, se confirma lo dicho
anteriormente.
Si se seleccionan muestras aleatorias de tamaño 9 bajo el supuesto que esta se configura como una
población de cuentas de la entidad, podemos seleccionar 10 cuentas de tamaño 9 de la población de
10
tamaño 10. ( )=10
9
Las 10 muestras serán las siguientes:
MUESTRA
1 2 3 4 5 6 7 8 9 10
2.67 2.67 2.67 2.67 2.67 2.67 2.67 2.67 2.67 1.67
1.67 1.67 1.67 1.67 1.67 1.67 1.67 1.67 1.85 1.85
1.85 1.85 1.85 1.85 1.85 1.85 1.85 1.57 1.57 1.57
1.57 1.57 1.57 1.57 1.57 1.57 1.59 1.59 1.59 1.59
1.59 1.59 1.59 1.59 1.59 1.61 1.61 1.61 1.61 1.61
1.61 1.61 1.61 1.61 1.53 1.53 1.53 1.53 1.53 1.53
1.53 1.53 1.53 1.4 1.4 1.4 1.4 1.4 1.4 1.4
1.4 1.4 1.7 1.7 1.7 1.7 1.7 1.7 1.7 1.7
1.7 1.48 1.48 1.48 1.48 1.48 1.48 1.48 1.48 1.48
𝑥̅𝑖 𝑥̅1 𝑥̅2 𝑥̅3 𝑥̅4 𝑥̅5 𝑥̅6 𝑥̅7 𝑥̅8 𝑥̅9 𝑥̅10
1.73222 1.70778 1.74111 1.72667 1.71778 1.72 1.72222 1.69111 1.71111 1.6
∑ 𝑥̅𝑖
µ= =(1.73222+1.70778+……..+1.71111+1.6)/10=1.707
𝑛
𝜎 𝑁−𝑛 0.34179087 10−9
𝜎𝑥̅𝑖 = ∙√ = ∙√ = 0.0379767 =
√𝑛 𝑁−1 √9 10−1
∑(𝑥̅𝑖 −𝜇)2
√ =√((1.73222 − 1.707)2 + (1.70778 − 1.707)2 + ⋯ + (1.71111 − 1.707)2 + (1.6 − 1.707)2 )/15
𝑛
En la gráfica siguiente para un tamaño de muestra de 9, todavía el promedio muestral no tiene una
distribución aproximadamente Normal, si se pudiera contar con una población grande y seguir aumentando
el tamaño de muestra, el promedio muestral presenta se aproxima a una distribución Normal.
UJTL_DCB_APUNTES DE ESTADISTICA INFERENCIAL_ MARA
35
EJEMPLO 1
Un auditor toma una muestra de tamaño 63 de una población muy grande de cuentas por cobrar; la
desviación estándar de la población se desconoce. La desviación estándar de la muestra fue de $43000
pesos. El valor real de la
media de las cuentas por cobrar se cree que es de $266000.
a. ¿Cuál es la probabilidad de que la media de la muestra pudiera ser de $250000 o menos?
250000 − 266000
𝑃(𝑥̅ ≤ 250000) = 𝑃(𝑍 ≤ ) = 𝑃(𝑍 ≤ −2.95) = 0.00159
43000/√63
b. ¿Cuál es la probabilidad de que en esta muestra se encuentre una media de $260000 o más?
260000 − 266000
𝑃( 𝑥̅ ≥ 260000) = 𝑃(𝑍 ≥ ) = 𝑃(𝑍 ≥ −1.11) = 0.8665
43000/√63
c. ¿Cuál es la probabilidad de que la media de la muestra esté entre $275000 y $325000
275000 − 266000 325000 − 266000
𝑃(275000 ≤ 𝑥̅ ≤ 325000) = 𝑃( ≤𝑍≤ ) = 𝑃(1.66 ≤ 𝑍 ≤ 10.89)
43000/√63 43000/√63
= 1 − 0.9515 = 0.0485
d. Determine el número de cuentas por cobrar que tengan un valor entre $200000 y $260000,
suponga que el total de las cuentas por cobrar son de 615.
200000 − 266000 260000 − 266000
𝑃(200000 ≤ 𝑥̅ ≤ 260000) = 𝑃( ≤ 𝑍≤ ) = 𝑃(−12.18 ≤ 𝑍 ≤ −1.11)
43000/√63 43000/√63
= 0.1335 − 0 = 0.1335
El número total de cuentas por cobrar que tienen esa característica es 0.1335*n=83.1705≅83
EJEMPLO 2
Dado que la proporción es un caso especial de la media aritmética en que todos sus valores sólo son ceros
o unos y como el error estándar de la media 𝜎𝑥̅ =σ/√𝑛 y la varianza de un evento Bernoulli es 𝜋(1 − 𝜋), se
sigue que el error estándar de la proporción también se puede calcular como: 𝜎𝑝 =√𝜋(1 − 𝜋)/𝑛 .
Se desea determinar la proporción de las empresas que tuvieron utilidades en los años anteriores (π). De
seis empresas encuestadas (N), tres generan utilidades. Se toman muestras de tamaño cuatro y finalmente
se obtiene la distribución muestral de la proporción de las empresas que generan utilidades.
EMPRESA UTILIDAD=𝑋𝑖 𝑋𝑖 − 𝜋 (𝑋𝑖 − 𝜋)2
A SI=1 1-0.5=0.5 0.25
B SI=1 1-0.5=0.5 0.25
C SI=1 1-0.5=0.5 0.25
X NO=0 0-0.5=-0.5 0.25
Y NO=0 0-0.5=-0.5 0.25
UJTL_DCB_APUNTES DE ESTADISTICA INFERENCIAL_ MARA
36
Z NO=0 0-0.5=-0.5 0.25
1.25
π= (3/6)=0.5
∑(𝑋𝑖 −𝜋)2
𝜎𝜋2 = = 1.25/6=0.25 𝜎𝜋 =√0.25 =0.5
𝑁
𝜎𝜋 𝑁−𝑛 𝜋(1−𝜋) 𝑁−𝑛 0.5 6−4 0.5(1−0.5) 𝑁−𝑛
𝜎𝑝 = ∙√ =√ .√ = ∙√ =√ .√ = 0.158113883
√𝑛 𝑁−1 𝑛 𝑁−1 √4 6−1 𝑛 𝑁−1
El número total de muestras de tamaño 4 que pueden seleccionarse de una población de tamaño 6 son 15,
(6 4 )=15.
MUESTRAS MUESTRAS 𝒑 𝒑 * MUESTRAS 𝒑
AXYZ ABXY 1/4 2/4 ABCX 3/4
BXYZ BCXY 1/4 2/4 ABCY 3/4
CXYZ ACXY 1/4 2/4 ABCZ 3/4
ABXZ 2/4
BCXZ 2/4
ACXZ 2/4
ABYZ 2/4
BCYZ 2/4
ACYZ 2/4
*Es la proporción de las empresas que tuvieron utilidades en el año anterior
𝒇 𝑷(𝒑) 𝒑 ∗ 𝒇 𝒑 − 𝝁𝒑 𝒇 ∗ (𝒑 − 𝝁𝒑 )𝟐
0.25 3 3/15 0.75 0.25-0.5=-0.25 3.(-0.25)2=0.1875
0.5 9 9/15 4.5 0.5-0.5=0 9(0)2=0
0.75 3 3/15 2.25 0.75-0.5=0.25 3(0.25)2=0.1875
Suma 15 7.5 0.375
La media de la distribución de muestreo de la proporción o proporción de las proporciones muestrales es:
∑𝑝 ∗ 𝑓
𝜇𝑝 = 𝜋 = = 7.5/15 = 0.5
6
( )
4
∑ 𝑓 ∗ (𝑝 − 𝜇𝑝 )2
𝜎𝑝2 = = 0.375/15 = 0.025
6
( )
4
𝜎𝑝 = 0.158113883
EJEMPLO 3
De 2000 (N) distribuidores de computadoras en el país, se sabe que el 40% (π) desea incrementar sus
pedidos para el próximo periodo.
a. La probabilidad de que en una muestra de 400 distribuidores encontramos que una proporción de 46% o
más incrementen sus pedidos es de :
(𝑛𝑝 ± 0.5) − 𝑛𝜋 ((400 ∗ 0.46 − 0.5) − 400 ∗ 0.4)
𝑃(𝑝 ≥ 0.46) = 𝑃 𝑍 ≥ =𝑃 𝑍≥ =
𝑁−𝑛 2000 − 400
( √𝑛𝜋(1 − 𝜋)√ ( √400(0.4)(0.6)√
𝑁 − 1) 2000 − 1 )
P(Z≥2.68)=1-0.9963= 0.0037
b. La probabilidad de que en una encuesta de 200 distribuidores se encuentre que deseen incrementar sus
pedidos 30% o menos de los distribuidores es:
(𝑛𝑝±0.5)−𝑛𝜋 ((200∗0.3+0.5)−200∗0.4)
𝑃(𝑝 ≤ 0.30) = 𝑃(𝑍 ≤ ) = 𝑃(𝑍 ≤ ) =P(Z≤-3.00)=0.0013
√𝑛𝜋(1−𝜋)√(𝑁−𝑛)/(𝑁−1) √200(0.4)(0.6)√(2000−200)/(2000−1)
UJTL_DCB_APUNTES DE ESTADISTICA INFERENCIAL_ MARA
37
EJERCICIOS
1. La audiencia de un programa de televisión es de 0.2. Se planea una nueva evaluación con una muestra
de 200 televidentes, ¿Cuál es la probabilidad de que la audiencia sea de 0.25 o más?
2. Se conoce que 45 de cada 100 clientes de una empresa gustan de adquirir directamente sus artículos.
a. Si Usted encuesta a 300 clientes, ¿cuál es la probabilidad de que 100 o menos de ellos deseen adquirir
directamente sus artículos?
b. Si Usted encuesta a 275 clientes, ¿cuál es la probabilidad de que 130 o más de ellos deseen adquirir
directamente sus artículos?
3. La carga máxima para el elevador de un edificio de oficinas es de 2000 libras. La distribución de
frecuencia relativa de los pesos de todos los hombres y mujeres que usan el elevador tiene forma de
montículo (ligeramente sesgada a los pesos pesados), con una media (𝑋̅) igual a 150 libras y desviación
estándar (S) de 35 libras. ¿Cuál es el número máximo de personas que se pueden permitir en el elevador,
si se desea que el peso total de ellas exceda del peso máximo con una pequeña probabilidad (por ejemplo,
cercano a .01)? (Sugerencia: Si x1, x2, …, xn son observaciones independientes hechas en una variable
aleatoria x, y si x tiene media μ y varianza σ, entonces la media y varianza de ∑ 𝑥𝑖 , que, cuando n se hace
grande, también tiene una distribución aproximadamente normal con media nµ y desviación estándar σ √𝑛 ).
A continuación se presentan las distribuciones muestrales de los parámetros más usados:
Parámetro(s) Distribución de muestreo
µ (σ 2 conocida) (𝑥̅ − 𝜇)
𝑍= 𝜎 ~𝑁(0,1)
√𝑛
µ (σ 2 desconocida, n<30) (𝑥̅ − 𝜇)
𝑇= ~𝑡(𝑛−1)
𝑆
√𝑛
µ (σ2 desconocida, n30) (𝑥̅ − 𝜇)
𝑙𝑖𝑚 = 𝑍 ≈ 𝑁(0,1)
𝑛→∞ 𝑆
√𝑛
σ2 (𝑛 − 1)𝑆 2 2
𝜒2 = ~𝜒(𝑛−1)
𝜎2
µ1 - µ2 (𝜎12 𝑦 𝜎22 conocidas) (𝑥̅1 − 𝑥̅2 ) − (𝜇1 − 𝜇2 )
𝑍= ~𝑁(0,1)
𝜎2 𝜎22
√ 1 +
𝑛1 𝑛2
µ1 - µ2 ( 𝜎12 = 𝜎22 =𝜎 2
conocidas) 𝑍=
(𝑥̅1 −𝑥̅2 )−(𝜇1 −𝜇2 )
~𝑁(0,1)
1 1
𝜎√ +
𝑛1 𝑛2
µ1 - µ2 (𝑋̅1 − 𝑋̅2 ) − (𝜇1 − 𝜇2 )
(𝜎12 = 𝜎22 desconocidas, muestra grande) 𝑙𝑖𝑚 = 𝑍 ≈ 𝑁(0,1)
𝑛→∞
𝑆2 𝑆2
√ 1+ 2
𝑛1 𝑛2
µ1 - µ2 𝑇
(𝜎12 = 𝜎22 desconocidas, muestra (𝑋̅1 − 𝑋̅2 ) − (𝜇1 − 𝜇2 )
pequeña) = ~𝑡(𝑛1+𝑛2−2)
(𝑛 − 1)𝑆12 + (𝑛2 − 1)𝑆22 1 1
√( 1 )( + )
𝑛1 + 𝑛2 − 2 𝑛1 𝑛2
𝜋 𝑝−𝜋
𝑍= ~𝑁(0,1)
√𝜋(1 − 𝜋)
𝑛
UJTL_DCB_APUNTES DE ESTADISTICA INFERENCIAL_ MARA
38
𝜋1 − 𝜋2 (𝑝1 − 𝑝2 ) − (𝜋1 − 𝜋2 )
𝑍= ~𝑁(0,1)
𝑝1 (1 − 𝑝1 ) 𝑝2 (1 − 𝑝2 )
√ +
𝑛1 𝑛2
𝜎12 𝑆12
𝜎22 𝜎 2 𝑆12 . 𝜎22
𝐹 = 12 = 2 2 ~𝐹(𝑛1−1 , 𝑛2−1)
𝑆2 𝑆2 . 𝜎1
𝜎22
1.3 TIPOS DE ESTIMADORES
Para estimar el valor de un parámetro poblacional, se puede usar información de la muestra en la forma de
un estimador. Los estimadores se calculan usando información de las observaciones muestrales y, en
consecuencia, por definición son también estadísticas.
Un estimador es una regla, generalmente expresada como fórmula, que nos dice cómo calcular una
estimación basada en información de la muestra. Los estimadores se usan en dos formas diferentes:
• Estimación puntual: Con base en datos muestrales, se calcula un solo número para estimar el parámetro
poblacional. La regla o fórmula que describe este cálculo se denomina estimador puntual y el número
resultante recibe el nombre de estimación puntual.
• Estimación de intervalo: Con base en datos muestrales, dos números se calculan para formar un
intervalo dentro del cual se espera esté el parámetro. La regla o fórmula que describe este cálculo se
denomina estimador de intervalo y el par de números resultantes se llama estimación de intervalo o
intervalo de confianza.
Las distribuciones muestrales dan información que se puede usar para seleccionar el mejor estimador.
¿Qué características serían valiosas para tener un buen estimador? Las tres características más
importantes, entre otras son:
Insesgamiento: la distribución muestral del estimador puntual debe estar centrada sobre el verdadero valor
del parámetro a ser estimado. Esto es, el estimador no debe subestimar o sobreestimar de manera
consistente al parámetro de interés. Un estimador como éste se dice que es insesgado. Se dice que un
estimador de un parámetro es insesgado si la media de su distribución es igual al verdadero valor del
parámetro. De otro modo, se dice que el estimado está sesgado.
Eficiencia: otra característica deseable de un estimador es que la dispersión (medida por la varianza) de la
distribución muestral debe ser tan pequeña como sea posible. Esto asegura que, con una alta probabilidad,
una estimación individual caerá cerca del valor verdadero del parámetro. Las distribuciones muestrales
para dos estimadores insesgados, una con una varianza pequeña (En general, los estadísticos usan el
término varianza de un estimador cuando en realidad es la varianza de la distribución muestral del
estimador. Esta expresión contraída se usa casi universalmente). Considere dos estimadores 𝜃1 , 𝜃2 ,
suponga que ambos son insesgados y suponga que la varianza de 𝜃1 es menor que la de 𝜃2 , lo cual quiere
decir que los valores de 𝜃1 son más probables que los de 𝜃2 . O sea que vamos a encontrar a 𝜃1 más cerca
del valor del parámetro que a 𝜃2 . Esto hace que nuestras preferencias estén con 𝜃1 . Cuando un estimador
tiene una varianza menor que otro decimos que el estimador es más eficiente. Por supuesto que sería
UJTL_DCB_APUNTES DE ESTADISTICA INFERENCIAL_ MARA
39
preferible el estimador con la varianza más pequeña, porque las estimaciones tienden a estar más cerca
del verdadero valor del parámetro que en la distribución con la varianza más grande.
Consistencia: También llamada robustez, se utilizan cuando no es posible emplear estimadores de mínima
varianza, el requisito mínimo deseable para un estimador es que a medida que el tamaño de la muestra
crece, el valor del estimador tiende a ser el valor del parámetro.
En situaciones muestrales prácticas, es posible saber que la distribución muestral de un estimador está
centrada alrededor del parámetro que se trate de estimar, pero todo lo que se tiene es la estimación
calculada de las n mediciones contenidas en la muestra.
¿A qué distancia del verdadero valor del parámetro estará esta estimación? La distancia entre la estimación
y el verdadero valor del parámetro se denomina error de estimación.
Usted puede suponer que los tamaños muestrales son siempre grandes y, por tanto, que los estimadores
insesgados que estudiará tienen distribuciones muestrales que pueden ser aproximadas por una
distribución normal (por el teorema del límite central). Recuerde que, para cualquier estimador puntual con
una distribución normal, la regla empírica dice que aproximadamente 95% de todas las estimaciones
puntuales estarán a no más de dos (o más exactamente, 1.96) desviaciones estándar de la media de esa
distribución.
Para estimadores insesgados, esto implica que la diferencia entre el estimador puntual y el verdadero valor
del parámetro será menor a 1.96 desviaciones estándar o 1.96 errores estándar (SE= σ/√𝑛). Esta cantidad,
llamada el 95% de margen de error (o simplemente “margen de error”), da un límite superior práctico para
el error de estimación. Es posible que el error de estimación exceda este margen de error, pero eso es muy
poco probable.
Al reportar resultados de una investigación, es frecuente
que los investigadores agreguen ya sea la desviación
muestral estándar “s” (a veces llamada SD) o el error
estándar s/√𝑛 (por lo general llamado SE o SEM) a las
estimaciones de medias poblacionales.
Siempre se debe buscar una explicación en el texto del
informe que diga si el investigador está informando 𝑋̅± SD
o 𝑋̅±SE.
EJERCICIOS
1. En un experimento para evaluar la intensidad del instinto del hambre en ratas, 30 animales previamente
entrenados fueron privados de alimento durante 24 horas. Al término de ese periodo, cada rata fue puesta
en una jaula donde se les dio alimento si el animal presionaba una palanca. Para cada animal, se registró el
tiempo en el que continuaba presionando la barra (aun cuando no recibiera alimento). Si los datos dieron
una media muestral de 19.3 minutos con una desviación estándar de 5.2 minutos, estime el verdadero
tiempo medio y calcule el margen de error.
2. Los vehículos gemelos en Marte, Spirit y Opportunity, que vagaron por la superficie de Marte hace varios
años, encontraron evidencia de que una vez hubo agua en Marte, elevando la posibilidad de que hubiera
vida en el planeta. ¿Piensa usted que Estados Unidos debería proseguir un programa para enviar seres
humanos a Marte? Una encuesta de opiniones realizada por la Associated Press indicó que 49% de los
1034 adultos encuestados piensan que se debería continuar con ese programa.
a. Estime la verdadera proporción de estadounidenses que piensan que Estados Unidos debería continuar
con un programa para enviar seres humanos a Marte. Calcule el margen de error.
UJTL_DCB_APUNTES DE ESTADISTICA INFERENCIAL_ MARA
40
b. La pregunta planteada en el inciso a) fue sólo una de otras muchas respecto a nuestro programa
espacial que se formularon en la encuesta de opiniones. Si la Associated Press deseaba informar de un
error muestral que sería válido para toda la encuesta, ¿qué valor debería publicar?.
UJTL_DCB_APUNTES DE ESTADISTICA INFERENCIAL_ MARA
Вам также может понравиться
- Parcial Probabilidad EafitДокумент3 страницыParcial Probabilidad Eafitpedro gil0% (1)
- Parcial Probabilidad EafitДокумент3 страницыParcial Probabilidad Eafitpedro gil0% (1)
- GRUPAL Estadistica Unidad 2 Tarea3Документ29 страницGRUPAL Estadistica Unidad 2 Tarea3ximena sarmientoОценок пока нет
- PRÁCTICA-9 Distribuciones Muestrales (TS) 2020-IДокумент2 страницыPRÁCTICA-9 Distribuciones Muestrales (TS) 2020-IValeria Vargas Fernández0% (1)
- Nuevo Documento de Microsoft WordДокумент1 страницаNuevo Documento de Microsoft WordRoberto Esquivel Tr100% (1)
- Tarea Distribuciones NormalДокумент3 страницыTarea Distribuciones NormalRebeca Perez50% (2)
- Dist Normal Educ-1Документ29 страницDist Normal Educ-1José Luis Mamani BarbaitoОценок пока нет
- Distribución de ProbabilidadДокумент50 страницDistribución de Probabilidadpamela martinez cazorla100% (1)
- CAP - 14 - Distribución de Probabilidad de Variables AleatoriasДокумент28 страницCAP - 14 - Distribución de Probabilidad de Variables AleatoriasAMYNNXXXXОценок пока нет
- Deber Estadistica 2Документ25 страницDeber Estadistica 2Maria Alejandra Jimenez100% (1)
- Métodos de MuestreoДокумент3 страницыMétodos de MuestreoDenisse AlarconОценок пока нет
- Redes y SimulacionДокумент15 страницRedes y Simulaciondaniel0% (1)
- UntitledДокумент5 страницUntitledAchik BravoОценок пока нет
- Practica Uno Segundo ParcialДокумент3 страницыPractica Uno Segundo ParcialLourdes Calani CanaviriОценок пока нет
- Ejercicios de Distribución NormalДокумент1 страницаEjercicios de Distribución NormalJuan Camilo Daza100% (1)
- Estadística aplicada a la ingeniería y los negociosОт EverandEstadística aplicada a la ingeniería y los negociosРейтинг: 3.5 из 5 звезд3.5/5 (8)
- Actividad Evaluativa Tarea Eje3Документ4 страницыActividad Evaluativa Tarea Eje3Oscar Javier Avila Melo33% (3)
- Monografía EstadísticaДокумент12 страницMonografía EstadísticaEVER MILITON SUCLLI SUCLLIОценок пока нет
- Estadistica Aplicada A Los Negocios 7Документ29 страницEstadistica Aplicada A Los Negocios 7Leycrow Ratzinger100% (1)
- Intro InferenciaДокумент24 страницыIntro Inferenciazedanes0% (1)
- Problemario ProbabilidadДокумент25 страницProblemario ProbabilidadCarolina Díaz PáezОценок пока нет
- Distribucion HipergeometricaДокумент3 страницыDistribucion HipergeometricaCasagualpa100% (1)
- Probabilidad NormalДокумент38 страницProbabilidad NormalJuan Jesus Soria Quijaite100% (1)
- Normal Con DesarrolloДокумент9 страницNormal Con DesarrolloAntonio Hernandez PОценок пока нет
- Variables Aleatorias Continuas y Distribuciones de ProbabilidadДокумент74 страницыVariables Aleatorias Continuas y Distribuciones de ProbabilidadGustavo AguasОценок пока нет
- Word Final Final Estadistica 1Документ99 страницWord Final Final Estadistica 1jorge jayoОценок пока нет
- Recurso #2 - Ud IV - Est II - Distrib Normal-BinomialДокумент8 страницRecurso #2 - Ud IV - Est II - Distrib Normal-BinomialReynaldo SanabiaОценок пока нет
- U4 - Guía de ProbabilidadesДокумент6 страницU4 - Guía de Probabilidadesjuliajb33% (3)
- Ev. 2 EQ.2Документ19 страницEv. 2 EQ.2Luis fernando CRОценок пока нет
- Taller Nº2 Distribuciones Muestrales, Etc.Документ3 страницыTaller Nº2 Distribuciones Muestrales, Etc.Veronica Daza100% (1)
- Aproximacion de Poisson A Binomial OkДокумент21 страницаAproximacion de Poisson A Binomial OkCinthia Chávez FattuchtОценок пока нет
- Tarea de A II Abril 2011Документ3 страницыTarea de A II Abril 2011yalideОценок пока нет
- Distribucion MuestralДокумент6 страницDistribucion MuestralMedina Laura100% (1)
- VDFH PDFДокумент52 страницыVDFH PDFAmericoОценок пока нет
- Prueba de Ensay1Документ27 страницPrueba de Ensay1WillingtonRamirezPaleОценок пока нет
- Ejemplos PH Media y Proporción1 - 092139Документ37 страницEjemplos PH Media y Proporción1 - 092139JosueОценок пока нет
- Practica I Parcial, Estadistica Inferencial, 2014Документ3 страницыPractica I Parcial, Estadistica Inferencial, 2014alexandritamibebeОценок пока нет
- EstadisticaДокумент6 страницEstadisticaJohanna MotaОценок пока нет
- Guia 2P 11° EstadisticaДокумент13 страницGuia 2P 11° EstadisticaSebastián Sarmiento100% (1)
- Estadística Aplicada Práctica 6Документ7 страницEstadística Aplicada Práctica 6Carmen Leyda De JesusОценок пока нет
- Analisis de Datos CategoricosДокумент51 страницаAnalisis de Datos CategoricosAna floresОценок пока нет
- MuestreoДокумент5 страницMuestreoPedro JesúsОценок пока нет
- EJERCICIOS V Aleatorias Binomial PoissonДокумент12 страницEJERCICIOS V Aleatorias Binomial PoissonCarlos Alberto Torres100% (1)
- EJERCICIOS CAP 7 EstadisticaДокумент3 страницыEJERCICIOS CAP 7 EstadisticaMARCELO SEBASTIAN CARDENAS SEMPERTEGUIОценок пока нет
- Ejercicios de Distribución de ProbabilidadДокумент1 страницаEjercicios de Distribución de ProbabilidadPam FriasОценок пока нет
- Distribución Bernoulli y BinomialДокумент18 страницDistribución Bernoulli y BinomialMike FonzalidaОценок пока нет
- DISTRIBUCIONES DiscretasДокумент3 страницыDISTRIBUCIONES DiscretasJaque PecuaОценок пока нет
- Solucion Taller Tecnicas de MuestreoДокумент3 страницыSolucion Taller Tecnicas de Muestreojuan wilchesОценок пока нет
- EXAMEN - EstadistiaaaaaaДокумент1 страницаEXAMEN - EstadistiaaaaaaSantiag CzОценок пока нет
- Guiadel Estudiante 2017 Estadistica I-UESДокумент14 страницGuiadel Estudiante 2017 Estadistica I-UESRichard Kings100% (1)
- Deber 6Документ5 страницDeber 6Lulu RiОценок пока нет
- Deber N-16Документ3 страницыDeber N-16dani O100% (1)
- Distribuciones EspecialesДокумент6 страницDistribuciones EspecialesDaniela Ramirez0% (1)
- Parte IIДокумент219 страницParte IIInsumo CríticoОценок пока нет
- Ejercicio 2 Unidad 1 y 2 - Jezebel Ryann AbuchaibeДокумент6 страницEjercicio 2 Unidad 1 y 2 - Jezebel Ryann AbuchaibeAndres Fernando Guevara GomezОценок пока нет
- Ejercicios de La Distribución Binomial y PoissonДокумент3 страницыEjercicios de La Distribución Binomial y Poissonalanna michellОценок пока нет
- Distribuciones ContinuasДокумент41 страницаDistribuciones ContinuasmayraОценок пока нет
- Distribucion Binomial, Poisson, Normal-2021Документ13 страницDistribucion Binomial, Poisson, Normal-2021Luis Manuel Valero ChavezОценок пока нет
- Prueba de Hipótesis Parte 1Документ3 страницыPrueba de Hipótesis Parte 1Germán Mojica MéndezОценок пока нет
- Prueba de Hipótesis Media 2Документ11 страницPrueba de Hipótesis Media 2Mery Fernández HurtadoОценок пока нет
- Ejercicios de Est Imac Ion Por IntervalosДокумент11 страницEjercicios de Est Imac Ion Por IntervalosManuel Alvariño Torres0% (2)
- Trabajo Individual - Lorena VillamilДокумент2 страницыTrabajo Individual - Lorena VillamilLorena VillamilОценок пока нет
- Estadistica 3Документ36 страницEstadistica 3luis salazar osorioОценок пока нет
- Elementos de estadística para ingeniería: Un curso básicoОт EverandElementos de estadística para ingeniería: Un curso básicoОценок пока нет
- Datos Punto 5Документ2 страницыDatos Punto 5pedro gilОценок пока нет
- Guía de Actividades y Rúbrica de Evaluación - Fase 2Документ17 страницGuía de Actividades y Rúbrica de Evaluación - Fase 2Margarita SandovalОценок пока нет
- Horarios PequeñasДокумент16 страницHorarios Pequeñaspedro gilОценок пока нет
- Taller Inferencial ItmДокумент2 страницыTaller Inferencial Itmpedro gilОценок пока нет
- 1 Punto NДокумент2 страницы1 Punto Npedro gilОценок пока нет
- Distribuciones MuestralesДокумент48 страницDistribuciones Muestralespedro gilОценок пока нет
- Balance WplayДокумент1 страницаBalance Wplaypedro gilОценок пока нет
- Taller Inferencial ItmДокумент2 страницыTaller Inferencial Itmpedro gilОценок пока нет
- Balance WplayДокумент1 страницаBalance Wplaypedro gilОценок пока нет
- 1 PuntoДокумент1 страница1 Puntopedro gilОценок пока нет
- Trabajo UNAD - Muestreo e Intervalos de ConfianzaДокумент7 страницTrabajo UNAD - Muestreo e Intervalos de Confianzapedro gil100% (1)
- 2 PuntoДокумент4 страницы2 Puntopedro gilОценок пока нет
- Regresion en PDFДокумент9 страницRegresion en PDFpedro gilОценок пока нет
- Yugi OhДокумент1 страницаYugi Ohpedro gilОценок пока нет
- Pautas para El Trabajo Escrito GAДокумент2 страницыPautas para El Trabajo Escrito GApedro gilОценок пока нет
- Elaboracion de LacteosДокумент158 страницElaboracion de LacteosISAIОценок пока нет
- Parcial Simulacion I ParteДокумент16 страницParcial Simulacion I Partepedro gil100% (1)
- Teoria de MuestreoДокумент5 страницTeoria de MuestreoHeidy Carolina Molina AcostaОценок пока нет
- Trabajo de Correlacion en PDFДокумент7 страницTrabajo de Correlacion en PDFpedro gilОценок пока нет
- Adjunto Excel Regresion LinealДокумент7 страницAdjunto Excel Regresion Linealpedro gilОценок пока нет
- Actividad Intervalos de ConfianzaДокумент2 страницыActividad Intervalos de Confianzapedro gilОценок пока нет
- Examen ExcelДокумент19 страницExamen ExcelJonathan José Cruz SáezОценок пока нет
- Trabajo Matematicas ALEXANDER VILLEGASДокумент4 страницыTrabajo Matematicas ALEXANDER VILLEGASpedro gilОценок пока нет
- Estadistica - Parcial 2 - AДокумент4 страницыEstadistica - Parcial 2 - Apedro gilОценок пока нет
- Parcial SimulacionДокумент7 страницParcial Simulacionpedro gilОценок пока нет
- 1 Propuesta-Estadistica IДокумент3 страницы1 Propuesta-Estadistica Ipedro gilОценок пока нет
- OkДокумент2 страницыOkpedro gilОценок пока нет
- Est-135 Tema I - PresentaciónДокумент34 страницыEst-135 Tema I - PresentaciónCristal Emilia Burgos SantanaОценок пока нет
- Estadística y Muestreo de Ciro Martínez B. (Páginas 287-293)Документ10 страницEstadística y Muestreo de Ciro Martínez B. (Páginas 287-293)yulitzaОценок пока нет
- Diseño Manual Tratamiento de Drogas Digital SPANISHДокумент113 страницDiseño Manual Tratamiento de Drogas Digital SPANISHIpci IngenieriaОценок пока нет
- Portafolio 2 DoДокумент33 страницыPortafolio 2 DoAxel Rodriguez AОценок пока нет
- Modulo 1Документ19 страницModulo 1Larolyn RodriguezОценок пока нет
- Tema 1 EjerciciosДокумент6 страницTema 1 EjerciciosBrayan GonzalesОценок пока нет
- Guia 3 de ProbabilisticosДокумент3 страницыGuia 3 de ProbabilisticosAlexis GarciaОценок пока нет
- Ejercicios Resueltos Tema 9Документ6 страницEjercicios Resueltos Tema 9Kwende89Оценок пока нет
- Unidad 1 Estudio de MercadoДокумент134 страницыUnidad 1 Estudio de MercadoKally Vaal Lugo TsengОценок пока нет
- Libro de EstadisticaДокумент101 страницаLibro de EstadisticaLisbeth PiñaОценок пока нет
- Estadistica Descriptiva Aplicada A La Quimica AnaliticaДокумент62 страницыEstadistica Descriptiva Aplicada A La Quimica Analiticajose antonio sierra coneoОценок пока нет
- Ejercicios de Prueba de HipótesisДокумент5 страницEjercicios de Prueba de HipótesiselvaОценок пока нет
- ACTIVIDAD No. 5 LAS EVIDENCIAS DEL AUDITOR (1) VICKYДокумент11 страницACTIVIDAD No. 5 LAS EVIDENCIAS DEL AUDITOR (1) VICKYVICKY ALEJANDRA ALARCON GUZMANОценок пока нет
- Separata de EstadisticaДокумент101 страницаSeparata de EstadisticaJhomar Lorenzo VenturaОценок пока нет
- Presentacion Curso de EstadisticaДокумент38 страницPresentacion Curso de EstadisticaDanny LeyvaОценок пока нет
- 3 Variables Aleatorias DiscretasДокумент13 страниц3 Variables Aleatorias DiscretasSamОценок пока нет
- Introduccion A La BioestadisticaДокумент9 страницIntroduccion A La BioestadisticaEva Galaz UlloaОценок пока нет
- Modulo Estadistica I y II SemanaДокумент9 страницModulo Estadistica I y II SemanaMarco Solorzano AlbaОценок пока нет
- Estadistica Aplicada V1Документ32 страницыEstadistica Aplicada V1Juan Cristóbal Rivera PuellesОценок пока нет
- 1er P Ejer de Estimacion de Medias B y Tamano de MuestraДокумент8 страниц1er P Ejer de Estimacion de Medias B y Tamano de MuestraLeslie LunaОценок пока нет
- Investigacion de Mercado 1Документ33 страницыInvestigacion de Mercado 1Shirley Paola Vilca Balbin100% (1)
- Martin ImprimirДокумент5 страницMartin ImprimirMartin Yanarico CapiaОценок пока нет
- Trabajo Terminado de EstadisticaДокумент56 страницTrabajo Terminado de EstadisticajoseОценок пока нет
- Estimación de Parametros InformeДокумент10 страницEstimación de Parametros Informedeyanig gonzalezОценок пока нет
- Plan de Negocio Productos Alimenticios Del PuertoДокумент36 страницPlan de Negocio Productos Alimenticios Del PuertoLuis Fernando Jacobo PerezОценок пока нет
- BALDERAS Tablas MilitaresДокумент5 страницBALDERAS Tablas MilitaresmichaelgrayebОценок пока нет
- Solucionario de Clase Integradora - PC2 PDFДокумент8 страницSolucionario de Clase Integradora - PC2 PDFEnrique MirandaОценок пока нет
- Examen Final - ERICK Revisión Del IntentoДокумент6 страницExamen Final - ERICK Revisión Del IntentoFélix Len Barreto HidalgoОценок пока нет